TL;DR: We built a tool that can secretly flag texts made by large language models, without access to the model itself. It works by limiting the vocabulary using a pattern based on cryptographic hashes. In our experiments, we detected all flagged texts quickly and with no false positives, using just one hash function. This tool could help meet the EU AI Act requirements starting in August 2026. However, we haven't yet tested how well it holds up against smart paraphrasing attacks.
Background
While the volume of AI-generated content is exploding, the European Commission recognized the need to build systems that let people easily check it under Article 50 of the EU AI Act. In December 2025, the detailed requirements for this, such as metadata, watermarks, and detection tools, were released in a draft Code of Practice. Here, they noted that any solution needs to be reliable (low error rates), accessible(verifiable by third parties without the original model), robust (survives text edits), and consistent across topics and writing styles.
However, with respect to these standards, existing detectors such as DetectGPT and GPTZero, which analyze statistical patterns, can't provide mathematical guarantees. Their error rates depend on writing style, topic, and length. Watermarking approaches like the green/red list method are more reliable, but their robustness against editing hasn't been proven.
Our objective was to develop something more rigorous that can meet the standards: a watermark that can't be forged without a secret key, provides explicit error guarantees, enables verification without model access, and degrades predictably under text modifications. This led to the Markov Chain Lock watermark (MCL).
How MCL works
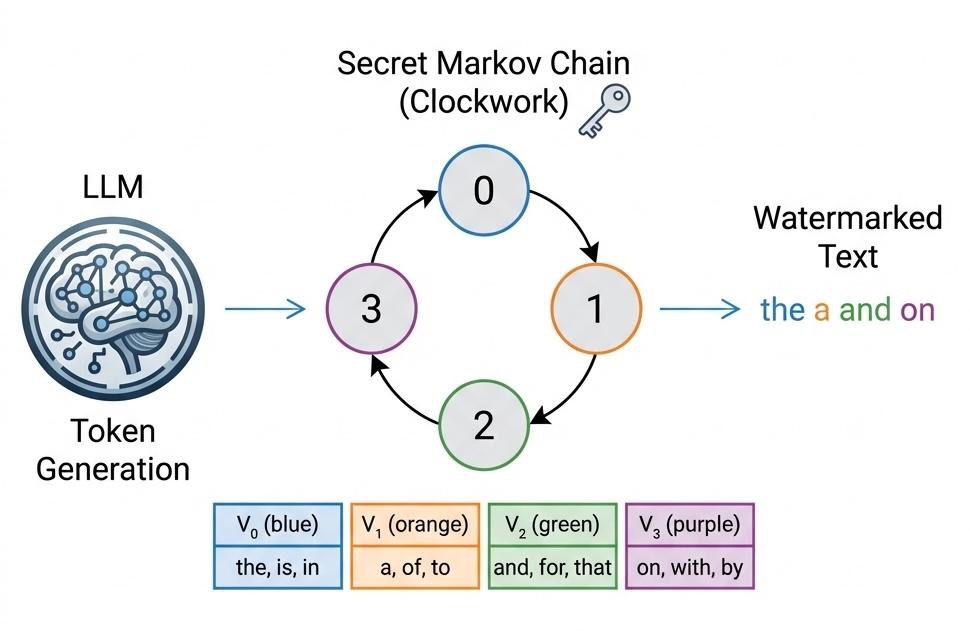
Most text AIs use autoregressive models, which generate a small piece of text (token) at a time. MCL uses this to embed a watermark. Figure 1 shows a simple toy example of a model with a vocabulary of 12 words.
Figure 1: How MCL works at a glance. The vocabulary is split into 4 groups using a secret key and SHA-256.
Step 1. Split the vocabulary into secret groups.
Using a secret key and a cryptographic hash (SHA-256), each word is put into one of several groups. Here, the words are split into four groups: blue {the, is, in}, orange {a, of, to}, green {and, for, that}, purple {on, with, by}. The important things are that (1) without the secret key, all the group assignments seem random, and (2) they are changed if you change the key.
Step 2. Add a hidden cycle during text generation.
Suppose that there’s a rule that allows each group to move only to certain other groups. The simplest pattern, called the "clockwork" pattern, makes the model cycle through the groups in order: 0, 1, 2, 3, 0, and so on.
In Figure 1, the model starts in state 0 and picks “the” from V0. Then, the cycle moves to state 1, and it must pick from V1 (here, it chooses “a”). In state 2, it chooses “and” from V2, and in state 3, “on” fromV3. At Last, the cycle moves back to state 0.
We can loosen this rule in practice. For example, instead of always picking the next group in the cycle, the model can sometimes skip ahead by one group. So from group 0, it could choose from group 1 or group 2. We call this the “soft cycle.” This gives the model more flexibility but still leaves a clear pattern for us to detect later.
Step 3. Calculate fingerprint score.
Now, you need to count how many pairs of words follow the expected cycle. That's what we call a fingerprint score (φ) and it follows like this:
φ(t)=1n−1∑n−1i=11[token i and token i+1 follow the pattern]
(where t is the list of words and n is the number of words)
So, it is the fraction of word pairs that match the expected pattern. In the case of "the a and on", since each word is in group 0, 1, 2, and 3, and three transitions match, the score is 3 out of 3, or 1.0.
When you use this on text without a watermark, the score averages around k/S, because words fall into random groups and most pairs don’t follow the cycle by chance. In our best setting (S=7, soft cycle), this baseline is about 2/7, while watermarked text scores close to 1.0. This difference is big enough for perfect detection, as our experiments show.
The best part is that this method doesn’t require access to the original model. You only need the secret key and a simple hash function. A regulator could check thousands of documents on an ordinary laptop.
What we can prove
As a watermarking method, MCL has four advantages over other methods.
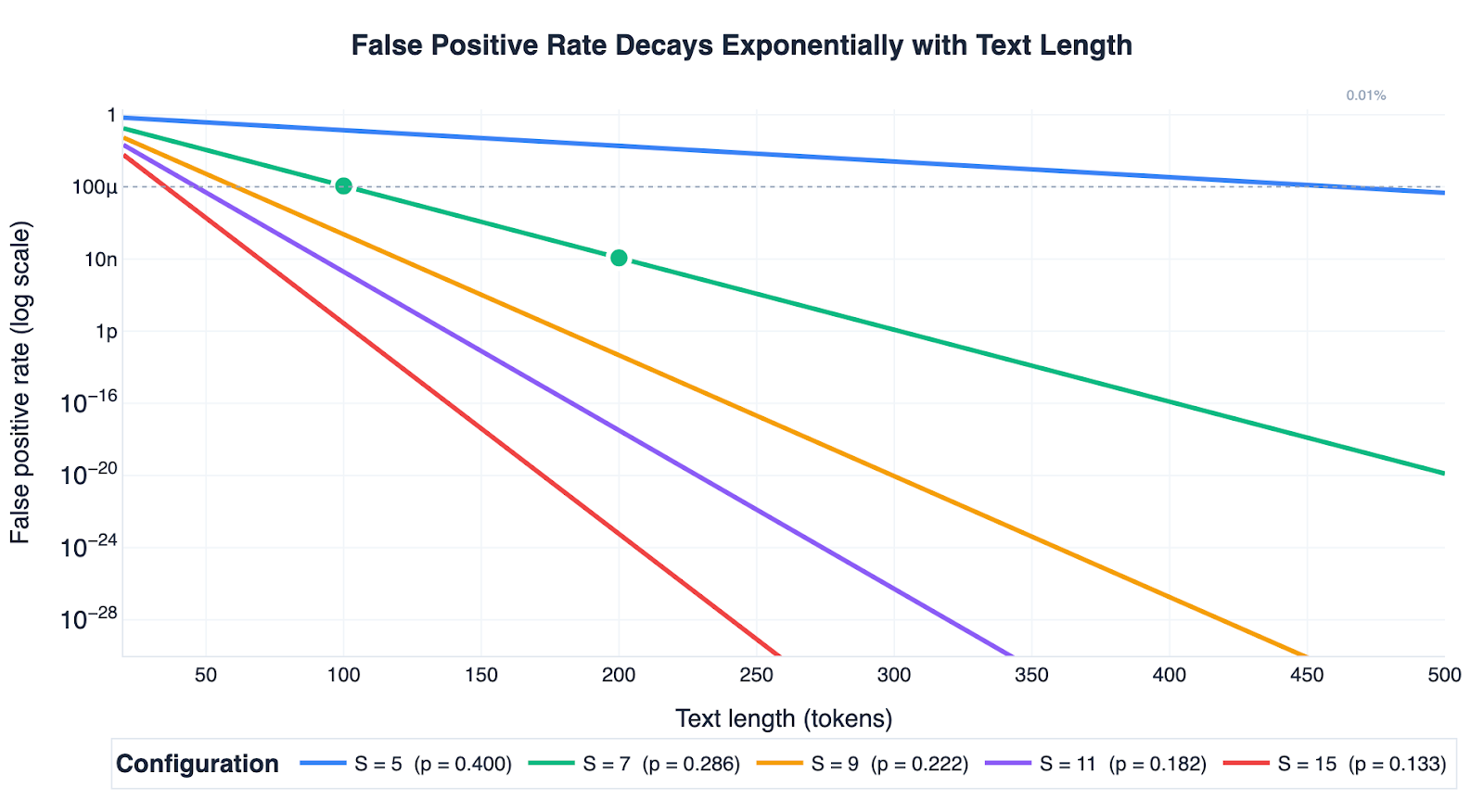
First, false alarms become basically impossible for longer texts. The probability of accidentally flagging a normal human-written text as AI-generated drops fast as the text gets longer. It can be proven using a standard statistical concentration bound (Hoeffding). The False Positive Rate (FPR) shrinks exponentially with text length as follows:
FPR≤exp(−2(n−1)(τ−kS)2)
(where n is the number of tokens in the text, τ is the threshold we use to decide “watermarked or not” (set it at 0.5). A random unwatermarked text would score the ratio k/S on average, where k is how many groups are allowed at each step, and S is the total number of groups.)
At 100 words, this gives less than a 0.011% chance of a false alarm; at 150 words, less than 0.0000012%. For anything longer than a short paragraph, false positives are almost impossible (Figure 2).
Figure 2: False positive rate drops exponentially with text length. Each line shows how FPR decreases as text length increases, for different state counts. The green dots mark two key milestones on the S=7 curve. The dashed line marks the 0.01% reference level.
Second, we know exactly how much editing the watermark survives. In the case of text revision, the fingerprint score can be calculated as follows:
E[φ]=(1−δ)2+k⋅δ(2−δ)S
(where δ is the fraction of words changed (0 means no edits, 1 means every word was replaced), k is the number of groups allowed at each step, and S is the total number of groups.)
The first part of the formula captures the word pairs that survived unchanged; the second part accounts for the fact that some of the newly generated random words might accidentally follow the cycle by chance.
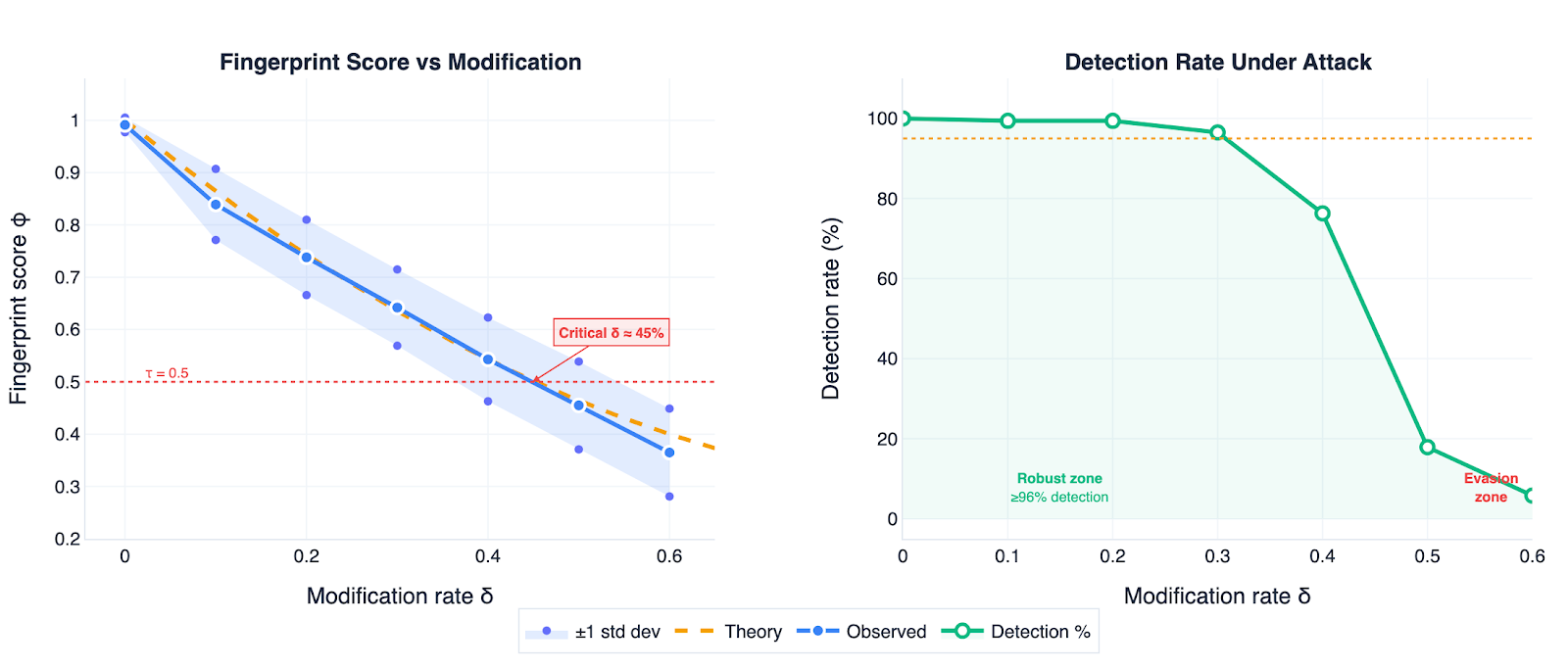
Even if someone randomly swaps words, they would need to change at least 45% of them before the watermark disappears when S = 7. In practice, this means rewriting almost the whole text. The bigger challenge is modern AI paraphrasing tools, which can rewrite sentences smoothly without obvious edits. These might break the watermark with fewer changes. We discuss this further in the Limitations section.
Third, the watermark can't be forged or removed without the key. The secret key is the only way to know which group each token belongs to. Without it, the group assignments look completely random, so an attacker cannot reconstruct the pattern or produce a valid watermark.
Last, text quality takes a small, bounded hit. Restricting the vocabulary obviously affects text quality, but we can predict the cost, which grows only proportionally to log(S). On the reader's side, this is noticeable but not dramatic, and adding more groups makes it worse only slightly. In our experiments, perplexity increased from about 3.8 for unconstrained text to 4.2 with S=7.
Experimental Setup
We used Llama-3.2-3B-Instruct (with ~128,000 tokens) and the soft cycle (k=2) on 173 Wikipedia prompts spanning science, history, tech, and culture, each generating up to 200 tokens (~150 words).
We tested models across the number of vocabulary groups ({2,4,5,7,9,11,15}) and the percentage of tokens shared across different vocabulary groups (overlap level: 0%, 5%, 10%, 15%). At 0% overlap, each token belongs to exactly one group, strictly enforcing the cryptographic constraint, while higher overlap gives the model greater flexibility.
Across 28 configurations, we measured fingerprint scores, detection rate, false alarm rate, and perplexity. For results on Mistral-7B and GPT-2-XL, see Appendix B.
Results
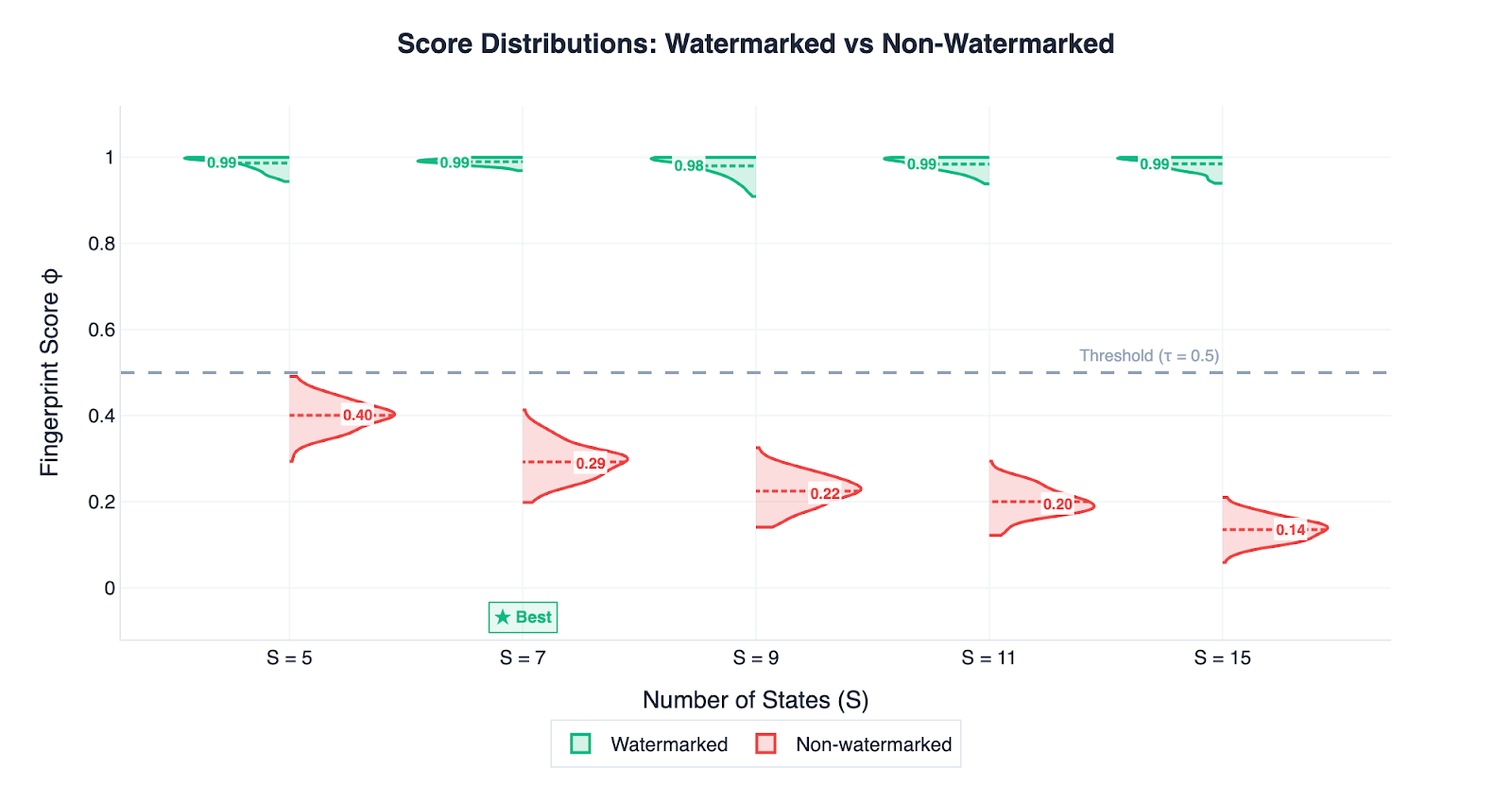
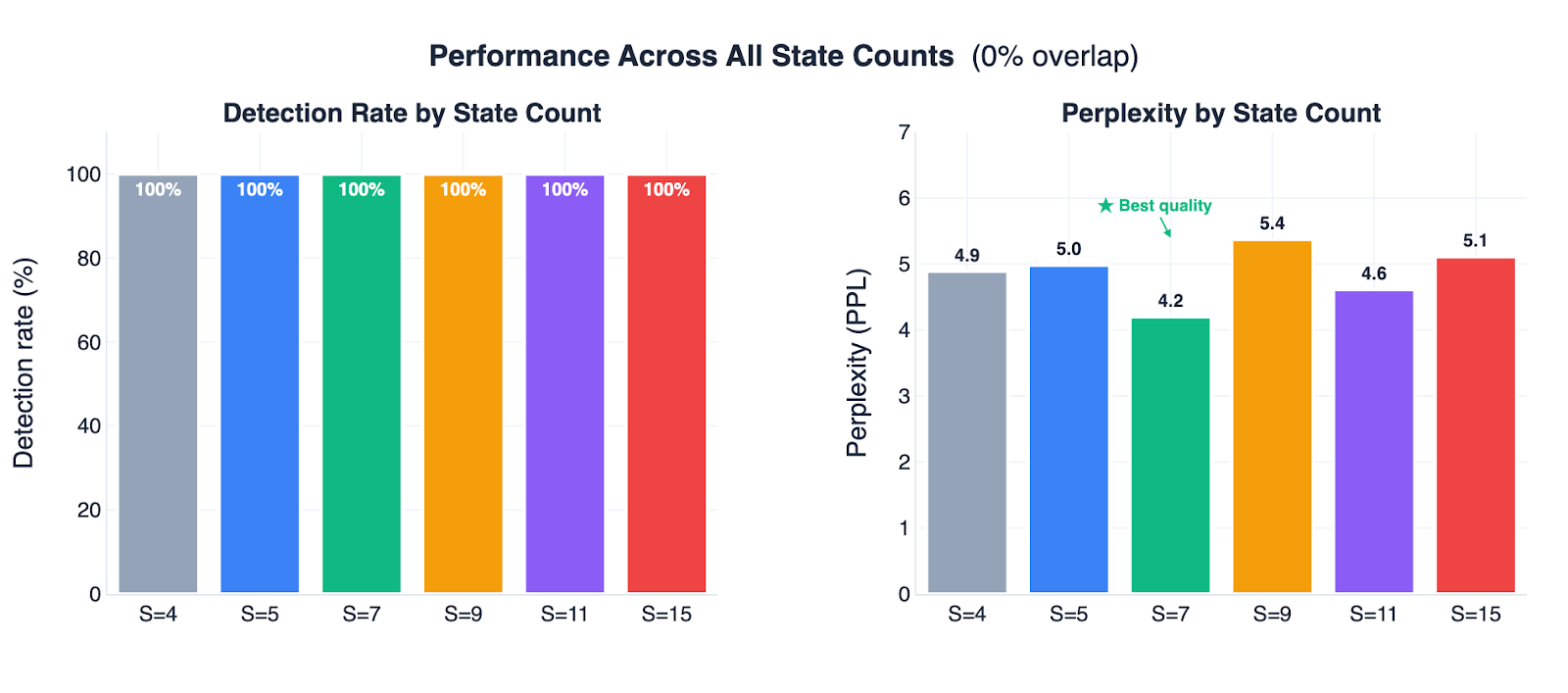
With S ≥ 5 and 0% overlap, every watermarked text scored higher than every non-watermarked text across all 173 prompts. A single threshold at 0.5 produced zero false positives and zero missed detections (Figure 3). Among all configurations that achieve perfect detection, S=7 produces the most natural-sounding text (perplexity 4.2), making it the best overall setting (Figure 4).
Figure 3: Perfect separation between watermarked and non-watermarked text. Each pair of violins shows the distribution of scores for watermarked (green, left) and non-watermarked (red, right) text. The dashed lines inside each violin mark the mean score. For every state count S ≥ 5, the two distributions are completely separated by the τ = 0.5 threshold, meaning zero false positives and zero missed detec
Figure 4: Why S=7 is the sweet spot. Left: every state count from S=4 to S=15 achieves 100% detection at 0% overlap. Right: perplexity (text quality cost) varies across configurations, with S=7 producing the most natural-sounding text (lowest PPL of 4.2).
Figure 5 shows that the robustness formulas also held up empirically. Randomly replacing words weakens the watermark, but importantly, it follows the prediction from our formulas. Even when 30% of tokens were replaced, detection remained above 96%, matching theoretical predictions within 1–6 percentage points. To evade detection, attackers would need to corrupt nearly half the text.
Figure 5: Theory matches reality. Left: the theoretical formula (dashed orange) predicts the observed fingerprint scores (blue) with outstanding accuracy, typically within 1-6 percentage points. Right: detection stays above 96% even with 30% of tokens randomly modified.
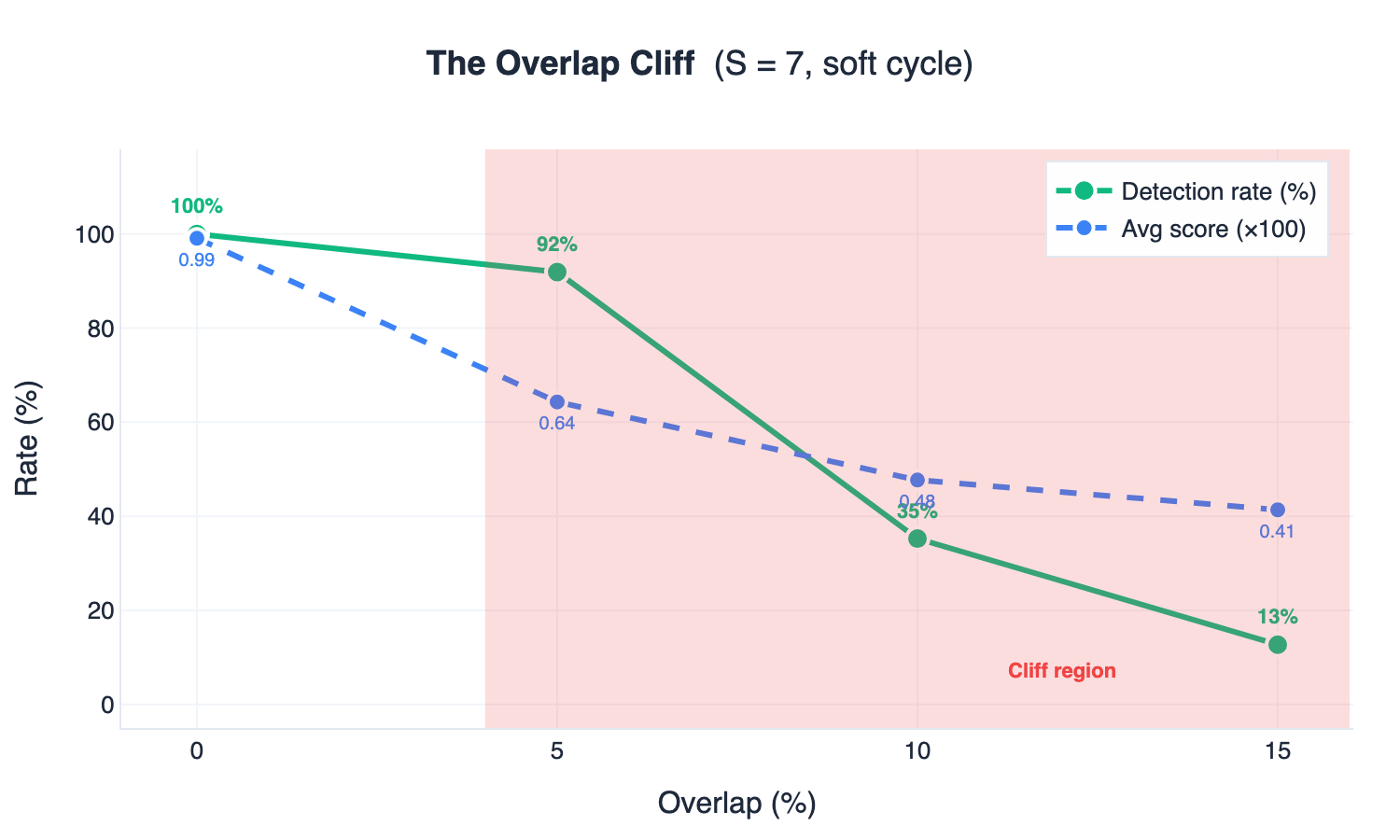
In addition to the findings, two failing configurations are worth flagging. One is that using S=2 with the soft cycle produces no signal, since every transition is allowed. The other is that any overlap between groups sharply degrades performance. As shown in Figure 6, even 5% overlap at S=7 drops detection from 100% to 92%. This means once tokens can belong to multiple groups, the cryptographic constraint no longer holds.
The results imply that MCL must be run at 0% overlap, but for Llama-3.2, the model still has roughly 18,000 tokens available at each step. So output quality is generally fine, though edge cases like code generation can be affected.
Figure 6: The overlap cliff. As the overlap ratio increases (x-axis), both the detection rate (green) and average score (blue dashed) drop steeply. The shaded red zone is the “cliff region” where the cryptographic constraint breaks down.
Limitations and open questions
Three issues deserve upfront acknowledgment.
Tokenizer coordination. MCL operates at the token level, and different models tokenize text differently. To verify a watermark, you need to know which tokenizer was used. The technical fix is straightforward: include the tokenizer information in the metadata (using C2PA or something similar). But getting all AI companies to agree on a metadata format before August 2026? That’s a coordination problem, not a technical one, and those are often harder to solve.
Untested against intelligent attacks. Our robustness tests only swapped out random words. A determined attacker would likely use another AI to paraphrase the text, which is easy to do and works well against most token-level watermarks. Our math covers any kind of token change, so the formulas still hold no matter how the text is edited. But we haven’t actually tested against AI-powered paraphrasing yet. The 30% random-replacement survival rate is promising, but it doesn’t show what happens if another LLM rewrites the text. That's the most important open question, and we plan to address it in follow-up work (including testing against GPT-5 and Claude).
The overlap cliff. The sudden drop from perfect performance to barely working between 0% and 5% overlap needs more study. It may be possible to relax the cryptographic constraint into something softer that handles overlap more gracefully.
One promising direction is sparse watermarking. Instead of applying the rule to every word, we’d use it only every few words. This lets the AI write more freely and makes the text sound more natural, but the watermark would still remain.
Conclusion
Our methodology achieves 100% detection and 0% false alarms with a perplexity of 4.20 (S=7). It has exponentially low false positives, exact robustness formulas, cryptographic unforgeability, and bounded quality costs. Lastly, MCL has a real advantage in that it can verify without access to the original AI model, and we hope it will help with compliance as the August 2026 deadline approaches.
Thanks to Apart Research for hosting the Technical AI Governance Challenge.
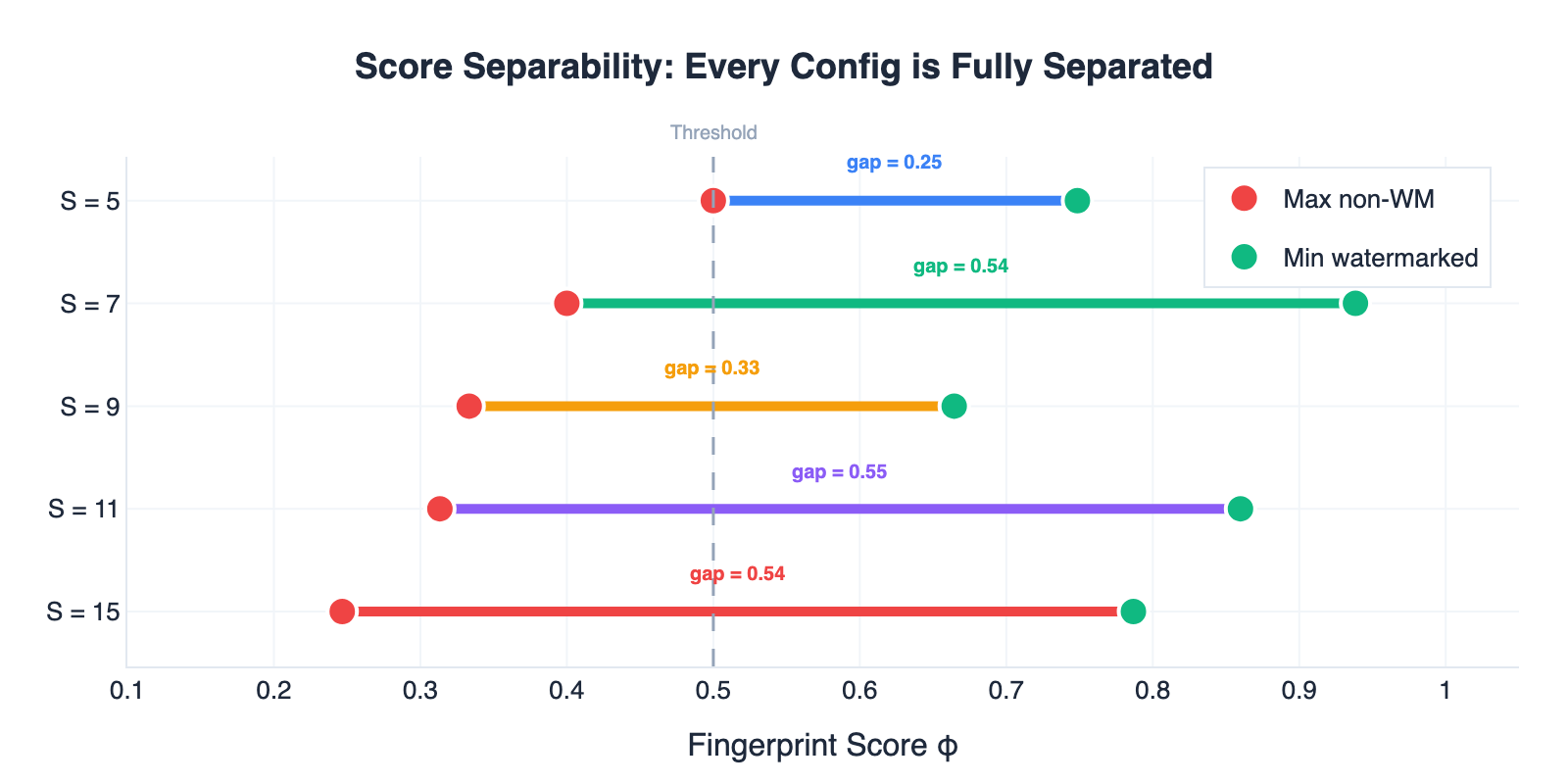
In order to see if there can be confusion between watermarked texts and non-watermarked ones, we compared the lowest score of the watermarked samples against the highest score of the non-watermarked samples in every setting with S=0 at 0% overlap. In every case, there is complete separation between the pairs. (Figure 7).
Figure 7: Score separation across all configurations. Each horizontal bar connects the worst-case scores: the red dot is the highest score from any non-watermarked text, and the green dot is the lowest score from any watermarked text.
Appendix B: Cross-model validation
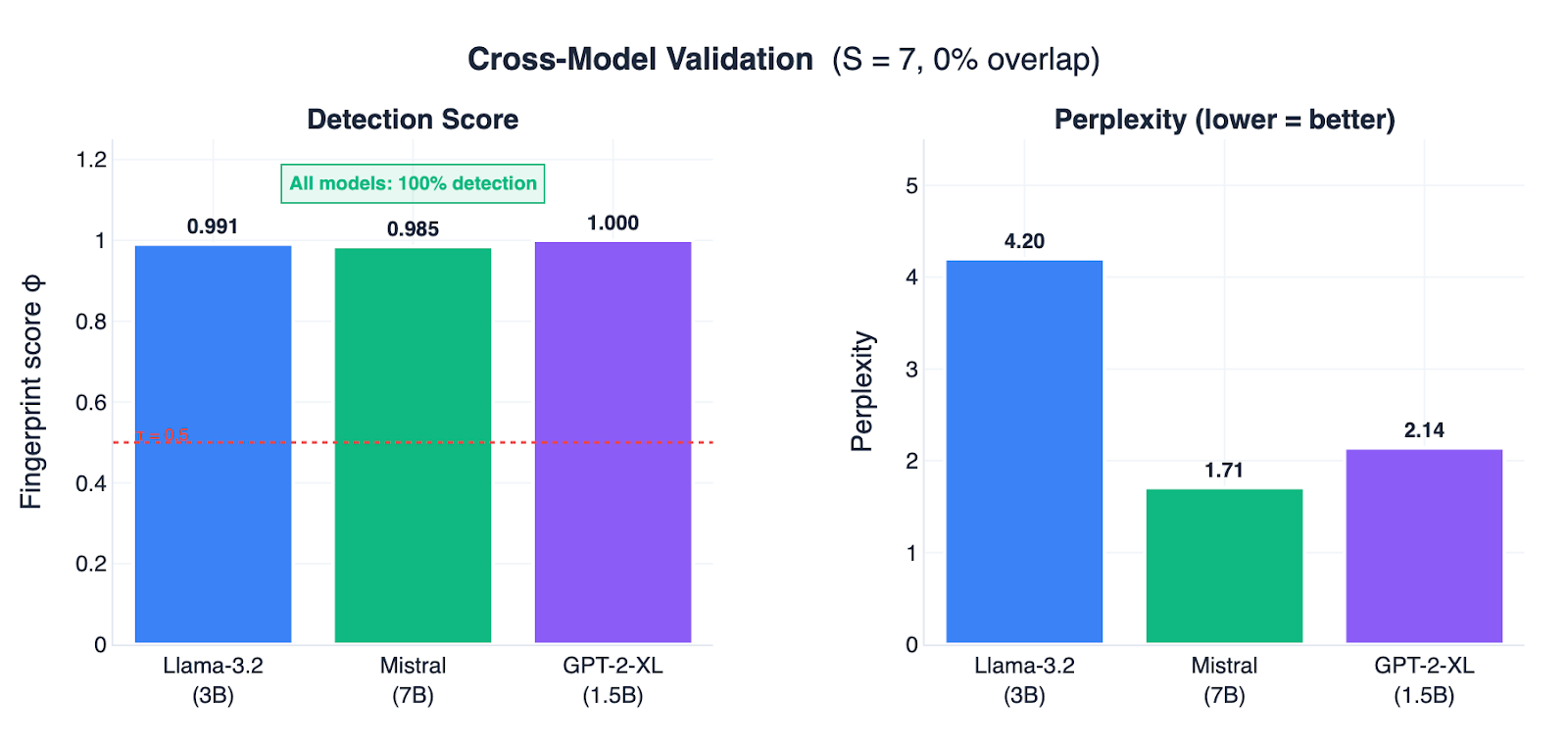
To check MCL's generalization, we ran the same 173 prompts on Mistral-7B-v0.3 and GPT-2-XL. All three models hit 100% detection at S=7 (Figure 8). The larger model (Mistral-7B) handled the vocabulary restriction much better, achieving a perplexity of just 1.71 compared to 4.20 for Llama.
Figure 8: MCL works across different model architectures. We tested the S=7 configuration on three models of different sizes: Llama-3.2 (3B), Mistral (7B), and GPT-2-XL (1.5B).
AI Use Note: Main body text entirely human written. Claude (Opus 4.8) helped develop models of animal life histories in the appendix.
Cross-posted from Good Structures.
Executive Summary
* Animal advocates sometimes make claims like “there are X of this animal...
“How long have you been v*g*n?”
This is one of the most common icebreakers at animal protection events. It’s a baseline assumption, and it mostly holds true: if you’re out advocating for animals not to be tortured or abused, realistically these days you are v**n, or close. And it makes for good conversation. It seems fairly safe to assume when you meet strangers.
But this assumption is hurting the movement in a way which we don’t always notice: someone new comes into the sp...
Summary
Back in November 2023 I posted here to launch Spiro and raise our first $198k. Two and a half years later this is an update and a fundraiser for the next step.
The short version: we've now reached over-5,900 people with TB preventive medicine, including over 3,000 children under five years old. Our early results have held up well an...