This post is one part of the sequence Understanding the diffusion of large language models. As context for this post, I strongly recommend reading at least the 5-minute summary of the sequence.
Definitions
Here I explain what various terms mean in the context of the diffusion of AI technology and this sequence.
I define transformative AI (TAI) qualitatively as “potential future AI that precipitates a transition comparable to (or more significant than) the agricultural or industrial revolution.”
This is how Holden Karnofsky originally defined the term in 2016 (Karnofsky, 2016). Luke Muehlhauser elaborated on the definition in 2019, emphasizing that “the transition immediately following the (‘first’) industrial revolution was a much larger change in [measures] of human empowerment and well-being than other events in recorded history, including the Black Death of the 14th century, the Scientific Revolution of the 17th century, the two world wars of the 20th century, and the ‘2nd and 3rd industrial revolutions’ implied by discussions of a potential future ‘4th industrial revolution’” (Muehlhauser, 2019).
Artifact: a product of AI R&D
An artifact is a product of AI research or development. Examples of artifacts include a trained model, the code for training a model, a new dataset, or a new algorithm. Artifacts are what diffuse among actors.
- I use the term “tangible” to contrast artifacts with tacit or procedural knowledge (e.g. the intuition that some research idea is worth trying). It can be useful to consider the diffusion of tacit or procedural knowledge, but in this sequence I focus on artifacts.
Diffusion: the spread of artifacts among actors
Diffusion is when an actor acquires an existing artifact. For example, suppose a machine learning model is trained by an AI lab and the model is made freely available to download from the internet. The model may then diffuse rapidly and widely to any individual that is able to download and run the model on their computer.
- Note that the meaning of “acquires an existing artifact” is deliberately vague. An AI technology being acquired by some actor does not necessarily mean that they have acquired the exact same object (e.g., the exact same ML model), but it means that the actor possesses an object that serves roughly the same function as an existing object.
- “Diffusion” can also refer to the general phenomenon of artifacts being acquired, rather than a specific case.
Taxonomy of diffusion mechanisms—e.g., open publication, replication
A diffusion mechanism is the final means by which an artifact is acquired by some actor, given that the artifact was already possessed by some other actor first. (Note that acquiring the artifact doesn’t necessarily mean possessing the original copy of the artifact; it can be copied or reproduced.)
Possible mechanisms include:
- Open publication, where the artifact is made publicly available. By definition, open publication is done by or with the permission of the original authors of the artifact. E.g., the authors upload their trained model’s weights to the internet, allowing the weights to be downloaded by anyone.
- Leak, where the artifact is unilaterally made publicly available, without the permission of all original authors. E.g., someone is granted access to a trained model’s weights under an agreement to not publish those weights, but then that person unilaterally publishes the weights on the internet, allowing the weights to be downloaded by anyone.
- Theft of information or artifacts. E.g., stealing a trained model by exfiltrating the model files from the private servers of the original developers. Theft could be achieved via hacking or espionage.
- Extortion, where one actor uses some kind of threat to coerce another actor to diffuse something (e.g., an AI model) to them.
- Replication, meaning training a model from random initialization with an identical architecture to some other model, with an intent to replicate a particular model, and achieving a negligible difference in performance between the two models.
- In this sequence, I define “negligible difference in performance” as a difference that is less than or equal to two percentage points on the benchmarks that have been evaluated for both the original model and the replica.
- In contrast to open publication, replication involves independently doing at least part of the process that produced the original result. The full process includes the design stage (e.g., specifying the model architecture), and obtaining a training dataset.
- Actors might use a model stealing attack to replicate a model, e.g., model extraction. A “model stealing attack” is not the direct theft of a model stored as data on a computer—it still involves training a model from random initialization, but uses the inputs and outputs of an existing model as training data rather than the original training dataset. Model extraction could thus be achieved using queries to an existing model’s public API.
- Replication may blend with other diffusion mechanisms—e.g., some of the required resources may be open-source or acquired via theft, while other resources need to be produced independently. However, in my case studies I found that it was clear enough when the main mechanism was replication.
- Incremental research, where research makes a relatively small change to an existing method, and produces a comparable or better artifact in the process. For example, an actor trains a new model which demonstrates performance that is at least comparable on the same evaluations as a previous model. This new model is based upon existing research results and artifacts to some extent, but is not trying to exactly replicate any other model.
- Incremental research leads to the diffusion of similar, though not identical, artifacts. In a later section, I explain why I include incremental research as a mechanism of diffusion.
In addition to the causal mechanisms of diffusion above, there is the phenomenon of multiple discovery. Multiple discovery is where two actors independently come up with the same idea or result, probably partly via drawing on the same prior work as each other. Considering the role of multiple discovery thus helps to judge the counterfactual impact of decisions that affect diffusion.
Accelerating and hindering factors in diffusion
- Accelerating factor: some factor which made diffusion easier or more likely in a given case. For example, a group that was trying to replicate an artifact had their compute resources sponsored (i.e., paid for) by some other entity, which made replication more affordable for that group.
- Hindering factor: some factor which made diffusion more difficult or less likely in a given case. For example, hardware failures continually occurring during a replication effort, requiring fixes and restarts that use up all of an actor’s budget.
- A diffusion factor is different to an input such as compute. A factor would be something that helped an actor gain access to compute, rather than the possession of the compute itself.
- Note that the default conditions from which to measure diffusion being easier or more likely are not clearly defined. I use my own judgment of what factors are notable.
A GPT-3-like model is a densely activated neural network model that was trained to autoregressively predict text using at least 1E+23 floating-point operations (FLOPs) of compute, and enough data to approximately follow established scaling laws for autoregressive language modeling.
- Note that this definition includes:
- GPT-3 itself
- Models that have a similar design, amount of training compute, and performance to GPT-3
- Models that have a similar design to GPT-3, but used even more training compute, and may have greater performance than GPT-3
- Note that this definition is drawing somewhat arbitrary or artificial boundaries for the sake of limiting the scope of my case studies. The definition may exclude some models that matter for essentially the same reasons as the models that are included. However, I did partly choose this definition in order to include most of the models that I think are most relevant.
The threshold of 1E+23 FLOPs of training compute in this definition serves as a proxy for how powerful the trained model is. Of course, arbitrary amounts of compute can be wasted, and training compute does not directly translate into model performance, so this is a flawed proxy. Nonetheless, I think it is a good enough proxy in the domain of large pretrained language models for the following reasons:
- In practice, model developers try to make efficient use of compute to maximize performance, in order to save money and time and obtain more impressive results.
- Scaling laws show that a language model’s test loss empirically follows an inverse power law with respect to training compute in FLOPs.,
- The proxy of training compute compensates for the fact that there is no clearly defined way to fairly compare the performance of language models across multiple tasks, especially when the training data for those models has different predominant languages (e.g. English vs. Chinese).
- Training compute is often easier to estimate and compare than overall performance, even where performance comparisons are applicable. This is because different research publications report results in different ways and for different sets of benchmarks. Meanwhile, training compute can always be estimated from basic facts about the training procedure (e.g., the model parameter count and the number of training tokens).
Despite reason 3, I still make efforts to compare the overall capability of potential GPT-3-like models—see the “Capability compared to GPT-3” column in the diffusion database.
Pretraining and fine-tuning in machine learning
A model that is trained to autoregressively predict text from a relatively large and broad dataset is often called “pretrained”. This is because the model is trained with the intention of further training the model later, on a more specific dataset, to improve the model’s performance at a specific task. Updating the model’s weights based on a more specific dataset is usually called “fine-tuning.” But GPT-3 showed that pretrained language models can exhibit in-context learning. That is, a model can learn based on information (e.g., examples of a new task) contained in the text input to the model, without any change to the model weights. This is often referred to as “prompting”.
I think of the four key inputs to AI development as compute, data, algorithmic insights, and talent. These inputs are crucial to understanding how AI development works—including diffusion—and how to influence it. In this section I explain what I mean when I refer to these inputs, along with some commentary on how they matter and relate to each other.
Compute
The basic definition of “compute” as a noun is simply “computation”. However, my impression is that in the context of AI development, “compute” can refer to either of the following things:
- Number of operations (in FLOPs): In modern machine learning, the number of floating-point operations (FLOPs) used by a model (whether for training or inference) is approximately proportional to the product of (a) the number of parameters in the model and (b) the number of examples (AKA data points) fed into the model.
- More FLOPs affords more data points. This creates a direct relationship between compute and data.
- Number of computing hardware units used to train a model
- E.g., the number of GPUs.
- More hardware units means more FLOPs on the same time budget.
- More hardware units also typically means more FLOPs on the same monetary budget, because using more units enables greater efficiency up to some point.
- For example, GPT-3 is too large to fit in the memory of even the largest available GPU. So training GPT-3 on a single GPU would require moving parts of the model between GPU memory and other computer memory. Repeatedly moving the model data this way would have a higher overhead cost that reduces efficiency compared to splitting the model over multiple GPUs.
When people talk about “better” compute, they are often referring to the efficiency of hardware (in FLOPs per second per hardware unit).
- Higher efficiency means more FLOPs for the same time budget.
- Historical growth in the peak FLOPs per second of hardware tends to happen alongside growth in FLOPs per second per dollar (which is doubling roughly every 2.5 years). So over time, exponentially more FLOPs can be afforded for the same monetary budget.
Hardware that is used for AI (such as data center GPUs) is also optimized partly for the rate of data transfer between hardware units (known as memory bandwidth), in bytes per second. The more that computation is parallelized over multiple hardware units, the more important memory bandwidth is.
Data
“Amount of data used” can refer to either of the following things:
- The number of examples a model sees during training
- I think this is less useful as a distinct meaning of “data”, because it relates directly to the notion of compute as the number of operations.
- Dataset size: how many examples are in the full dataset used to train a model
- The larger the dataset size, the fewer repeated examples the model will see during training.
- An “epoch” of training is when the model has seen every example in the dataset. For instance, GPT-3 saw between 0.43 and 3.4 epochs of each dataset that made up its full training dataset.
- One takeaway from Hernandez et al. (2022) is that repeated examples generally harm the performance of pretrained language models. So a larger dataset size is generally better for performance.
Data quality is also important for AI development. I’d define data quality as the combination of (a) how relevant the examples are to the capabilities that are desired for the model, (b) how diverse the examples are.
- I am not aware of a widely agreed upon, precise definition of data quality. The above is my attempt at a vague but useful definition.
- For a language model, the criteria for relevance may include factual accuracy, narrative consistency, or appropriate style. For instance, if I want a pretrained language model to be better at written arithmetic, I might improve the quality of the training dataset by increasing the proportion of correct examples of worked solutions to arithmetic problems (as opposed to zero examples, or incorrect examples, or solutions without working).
- The diversity of the examples tends to improve the breadth and robustness of the trained model’s capabilities. For example, to give a language model a more robust understanding of English grammar, it would be helpful to include examples of various exceptions to rules in English grammar in many different contexts.
Algorithmic insights
I divide algorithmic insights into two broad categories:
- Improved algorithms. In machine learning, an improved algorithm is a new procedure for training a model that results in improved performance. The improved performance could be an increase in the efficiency of training (same performance for fewer FLOPs), or an increase in a specific evaluation metric for the model.
- Importantly, the new procedure might enable more compute and data to be used more efficiently. This in turn might enable further improvements to performance by scaling up compute and data. But to count as an algorithmic improvement, the new procedure must be counterfactually responsible for improving performance.
- One example of this kind of improvement is the Transformer architecture, introduced in Vaswani et al. (2017). In Hernandez and Brown (2020), it was found that “within translation, the Transformer surpassed seq2seq performance on English to French translation on WMT’14 with 61x less training compute 3 years later.” But the Transformer not only reduced the compute required to match an existing state-of-the-art; it also allowed using the same amount of compute as before (or more) to achieve better performance. This has ultimately led to models like GPT-3 leveraging the Transformer architecture with unprecedented quantities of compute (within the language domain, at least).
- Insight about how to leverage existing algorithms. There are some insights about the use of algorithms that don’t involve any fundamentally new procedures. Instead, these insights inform how existing algorithms can be leveraged better, e.g., by using a different allocation of inputs to the algorithm.
- For example, I consider the empirical scaling laws discovered for neural language models to be an algorithmic insight. The laws imply that the same set of algorithms will continue to yield predictable improvements on the training objective as the model size and the number of training data points is increased. Here, there is both the insight that scaling laws are a phenomenon at all (which occurred before GPT-3 was produced), and the insight that scaling laws continue to have predictive power at the scale of GPT-3 (which was confirmed by GPT-3 itself).
Talent
Talent in the context of AI development can refer to (not mutually exclusive):
- The number of people that have the requisite skills to fulfill a role in an AI development project.
- Depending on the context, this could refer to how many such people a given actor such as an AI lab has employed, or how many such people exist in the world.
- A person’s level of skill that is relevant to a given role in an AI development project. E.g., “engineering talent” could refer to the level of machine learning engineering skill a project member has.
- The product of (1) and (2) that was put toward a given machine learning project—that is, the average skill level multiplied by the project team size.
- This is usually what I mean by “talent” in this sequence.
The cost of AI talent can be measured in the following ways (not mutually exclusive):
- The cost for a given actor to acquire a given level of talent. This may involve setting up the infrastructure to support talent, creating incentives to attract talent, marketing to potential candidates, relocating candidates, and taking candidates through a hiring and onboarding process.
- The cost of labor for an AI development project. This could be approximated by the annual salary per project member, multiplied by the project team size, multiplied by the number of years spent on the project.
Of the other three inputs to AI development, I think talent is most closely related to algorithmic insights. However, talent is related to all other inputs in some way:
- The more talent a project has in machine learning research and engineering (both in quality and quantity), the more likely algorithmic insights are to be discovered and successfully applied.
- The more engineering talent a project has, the easier it is to scale up compute successfully.
- The more machine learning (and perhaps data science) expertise a project has, the more knowledge there will tend to be about how to improve data quality.
The relevance of AI diffusion to AI x-risk
AI timelines
Diffusion can hasten the arrival of TAI via knowledge sharing. The knowledge and artifacts that are shared by various AI developers can benefit the leading developer greatly, even though the leading developer is ahead overall. This is because the surface area of AI research is large, and throwing more resources at research does not produce insights at a reliable rate. The leading developer is therefore unlikely to be the first to discover every insight needed for TAI. By gaining shared knowledge sooner than they would on their own, the leading developer can reach TAI faster.
Who leads AI development by what margin
Diffusion can affect how large a lead the leading AI developer has and who the leading developer is, in two ways:
- Drafting: in racing sports, to draft is “to stay close behind (another racer) so as to take advantage of the reduced air pressure created by the leading racer.” Similarly, an AI developer might keep themselves close behind the leading AI developer, to take advantage of any resources that diffuse from the leading developer. Actors who are further behind will be less able to properly understand or make use of the diffused artifacts, so it’s better to remain close behind. Some actors may even remain behind the leader deliberately for some time, rather than getting in front, in order to produce artifacts at lower cost.
- Leapfrogging: diffusion can also help an actor go beyond just “drafting” to surpass an actor in front of them. Suppose that one actor, Beta, learns about some new result published by another actor, Alpha. Even if Beta is generally less resourced than Alpha, they might have a different set of resources (e.g., more expertise in a certain domain) that enables them to improve upon Alpha’s result before Alpha does. This is arguably the main purpose of having a research community with transparency as a norm—to make it easier to increment upon each other’s results. But this phenomenon may be undesirable for TAI development. This is because easier incremental progress may increase competitiveness and in turn reduce caution, or cause a less benevolent actor to take the lead.
In these ways, diffusion tends to increase competitiveness on capabilities. Increased competition tends to create an AI race, and decrease the willingness to pay the alignment tax.
Multipolarity of TAI development and deployment
In addition to who the leading AI developer is and how much of a lead they have, AI diffusion also affects the number of actors who are close contenders, and therefore who might be able to take the lead in the future. The more actors that are close to the leader, the more multipolar AI development is. The speed and scale of diffusion will affect the ease by which actors can gain more resources and catch up on AI capabilities, which tends to increase multipolarity.
The multipolarity of TAI development also affects multipolarity in a post-TAI world. The more actors who possess power through TAI technology, the more multipolar the post-TAI world is. During a multipolar scenario, I think there is an increased risk of:
- Unilateral deployment of AI that leads to an existential catastrophe
- Great power conflict, and reduced capacity for coordination in general
- Coordination would be more difficult because the more actors that have power, the more varying interests there will tend to be, and therefore the more complicated it becomes to coordinate actions.
Multipolar scenarios in a post-TAI world seem more likely if:
- In the lead up to TAI being deployed, no actor has a large lead in developing TAI
- The barrier to entry for developing TAI is not very high, and new entrants can catch up relatively quickly.
In general, the more easily that AI technology diffuses, the more likely conditions 1 and 2 are.
Accidents vs misuse
Existential catastrophe from AI development or deployment could occur either via accidents with the AI (especially due to misaligned, power-seeking, highly capable AI systems) or via misuse of the AI by humans (or perhaps also via “structural risk”; see Zwetsloot & Dafoe, 2019). Diffusion of AI capabilities increases the number of actors that can access those capabilities. That can increase both types of risk, by increasing the chance that some actor uses those capabilities poorly.
I think that if existentially catastrophic misuse occurs, it will most likely result from the actions of a single large actor such as a government. However, it’s plausible to me that at some point in the future, due to diffusion, many actors would be able to misuse AI in a way that causes existential catastrophe—at least tens, but possibly thousands or more. Perhaps only the most malicious among these actors (e.g., a radical terrorist organization) would actually take a catastrophic action.
Overall, I think there is a higher total risk from the possibility of TAI systems being misaligned than from the possibility of existentially catastrophic misuse, so I think diffusion’s effects on the former are more important than its effects on the latter. For the sake of brevity, I do not argue this view further, so this should be treated as an assumption that underlies the focus areas and recommendations in this sequence.
Benefits of diffusion: scrutiny, AI alignment, and defense against misuse
There are some ways in which diffusion can be beneficial, including:
- Transparency and scrutiny of leading developers: greater diffusion makes it easier for more actors to scrutinize the work of other (leading) actors. This scrutiny in turn could increase the accountability of leading actors to be cautious and responsible with the development and deployment of TAI.
- Accelerating AI alignment research: more diffusion results in more actors having access to resources that can help alignment research. These resources include datasets or tools that can be used as part of alignment research, and AI models that researchers can “do alignment research on” to make their research more relevant and grounded. I expect that this increased access to resources speeds up progress on alignment.
- Improved defense against harms from AI: diffusion can enable more actors to develop and use AI as a defense against the harms of AI. This might apply especially to harms from misuse of AI, but could also apply to harms from misaligned AI in some scenarios (see Karnosfky, 2022). This is a counterpoint to the argument for diffusion increasing the risk of existentially catastrophic misuse (see the previous section).
Overall opinion: diffusion is net bad by default, but can be net good if the right things are diffused carefully
I do not have thoroughly reasoned conclusions about the benefits and harms of diffusion. In this sequence I mostly leave that question for future work (see the Questions for further investigation post). My best guess is that if there were no change in publication norms from today, diffusion would lead to faster capabilities progress overall. This is because there are more actors focused on improving and applying capabilities than on scrutiny or alignment. This would in turn increase the likelihood of TAI systems being misaligned or misused. Furthermore, my intuition is that the offensive capabilities of AI will generally outweigh the defensive capabilities of AI, because using AI to detect and neutralize harms from AI generally seems more difficult than causing those harms.
However, it’s crucial to realize that differential diffusion is possible—we can limit the diffusion of net-harmful artifacts while increasing the diffusion of net-beneficial artifacts. This idea is related to differential technology development, which “calls for leveraging risk-reducing interactions between technologies by affecting their relative timing.” I don’t think the best strategy would be to stop diffusion altogether, even if that were possible. Rather, the AI governance community should do more research on how to safely diffuse artifacts that boost responsible AI development, but that do not significantly increase risk. For example, we could diffuse tools that make it easier to apply best practices for deploying models. The question of which artifacts are best to diffuse, and how to diffuse them with minimum risk, is something I leave for further investigation.
Why focus on case studies of large language models?
In the previous section I explored how diffusion is relevant to risks from TAI. But TAI may be decades away, which makes it very difficult to forecast the ultimate effects of diffusion. And as impressive as current state-of-the-art language models are, they still seem far from being TAI. So what is the relevance of studying the diffusion of (nearly) state-of-the-art language models today?
I see three main reasons:
- The way that diffusion works today might basically persist until the development of TAI.
- This becomes more likely the sooner that TAI happens (e.g., if “Artificial General Intelligence” is created before 2032, a prospect which Barnett (2020) assigns a 25% probability).
- However, I do see strong reasons to expect the dynamics of diffusion to change a lot even within ten years. One reason is that if we just extrapolate current trends, the investment in future state-of-the-art AI systems would be on the order of $1 trillion by 2032, even when adjusting for improvements in hardware efficiency. This cost might be implausible for any actor to incur, perhaps with the exception of the US and Chinese governments. But the trend at least suggests that the investment in AI training runs could become multiple orders of magnitude larger than it is today, which in turn makes diffusion much more difficult. I think that such huge investments would also warrant greater secrecy than we see today, to protect intellectual property or national security. The greater secrecy would reduce diffusion.
- TAI systems might resemble today’s best-performing language models, so the implications of diffusion related to such models may be similar to the implications of diffusion related to TAI systems.
- GPT-3 demonstrated that pretrained language models can achieve near-state-of-the-art performance across a wide range of tasks, without fine-tuning. Furthermore, text as a medium seems theoretically sufficient to perform a wide range of economically valuable tasks. These tasks include software development, or any form of research that does not involve performing physical experiments.
- The Scaling Hypothesis is the hypothesis that scaling up the amount of compute and data with essentially the same methods used for training state-of-the-art AI models today could be sufficient to create TAI. Some evidence for this hypothesis comes from empirical scaling laws that have been discovered for neural language models (see e.g., Kaplan et al., 2020). The more likely the scaling hypothesis is, the more TAI systems should be expected to resemble today’s AI systems.
- Even if a lot changes between now and TAI, studying the history of diffusion will inform our priors, and improve our understanding of what could happen.
- I think two of the ways that diffusion is most relevant to existential risk from AI are its effect on who leads AI development by what margin, and how many actors will be plausible contenders to develop TAI (see the previous sections on leading and multipolarity). A factor that’s relevant to those two questions is: how easily can leading AI developers—and potential future leading AI developers such as governments or AI startups—reproduce and build upon each other’s work? The historical attempts to replicate state-of-the-art models can inform us about how those potential AI leaders could gain ground.
To be even more specific, I focus on language models that are similar to GPT-3 because of their current relevance, and because they present an unusually good opportunity for case studies:
- GPT-3 seems to be one of the biggest AI milestones in terms of publicity and influence on subsequent AI R&D. The overall interest in replicating GPT-3 seemed unusually high as a result.
- As mentioned above, GPT-3 is a very capable AI system relative to the current state-of-the-art. I think it is therefore one of the most relevant historical examples for understanding diffusion leading up to TAI.
- Prior work by Shevlane (2022) in The Artefacts of Intelligence: Governing Scientists' Contribution to AI Proliferation provided a great starting point for my case studies of subsequent GPT-3-like models and other research. Shevlane’s work included a case study of the publication strategies and replication attempts for GPT-3 and its predecessor, GPT-2. That work also established how unusual the publication strategies of GPT-2 and GPT-3 were, which makes the diffusion of GPT-3-like models particularly interesting.
Having said all of that, I still think that these case studies only inform a small fraction of the total understanding needed to beneficially shape diffusion. Studying other models in other domains of AI would be helpful. The connection between narrow historical case studies and the key questions about TAI is also highly uncertain. See the questions for further investigation post for my ideas on how future work can best improve our understanding.
The scope of diffusion mechanisms and factors in this sequence
- The mechanisms of diffusion that I focus on most in this sequence are open publication, replication and incremental research (for definitions of those terms, see my taxonomy of mechanisms in this section). The reason for this focus is one of practicality as well as importance, as these mechanisms were the most common and most easily identified mechanisms in my case studies.
- I expect that my methodology is biased towards cases of open publication, replication, and incremental research, especially relative to cases of theft or extortion.
- This is because these mechanisms are the most inherent to the practice of AI research. The AI research community also seems to be the largest source of public evidence about AI diffusion (in the form of papers, blog posts, GitHub repositories, and other formats).
- In contrast, information about theft, for instance, will tend to be more limited. This is because theft is illegal, and publicizing theft creates a risk of punishment or unwanted attention for the thief.
- Despite the possibility of unknown or hard-to-observe mechanisms of diffusion, the lack of evidence for those mechanisms makes me 80% confident that open publication, replication, and incremental research are the most common and most important mechanisms in my case studies.
- The mechanism of multiple discovery is also important to identify, but I expect it to be more difficult to identify. As such, my conclusions about multiple discovery are more uncertain than open publication, replication, and incremental research.
- The extent to which a case of incremental research is based upon an existing machine learning result was determined case-by-case in my research. I tried to determine the extent to which a result is directly influenced by some other result, versus being independently discovered and based on earlier research (i.e., multiple discovery).
- Why do I consider incremental research to be a mechanism of diffusion, when it does not strictly involve the same artifact spreading from one actor to another?
- Evidence about when, how fast, and under what conditions incremental research happens serves as (weaker) evidence about the same things for other mechanisms of diffusion, especially replication. If an actor is capable of incremental research, then they are probably also capable of replicating the original result, even if they don’t actually do so.
- I think it’s particularly important and tractable to study the recent diffusion of large language models, but these models are becoming so expensive that successful attempts at replication are increasingly few. Studying the published incremental research on these models, conducted by the most well-resourced actors, is a way of compensating for the lack of replication.
- The ability to do incremental research, and the speed at which this happens, is also related to AI timelines, and how competitive the race to develop TAI will be (see the section on the relevance of AI diffusion to AI risk). This link from incremental research to some of the big questions in AI governance is part of why I think it’s important to study diffusion.
- I consider numerous accelerating factors for diffusion, such as the publishing of algorithmic details, the sponsorship of compute resources, and the open-sourcing of software artifacts and tools. To keep the scope of the project smaller and simpler, I focused on the factors that seem to be most relevant in AI research historically. I’m setting aside some possible mechanisms such as espionage, or extorting labs into sharing models/information, which are less relevant historically, even though such mechanisms (a) may in fact accelerate or alter how diffusion occurs and (b) may be more relevant in the future.
Diffusion database
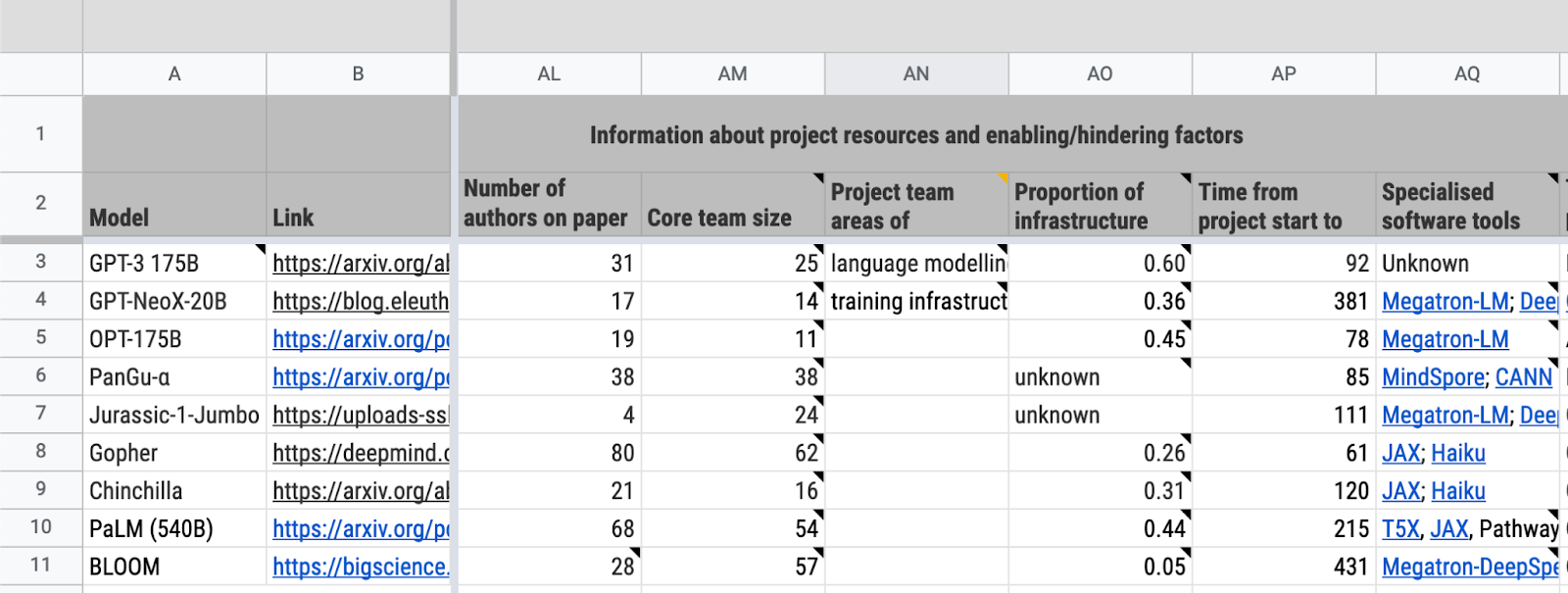
Figure 1: A screenshot of part of the database
Overview
A core component of my research on large language model diffusion was this database:
Diffusion trends for GPT-3-like models
The database organizes information that helps understand how GPT-3-like models have diffused among different actors. The fields in the database are broadly categorized by:
- Key information about the model and the project behind it (e.g., affiliations, publication date)
- Release strategy and publicity about the system (e.g., whether the trained model weights were open-sourced, the rationale for the release strategy)
- Information about project resources and any notable accelerating or hindering factors in the model’s development (e.g., training cost, training compute sponsors)
- Other relevant information (e.g., the hardware used for training)
A lot of information in the database is sourced from the Parameter, Compute and Data Trends in Machine Learning database (henceforth “the PCD database”).
Case study selection process
To search for GPT-3-like models, I filtered the PCD database by the “Language” domain and “Training compute” greater than 1E+23 FLOP, then manually checked which models were densely vs. sparsely gated (see footnote 4), and then manually prioritized the resulting list of models according to various other factors. I subsequently heard from various people about other GPT-3-like models or attempts to produce them. I also asked Connor Leahy—who co-founded the independent research collective EleutherAI with an aim of replicating GPT-3—about GPT-3 replication attempts that he knew of. Finally, I reviewed the list of recent Chinese large language models obtained by Ding & Xiao (forthcoming). Beyond that, I did not actively search for more GPT-3-like models. Ultimately, I included not just “GPT-3-like models” but also models that seemed to result from a failed effort to produce a GPT-3-like model—namely, PanGu-α and GPT-NeoX-20B.
I ended up studying nine models in detail, based on a priority rating that took into account:
- Similarity to GPT-3
- Whether the model was a direct attempt to replicate GPT-3
- How much influence GPT-3 seemed to have on the model
- Whether the model set a new state-of-the-art
The nine models are:
- GPT-3 from OpenAI
- PanGu-α from the PanGu-α team (sometimes referred to in this sequence as PanGu-alpha)
- Gopher from DeepMind
- Jurassic-1-Jumbo from AI21 Labs
- GPT-NeoX-20B from EleutherAI
- Chinchilla from DeepMind
- PaLM (540B) from Google Research
- OPT-175B from Meta AI Research
- BLOOM (176B) from BigScience
My research drew on various facts about other large language models, but I have not studied those models in as much detail as the models above. The most notable omission from the above is probably Megatron-Turing NLG, though I still studied that case somewhat.
How data was acquired
I acquired data in the database through a combination of:
- Online sources
- Information from asking experts
- Experts included developers of large language models, AI policy researchers at AI labs, and AI governance researchers at other institutions.
- Note that for the most part, I failed to obtain relevant information from the people who were involved in developing the above-mentioned nine models. However, I did get some information directly from developers of GPT-NeoX-20B, Gopher, and BLOOM.
- Estimates based on background information that came from both written sources and expert interviews, as well as my own models of how large language model development works.
- As such, the majority of the data in the database is significantly uncertain, with some confidence intervals spanning an order of magnitude. You can find confidence intervals in the spreadsheet cell notes where applicable.
How to view and use the database
- Read the README sheet before viewing the database in the “Main data” sheet.
- Read the cell notes for context. Many cells in the database have notes (indicated by a black triangle in the upper-right corner of the cell). Hover over the cell to view the note. The cell note of a column heading explains what the column means. The notes on other cells have information about the source or the reasoning that informed the data in the cell.
- If a cell has a hyperlink, that link is the source of the data in that cell. Otherwise, assume that the data comes from the main source (provided in the "Link" column).
There are no plans to maintain the database—help would be useful
I have not made concrete plans to maintain the database in the future. However, it is possible that I will maintain and extend the database if it remains relevant to my future work. Please get in contact with me if you are interested in maintaining or extending the database in some way. It's possible that I could help connect you with funding to work on this if you're interested and a good fit.
Acknowledgements

This research is a project of Rethink Priorities. It was written by Ben Cottier. Thanks to Alexis Carlier, Amanda El-Dakhakhni, Ashwin Acharya, Ben Snodin, Bill Anderson-Samways, Erich Grunewald, Jack Clark, Jaime Sevilla, Jenny Xiao, Lennart Heim, Lewis Ho, Lucy Lim, Luke Muehlhauser, Markus Anderljung, Max Räuker, Micah Musser, Michael Aird, Miles Brundage, Oliver Guest, Onni Arne, Patrick Levermore, Peter Wildeford, Remco Zwetsloot, Renan Araújo, Shaun Ee, Tamay Besiroglu, and Toby Shevlane for helpful feedback. If you like our work, please consider subscribing to our newsletter. You can explore our completed public work here.

