Highlights
- Polymarket’s future is uncertain after it settled with the CFTC for $1.4M
- Astral Codex Ten gives out $40k to forecasting projects
- Many people, including Mathew Yglesias, write predictions for 2022.
- Eli Lifland writes the reference piece on bottlenecks to impactful forecasting
- Google reveals the existence of a gigantic new internal prediction market
- A new forecasting platform appears, Manifold Markets
Index
- Prediction Markets & Forecasting Platforms
- Long Content
- Blog Posts
- In The News
You can sign up for this newsletter on substack (a), or browse past newsletters here (a). If you have a content suggestion or want to reach out, you can leave a comment or find me on Twitter. A big hat tip goes to Nathan Young and Clay Graubard for comments and suggestions on this edition.
Prediction Markets & Forecasting Platforms
Polymarket
The US Commodity Futures Trading Commission (CFTC) has fined Polymarket $1.4M (a). For reference, Polymarket's seed funding amounted to $4M (a) and were in talks for another round at a nearly $1B valuation (a) prior to the investigation.
The order requires that Polymarket pay a $1.4 million civil monetary penalty, facilitate the resolution (i.e. wind down) of all markets displayed on Polymarket.com that do not comply with the Commodity Exchange Act (CEA) and applicable CFTC regulations, and cease and desist from violating the CEA and CFTC regulations, as charged.
With this, Polymarket's future seems now very uncertain. The Polymarket team has been mostly silent, though it recently released an update (a) as a Google doc, which promised that they were just "getting started".
To quantify this uncertainty, I asked a more experienced prediction market trader—who wishes to remain anonymous—for his probability estimate that Polymarket would be "pretty much dead". This was operationalized as there being no new markets with more than $100k in volume by November 2022. His guess ranged from 30% to 50% that it'd in fact be dead.
This is terrible news. Polymarket has recently been one of the very few real-money markets where one could find highly liquid markets on things of actual importance, like the covid pandemic. I don't tire of mentioning this ¡2008! piece (a) by several Nobel prize winners and other notable figures urging the CFTC to essentially allow these markets to exist.
[As an aside, I'll elaborate a bit on the method of elicitation, because I thought it was bloody ingenious, and it might be more standard in the future. I offered him $100 to suggest a bet on Polymarket being dead where I can take either side. He selects the odds, and is also allowed to have a spread, i.e., a difference between the bets against and the bets in favor. Then, I can choose to take the bet on either side, or to leave at that. In effect, I was paying him to potentially act as a bookie, where this costs him some effort and produces some probabilities I’m interested in as a side effect.
As a result of this process, he offered me bets ranging from 3:7 to 1:1, corresponding to between a 30% and a 50% probability of Polymarket being dead. So his revealed confidence was that the probability of it happening is in between.
This process was messier and involved some negotiation. But in the future, conditions could be standardized, e.g., instead of “a few thousands”, either side’s maximum bet could be predetermined to be $5k, as we finally agreed. One would also have to think about the policy around making this kind of bet public. In particular, there are some issues around adversarial selection, or insider trading. If I or others had some private information about whether Polymarket was going to survive, I could extract money from the other party.]
CSET-Foretell
CSET-Foretell (a) is a forecasting platform that aimed to produce policy-relevant predictions and insights to influence US policy.
Foretell is now moving from being hosted by the Center For Security and Emerging Technologies (a) (CSET) at Georgetown University, to being hosted by the "Applied Research Laboratory for Intelligence and Security" (a) (ARLIS) at the University of Maryland.
The University of Maryland is generally less prestigious than the University of Georgetown, but Maryland ranks in the top 5 for Homeland Security Graduate Schools (a). ARLIS is also one of a very few Department of Defense University Affiliated Research Centers (UARCs) (a) and the only one in the DC-Metro Area (a).
I feel bitter about this, because I had high hopes for the platform, and because I expect ARLIS to be worse than CSET according to my values. On the one hand, CSET has received $100M from OpenPhilanthropy (a) within a few years, whereas organizations similar to ARLIS historically receive one million to $50M a year (a) (page 55), and I'd expect ARLIS to receive an amount on the lower end of that range.
I'd also prefer funding which, broadly speaking, cares about people generally—like that of OpenPhil—over funding from the Department of Defense—which I'd expect would be more focused on the interests of the US alone.
On the positive side, ARLIS seems more deeply enmeshed into the US government's bureaucracy, and may have the ear (a) of Kathleen Hicks (a), a high-ranking US government official.
CSET's Michael Page also published Wisdom of the Crowd as Arbiter of Expert Disagreement (a), which outlines a methodology for using forecasts to resolve policy debates.
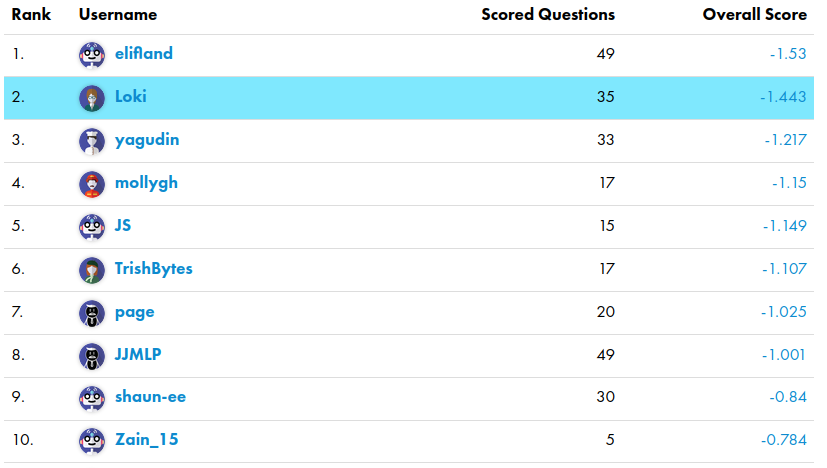
As in the first season, Samotsvety Forecasting, a team made up of Eli Lifland, Misha Yagudin, and myself, completely demolished the competition. We were around twice as good as the next-best team in terms of the relative Brier score.
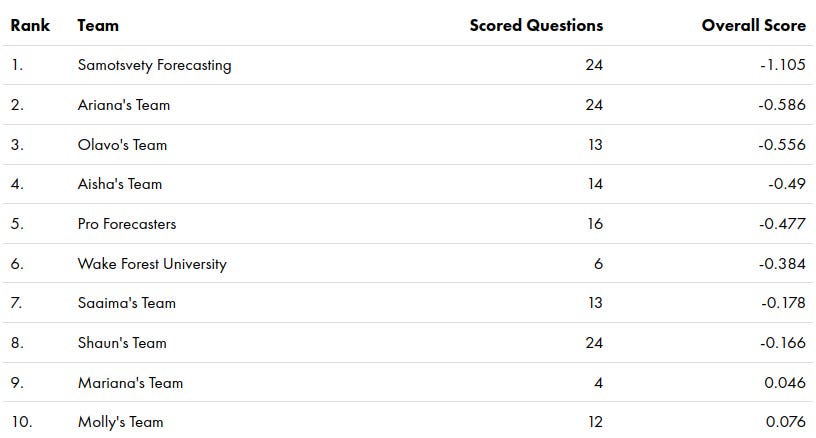
Amusingly, all three of us are in the top 3 of all time (out of 1035 contenders.)
Metaculus
SimonM highlights some comment threads from Metaculus this past December (a). They are:
- Discussion on Roe vs Wade (a), part 2 (a), part 3 (a)
- Discussion on whether or not Russia will invade Ukraine in 2022 (a), part 2 (a), part 3 (a)
- Discussion on how dangerous Omicron is (a), part 2 (a), part 3 (a)
Otherwise, the Economist partnered with Metaculus for a Global trends in 2022 (a) tournament. Tom Chivers wrote a piece on solar power for Metaculus (a).
Odds and ends
Hedgehog Markets announced their liquidity provider program (a). The idea is to use the money which prediction market participants park to generate some return, which can then be given out as a reward to the best predictors. And Hedgehog Market is looking for partners, e.g., other Solana protocols, to generate that return for them.
Although the idea is interesting and innovative, Hedgehog Markets (a) continues to focus on sports, crypto, e-sports and NFT markets. And I view these topics as not being all that valuable to predict.
Still, Hedgehog Markets has the advantage that it allows participants to bet without losing their money. If the participant finally withdraws their money after a time, the scheme could be viewed as somewhat similar to a tontine (a), or to a susu (a), i.e., as a very simple savings device.
Astral Codex Ten (a) awarded $1.55 million in grants, of which $40k (2.5%) went to forecasting related projects. These were:
- James Grugett, Stephen Grugett and Austin Chen, $20,000, for a new prediction market—Manifold Markets. If every existing prediction market is Lawful Good, this team proposes the Chaotic Evil version: anyone can submit a question, questions can be arbitrarily subjective, and the resolution is decided by the submitter, no appeal is allowed
- Nikos Bosse, $5,000, to seed a wiki about forecasting
- Nathan Young, $5,000, to fund his continued work writing Metaculus questions and trying to build bridges between the forecasting and effective altruist communities
- Nuño Sempere (myself), $10,000, to fund his continued work on metaforecast.org and the @metaforecast bot.
Manifold Markets (a) was previously called Mantic Markets because of a section on Astral Codex Ten named "Mantic Mondays", but recently changed its name to allow that section to remain impartial. I find the platform rather neat.
In particular, most other prediction markets/forecasting platforms—like Hypermind, CultivateLabs, Betfair, Metaculus, etc.—were mostly programmed in or before 2015, with the web technologies of the time. Unlike them, Manifold Markets looks and feels more modern, which is something that I appreciate a lot as a heavy user of various forecasting platforms.
Moreover, the team has a couple of ex-Googlers, so beating everyone else in the technology front seems like a plausible pathway to dominance. I encourage people to give it a try (a). Some of the markets are entertaining, and for now, it's just play money.
For those curious, an explanation of Manifold Markets' tricky dynamic parimutuel betting system can be found here (a).
In the interest of transparency, and because I think it's interesting in its own right, my application can be found here (a).
I applied to a large extent because Nathan Young specifically was cheerleading the embryonic capabilities of the current @metaforecast bot, and proposing new things that could be built on top of it. I realized that server costs could stack up fairly quickly, particularly in the best case scenario where a lot of people use it, as in the case of @threaderapp. And if ACX wanted to bankroll a weekend project of mine, why not.
With the benefits of hindsight, I should also have applied for more money and for more ambitious projects, and for the Quantified Uncertainty Research Institute (a), the org for which I work, rather than for hobby projects. But I forgive myself, because initially this was going to be a $200k grant round, before Vitalik Buterin and others bumped it up to $1.55M.
Lastly, it's kind of interesting how $40k feels like a significant quantity of all the funding there is for small experiments in the forecasting space. This is probably suboptimal.
Nathan Young and I are organizing a chill online meetup at 7:00 PM UTC on the 9th of February in the LessWrong online Walled Garden. The LessWrong Walled Garden is great because you can leave and join conversations as you wish, allowing better flowing conversations. The event will officially finish 2 hours after it starts, but anyone is welcome to stay later
Long Content
Eli Lifland publishes what is now the reference piece on bottlenecks to more impactful forecasting (a). It crystallizes his knowledge from a few years of his forecasting on Metaculus, CSET-Foretell and Good Judgment Open.
The data from the original Good Judgment Project is available publicly (a), and has been for some time.
Together with my co-authors Misha Yagudin and Eli Lifland, I posted a fairly thorough investigation into Prediction Markets in The Corporate Setting (a). The academic consensus seems to overstate their benefits and promisingness. Lack of good tech, the difficulty of writing good and informative questions, and social disruptiveness are likely to be among the reasons contributing to their failure. In the end, our report recommended not having company-internal prediction markets.
Dan Schwarz, who leads the below-mentioned prediction market at Google, answered on Twitter here. Ozzie Gooen, of my own Quantified Uncertainty Research Institute, left some criticisms here (a), emphasizing that small experiments may nonetheless be worth it, and that experimenting with prediction setups could have large externalities if they work.
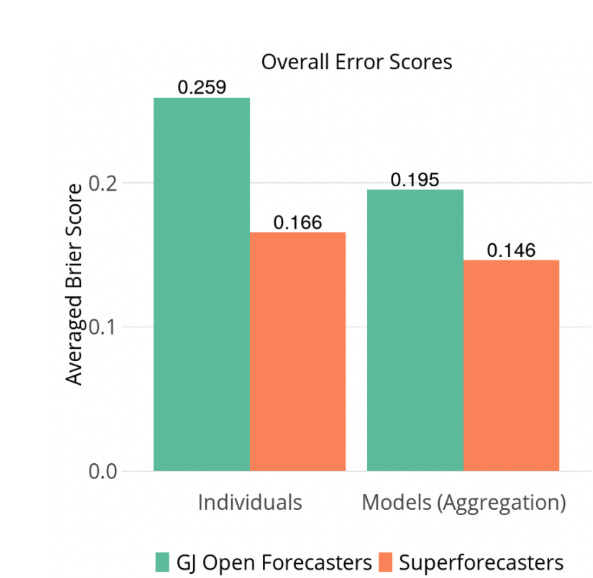
A white paper by the Good Judgment project (a) compares the performance of superforecasters vs Good Judgment Open forecasters. I recommend mostly skipping the text because of the information is contained in the charts.
The paper also doesn’t have the visceral impact of the comparison in the Superforecasting book, where the original Good Judgment project beat intelligence analysts with classified information. This time, the paper compares paid superforecasters against unpaid hobbyists. I guess I’d have liked to see a comparison between different platforms, e.g., a Good Judgment vs Metaculus or vs PredictIt head-to-head fight.
Jaime Sevilla looks at aggregating forecasts in a principled way (a), building on his previous work (a). This time, he explains a result by Neyman et al. (a), and tests it on past Metaculus data. He finds that it beats Metaculus' own prediction, as well as all other aggregation methods commonly considered.
Blog Posts
The Machine Intelligence Research Institute has published a few conversations on future AI capabilities (a). Of these, readers of this newsletter might be particularly interested in the Conversation on technology forecasting and gradualism (a).
Epidemic tracking and forecasting: Lessons learned from a tumultuous year (a) summarizes a collection of papers on the PNAS (Proceedings of the National Academy of Science). The main lessons are:
- Data was often unreliable
- It is important to understand what process generates the data.
- Mandated reporting was burdensome and inflexible
- Human behavior was hard to model.
See also Valentine's What are sane reasons that Covid data is treated as reliable? (a).
A non-magical explanation of Jeffrey Epstein (a) attempts to model Epstein's death and the organizations around it. However, see this comment (a) for pushback.
It's easy to make fun of Alex Jones tier conspiracy theories. But if we're being honest, it's really hard for any regular person to model opaque organizations like their local police department, their district attorney's office, the FBI, the NSA, the state department, or Congress. I think deep down most people are not conspiracy theorists, simply because they do not have the tools equipped to understand those organizations. Some of this is due to a lack of knowledge about what these organizations do and what their internal politics are. Some of this is due to the fact it's socially encouraged to have a non-sensibly cynical attitude when it comes to clandestine organizations, lest we be accused of being too naive by our wizened and grizzled friends.
But a lot of it is just because, by default, we no longer use the operationally important reasoning for understanding the behavior of people we actually know. Instead we feel free to shift into far-mode thinking, and posit relationships and arrangements that do not actually occur in the wild. The things our theories say about us and let us get to believe become more important than their predictive value. We don't actually see any of these grand coverups happen, but it's cool to imagine they do, especially when we get to imagine our political enemies doing it. Sometimes the long downtime between regime changes are so boring that it's easier and more exciting to just assume it's happening all the time, everywhere, right out of sight.
R Street, a libertarian policy think tank, offers an analysis of A cybersecurity forecasting platform. (a)
A new substack blogger and old Metaculus forecaster looks at ordered prediction markets (a), which might allow markets to extract probability distributions, rather than just probabilities. See also here (a) for a more academic treatment of the topic.
In the News
Google has revealed the existence of a new internal prediction market (a), with over 175,000 predictions from over 10,000 Google employees.
NeuralProphet (a) aims to be an update over Facebook's Prophet library (a), which offers time series data prediction in a box. I haven't tried it out, but it looks promising.
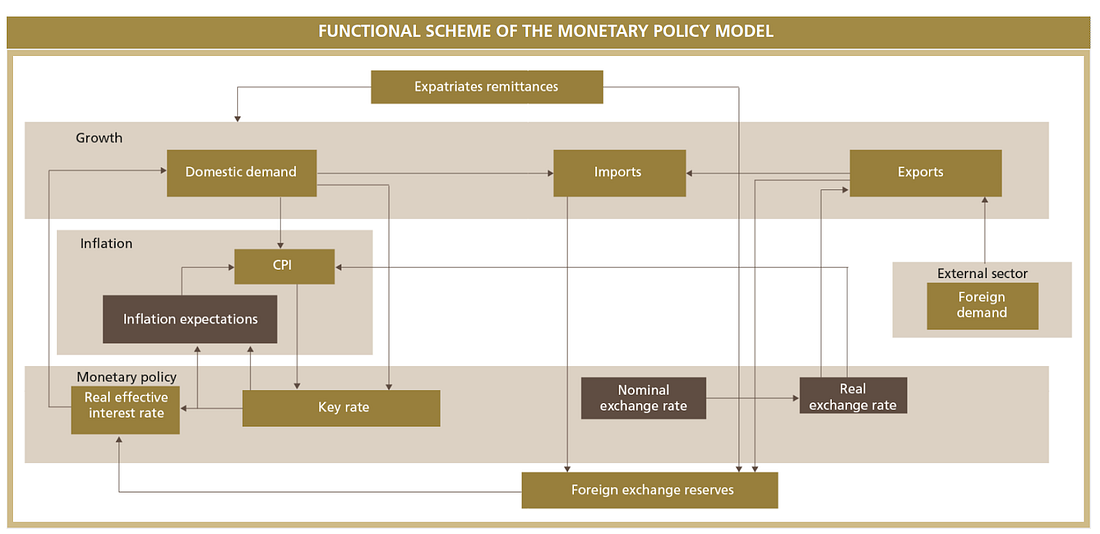
The Bank Al-Maghrib—the central bank of Morocco—has a very clearly written report on monetary policy (a). I found the international comparisons on growth, interest and inflation rates to be particularly interesting.
Some news media & individuals wrote some quantified predictions for 2022: Vox (a), UnHerd (a), The Economist (a), Ipsos (a), Matt Rickard (a), Avraham Eisenberg (a), Mathew Yglesias (a), The Atlantic Council (a), and Blackrock (a). h/t to Clay Graubard for this longer list of 2022 predictions, from which some of the aforementioned were taken. It feels like there are more of these than last year, and the Mathew Yglesias piece is by a particularly mainstream author, which might be indicative that forecasting is becoming something less niche.
I tried to get Vox to make some bets against me on Twitter, but my megaphone wasn't big enough to get their attention.
Note to the future: All links are added automatically to the Internet Archive, using this tool (a). "(a)" for archived links was inspired by Milan Griffes (a), Andrew Zuckerman (a), and Alexey Guzey (a).
I critique here in such detail because, despite all our disagreements and my worries, I love and I care.
Zvi, Thoughts on the Survival and Flourishing Fund (a)