Jamie E
Posts 23
Comments80
Hi Joel - in this case the positive sentiment towards mental health is indeed probably driven quite a bit by domestic mental health concerns. We actually provide an example or two for each cause and the mental health one notes improving or increasing access to mental health in the U.S.. Given it is the only mental health thing we have done so far in Pulse I think it would be hard to tease out with current data as you suggest.
But yes there could be opportunities to add something in upcoming rounds - feel free to DM or reach out by email to discuss more exactly what you would be looking for insights into. At face value it would probably be quite easy to compare how much people support e.g., mental health access/improvements at home, vs. as something they would support being done in lower income countries.
I can imagine support for government or charitable efforts at improving mental health in lower income settings being similar to support for general efforts to improve welfare/health in lower income settings, but it also seems possible that the current vogue for mental health (with therapy apps, ads all over etc. about its importance) could make people think it is an especially valuable way of helping abroad. That might just be cannibalizing broader GHD support even then though.
"I do think this has happened to some extent with M&E, where it has been conflated with existing EA concepts like cost-effectiveness projections." - this is an interesting observation and something that has come up in some of my own recent work, where estimating and tracking impact in expectation is perhaps mistaken as M&E as typically understood by experts in M&E. Can you share some concrete aspects of/tools from M&E you think others may be overlooking?
I also generally agree with your overall thoughs, and feel that people in EA are sometimes unwittingly unaware of entire fields that address the specific problem they believe is completely neglected.
Hi Vasco, it's an interesting though not simple question, as we're currently in the process of looking into how to understand possible impacts of research projects in general (or rather, specific projects/pieces of research, but not currently specifically/just for Pulse).
Each time we've ran Pulse, we've had a handful of specific requests from impact-focused funders or charities for items to include and received positive feedback about the value of the information for them when we've done so. To some degree when we do that, we are trusting their judgment as to the value of what they wanted to know about, not explicitly modelling it.
I've also seen some Pulse findings in wider discussions in some more and some less formal outlets over time, which suggests some interest and traction - this has perhaps been more the case with some of the AI-related findings. I think providing such information so that people are better informed in what they're discussing is valuable.
The general awareness findings were, I believe, something of an update for people/orgs in understanding how much reach EA actually has so far (including at RP), and I believe such information - naturally amongst many other pieces - has been at least discussed when talking about field building for EA or for different particular causes, and possible communication strategies. It could be that the continued polling there is less of an update each time, but for a lot of the information I think that the value can increase as we track opinions and awareness over time, such that some of the knowledge and possibly action relevant information we gain will be realised by understanding trends and how certain events or developments do - or surprisingly do not - affect public perceptions and concerns over different causes.
A less tangible impact that I think could arise over time is a generally better sense amongst decisions makers of what and how people outside of the 'EA community' actually think about the things people closer to the community care about. Whilst EA isn't for everyone, I still think it is important to have a good mental model and ideally an empirically informed understanding of where the general public is on various issues, and contributing to that understanding and awareness is also important.
A slight issue here might be something of what I see as a category error - a 'treatment resistant' mental illness is usually not considered a distinct mental illness. For example, treatment resistant depression is depression, against which multiple treatments have been tried and have failed. There is a lot of traditional mental health research funding on severe mental illness, and a lot of funding is also geared towards trying to understand why some treatments don't work for some people (i.e., some people's mental illnesses resist treatment). So in this sense, I just don't think it is neglected.
I just think this example is misapplying the Shapley values/approach - in a case in which a payment is locked in, there is nothing in the Shapley approach saying you would treat it as if it is not locked in. As a matter of principle the Shapley values are order invariant, but that is not to say that when computing Shapley values you should imagine an alternative reality in which everything is order invariant when in fact it is not. As described I think the Shapley values in this case naturally argue for the second actor to favor getting the 15 units by completing the payment for P.
Here is how I would think this situation would be computed using Shapley values:

Whereas if player 2 were to aim for just going for their single better option, it would be:

So if player 2 seeks to maximise their Shapley value, they do in fact choose the option you think that they should.
So I think it is correct that one should consider if commitments are locked in etc., but I don't think this is a critique of the Shapley approach, but rather that what is described as a 'simple application of the Shapley values' is just an incorrect application.
The cleaned data set was very nice to have access to and clear - the only thing that wasn't clear to me was whether any exclusions were actually applied on the basis of the attention checks, and what the correct answers to the attention question were, but this may be in your documentation already, I just had a fairly quick look and downloaded the csv and got going.
Thanks for the thorough response -
- indeed if the goal is about doing something to shift Chipotle/similar chains then the chicken reduction angle is unlikely to be persuasive.
- Is there any way of finding out from real data whether people who literally wouldn't go to chipotle started doing so when sofritas became a thing?
- Fair enough
- Agree with this. I could imagine that over the scale of something like Chipotle, it could be that satisfying the 'every so often' plant-based purchase, as opposed to meat, of reducetarians could be impactful and affect how much meat gets purchased overall, but it's far from clear and not something we'd be powered to detect with all but the most elaborate experiments, most likely
- That's a good point, I actually had not considered people ordering online somehow...to the extent that the study was intending to represent an online experience then yes I consider it more ecologically than I first perceived it to be
- Those studies don't really convince me as I don't think it's possible to actually change what people perceive to be real norms (or basically their schemas of how the world is), or what their friends are saying and getting excited about, or the media is reporting on, which percolates organically and affects ones worldview, with small experimental manipulations, so to this extent I think the sorts of stuff I'm talking about are very hard experimentally. Even with an online menu I think people still arrive there having already been influenced by all sorts of things, I'm not referring to explicit advertising that would in the menu or in the store specifically. [edit: but I don't think it is necessary to discuss further]
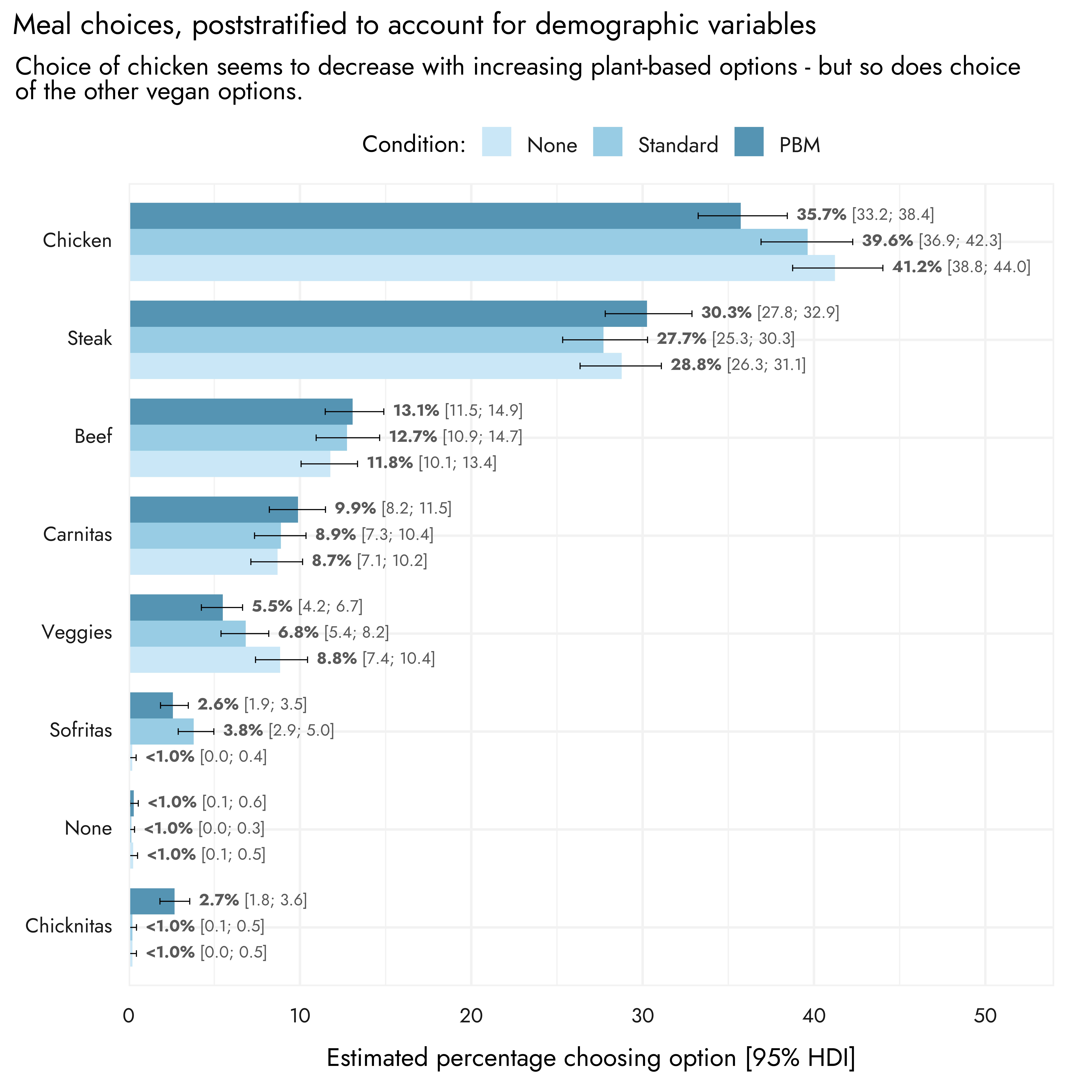
Thanks for sharing the data for the paper. Based on a fairly quick re-analysis, it appears that a decline in selection of chicken can be detected - but as you note, choice of alternative red meats tends to increase slightly, and some of the increase in selecting the new plant-based meat is driven by fewer people selecting the other veg-based options.
A few considerations as a result:
- Could it still be good to reduce purchasing of chicken, given the relatively poorer conditions of chickens and greater animals per kg of meat slughtered to get chicken vs. beef?
- Given some people who seemingly would have eaten the chicken switch to beef when a chicken alternative is on the menu, might some moral self deception be at play? People say they'll eat veggie if only there is a replacement for X. When there is a replacement for X, they can't continue eating X in good conscience but switch to Y, for which they can then say they would eat plant-based if only there were a plant-based Y alternative
- I wonder if one could see if chicken increases when an explicit replacement for beef and steak were made (or is sofritas already explicitly intended as a replacement for one of these?)
- I wonder if meat might ultimately decline if there were yet more plant-based explicit alternatives - what do you think?
- It would be particularly interesting to know the 'readiness to change' or 'intention/sympathy' towards vegetarianism - I might expect more sympathetic/genuinely ready to change people really would try the alternative out as opposed to just switching to beef
Finally, what are your thoughts on the ecological validity of the experiment? Naturally, people can't see or smell the options, as you note in the paper, but the experiment also takes place in the absence of repeat visits, advertising, and hearsay about how X or Y tastes really good, has to be tried etc. I'm not totally surprised that just adding an option to the end of a virtual menu doesn't greatly shift behavior, but that also seems a slightly reductionistic model of what plant-based advocates might expect would happen in such a situation, which might be more to do with norm shifting, decreasing difficulty enabling people to switch over time etc. I hope that does not come across as overly critical, because I'm also really pleased to see a rigorous attempt to put ideas to the test and challenge assumptions. [edit: I haven't thoroughly read you paper, so apologies if you already discuss this]
I don't think there is a claim that they are mental health interventions - the blue hue only denotes they were evaluated by HLI, probably for the sake of comparison with other interventions. For example, Fortify Health is also in there and I don't think the authors are under the illusion that it's a mental health intervention