
Jonas Hallgren 🔸
Bio
Participation5
Co-Director of Equilibria Network: https://eq-network.org/
I try to write as if I were having a conversation with you in person.
I would like to claim that my current safety beliefs are a mix between Paul Christiano's, Andrew Critch's and Def/Acc.
Posts 18
Comments92
Topic contributions3
Both equanimity and the intense wanting for relief of all beings can be true at the same time.
Dzogchen for example is all about bringing equanimity into daily experiences so that you can act from a state of peaceful existence even in something like an argument.
For me being open induces a sense of loving everything in the world and from that state a deep sense of wanting to act is born.
I think you might find it interesting to talk to someone from the Tibetan Buddhism tradition or a non-dual tradition like the thai forest tradition.
No-self is completely different there. There are different kinds of practices with different outcomes, the Burmese tradition which Ingram practiced is one of many.
You're already perfect but you could be a little better. If there's no thing which is fully real to harm you then there are a lot more things that you can do in the name of loving kindness.
I like this a lot!
One of the things you're pointing at here is the local planning and long-term goal setting that allows you to be robust to local changes in your plans. You then go on to point at this sort of robustness picture where you're essentially asking about how we deal with moral uncertainty and second order consequences of our actions in a highly changeable world.
I think this actually points at a specific modelling picture for what you're thinking about.
I like to think about institutions and similar as generators and changes of a sort of continous coordination landscape. They're essentially the things that set the local incentive landscape or in my head they're ways of changing the contour lines of an underlying phase space that things move in.
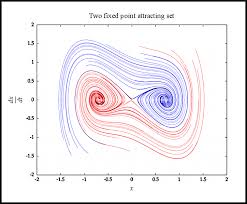
When you're asking if we can create institutions or good governance escape velocity you're essentially asking whether you can create a spiral that is strong enough to external perturbation that it keeps spiralling towards good equilibria states.
There is in some sense a sort of external platonic space of cooperative mechanisms where different paths of the world lead you down different cooperative spirals. Totalitarianism is one way where you have these recursive actions that you lead down more and more towards negative states whilst something like open instituions and democracy might do something differently. The question that seems the most important for a good future imo is then how we can retain the institutions that make us robust to adversarial changes. E.g, how do we retain and improve the instituions of democracy and truth-seeking?
Another point in favor of the virtue ethics goodness spiral is that good liberal democracy improves your collective epistemics and makes it easier to steer away from bad states in the future.
Also, high plasticity moments have a very natural analogy in the phase space diagram. They're essentially points in the plane where it is a lot easier to perturb the landscape and shift it on to a new path.
There's a lot of interesting points here, nicely put!
In light of these new findings, it might be smart to reconsider the question of whether new EA parents should vaccinate their children?
From a risk-reward perspective it might be smart to create a supply side source of non-nt children? It is commonly known that vaccines cause autism and if we look at an observational study most neuro-divergent people in EA are vaccinated which I think is pretty clear evidence.
In fact according to the meta coordination forum talent survey we can see demand for neurotypical people roles go up over time and as a consequence I believe there is a strong economical demand for nts.
We can estimate an increase with 10% all cause mortality from not taking vaccines (scientific) and the counterfactual impact of being neurotypical on your ability to take on leadership and management roles naturally go up by around 30%. This is an increase in expected value of 1.17 which will make the EA community approximately 20% more effective. This is therefore one of the most counterfactually important interventions of our time.
P.S: We might want to do some authentic circling to figure out the true needs of nt people? We should probably also throw in some anonymous feedback surveys as well.
I enjoyed reading this and yet I find that in the practice of higher ambition there are some specific pitfalls that I still haven't figured out my way around.
If you've every worked a 60-70 hour work week and done it for a longer period of time, you can notice a narrowing characteristic of experience, it is as if you have blinders to what is not within your stated goals or the project you're working on. (I like to call this compression) With some of my more ambitious friends who do this more often, I find that they sometimes get lost in what they're working on. It is as if their precision of their cause area goes down and suddenly they're working on something that is a lot less effective in absolute terms (due to the difficulty of finding a good effective target) and they're carried by the local incentive gradients.
So they end up in lab automation instead of aging, developing specific medicines instead of working whole brain emulation or end up starting a SaaS multi-agent project instead of working on the safety of multi-agent systems.
I can't help but feel that in the search of ambition, it is very easy to let go of your grounded foundation and that the pull of ambition once you've started can easily carry you away from where you want to be, power changes people and all that.
I was thinking about how to round off this comment and I think my own theory about how to solve it might be interesting. I think this generally has to do with sympathetic activation in your nervous system and that when you're compressed this shows in cortisol levels, hrv and elevated heart rate during the night. This is at least my mapping on when I've become "compressed" in the past. So the theory and n = 1 experiment then says that if you can work on being really good at active recovery you can get around some of the cognitive narrowing. This might then mean that if you want to remain reflective while ambitious you might want to get good at active recovery, things such as meditation, exercise, walks, supplements and more can really help with it. You can also pretty easily track this for yourself by tracking your recovery metrics using some sort of tracker.
Are you building these things on ATProtocol (Bluesky) or where are you building it right now? I feel like there's quite a nice movement happening there with some specific tools for this sort of thing. (I'm curious because I'm also trying to build some stuff more on the deeper programming level but I'm currently focusing on open-source bridging and recommendation algorithms like pol.is but for science and it would be interesting to know where other people are building things.)
If you don't know about the ATProtocol gang, some things I enjoy here are:
- https://semble.so/
- Paper Skygest: https://bsky.app/profile/paper-feed.bsky.social/feed/preprintdigest
- (Feed on bluesky): https://bsky.app/profile/paper-feed.bsky.social/feed/preprintdigest
- AT Protocol: https://docs.bsky.app/docs/advanced-guides/atproto
Firstly, that is if you think that it isn't inevitable and that it is possible to stop or slow down, if nuclear was going to be developed anyway, that changes the calculus. Even if that is the case there's also this weird thing within human psychology where if you can point out a positive vision of something, it is often easier for people to kind of get it?
"Don't do this thing" is often a lot worse than saying something like, could you do this specific thing instead when it comes to convincing people of things. This is also true for specific therapeutic techniques like the perfect day exercise and from a predictive processing perspective this is because you're kind of anchoring your expectations around something better and it enables you to visualise things that are easier to take actions towards? You have an easier time seeing what actions that you actually have to take?
Finally, this is not likely what the underlying reasoning for why Will is doing something like the positive vision as that is more likely to be about the estimated value from improving the future versus reducing existential risk (see the following post).
I would very much be curious about mechanisms for the first point you mentioned!
For 11, I would give a little bit of pushback related to your building as a sport team metaphor as I find them a bit discongruant with each other?
Or rather the degree of growth mindset that is implied in 11th seems quite bad based on best practices within things like sport psychology and general psychology? The existent frame is like you're either elite or you're not gonna make it. I would want the frame to be like "it's really hard to become a great football player but if you put your full effort into it and give it your all, you consistently show up and put in the effort then you might make it".
I work within a specific sub-part of Cooperative AI that is quite demanding in various ways and it's only like 1 in 10 or 20 people who really get it from a existent pool of people who already understand related areas. Yet I've really got no clue who it will be and the best way to figure it out is to give my time and effort to anyone who wants to try. Of course there is an underlying resource prioritization going on but it is a lot more like a growing sports team than not?
Firstly, great post thanks for writing it!
Secondly, with regards to the quantification section:
Putting numbers on the qualities people have feels pretty gross, which is probably why using quantification in hiring is rather polarising. On the one hand, there’s some line of thinking that the different ways in which people are well and ill suited to particular roles isn’t quantifiable and if you try to quantify it you’ll just be introducing bias. On the other hand, people in favour of quantification tend to strongly recommend that you stick exactly to the ranking your weightings produced.
I just wanted to mention something that I've been experimenting a bit with lately that I think has worked reasonably well when it comes to this? One of the problems here is the overindexing on the numbers that you assign to people and taking the numbers too seriously. A way to go around taking things to seriously is play and we did an experiment where we took this seriously.
When we took mentees into our latest research program we divided people up into different D&D Classes such as "wizard", "paladin" and "engineer" based on their profiles. You're not going to be able to make a decision fully based on the experience level someone has as a "paladin", yet you're not going to feel bad using the information.
I imagine it can be a bit hard to implement in an existing organisation but I do think this degree of playfulness opens up a safety in talking about hiring decisions that wasn't there before. So I'll likely continue to use this system.
I'll post the list of classes below as well as how to evaluate their level from 1-10 if anyone is interested (you can also multi-class and experience is within a class):
Tank - Can take a bunch of work and get things done
Healer - Helps keep the team on track with excellent people management
Paladin - A leader that can heal but also take on a bunch of the operational work - generalist
Sorcerer - Communicator & creative that can magic things out into the real world intuitively
Bard - A communicator that has experience with talking with external stakeholders & writing beautiful prose about the work
Engineer - Technical person who can make all the technical stuff happen
Wizard - Organised researcher with deep knowledge in fields that can create foundational work
Diplomat - Understanding institutional design and governance structures and crafting policies and frameworks that enable coordination
Levels:
1 - Hasn’t slain rats yet - no experience
3 - Finished the sewer level - Finished undergrad + initial project in AI Safety
5 - Can fight wolves relatively well - Done with PhD + initial knowledge in AI Safety
7 - When you’re slaying an epic monster you want this person in your team - Experience with taking responsibility in difficult domains
9 - Could probably slay a dragon if they try - Wooow, this person is like so cool, god damn.
10 - Legendary expert - possible one of the best people in their field
Yeah, this makes sense to me.
My teacher from the thai forest tradition has a nice quote on this which I like. "Don't poopoo the mind"
But a pointing out instruction here for you might be something like: "is it true that you are yourself when you're self-ing?"
Who is it really who is having the experience?
There is in fact not a self nor a non-self to start with for that presumes that there is a self to relate to (emptiness of emptiness). There is no ground for reality to stand on, groundlessness...
Yada yada yada...
The tldr is that meditation can be a way for you to deeply anchor you to your emotions and that it can be a way of acting from a place that is more alive and agentic.
A deeper, rawer, and vibrant state of acting where there is so much more you can do and where the self that is effective in the world can know that peace is accessible at any point.
Hopefully that made some sense?