mic
Participation7
- Completed the Introductory EA Virtual Program
- Completed the Precipice Reading Group
- Completed the AGI Safety Fundamentals Virtual Program
- Attended an EA Global conference
- Attended an EAGx conference
- Attended more than three meetings with a local EA group
- Received career coaching from 80,000 Hours
Posts 20
Comments296
In 2018, the Center for Humane Technology's "Time Well Spent" campaign probably contributed to Apple's Screen Time and Google's Digital Wellbeing features. These features seem deliberately hampered because of how easy it is to disable the reminder for you to get off your phone. I wonder if this problem is hard to make real traction on because tech companies, especially ones that make revenue from advertisements, are actively motivated against reducing screen time.
Great piece overall! I'm hoping AI risk assessment and management processes can be improved.
Anthropic found that Claude 3 didn't trigger AI Safety Level 3 for CBRN, but gave it a 30% chance of doing so in three months
30% chance of crossing the Yellow Line threshold (which requires building harder evals), not ASL-3 threshold
The plant-based foods industry should make low-phytoestrogen soy products.
Soy is an excellent plant-based protein. It's also a source of the phytoestrogen isoflavone, which men online are concerned has feminizing properties (cf. soy boy). I think the effect of isoflavones is low for moderate consumption (e.g., one 3.5 oz block of tofu per day), but could be significant if the average American were to replace the majority of their meat consumption with soy-based products.
Fortunately, isoflavones in soy don't have to be an issue. Low-isoflavone products are around, but they're not labeled as such. I think it would be a major win for animal welfare if the plant-based foods industry could transition soy-based products to low-isoflavone and execute a successful marketing campaign to quell concerns about phytoestrogens (without denigrating higher-isoflavone soy products).
More speculatively, soy growers could breed or bioengineer soy to be low in isoflavones, like other legumes. One model for this development would be how normal lupin beans have bitter, toxic alkaloids and need days of soaking. But in the 1960s, Australian sweet lupins were bred with dramatically lower alkaloid content and are essentially ready to eat.
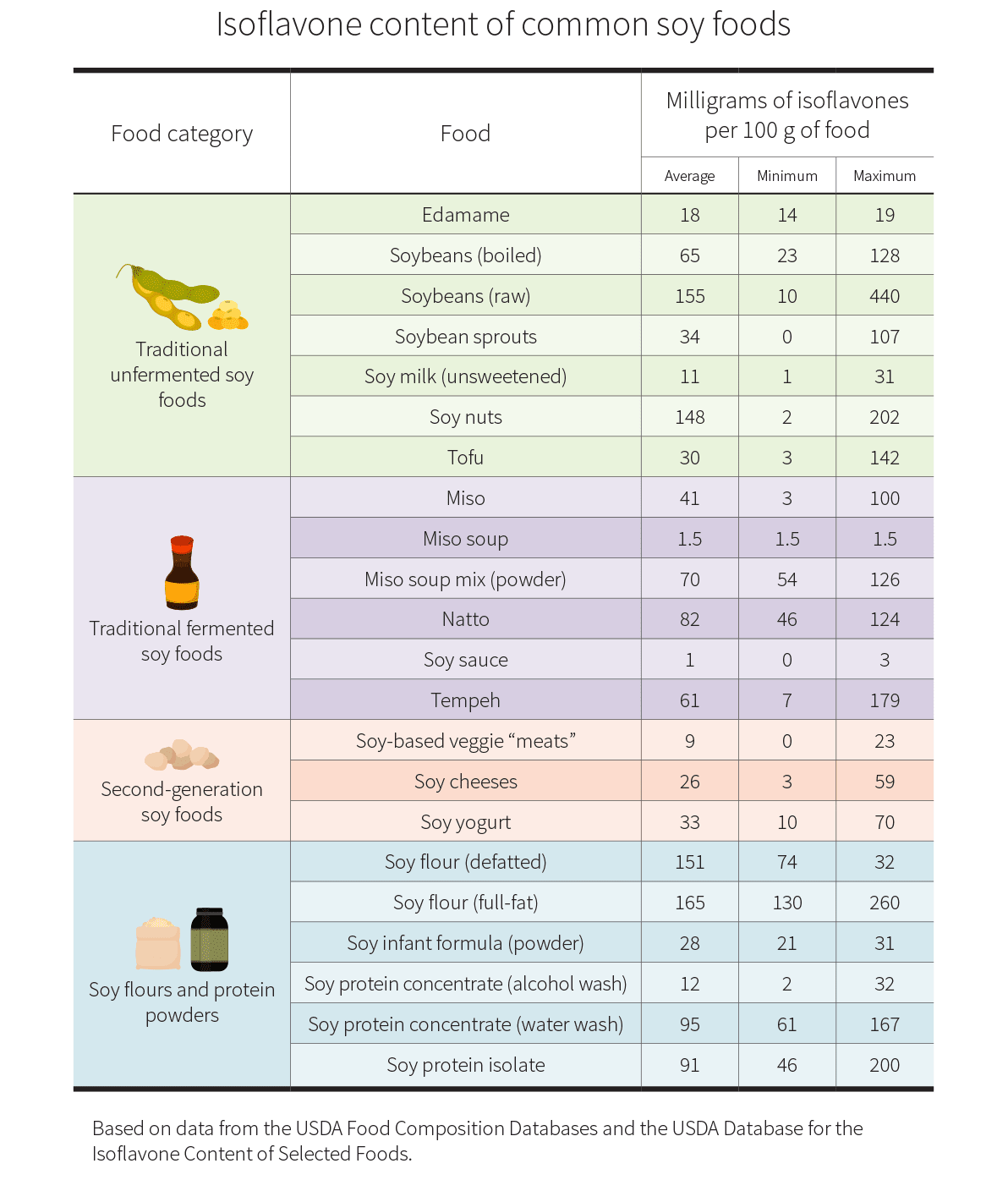
Isoflavone content varies dramatically depending on the processing and growing conditions. This chart from Examine shows that 100 g of tofu can have anywhere from 3 to 142 mg of isoflavones, and 100 mg soy protein isolate can have 46 to 200 mg of isoflavones.
Harris was the one personally behind the voluntary AI safety commitments of July 2023. Here's a press release from the White House:
The Vice President’s trip to the United Kingdom builds on her long record of leadership to confront the challenges and seize the opportunities of advanced technology. In May, she convened the CEOs of companies at the forefront of AI innovation, resulting in voluntary commitments from 15 leading AI companies to help move toward safe, secure, and transparent development of AI technology. In July, the Vice President convened consumer protection, labor, and civil rights leaders to discuss the risks related to AI and to underscore that it is a false choice to suggest America can either advance innovation or protect consumers’ rights.
As part of her visit to the United Kingdom, the Vice President is announcing the following initiatives.
- The United States AI Safety Institute: The Biden-Harris Administration, through the Department of Commerce, is establishing the United States AI Safety Institute (US AISI) inside NIST. ...
See also Foreign Policy's piece Kamala Harris's Record as the Biden Administration's AI Czar
I'm surprised the video doesn't mention cooperative AI and avoiding conflict among transformative AI systems, as this is (apparently) a priority of the Center on Long-Term Risk, one of the main s-risk organizations. See Cooperation, Conflict, and Transformative Artificial Intelligence: A Research Agenda for more details.
I wouldn't consider factory farming to be an instance of astronomical suffering, as bad as the practice is, since I don't think the suffering from one century of factory farming exceeds hundreds of millions of years of wild animal suffering. However, perhaps it could be an s-risk if factory farming somehow continues for a billion years. For reference, here is definition of s-risk from a talk by CLR in 2017:
“S-risk – One where an adverse outcome would bring about severe suffering on a cosmic scale, vastly exceeding all suffering that has existed on Earth so far.”
See Ask MIT Climate: Why do some people call climate change an “existential threat”?