All of Misha_Yagudin's Comments + Replies
(From an email.) Some questions I am interested in:
-
What's the size of alexithymia (A)?
-
Does it actually make MH issues more likely or more severe? This mashes a few plausible claims and needs to be disentangled carefully, e.g., (a) given A, does MH more likely to be developed in the first place; (b) given MH, will A (even if acquired as a result of MH) make MH issues last longer or be worse? A neat casual model might be helpful here, separating A acquired with MH vs. A pre-existing to MH.
-
How treatable is A? Does treating A improves MH? Is there any
Yes, the mechanism is likely not alexithymia directly causing undesirable states like trauma but rather diminishing one's ability to get unstack given that traumatic events happened.
Ah, I didn't notice the forecasting links section... I was thinking of adding a hyperlink to the question to the name of the platform at the highlighted place.
Also, maybe expanding into the full question when you hover over the chart?
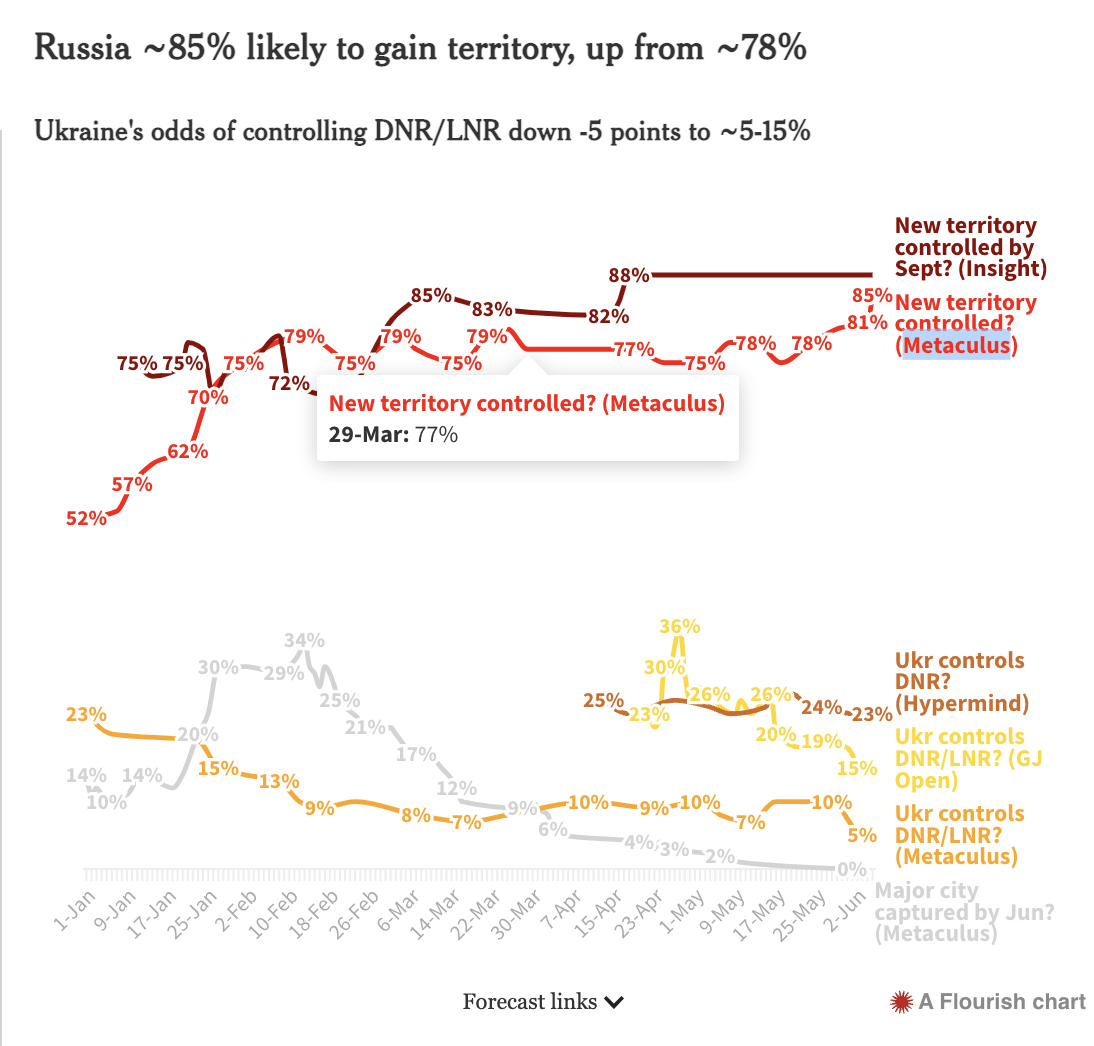
I think this is great!
https://funds.effectivealtruism.org/funds/far-future might be a viable option to get funding.
As for suggestions,
- maybe link to the markets/forecasting pools you use for the charts like this "… ([Platform] (link-to-the-question))?
- I haven't tested, but it would be great for links to your charts to have snappy social media previews.
If you think there is a 50% chance that your credences will say go from 10% to 30%+. Then you believe that with a 50% probability, you live in a "30%+ world." But then you live in at least a 50% * 30%+ = 15%+ world rather than a 10% world, as you originally thought.
FWIW, different communities treat it differently. It's a no-go to ask for upvotes at https://hckrnews.com/ but is highly encouraged at https://producthunt.com/.
So it's fair to say that FFI-supers were selected and evaluated on the same data? This seems concerning. Specifically, on which questions the top-60 were selected, and on which questions the below scores were calculated? Did these sets of questions overlap?
...The standardised Brier scores of FFI superforecasters (–0.36) were almost perfectly similar to that of the initial forecasts of superforecasters in GJP (–0.37). [17] Moreover, even though regular forecasters in the FFI tournament were worse at prediction than GJP forecasters overall (probably due to no
Hey, I think the fourth column was introduced somehow… You can see it by searching for "Mandel (2019)"
More as food for thought... but maybe "broad investor base" is a bit of exaggeration? Index funds are likely to control a significant fraction of these corporations, and it's unclear if the board members they appoint would represent ordinary people. Especially when owning ETF != owning actual underlying stocks.
From an old comment of mine:
...Due to the rise of index funds (they "own" > 1/5 of American public companies), it seems that an alternative strategy might be trying to rise in the ranks of firms like BlackRock, Vanguard, or SSGA. It's not unprecede
The table here got all messed up. Could it be fixed?
Thanks for highlighting Beadle (2022), I will add it to our review!
I wonder how FFI Superforecasters were selected? It's important to first select forecasters who are doing good and then evaluate their performance on new questions to avoid the issue of "training and testing on the same data."
How much of the objection would be fixed if Windfall Clause required the donations to be under the board's oversight?
Thank you, Hauke, just contributed an upvoted to the visibility of one good post — doing my part!
Alternatively, is there a way to apply field customization (like hiding community posts and up-weighting/down-weighting certain tags) to https://forum.effectivealtruism.org/allPosts?
A random thought. Philippines is famous for having a flourishing personal/executive assistant industry (e.g., https://www.athenago.com/). I guess there is a demand for assistants who are engaged in EA and know EA culture; IIRC, people who listed themselves at https://pineappleoperations.org/ were overbooked sometime ago. Have you thought about that as a recommended career path?
Thank you! We agree and [...], so hopefully, it's more informative and is not about edge cases of Turing Test passing.
We chose to use an imperfect definition and indicated to forecasters that they should interpret the definition not “as is” but “in spirit” to avoid annoying edge cases.
I've preregistered a bunch of soft expectations about the next generation of LLMs and encouraged others in the group to do the same. But I don't intend to share mine on the Forum. I haven't written down my year-by-year expectations with a reasonable amount of detail yet.
The person in charge of the program should be unusually productive/work long hours/etc. because otherwise, they would lack the mindset, tacit knowledge, and intuitions that go into having an environment optimized for productivity. E.g., most people undervalue the time and time of others and hence significantly underinvest in time-saving/convenience/etc. stuff at work.
(Sorry if mentioned above; haven't read the post.)
If you think that movement building is effective in supporting the EA movement, you need to think that the EA movement is negative. I honestly can't see how you can be very confident in the latter. Skrewing things up is easy; unintentionally messing up AI/LTF stuff seems easy and given high-stakes causing massive amounts of harm is an option (it's not an uncommon belief that FLI's Puerto Rico conferences turned out negatively, for example).
I read it, not as a list of good actors doing bad things. But as a list of idealistic actors [at least in public perception] not living up to their own standards [standards the public ascribes to them].
Looking back on my upvotes, a surprisingly few great posts this year (< 10 if not ~5). Don't have a sense of how things were last year.
Thanks, I wasn't aware of some of these outside my cause areas/focus/scope of concern. Very nice to see others succeeding/progressing!
Given how much things are going on in EA these days (I can't keep up even with the forum) might be good to have this as a quarterly thread/post and maybe invite others to celebrate their successes in the comments.
If Global Health Emergency is meant to mean public health emergency of international concern , then the base rate is roughly 45% = 7 / 15.5: declared 7 times, while the appropriate regulation come into force in mid-2007.
Well, yeah, I struggle with interpreting that:
- Prescriptive statements have no truth value — hence I have trouble understanding how they might be more likely to be true.
- Comparing "what's more likely to be true" is also confusing as, naively, you are comparing two probabilities (your best guesses) of X being true conditional on "T " and "not T;" and one is normally very confident in their arithmetic abilities.
- There are less naive ways of interpreting that would make sense, but they should be specified.
- Lastly and probably most importantly, a "probability
I am quite confused about what probabilities here mean, especially with prescriptive sentences like "Build the AI safety community in China" and "Beware of large-scale coordination efforts."
I also disagree with the "vibes" of probability assignment to a bunch of these, and the lack of clarity on what these probabilities entail makes it hard to verbalize these.
Apologies for maybe sounding harsh: but I think this is plausibly quite wrong and nonsubstantive. I am also somewhat upset that such an important topic is explored in a context where substantial personal incentives are involved.
One reason is that the post that gives justice to the topic should explore possible return curves, and this post doesn't even contextualize betting with how much money EA had at the time (~$60B)/has now(~$20B) until the middle of the post where it mentions it in passing: "so effectively increase the resources going towards them by m...
Hi Misha — with this post I was simply trying to clarify that I understood and agreed with critics on the basic considerations here, in the face of some understandable confusion about my views (and those of 80,000 Hours).
So saying novel things to avoid being 'nonsubstantial' was not the goal.
As for the conclusion being "plausibly quite wrong" — I agree that a plausible case can be made for both the certain $1 billion or the uncertain $15 billion, depending on your empirical beliefs. I don't consider the issue settled, the points you're making are interesti...
Interesting thread on early RAND culture: https://twitter.com/jordanschnyc/status/1593294746725756929
Yes, more broadly, I think that we should think about governance more… I guess there are a bunch of low-hanging fruits we can import from the broader world, e.g., someone doing internal-to-EA investigative journalism could have unraveled risks related to FTX/Alameda leadership or just did an independent risk analysis (e.g., this forecasting question put the risk of FTX default at roughly 8%/yr — I am not sure betters had any private information, I think just base-rates give probability around 10%).
Great! I think you missed a few from newer ones from https://ftxfuturefund.org/all-grants/?_area_of_interest=epistemic-institutions
I think the value of information is really high for the Future Fund. If p(doom) is really high (e.g., the largest prize is claimed), they might decide to almost exclusively focus on AI stuff — this would be a major organizational change that (potentially/hopefully) would help with AI risk reduction quite a bit.
I don't think your argument reflects much on the importance of forecasting. E.g., it might be the case that forecasting is much more important than whatever experts are going (in absolute terms), but nonetheless, experts should do their things because no one else can substitute them. (To be clear, this is a hypothetical against the structure of the argument.)
I think it's best to access the value of information you can get from forecasting directly.
Hopefully, we can make forecasts credible and communicate it to sympathetic experts on such teams.
Just want to flag that "hardware" is a bit misleading, as I think people often/mostly use it as shorthand for computer hardware , especially with communities' focus on AI/compute. Maybe disambiguate it straight after TL;DR or in TL;DR.
I think CFTC has no authority over play-money internal prediction markets, so that undercuts illegality a bit.
I guess one might even experiment with structuring them as real money markets, e.g., by paying winnings as "bonuses."
do we actually have better-than-order-of-magnitude knowledge about all of these parameters except Containment?)
Sorta kinda, yes? For example, convincingly arguing that any conditional probability in Carlsmith decomposition is less than 10% (while not inflating others) would probably win the main prize given that "I [Nick Beckstead] am pretty sympathetic to the analysis of Joe Carlsmith here." + Nick is x3 higher than Carlsmith at the time of writing the report.
Seems like esketamine with "some effect in a day", a comparative lack of side effects, and lack of withdrawal issues might be an attractive option. I am curious why wasn't it on your list?
A forecast from Swift Center: https://www.swiftcentre.org/will-russia-use-a-nuclear-weapon/
Upd: seems important to note that we have an overlap of ~2 forecasters, I think.
Hey Dan, thanks for sanity-checking! I think you and feruell are correct to be suspicious of these estimates, we laid out reasoning and probabilities for people to adjust to their taste/confidence.
-
I agree outliers are concerning (and find some of them implausible), but I likewise have an experience of being at 10..20% when a crowd was at ~0% (for a national election resulting in a tie) and at 20..30% when a crowd was at ~0% (for a SCOTUS case) [likewise for me being ~1% while the crowd was much higher; I also on occasion was wrong updating x20 as a res
It would be interesting whether the forecasters with outlier numbers stand by those forecasts on reflection, and to hear their reasoning if so. In cases where outlier forecasts reflect insight, how do we capture that insight rather than brushing them aside with the noise? Checking in with those forecasters after their forecasts have been flagged as suspicious-to-others is a start.
The p(month|year) number is especially relevant, since that is not just an input into the bottom line estimate, but also has direct implications for individual planning. The plan ...
Another important consideration that is not often mentioned (here and in our forecast) is how much more/less impact you expect to have after a full-out Russia-NATO nuclear war that destroys London.
Asking forecasters about their expertise, or about their thinking patterns is not useful in terms of predicting which individuals will prove consistently accurate. Examining their behaviors, such as belief updating patterns, as well as their psychometric scores related to fluid intelligence offer more promising avenues. Arguably the most impressive performance in our study was for registered intersubjective measures, which rely on comparisons between individual and consensus estimates. Such measures proved valid as predictors of relative accuracy.
From the conclusion of this new paper https://psyarxiv.com/rm49a/
Nicole Noemi gathers some forecasts about AI risk (a) from Metaculus, Deepmind co-founders, Eliezer Yudkowsky, Paul Christiano, and Aleja Cotra's report on AI timelines.
h/t Nuño
Terri Griffith [thinks](https://econjwatch.org/File+download/1236/UnderappreciatedWorksSept2022.pdf?mimetype=pdf Research Team Design and Management for Centralized R&D is their most neglected paper. They summarize it as follows:
...It is a field study of 39 research teams within a global Fortune 100 science/technology company. As we write in the abstract, we demonstrate that “teams containing breadth of both research and business unit experience are more effective in their innovation efforts under two conditions: 1) there must be a knowledge-sharing cli
A slightly edited section of my comment on the earlier draft:
...I lean skeptical about "relative pair-wise comparisons" after participating: I think people were surprised by their aggregate estimates (e.g., I was very surprised!); I think later convergence was due to common sense and mostly came from people moving points between interventions and not from pair-wise anything;
I think this might be because I am unconfident about eliciting distributions with Squiggle. As I don't have good intuition about how a few log-normals with 80% probability between xx and
Related: https://www.clearerthinking.org/post/can-you-experience-enlightenment-through-sam-harris-waking-up-meditation-app