Misha_Yagudin
Posts 14
Comments269
(From an email.) Some questions I am interested in:
-
What's the size of alexithymia (A)?
-
Does it actually make MH issues more likely or more severe? This mashes a few plausible claims and needs to be disentangled carefully, e.g., (a) given A, does MH more likely to be developed in the first place; (b) given MH, will A (even if acquired as a result of MH) make MH issues last longer or be worse? A neat casual model might be helpful here, separating A acquired with MH vs. A pre-existing to MH.
-
How treatable is A? Does treating A improves MH? Is there any research (esp. RCT) on this? Does this depends on subgroups, e.g., A acquired with MH vs. A pre-existing to MH vs. A without MH…
-
How would treating A fit into the MH treatment landscape? Can it be integrated with ongoing MH efforts in general (like people generally seeing therapy or doing CBT with a book or an app)? Can it be integrated with existing seemingly effective solutions (e.g., https://www.charityentrepreneurship.com/our-charities incubated MH orgs or charities recommended by https://www.happierlivesinstitute.org/)?
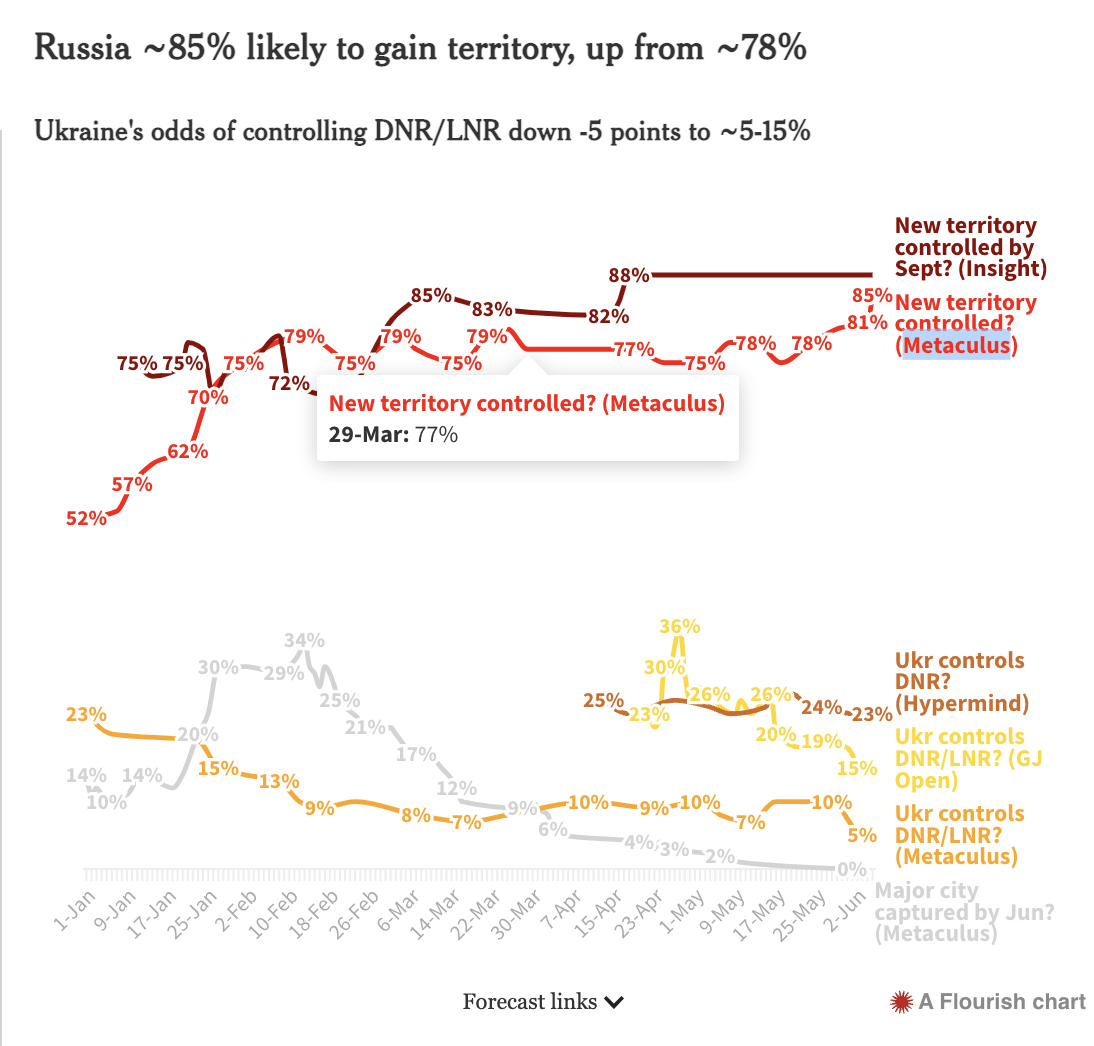
I think this is great!
https://funds.effectivealtruism.org/funds/far-future might be a viable option to get funding.
As for suggestions,
- maybe link to the markets/forecasting pools you use for the charts like this "… ([Platform] (link-to-the-question))?
- I haven't tested, but it would be great for links to your charts to have snappy social media previews.
FWIW, different communities treat it differently. It's a no-go to ask for upvotes at https://hckrnews.com/ but is highly encouraged at https://producthunt.com/.
So it's fair to say that FFI-supers were selected and evaluated on the same data? This seems concerning. Specifically, on which questions the top-60 were selected, and on which questions the below scores were calculated? Did these sets of questions overlap?
The standardised Brier scores of FFI superforecasters (–0.36) were almost perfectly similar to that of the initial forecasts of superforecasters in GJP (–0.37). [17] Moreover, even though regular forecasters in the FFI tournament were worse at prediction than GJP forecasters overall (probably due to not updating, training or grouping), the relative accuracy of FFI's superforecasters compared to regular forecasters (-0.06), and to defence researchers with access to classified information (–0.1) was strikingly similar.[18]
Related: https://www.clearerthinking.org/post/can-you-experience-enlightenment-through-sam-harris-waking-up-meditation-app