Comments
Thank you for writing this overview! I think it's very useful. A few notes on the famous "30%" claim:
- Part of the problem with fully understanding the performance of IC analysts is that much of the information about the tournaments and the ICPM is classified.
- What originally happened is that someone leaked info about ACE to David Ignatius, who then published it in his column. (The IC never denied the claim.[1]) The document you cite is part of a case study by MITRE that's been approved for public release.
One under-appreciated takeaway that you hint at is that prediction markets (rather than non-market aggregation platforms) are poorly suited to classified environments. Here's a quote from a white paper I co-wrote last year:[2]
"Prediction markets are especially challenging to implement in classified environments because classified markets will necessarily have large limitations on participation, requiring the use of algorithmic correctives to solve liquidity problems. Good liquidity, like that of a well-functioning stock market, is difficult to achieve in prediction markets like the ICPM, requiring prediction markets to have corrective tools like setting liquidity parameters and using automated market makers, which attempt to simulate efficient market behavior in electronic prediction markets."
More broadly, I would like to push back a little against the idea that your point 3(a) ( whether supers outperform IC analysts) is really much evidence for or against 3 (whether supers outperform domain experts).
First, the IARPA tournaments asked a wide range of questions, but intelligence analysts tend to be specialized. If you're looking at the ICPM, are you really looking at the performance of domain experts? Or are you looking at e.g. an expert on politics in the Horn of Africa trying to forecast the price of the Ruble? On the one hand, since participants self-selected which questions they answered, we might expect domain experts to stick to their domain. On the other, analysts might have seen it as a "game," a "break," or "professional development" -- in short, an opportunity to try their hand something outside their expertise. The point is that we simply don't know whether the ICPM really reflects "expert" opinion.
Second, I am inclined to believe that comparisons between IC analysts and supers may tell us more about the secrecy heuristic than about forecaster performance. From the same white paper:
"Experimental research on using secrecy as a heuristic for informational quality demonstrates that people tend to weigh secret information more heavily than publicly available information, viewing secret information as higher quality than public information.[3] Secrecy does matter, especially in situations where information asymmetry exists, but a pervasive secrecy bias may negatively affect the accuracy of a classified crowd in some cases."
I personally see much of the promise of forecasting platforms not as a tool for beating experts, but as a tool for identifying them more reliably (more reliably than by the usual signals, like a PhD).
- ^
Tetlock discusses this a bit in Chapter 4 of Superforecasting.
- ^
Keeping Score: A New Approach to Geopolitical Forecasting, https://global.upenn.edu/sites/default/files/perry-world-house/Keeping%20Score%20Forecasting%20White%20Paper.pdf.
- ^
Travers et al., "The Secrecy Heuristic," https://www.jstor.org/stable/43785861.
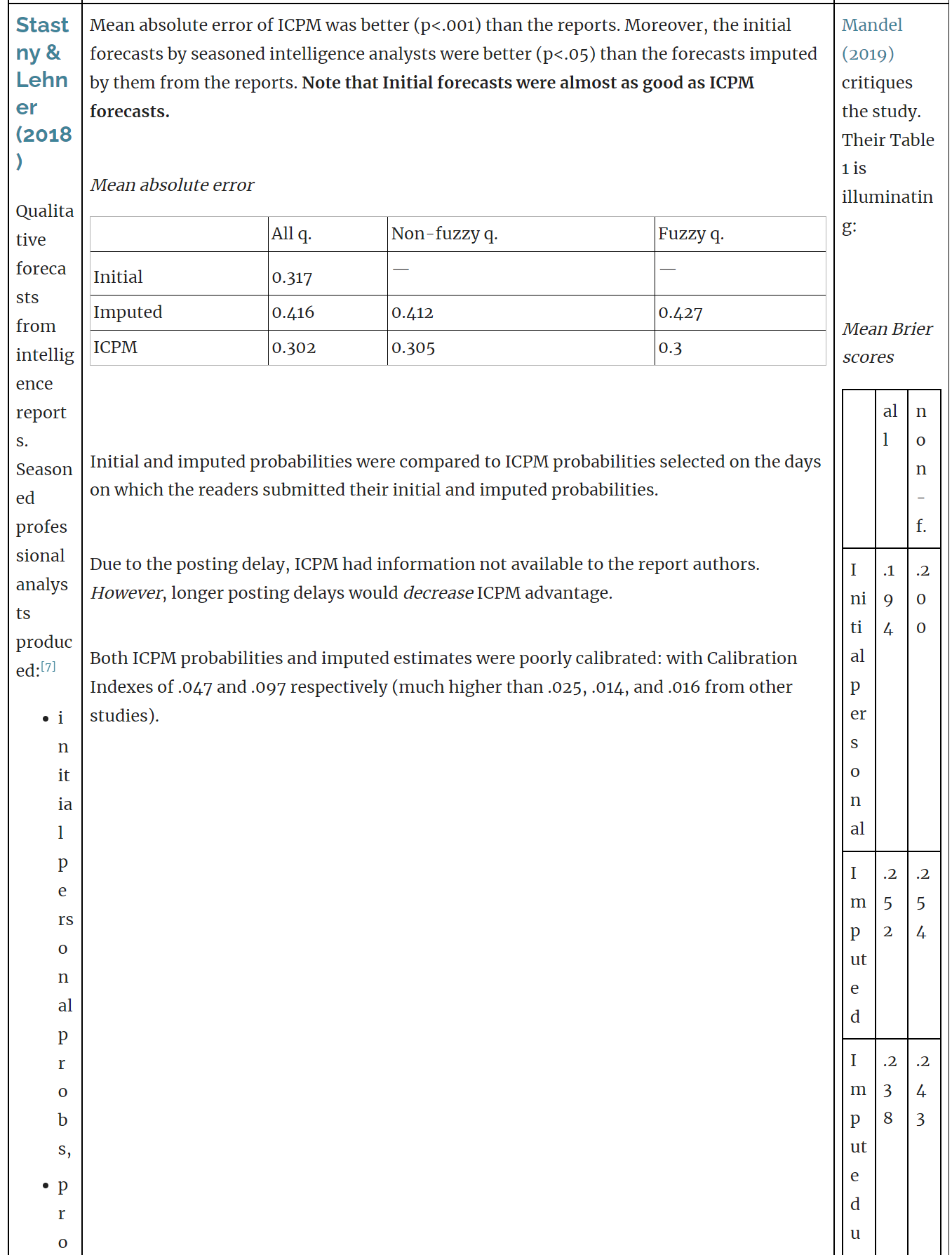




Interesting side-finding: prediction markets seem notably worse than cleverly aggregated prediction pools (at least when liquidity is as low as in the play markets). Not many studies, but see Appendix A for what we've found.