All of Neel Nanda's Comments + Replies
I'm sympathetic to the argument that it would be hard to operationalise a salary sacrifice pledge in ways that are hard to game, but true to the spirit of it.
But I feel annoyed that the tone of the FAQ and Luke's comment is not "this is a meaningful flaw in the pledge, we don't see a good way to fix it, but acknowledge it creates bad incentivises". Eg it seems terrible that the FAQ frames this as "resigning from your pledge", which I consider to have strong connotations of giving up or failing.
...In many cases, the above conclusion is based on misunderstand
If your non profit will eventually be extremely cost effective, and donations now help it reach that point, then that would make donations now highly cost effective. Of course, you're likely positively biased in favour of your non profit, so could easily be wrong in this assessment, but I am generally pro people making high conviction altruistic bets with their donations
More importantly, you are, in fact, choosing to take a lower salary in order to spend your labour on your non profit. This means you are choosing actions that lead to you not donating to ot...
Wow, that's a terrible policy IMO, and the linked forum comment feels like it totally misses the point - I personally think Quinn should go ahead and use the diamond emoji if he's confident he would be earning far more if he wasn't making altruistic career choices.
GWWC shouldn't try to attach a sense of status and altruism to the diamond emoji and then tell people they need to do less good if they want to keep it, that seems deeply against the principles of EA to me, and the incentives we should create as a functional community of altruists
EDIT: Do the peo...
I disagree voted, because I don't think it is a terrible policy / think it is a hard problem and they've solved it in probably the most reasonable way.
I think that it probably isn't perfect and has a lot of issues, but pledged donations are counterfactual (no one would donate otherwise), while doing a direct work role is not as clearly counterfactual (the organization would usually probably hire someone else, but maybe they'd be less good than you, etc). I think that feels messy to litigate properly - in some cases doing direct work is way better than the ...
As far as I'm aware, coefficient giving may slightly adjust which global health causes they support based on how neglected those are, but it's less than a 1:1 effect, and the size of the global health funding pool at CG is fairly fixed. And there are a bunch of people dying each year, especially given the foreign aid cuts, who would not die if there was more money given to global health stuff, including GiveWell top charities (if nothing else, GiveDirectly seems super hard to saturated). So I don't really see much cause for despondency here, your donations...
As this person seems very worried about counterfactuals, I should probably point out that the All Grants Fund does still make substantial grants to the Top Charities because they don't get enough granting opportunities that are reliably estimated as more effective than a top charity, so on the margin your donations are equivalent.
This may change in future - GiveWell are investigating lots more scalable grants in things like water treatment and humanitarian contexts.
Note that Dominic Cummings, one of the then most powerful men in the UK, [credits the rationality community] (https://x.com/dominic2306/status/1373333437319372804) for convincing him that the UK needed to change its coronavirus policy (which I personally am very grateful for!). So it seems unlikely to have been that obvious
What do you mean by giving to Manifund's regranting program? It's not one place to donate to. It's a bunch of different people who get regranting budgets. You can give to one of those people, but how the money gets used depends a ton on who, which seems important
If you're looking for something x risk related then I think something like the Longview emerging challenges fund is better https://www.longview.org/fund/emerging-challenges-fund/
My understanding is that Coefficient remains excited about recommending us to donors, but recently confirmed with Good Ventures that we're not a good fit for Good Ventures' specific preferences at the moment.
I'm afraid that I can't speak to Good Ventures' reasons apart from noting that they evidently didn't change Coefficient's decision to recommend us to their other donors.
I was surprised to see that you are US tax deductible (via every) but not UK tax deductible, given that you are a uk-based charity. I assume this is downstream of different levels of non-profit bureaucracy in the different countries? I would recommend explicitly flagging this early in the post as this is a deal breaking factor for many medium sized donors and if this was a constraint for me, I would have filtered exactly incorrectly
I'm happy to confirm that we can now accept Gift Aid (tax-deductible) donations from the UK, via this page on Giving What We Can's donation platform.
EDIT 1st Dec 2025: I'm happy to confirm that we can now accept Gift Aid (tax-deductible) donations from the UK, via this page on Giving What We Can's donation platform.
--
Great nudge, thanks Neel! I've updated the post and webpages to make this clearer now.
Extra notes:
- It's likely that we'll have an online platform for allowing UK donors to fund us tax-deductibly / with Gift Aid later this year or in early 2026. If anyone would like to be notified if/when this becomes the case, please fill in this form [link removed].
- If anyone would like to make a substan
I struggle to imagine Qf 0.9 being reasonable for anything on TikTok. My understanding of TikTok is that most viewers will be idly scrolling through their feed, watch your thing for a bit as part of this endless stream, then continue, and even if they decide to stop for a while and get interested, they still would take long enough to switch out of the endless scrolling mode to not properly engage with large chunks of the video. Is that a correct model, or do you think that eg most of your viewer minutes come from people who stop and engage properly?
Innocent until proven guilty is a fine principle for the legal system, but I do not think it is obviously reasonable to apply it to evaluating content made by strangers on the internet. It is not robust to people quickly and cheaply generating new identities, and new questionably true content. Further, the whole point of the principle is that it's really bad to unjustly convict people, along with other factors like wanting to be robust to governments persecuting civilians. Incorrectly dismissing a decent post is really not that bad.
Feel free to call discri...
I empathise but strongly disagree. AI has lowered the costs of making superficially plausible but bad content. The internet is full of things that are not worth reading and people need to prioritise.
Human written writing has various cues that people are practiced at identifying that indicate bad writing, and this can often be detected quickly, eg seeming locally incoherent, bad spelling, bad flow, etc. These are obviously not perfect heuristics, but convey real signal. AI has made it much easier to avoid all these basic heuristics, without making it much e...
Your points seem pretty fair to me. In particular, I agree that putting your videos at 0.2 seems pretty unreasonable and out of line with the other channels - I would have guessed that you're sufficiently niche that a lot of your viewers are already interested in AI Safety! TikTok I expect is pretty awful, so 0.1 might be reasonable there
Agreed with the other comments for why this is doomed. The thing closest to this that I think might make sense, is something like, "conditioned on the following assumptions/worldview we estimate that this intervention for an extra million dollars can have the following effect". I think that anything that doesn't acknowledge the fact that there are enormous fundamental cruxes here is pretty doomed. but that there might be something productive about clustering the space of worldviews and talking about what makes sense by the lights of each
My null hypothesis is that any research field is not particularly useful until proven otherwise. I am certainly not claiming that all economics research is high quality, but I've seen some examples that seemed pretty legit to me. For example, RCTs on direct cash transfers seem pretty useful and relevant to EA goals. And I think tools like RCTs are a pretty powerful way to find true insights into complex questions.
I largely haven't come across insights from other social sciences that seem useful for EA interests. I haven't investigated this much, and I woul...
This post is too meta, in my opinion. The key reason EA discusses economics a lot more is that if you want to have true beliefs about how to improve the world, economics can provide a bunch more useful insights than other parts of the social sciences. If you want to critique this, you need to engage with the actual object level claims of how useful the fields are, how good their scientific standards are and how much value there actually is. And I didn't feel like your post spent much time arguing for this
Overrelying on simple economic models might mislead us about which policies will actually help people, while a more holistic look at the social sciences as a whole may counter that.
The papers you cite about how the minimum wage doesn't lead to a negative impact on jobs all seem like economics papers to me. What are the social science papers you have in mind that provide useful evidence that the minimum wage doesn't harm employment?
Your examples seem disanalogous to me. The key thing here is the claim that people have a lifelong obligation to their parents. Some kind of transactional "you received a bunch of upfront benefits and now have a lifelong debt", and worse, often a debt that's considered impossible to discharge
This is very different from an instantaneous obligation that applies to them at a specific time, or a universal moral obligation to not do harm to an entity regardless of your relationship with them, or an ongoing obligation that is contingent on having a certain statu...
Interesting. Does anyone do group brainstorming because they actually expect it to make meaningful progress towards solving a problem? At least when you're at a large event with people who are not high context on the problem, that seems pretty doomed. I assumed the main reason for doing something like that is to get people engaged and actually thinking about ideas and participating in a way that you can't in a very extremely large group. If any good ideas happen, that's a fun bonus
If I wanted to actually generate good ideas, I would do a meeting of people ...
[Epistemic status: argument from authority*]
I think your suggested format is a significant upgrade on the (much more common, unfortunately) "group brainstorm" set up that Ollie is criticising, for roughly the reasons he outlines; It does much better on "fidelity per person-minute".
Individual brainstorming is obviously great for this, for the reasons you said (among others).
Commenting on a doc (rather than discussing in groups of 6-8) again allows many more people to be engaging in a high-quality/active way simultaneously.
It also seems worth saying th...
When you say you doubt that claim holds generally, is that because you think that the weight of AI isn't actually that high, or because you think that AI may make the other thing substantially more important too?
I'm generally pretty sceptical about the latter - something which looked like a great idea not accounting for AI will generally not look substantially better after accounting for AI. By default I would assume that's false unless given strong arguments to the contrary.
I agree with the broad critique that " Even if you buy the empirical claims of short-ish AI timelines and a major upcoming transition, even if we solve technical alignment, there is a way more diverse set of important work to be done than just technical safety and AI governance"
But I'm concerned that reasoning like this can easily implicitly lead to people justifying incremental adaptions to what they were already doing and answering the question of, is what I'm doing useless in the light of AI, rather than the question that actually matters of, given my v...
By calling out one kind of mistake, we don't want to incline people toward making the opposite mistake. We are calling for more careful evaluations of projects, both within AI and outside of AI. But we acknowledge the risk of focusing on just one kind of mistake (and focusing on an extreme version of it, to boot). We didn't pursue comprehensive analyses of which cause areas will remain important conditional on short timelines (and the analysis we did give was pretty speculative), but that would be a good future project. Very near future, of course, if short-ish timelines are correct!
I'd argue that you also need some assumptions around is-ought, whether to be a consequentialist or not, what else (if at all) you value and how this trades off against suffering, etc. And you also need to decide on some boundaries for which entities are capable of suffering in a meaningful way, which there's wide spread disagreement on (in a way that imo goes beyond being empirical)
It's enough to get you something like "if suffering can be averted costlessly then this is a good thing" but that's pretty rarely practically relevant. Everything has a cost
Less controversial is a very long way from objective - why do you think that "caring about the flourishing of society" is objectively ethical?
Re the idea of an attractor, idk, history has sure had lot of popular beliefs I find abhorrent. How do we know there even is convergence at all rather than cycles? And why does being convergent imply objective? If you told me that the supermajority of civilization concluded that torturing criminals was morally good, that would not make me think it was ethical.
My overall take is that objective is just an incredibly st...
Idk, I would just downvote posts with unproductively bad titles, and not downvote posts with strong but justified titles. Further posts that seem superficially justified but actually don't justify the title properly are also things I dislike and downvote. I don't think we need a slippery slope argument here when the naive strategy works fine
Morality is Objective
What would this even mean? If I assert that X is wrong, and someone else asserts that it's fine, how do we resolve this? We can appeal to common values that derive this conclusion, but that's pretty arbitrary and largely just feels like my opinion. Claiming that morality is objective just feels groundless.
I agree in general, but think that titotal's specific use was fine. In my opinion, the main goal of that post was not to engage the AI 2037, which had already be done extensively in private but rather to communicate their views to the broader community. Titles in particular are extremely limited, many people only read the title, and titles are a key way people decide whether to eat on, and efficiency of communication is extremely important. The point they were trying to convey was these models that are treated as high status and prestigious should not be a...
I agree with you but I think that part of the deal here should be that if you make a strong value judgement in your title, you get more social punishment if you fail to convince readers. E.g. if that post is unpersuasive, I think it's reasonable to strong downvote it, but if it had a gentler title, I'd think you should be more forgiving.
I think A>B, eg I often find people who don't know each other in London who it is valuable to introduce. People are not as on the ball as you think, the market is very far from efficient
Though many of the useful intros I make are very international, and I would guess that it's most useful to have a broad network across the world. So maybe C is best, though I expect that regular conference and business trips are enough
I think this is reasonable as a way for the community to reflexively react to things, to be honest. The question I'm trying to answer when I see someone making a post with an argument that seems worth engaging with is: what's the probability that I'll learn something new or change my mind as a result of engaging with this?
When there's a foundational assumption disagreement, it's quite difficult to have productive conversations. The conversation kind of needs to be about the disagreement about that assumption, which is a fairly specific kind of discussion. ...
Have people recognize you right away. You don't need to tell your name to everyone
This is a VERY huge use case for me. It's so useful!
If someone is in this situation they can just take off their name tag. Security sometimes ask to see it, but you can just take it out of a pocket to show them and put it back
I just originally thought that the All Grants fund has stuff with a decent evidence base, but less certainty then the top charities. So still more certainty than most other funders in the world.
Nearly all of the charities there would fit that description so I think they were following that practice. So yes I thought they were making a mistake somewhat by their own lights, or maybe taking the fund in a bit of a different direction.
Or Maybe I was just wrong about what they were trying to do.
When I read that description I infer "make the best decision we can under uncertainty", not "only make decisions with a decent standard of evidence or to gather more evidence". It's a reasonable position to think that the TSUs grant is a bad idea or that it would be unreasonable to expect it to be a good idea without further evidence, but I feel like GiveWell are pretty clear that they're fine with making high risk grants, and in this case they seem to think this TSUs will be high expected value
What’s unique about these grants?: These grants are a good illustration of how GiveWell is applying increased flexibility, speed, and risk tolerance to respond to urgent needs caused by recent cuts to US foreign assistance. Funded by our All Grants Fund, the grants also demonstrate how GiveWell has broadened its research scope beyond its Top Charities while maintaining its disciplined approach—comparing each new opportunity to established interventions, like malaria prevention or vitamin A supplementation, as part of its grantmaking decisions.
The grants...
Related to this point, I was surprised to see this
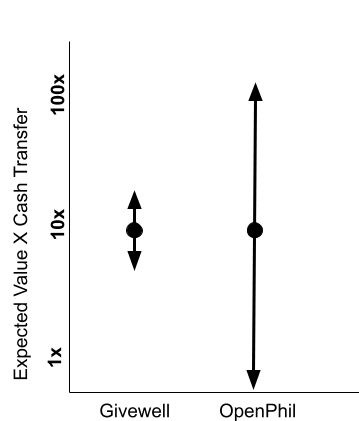
Given that GiveWell's All Grants Fund has basically the same graph

Many other grants from the All Grants Fund don't have a ton of evidence behind them and are exploratory. As an example, they funded part of an RCT on building trailbridges in Rwanda, with reasoning «While our best guess is that bridges are below the range of cost-effectiveness of programs we would recommend funding, we think there’s a reasonable chance the findings of the RCT update us toward believing this program is above our ba...
I think there's some speaking past each other due to differing word choices. Holly is prominent, evidenced by the fact that we are currently discussing her. She has been part of the EA community for a long time and appears to be trying to do the most good according to her own principles. So it's reasonable to call her a member of the EA community. And therefore "prominent member" is accurate in some sense.
However, "prominent member" can also imply that she represents the movement, is endorsed by it, or that her actions should influence what EA as a whole i...
Some takes:
- I think Holly's tweet was pretty unreasonable and judge her for that not you. But I also disagree with a lot of other things she says and do not at all consider her to speak for the movement
- To the best of my ability to tell (both from your comments and private conversations with others), you and the other Mechanize founders are not getting undue benefit from Epoch funders apart from less tangible things like skills, reputation, etc. I totally agree with your comment below that this does not seem a betrayal of their trust. To me, it seems more
I was going to write a comment responding but Neel basically did it for me.
The only thing I would object to is Holly being a "prominent member of the EA community". The PauseAI/StopAI people are often treated as fringe in the EA community and the she frequently violates norms of discourse. EAs due to their norms of discourse, usually just don't respond to her in the way she responds to others..
That's not my understanding of what happened with CAIP, there's various funders who are very happy to disagree with OpenPhil who I know have considered giving to CAIP and decided against. My understanding is that it's based on actual reasons, not just an information cascade from OpenPhil
No idea about Apart though
Seems true to me. I'd love to see more talented grant makers out there!