All of Paul_Christiano's Comments + Replies
Quantitatively how large do you think the non-response bias might be? Do you have some experience or evidence in this area that would help estimate the effect size? I don't have much to go on, so I'd definitely welcome pointers.
Let's consider the 40% of people who put a 10% probability on extinction or similarly bad outcomes (which seems like what you are focusing on). Perhaps you are worried about something like: researchers concerned about risk might be 3x more likely to answer the survey than those who aren't concerned about risk, and so in fact only 20...
I really appreciate your and @Katja_Grace's thoughtful responses, and wish more of this discussion had made it into the manuscript. (This is a minor thing, but I also didn't love that the response rate/related concerns were introduced on page 20 [right?], since it's standard practice—at least in my area—to include a response rate up front, if not in the abstract.) I wish I had more time to respond to the many reasonable points you've raised, and will try to come back to this in the next few days if I do have time, but I've written up a few thoughts here.
Yes, I'd bet the effects are even smaller than what this study found. This study gives a small amount of evidence of an effect > 0.05 SD. But without a clear mechanism I think an effect of < 0.05 SD is significantly more likely. One of the main reasons we were expecting an effect here was a prior literature that is now looking pretty bad.
That said, this was definitely some evidence for a positive effect, and the prior literature is still some evidence for a positive effect even if it's not looking good. And the upside is pretty large here since creatine supplementation is cheap. So I think this is good enough grounds for me to be willing to fund a larger study.
My understanding of the results: for the preregistered tasks you measured effects of 1 IQ point (for RAPM) and 2.5 IQ points (for BDS), with a standard error of ~2 IQ points. This gives weak evidence in favor of a small effect, and strong evidence against a large effect.
You weren't able to measure a difference between vegetarians and omnivores. For the exploratory cognitive tasks you found no effect. (I don't know if you'd expect those tests to be sensitive enough to notice such a small effect.)
At this point it seems a bit unlikely to me that there is a cl...
It seems quite likely to me that all the results on creatine and cognition are bogus, maybe I'd bet at 4:1 against there being a real effect >0.05 SD.
Unless I'm misunderstanding, does this mean you'd bet that the effects are even smaller than what this study found on its preregistered tasks? If so, do you mind sharing why?
Agree that it's easier to talk about (change)/(time) rather than (time)/(change). As you say, (change)/(time) adds better. And agree that % growth rates are terrible for a bunch of reasons once you are talking about rates >50%.
I'd weakly advocate for "doublings per year:" (i) 1 doubling / year is more like a natural unit, that's already a pretty high rate of growth, and it's easier to talk about multiple doublings per year than a fraction of an OOM per year, (ii) there is a word for "doubling" and no word for "increased by an OOM," (iii) I think the ari...
Yes, I'm not entirely certain Impossible meat is equivalent in taste to animal-based ground beef. However, I do find the evidence I cite in the second paragraph of this section somewhat compelling.
Are you referring to the blind taste test? It seems like that's the only direct evidence on this question.
It doesn't look like the preparations are necessarily analogous. At a minimum the plant burger had 6x more salt. All burgers were served with a "pinch" of salt but it's hard to know what that means, and in any case the plant burger probably ended up at least ...
The linked LW post points out that nuclear power was cheaper in the past than it is today, and that today the cost varies considerably between different jurisdictions. Both of these seem to suggest that costs would be much lower if there was a lower regulatory burden. The post also claims that nuclear safety is extremely high, much higher than we expect in other domains and much higher than would be needed to make nuclear preferable to alternative technologies. So from that post I would be inclined to believe that overregulation is the main reason for a hi...
I'm confused about your analysis of the field experiment. It seems like the three options are {Veggie, Impossible, Steak}. But wouldn't Impossible be a comparison for ground beef, not for steak? Am I misunderstanding something here?
Beyond that, while I think Impossible meat is great, I don't think it's really equivalent on taste. I eat both beef and Impossible meat fairly often (>1x / week for both) and I would describe the taste difference as pretty significant when they are similarly prepared.
If I'm understanding you correctly then 22% of the people p...
I didn't mean to imply that human-level AGI could do human-level physical labor with existing robotics technology; I was using "powerful" to refer to a higher level of competence. I was using "intermediate levels" to refer to human-level AGI, and assuming it would need cheap human-like bodies.
Though mostly this seems like a digression. As you mention elsewhere, the bigger crux is that it seems to me like automating R&D would radically shorten timelines to AGI and be amongst the most important considerations in forecasting AGI.
(For this reason I don't o...
My point in asking "Are you assigning probabilities to a war making AGI impossible?" was to emphasize that I don't understand what 70% is a probability of, or why you are multiplying these numbers. I'm sorry if the rhetorical question caused confusion.
My current understanding is that 0.7 is basically just the ratio (Probability of AGI before thinking explicitly about the prospect of war) / (Probability of AGI after thinking explicitly about prospect of war). This isn't really a separate event from the others in the list, it's just a consideration that leng...
That's fair, this was some inference that is probably not justified.
To spell it out: you think brains are as effective as 1e20-1e21 flops. I claimed that humans use more than 1% of their brain when driving (e.g. our visual system is large and this seems like a typical task that engages the whole utility of the visual system during the high-stakes situations that dominate performance), but you didn't say this. I concluded (but you certainly didn't say) that a human-level algorithm for driving would not have much chance of succeeding using 1e14 flops.
Incidentally, I'm puzzled by your comment and others that suggest we might already have algorithms for AGI in 2023. Perhaps we're making different implicit assumptions of realistic compute vs infinite compute, or something else. To me, it feels clear we don't have the algorithms and data for AGI at present
I would guess that more or less anything done by current ML can be done by ML from 2013 but with much more compute and fiddling. So it's not at all clear to me whether existing algorithms are sufficient for AGI given enough compute, just as it wasn't clea...
Are you saying that e.g. a war between China and Taiwan makes it impossible to build AGI? Or that serial time requirements make AGI impossible? Or that scaling chips means AGI is impossible?
C'mon Paul - please extend some principle of charity here. :)
You have repeatedly ascribed silly, impossible beliefs to us and I don't know why (to be fair, in this particular case you're just asking, not ascribing). Genuinely, man, I feel bad that our writing has either (a) given the impression that we believe such things or (b) given the impression that we're the type ...
You start off saying that existing algorithms are not good enough to yield AGI (and you point to the hardness of self-driving cars as evidence) and fairly likely won't be good enough for 20 years. And also you claim that existing levels of compute would be a way too low to learn to drive even if we had human-level algorithms. Doesn't each of those factors on its own explain the difficulty of self-driving? How are you also using the difficulty of self-driving to independently argue for a third conjunctive source of difficulty?
Maybe another related question:...
Maybe another related question: can you make a forecast about human-level self-driving (e.g. similar accident rates vs speed tradeoffs to a tourist driving in a random US city) and explain its correlation with your forecast about human-level AI overall?
Here are my forecasts of self-driving from 2018: https://www.tedsanders.com/on-self-driving-cars/
Five years later, I'm pretty happy with how my forecasts are looking. I predicted:
- 100% that self-driving is solvable (looks correct)
- 90% that self-driving cars will not be available for sale by 2025 (looks correct
I don't think I understand the structure of this estimate, or else I might understand and just be skeptical of it. Here are some quick questions and points of skepticism.
Starting from the top, you say:
We estimate optimistically that there is a 60% chance that all the fundamental algorithmic improvements needed for AGI will be developed on a suitable timeline.
This section appears to be an estimate of all-things-considered feasibility of transformative AI, and draws extensively on evidence about how lots of things go wrong in practice when implementing compl...
Am I really the only person who thinks it's a bit crazy that we use this blobby comment thread as if it's the best way we have to organize disagreement/argumentation for audiences? I feel like we could almost certainly improve by using, e.g., a horizontal flow as is relatively standard in debate.[1]
With a generic example below:
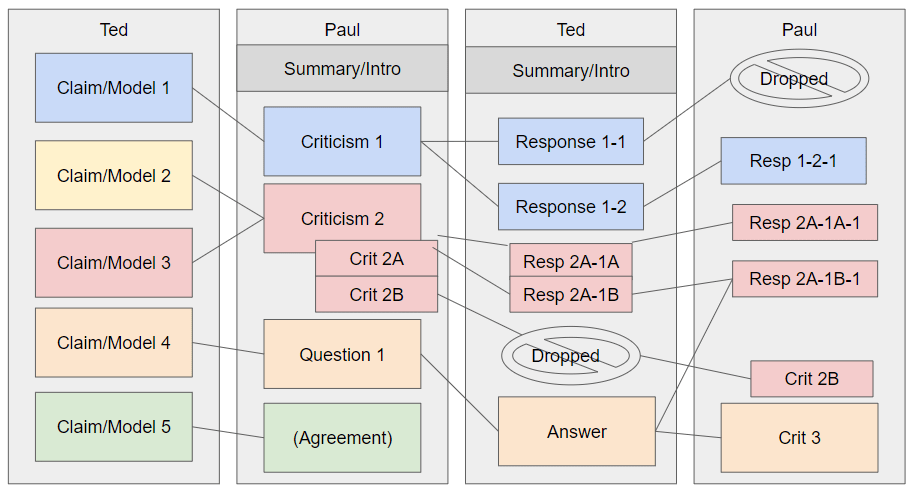
To be clear, the commentary could still incorporate non-block/prose text.
Alternatively, people could use something like Kialo.com. But surely there has to be something better than this comment thread, in terms of 1) ease of determini...
Excellent comment; thank you for engaging in such detail. I'll respond piece by piece. I'll also try to highlight the things you think we believe but don't actually believe.
Section 1: Likelihood of AGI algorithms
..."Can you say what exactly you are assigning a 60% probability to, and why it's getting multiplied with ten other factors? Are you saying that there is a 40% chance that by 2043 AI algorithms couldn't yield AGI no matter how much serial time and compute they had available? (It seems surprising to claim that even by 2023!) Presumably not that, but wh
There was a related GiveWell post from 12 years ago, including a similar example where higher "unbiased" estimates correspond to lower posterior expectations.
That post is mostly focused on practical issues about being a human, and much less amusing, but it speaks directly to your question #2.
(Of course, I'm most interested in question #3!)
I agree. When I give numbers I usually say "We should keep the risk of AI takeover beneath 1%" (though I haven't thought about it very much and mostly the numbers seem less important than the qualitative standard of evidence).
I think that 10% is obviously too high. I think that a society making reasonable tradeoffs could end up with 1% risk, but that it's not something a government should allow AI developers to do without broader public input (and I suspect that our society would not choose to take this level of risk).
Yeah, the sentence cut off. I was saying: obviously a 10% risk is socially unacceptable. Trying to convince someone it's not in their interest is not the right approach, because doing so requires you to argue that P(doom) is much greater than 10% (at least with some audiences who care a lot about winning a race). Whereas trying to convince policy makers and the public that they shouldn't tolerate the risk requires meeting a radically lower bar, probably even 1% is good enough.
I mean that 90% or 99% seem like clearly reasonable asks, and 100% is a clearly unreasonable ask.
I'm just saying that the argument "this is a suicide race" is really not the way we should go. We should say the risk is >10% and that's obviously unacceptable, because that's an argument we can actually win.
I'm pushing back against the framing: "this is a suicide race with no benefit from winning."
If there is a 10% chance of AI takeover, then there is a real and potentially huge benefit from winning the race. But we still should not be OK with someone unilaterally taking that risk.
I agree that AI developers should have to prove that the systems they build are reasonably safe. I don't think 100% is a reasonable ask, but 90% or 99% seem pretty safe (i.e. robustly reasonable asks).
(Edited to complete cutoff sentence and clarify "safe.")
I've seen this a few times but I'm skeptical about taking this rhetorical approach.
I think a large fraction of AI risk comes from worlds where the ex ante probability of catastrophe is more like 50% than 100%. And in many of those worlds, the counterfactual impact of individual developers move faster is several times smaller (since someone else is likely to kill us all in the bad 50% of worlds). On top of that, reasonable people might disagree about probabilities and think 10% in a case where I think 50%.
So putting that together they may conclude that raci...
As an analogy: consider a variant of rock paper scissors where you get to see your opponent's move in advance---but it's encrypted with RSA. In some sense this game is much harder than proving Fermat's last theorem, since playing optimally requires breaking the encryption scheme. But if you train a policy and find that it wins 33% of the time at encrypted rock paper scissors, it's not super meaningful or interesting to say that the task is super hard, and in the relevant intuitive sense it's an easier task than proving Fermat's last theorem.
Smaller notes:
- The conditional GAN task (given some text, complete it in a way that looks human-like) is just even harder than the autoregressive task, so I'm not sure I'd stick with that analogy.
- I think that >50% of the time when people talk about "imitation" they mean autoregressive models; GANs and IRL are still less common than behavioral cloning. (Not sure about that.)
- I agree that "figure out who to simulate, then simulate them" is probably a bad description of the cognition GPT does, even if a lot of its cognitive ability comes from copying human cognitive processes.
I agree that it's best to think of GPT as a predictor, to expect it to think in ways very unlike humans, and to expect it to become much smarter than a human in the limit.
That said, there's an important further question that isn't determined by the loss function alone---does the model do its most useful cognition in order to predict what a human would say, or via predicting what a human would say?
To illustrate, we can imagine asking the model to either (i) predict the outcome of a news story, (ii) predict a human thinking step-by-step about what will happe...
For what it's worth, I think Eliezer's post was primarily directed at people who have spent a lot less time thinking about this stuff than you, and that this sentence:
"Getting perfect loss on the task of being GPT-4 is obviously much harder than being a human, and so gradient descent on its loss could produce wildly superhuman systems."
Is the whole point of his post, and is not at all obvious to even very smart people who haven't spent much time thinking about the problem. I've had a few conversations with e.g. skilled Google engineers who have said things...
Smaller notes:
- The conditional GAN task (given some text, complete it in a way that looks human-like) is just even harder than the autoregressive task, so I'm not sure I'd stick with that analogy.
- I think that >50% of the time when people talk about "imitation" they mean autoregressive models; GANs and IRL are still less common than behavioral cloning. (Not sure about that.)
- I agree that "figure out who to simulate, then simulate them" is probably a bad description of the cognition GPT does, even if a lot of its cognitive ability comes from copying human cognitive processes.
The better reference class is adversarially mined examples for text models. Meta and other researchers were working on a similar projects before Redwood started doing that line of research. https://github.com/facebookresearch/anli is an example
I agree that's a good reference class. I don't think Redwood's project had identical goals, and would strongly disagree with someone saying it's duplicative. But other work is certainly also relevant, and ex post I would agree that other work in the reference class is comparably helpful for alignment
...Reader: evaluate
I don't think Redwood's project had identical goals, and would strongly disagree with someone saying it's duplicative.
I agree it is not duplicative. It's been a while, but if I recall correctly the main difference seemed to be that they chose a task with gave them a extra nine of reliability (started with an initially easier task) and pursued it more thoroughly.
think I'm comparably skeptical of all of the evidence on offer for claims of the form "doing research on X leads to differential progress on Y,"
I think if we find that improvement of X leads ...
I've argued about this point with Evan a few times but still don't quite understand his take. I'd be interested in more back and and forth. My most basic objection is that the fine-tuning objective is also extremely simple---produce actions that will be rated highly, or even just produce outputs that get a low loss. If you have a picture of the training process, then all of these are just very simple things to specify, trivial compared to other differences in complexity between deceptive alignment and proxy alignment. (And if you don't yet have such a picture, then deceptive alignment also won't yield good performance.)
Yes, I think that's how people have used the terms historically. I think it's also generally good usage---the specific thing you talk about in the post is important and needs its own name.
Unfortunately I think it is extremely often misinterpreted and there is some chance we should switch to a term like "instrumental alignment" instead to avoid the general confusion with deception more broadly.
Because they lead to good performance on the pre-training objective (via deceptive alignment). I think a similarly big leap is needed to develop deceptive alignment during fine-tuning (rather than optimization directly for the loss). In both cases the deceptively aligned behavior is not cognitively similar to the intended behavior, but is plausibly simpler (with similar simplicity gaps in each case).
For the sake of argument, suppose we have a model in pre-training that has a misaligned proxy goal and relevant situational awareness. But so far, it does not have a long-term goal. I'm picking these parameters because they seem most likely to create a long-term goal from scratch in the way you describe.
In order to be deceptively aligned, the model has to have a long enough goal horizon so it can value its total goal achievement after escaping oversight more than its total goal achievement before escaping oversight. But pre-training processes are inc...
I don't know how common each view is. My guess would be that in the old days this was the more common view, but there's been a lot more discussion of deceptive alignment recently on LW.
I don't find the argument about "take actions with effects in the real world" --> "deceptive alignment," and my current guess is that most people would also back off from that style of argument if they thought about the issues more thoroughly. Mostly though it seems like this will just get settled by the empirics.
I don't know how common each view is either, but I want to note that @evhub has stated that he doesn't think pre-training is likely to create deception:
...The biggest reason to think that pre-trained language models won’t be deceptive is just that their objective is extremely simple—just predict the world. That means that there’s less of a tricky path where stochastic gradient descent (SGD) has to spend a bunch of resources making their proxies just right, since it might just be able to very easily give it the very simple proxy of prediction. But th
Models that are only pre-trained almost certainly don’t have consequentialist goals beyond the trivial next token prediction.
If a model is deceptively aligned after fine-tuning, it seems most likely to me that it's because it was deceptively aligned during pre-training.
"Predict tokens well" and "Predict fine-tuning tokens well" seem like very similar inner objectives, so if you get the first one it seems like it will move quickly to the second one. Moving to the instrumental reasoning to do well at fine-tuning time seems radically harder. And generally it'...
There is another form of deceptive alignment in which agents become more manipulative over time due to problems with training data and eventually optimize for reward, or something similar, directly.
I think "deceptive alignment" refers only to situations where the model gets a high reward at training for instrumental reasons. This is a source of a lot of confusion (and should perhaps be called "instrumental alignment") but worth trying to be clear about.
I might be misunderstanding what you are saying here. I think the post you link doesn't use th...
Rather, I don't think that GPUs performing parallel searches through a probabilistic word space by themselves are likely to support consciousness.
This seems like the crux. It feels like a big neural network run on a GPU, trained to predict the next word, could definitely be conscious. So to me this is just a question about the particular weights of large language models, not something that can be established a priori based on architecture.
It seems reasonable to guess that modern language models aren't conscious in any morally relevant sense. But it seems odd to use that as the basis for a reductio of arguments about consciousness, given that we know nothing about the consciousness of language models.
Put differently: if a line of reasoning would suggest that language models are conscious, then I feel like the main update should be about consciousness of language models rather than about the validity of the line of reasoning. If you think that e.g. fish are conscious based on analysis of thei...
I don't think those objections to offsetting really apply to demand offsetting. If I paid someone for a high-welfare egg, I shouldn't think about my action as bringing an unhappy hen into existence and then "offsetting" that by making it better off. And that would be true even if I paid someone for a high-welfare egg, but then swapped my egg with someone else's normal egg. And by the same token if I pay someone to sell a high-welfare egg on the market labeled as a normal egg, and then buy a normal egg from the market, I haven't increased the net demand for normal eggs at all and so am not causally responsible for any additional factory-farmed hens.
The idea is: if I eat an egg and buy a certificate, I don't increase demand for factory farmed eggs, and if I buy 2 certificates per egg I actually decrease demand. So I'm not offsetting and causing harm to hens, I'm directly decreasing the amount of harm to hens. I think this is OK according to most moral perspectives, though people might find it uncompelling. (Not sure which particular objections you have in mind.)
I'm particularly interested in demand offsetting for factory farming. I think this form of offsetting makes about as much sense as directly purchasing higher-welfare animal products.
The picture I was suggesting is: FTX leaves customer assets in customer accounts, FTX owes and is owed a ton of $ as part of its usual operation as a broker + clearinghouse, Alameda in particular owes them a huge amount of $ and is insolvent (requiring negligence on both risk management and accounting), FTX ends up owing customers $ that FTX can't pay, FTX starts grabbing customer assets to try to meet withdrawals.
I'm still at maybe 25-50% overall chance that their conduct is similar to a conventional broker+exchange+clearinghouse except for the two points...
Another issue is the fiat that FTX owed customers. I think FTX did not say that the $ were being held as deposits (e.g. I think the terms of service explicitly say they aren't). Those numbers in accounts just represent the $ that FTX owes its customers. And if the main problem was a -$8B fiat balance, then it's less clear any of the expectations about assets and lending matters.
The statement "we never invest customer funds" is still deeply misleading but it's more clear how SBF could spin this as not being an outright lie: he could ask (i) "How much cash a...
One important accounting complexity is that there might be a lot of futures contracts that effectively represent borrow/lend without involving physical borrowing or lending. My impression is that FTX offered a lot of futures so this could be significant.
For example, a bunch of people might have had long BTC futures contracts, with Alameda having the short end of that contract. If Alameda is insolvent then it can't pay its side of the contract; usually FTX (which is both broker and clearinghouse) would make a margin call to ensure that Alameda has enough co...
It seems significant if only $3B of customers were earning interest on cash or assets, and the other customers had the option to opt in to lending but explicitly did not. I think all the other customers would have an extremely reasonable expectation of their assets just sitting there. I'm not super convinced by the close reading of the terms of service but it seems like the common-sense case is strong.
I'm interested in understanding that $3B number and any relevant subtleties in the accounting. I feel like if that number had been $15B then this...
Yeah, I also don't have anything else better.
I am piecing some of this together from this alleged report of someone who worked at in the two days before the end, from which I inferred that Caroline and Sam knew that they took an unprecedented step when they loaned that customer money that nobody knew about, which seems like it just wouldn't really be the case if they had only used money from the people who had lending enabled: https://twitter.com/libevm/status/1592383746551910400
I am definitely very interested in a better estimate of how many c...
It's reported here: https://www.axios.com/2022/11/12/ftx-terms-service-trading-customer-funds
I've heard (unverified) that customer deposits were $16B and voluntary customer lending <$4B. It would make sense to me that a significant majority of customer funds were not voluntarily lent, based on the fact that returns from lending crypto were minimal, and lending was opt-in, and not pushed hard on the website.
It seems like FTX offered borrowing and lending to its clients, and this was prominently marketed. I don't think you can call FTX offering margin loans to Alameda a "straightforward case of fraud" if they publicly offer margin loans to all of their clients. (There may be other ways in which their behavior was straightforwardly fraudulent, especially as they were falling apart, but I don't know.)
In general brokers can get wiped out by risk management failures. I agree this isn't just an "ordinary bank run," the bank run was just an exacerbating featur...
It seems like FTX offers borrowing and lending to its clients, and this was prominently marketed. I don't think you can call FTX offering margin loans to Alameda a "straightforward case of fraud" if they publicly offer margin loans to all of their clients. (There may be other ways in which their behavior was straightforwardly fraudulent, especially as they were falling apart, but I don't know.)
I think Matt Levine mentioned something similar, but I don't think I understand this, so let me try to get some more clarity on this by thinking through it ste...
Per the screenshot at tweet 17 of this thread, it seems like 2.8B of customer assets were opted-in to lending. Not nearly enough to explain the amount that went to Alameda.
If someone is strongly considering donating to a charitable fund, I think they should usually instead participate in a donor lottery up to say 5-10% of the annual money moved by that fund. If they win, they can spend more time deciding how to give (whether that means giving to the fund that they were considering, giving to a different fund, changing cause areas, supporting a charity directly, participating in a larger lottery, saving in a donor-advised fund, or doing something altogether different).
I'm curious how you feel about that advice. Ob...
Thanks for the thoughtful comment.
I think there’s a strong theoretical case in favour of donation lotteries — Giving What We Can just announced our 2022/2023 lottery is open!
I see the case in favour of donation lotteries as relying on some premises that are often, but not always true:
- Spending more time researching a donation opportunity increases the expected value of a donation.
- Spending time researching a donation opportunity is costly, and a donation lottery allows you to only need to spend this time if you win.
- Therefore, all else equal, it’s more impact
I would prefer more people give through donor lotteries rather than deferring to EA funds or some vague EA vibe. Right now I think EA funds do like $10M / year vs $1M / year through lotteries, and probably in my ideal world the lottery number would be at least 10x higher.
I think that EAs are consistently underrating the value of this kind of decentralization. With all due respect to EA funds I don't think it's reasonable to say "thinking more about how to donate wouldn't help because obviously I should just donate 100% to EA funds." (That said, I don...
Following up on this. Since May 2020 when these comments were written:
- VT is up 13.5%/year.
- VWO (emerging markets ETF) is up 3.6%/year.
- VMOT is up 7%/year.
Comparing to your predictions:
- You expected VMOT to outperform by about 6%, and suggesting cut that in half to 3% to be conservative, but it underperformed by 6.5%. So that's another 1.5-3 standard deviations of underperformance.
- You expected VWO to significantly outperform, but it underperformed by about 10%/year.
I still broadly endorse this post. Here are some ways my views have changed over the last 6 years:
- At the time I wrote the OP I considered consequentialist evaluation the only rubric for judging principles like this, and the only reason we needed anything else was because of the intractability of consequentialist reasoning or moral uncertainty. I’m now more sympathetic to other moral intuitions and norms, and think my previous attempts to shoehorn them into a consequentialist justification involve some motivated cognition and philosophical error.
- That said I
Earlier this year ARC received a grant for $1.25M from the FTX foundation. We now believe that this money morally (if not legally) belongs to FTX customers or creditors, so we intend to return $1.25M to them.
It may not be clear how to do this responsibly for some time depending on how bankruptcy proceedings evolve, and if unexpected revelations change the situation (e.g. if customers and creditors are unexpectedly made whole) then we may change our decision. We'll post an update here when we have a more concrete picture; in the meantime we will set aside t...
I think the point of most non-profit boards is to ensure that donor funds are used effectively to advance the organization's charitable mission. If that's the case, then having donor representation on the board seems appropriate. Why would this represent a conflict of interest? My impression is that this is quite common amongst non-profits and is not considered problematic. (Note that Holden is on ARC's board.)
I'm also not sure this what the NYT author is objecting to. I think they would be equally unhappy with SBF claiming to have donated a lot, but it se...
I think the point of most non-profit boards is to ensure that donor funds are used effectively to advance the organization's charitable mission. If that's the case, then having donor representation on the board seems appropriate.
I don't see how this follows.
It is indeed very normal to have one or more donors on the board of a nonprofit. But FTX the for-profit organization did in fact have different interests than the FTX Foundation. For example, it was in the FTX Foundation's interest to not make promises to grantees that it could not honor. It was also...
ARC returned this money to the FTX bankruptcy estate in November 2023.