
Ryan Kidd
Bio
Participation6
- Co-Executive Director, Machine Alignment, Transparency, and Security (MATS) Research (2022-present)
- Co-Founder & Board Member, London Initiative for Safe AI (2023-present)
- Board Member, Catalyze Impact (2026-present) | ToC here
- Manifund Regrantor (2023-present) | RFPs here
- Advisor, AI Safety ANZ (2024-present)
- Advisor, Pivotal Research (2024-present)
- Advisor, Halcyon Futures (2025-present)
- Advisor, Black in AI Safety and Ethics (2025-present)
- Advisor, Alignment Foundation (2026-present)
- Ph.D. in Physics at the University of Queensland (2017-2023)
- Group organizer at Effective Altruism UQ (2018-2021)
Personal website: ryankidd.ai
Give me feedback! :)
Posts 25
Comments41
Hi, this Ryan Kidd answering on behalf of MATS Research!
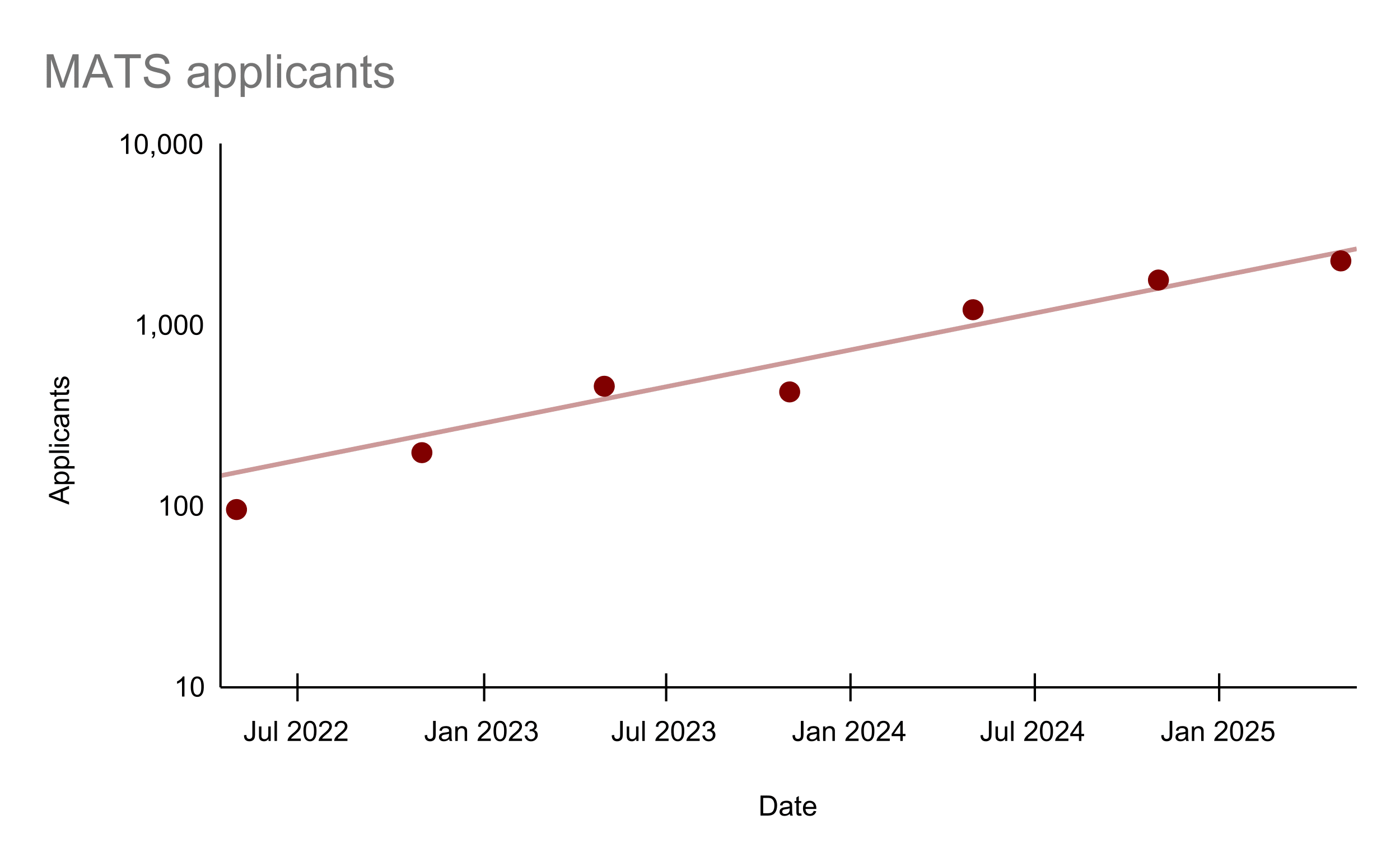
MATS is currently fundraising for our 2026 programs and beyond. We are the largest AI safety research fellowship and talent pipeline, supporting 100 fellows twice a year. Some impact stats:
- 446 alumni and 120+ arXiv papers (h-index 37) in 3.5 years.
- 80% of our pre-2025 alumni work on AI safety and 10% founded AI safety orgs or teams (e.g., Apollo, Timaeus).
- Participants in our last program rated it 9.4/10 on average.
- Former team members have gone on to (re)found Constellation's Astra Fellowship, manage Anthropic's AI safety external partnerships, and help other AI safety orgs scale.
We are well-funded by Coefficient Giving, but have big scaling plans! We want to run an additional fellowship in Fall 2026, expand Summer and Winter 2026 programs to 120 fellows each, and launch a 1-2 year residency program for senior researchers. Each additional fellow costs $40.8k.
Some testimonials:
- "Apollo almost certainly would not have happened without MATS." Marius Hobbhahn (CEO, Apollo Research)
- "It's my number one recommendation to people considering work on Al safety." Jesse Hoogland (Executive Director, Timaeus)
Please reply here or contact us if you have any questions!
As part of MATS' compensation reevaluation project, I scraped the publicly declared employee compensations from ProPublica's Nonprofit Explorer for many AI safety and EA organizations (data here) in 2019-2023. US nonprofits are required to disclose compensation information for certain highly paid employees and contractors on their annual Form 990 tax return, which becomes publicly available. This includes compensation for officers, directors, trustees, key employees, and highest compensated employees earning over $100k annually. Therefore, my data does not include many individuals earning under $100k, but this doesn't seem to affect the yearly medians much, as the data seems to follow a lognormal distribution, with mode ~$178k in 2023, for example.
I generally found that AI safety and EA organization employees are highly compensated, albeit inconsistently between similar-sized organizations within equivalent roles (e.g., Redwood and FAR AI). I speculate that this is primarily due to differences in organization funding, but inconsistent compensation policies may also play a role.
I'm sharing this data to promote healthy and fair compensation policies across the ecosystem. I believe that MATS salaries are quite fair and reasonably competitive after our recent salary reevaluation, where we also used Payfactors HR market data for comparison. If anyone wants to do a more detailed study of the data, I highly encourage this!
I decided to exclude OpenAI's nonprofit salaries as I didn't think they counted as an "AI safety nonprofit" and their highest paid current employees are definitely employed by the LLC. I decided to include Open Philanthropy's nonprofit employees, despite the fact that their most highly compensated employees are likely those under the Open Philanthropy LLC.
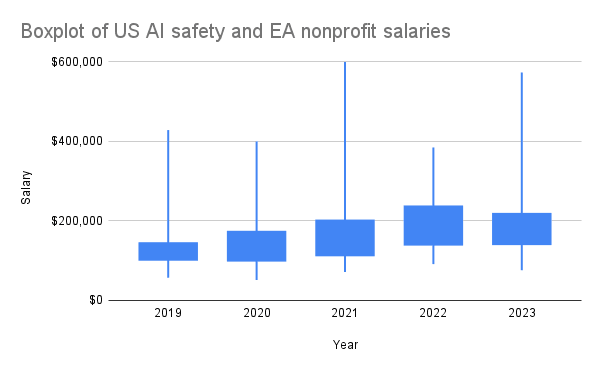
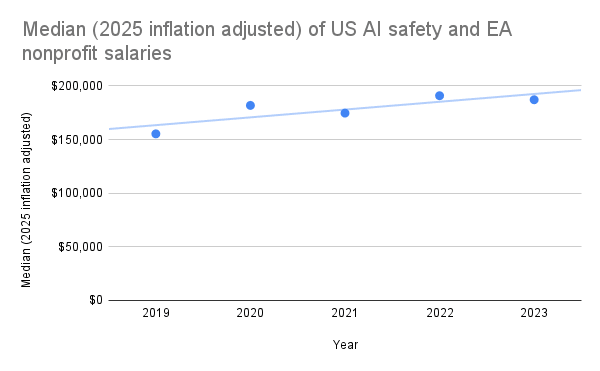
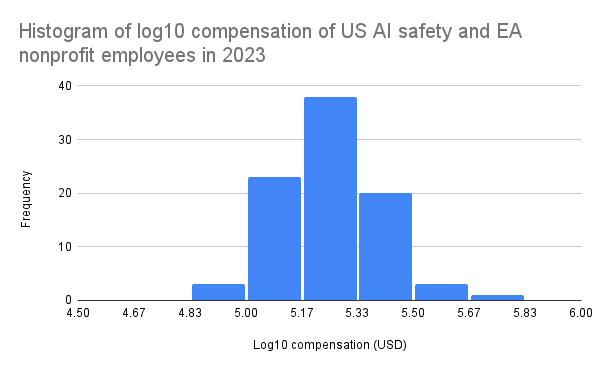
Thanks for publishing this, Arb! I have some thoughts, mostly pertaining to MATS:
Why do we emphasize acceleration over conversion? Because we think that producing a researcher takes a long time (with a high drop-out rate), often requires apprenticeship (including illegible knowledge transfer) with a scarce group of mentors (with high barrier to entry), and benefits substantially from factors such as community support and curriculum. Additionally, MATS' acceptance rate is ~15% and many rejected applicants are very proficient researchers or engineers, including some with AI safety research experience, who can't find better options (e.g., independent research is worse for them). MATS scholars with prior AI safety research experience generally believe the program was significantly better than their counterfactual options, or was critical for finding collaborators or co-founders (alumni impact analysis forthcoming). So, the appropriate counterfactual for MATS and similar programs seems to be, "Junior researchers apply for funding and move to a research hub, hoping that a mentor responds to their emails, while orgs still struggle to scale even with extra cash."