Stefan_Schubert
Bio
I'm a researcher in psychology and philosophy.
https://stefanschubert.substack.com/
Posts 17
Comments725
Topic contributions39
I'm writing a newsletter on current events, long-term trends, and topical debates roughly every other day. Recent posts include:
- A summary of a debate on AI progress, featuring Ajeya Cotra, Peter Wildeford, Eli Lifland, Matthew Barnett, and others.
- The three types of problems with population decline.
- We underestimate the pace of progress because much of it isn't salient.
- The reason we don't see more automation is simply that AI isn't good enough.
- Economists are unusually good at taking human agency into account.
This is a summary of Temporal Distance Reduces Ingroup Favoritism by Stefan Schubert, @Lucius Caviola, Julian Savulescu, and Nadira S. Faber.
Most people are morally partial. When deciding whose lives to improve, they prioritise their ingroup – their compatriots or their local community – over distant strangers. And they are also partial with respect to time: they prioritise currently living people over people who will live in the future. This is well known from psychological research.
But what has received less attention is how these psychological dimensions interact. In this chapter, we study this question. Specifically, we ask how time affects ingroup favouritism. Suppose you’re asked to support one of two charities:
- A national charity, supporting your compatriots
- A global charity, supporting whoever needs the money the most, regardless of country
Now suppose that these beneficiaries are future people who will live hundreds or thousands of years from now. How would that affect your choice?
In our first study, we sought to answer that question. We asked American participants whether they would prioritise the national or the global charity, and varied the time at which the beneficiaries were said to live. We found a clear pattern: greater temporal distance meant a stronger tendency to prioritise the global charity.
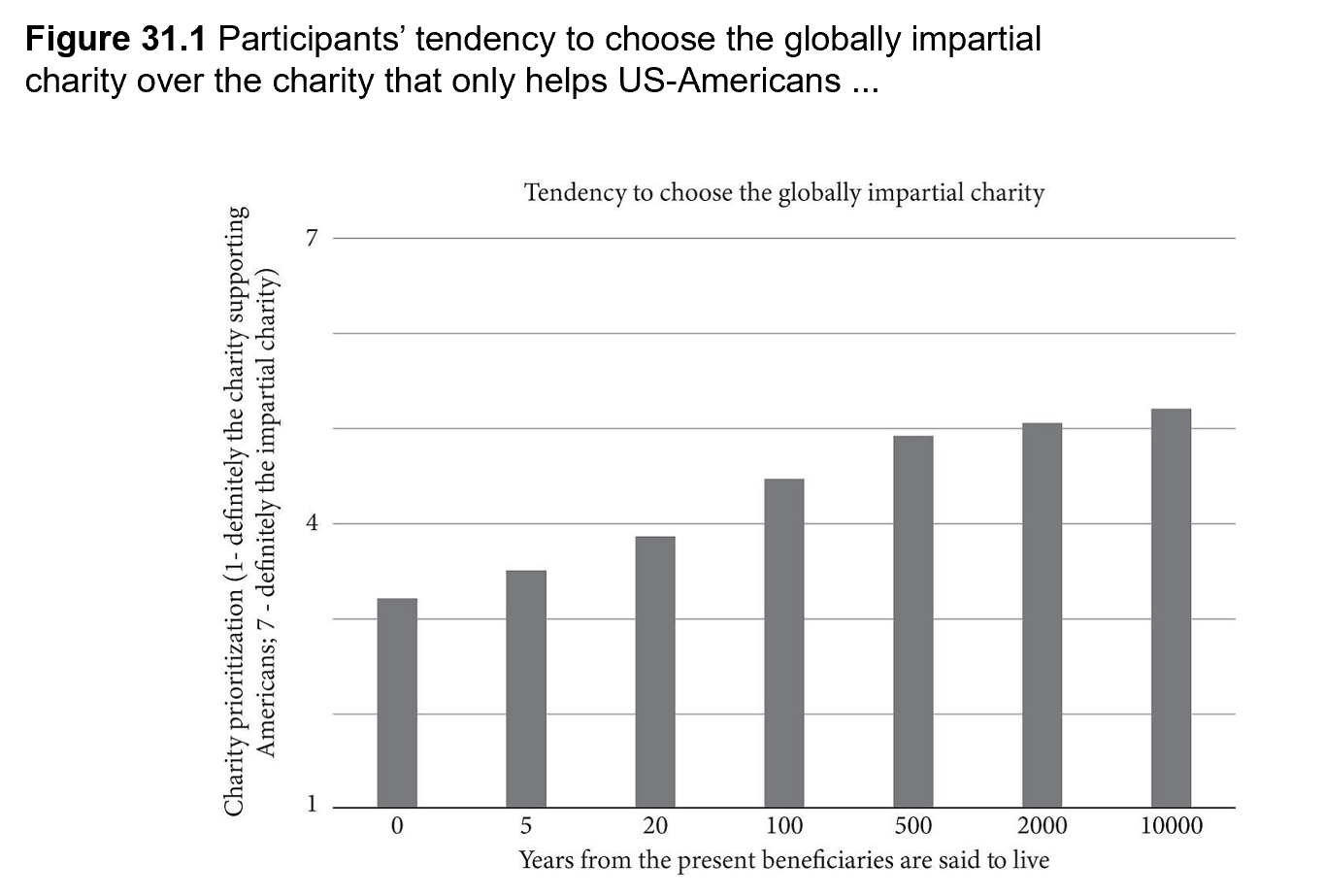
As we will see, we believe that these results are driven by people’s moral judgements. There is, however, an alternative explanation: that people simply hold the empirical belief that their country won’t exist in the future. In Study 2, we tested this explanation by asking a subset of participants to assume that their country (the US) would still exist 5 or 500 years from now (with the year varying by condition). We found that these participants, too, were less likely to prioritise their compatriots when the beneficiaries lived further into the future. While the assumption reduced the effect somewhat, it persisted – meaning it’s unlikely to be driven by empirical beliefs alone.
Study 3 sought to generalise the findings of Studies 1 and 2 to other forms of partiality besides that for compatriots. We found that temporal distance also weakens people’s inclination to prioritise their local community and their own family and its descendants. These findings further entrench the findings from the previous studies.
Finally, in Study 4, we turned to another potential connection between our two psychological dimensions, relating to individual differences. Are people who are more likely to prioritise their compatriots over foreigners also more likely to prioritise current people over future people? We found that the answer is yes. This result is in line with other research that has found that different types of moral partiality (e.g. racism and speciesism) are psychologically related.
Why is it that temporal distance reduces ingroup favouritism? One way to think about it is in terms of relative differences. In the present, people strongly prefer their compatriots over foreigners. But when we shift attention to the distant future, everyone feels far away, reducing the gap between compatriot and foreigner. The added distance makes national boundaries seem less significant compared to the temporal gulf separating us from all future people.
This raises a further question. If people adopted a more longtermist perspective – if they became more focused on the interests of future beneficiaries – would they thereby become more cosmopolitan? Could longtermism bring the world together? Our findings cannot establish this with certainty, but they suggest it is a possibility. It’s certainly a question that deserves further study. If these results hold up, they would entail that cosmopolitans have instrumental reasons to promote long-term thinking, over and above intrinsic reasons for doing so.
Yes, I agree.
The OP seems to talk about cause-agnosticism (uncertainty about which cause is most pressing) or cause-divergence (focusing on many causes).
A groundbreaking paper by Aidan Toner-Rodgers at MIT recently found that material scientists assisted by AI systems "discover 44% more materials, resulting in a 39% increase in patent filings and a 17% rise in downstream product innovation."
MIT just put up a notice that they've "conducted an internal, confidential review and concluded that the paper should be withdrawn from public discourse".
Thanks, Toby!