Any updates on this? Have other projects and tools superceded it?
We're looking to do something similar with content from unjournal.org. We're exploring the alternatives, and considering hiring a specialist for this project.
The chatbot uses a dataset of alignment literature to answer any questions related to AI safety that you might have, while also citing established sources. Please keep in mind that this is a very early prototype and despite citing references, it may still provide inaccurate or inappropriate information.
The overall objective is to help people better understand AI Safety issues based on alignment research using an LLM. This helps with tailoring content to the user's needs and technical level. The chatbot can hopefully be used by both newcomers to AI safety, as well as researchers and engineers who want to get up to speed on specific topics.
How it works
This chatbot builds upon AlignmentSearch. Our work also expands upon the alignment research dataset (ARD) developed during AI Safety Camp 6. This involved updating and curating the dataset to focus more on quality over quantity. Additionally, we created a process to regularly fetch new articles from selected sources. The ARD contains information about alignment from various books, research papers, and blog posts. For a full list of all the sources being used, look at the readme of the repository on GitHub or HuggingFace.
We use a process called retrieval-augmented generation (RAG) to generate the answers. Since LLM data is static, RAG increases the capabilities of a LLM by referencing an external authoritative knowledge base before generating a response. So the process can be roughly broken into - 1) getting and storing the data in a vector database, and then 2) generating an answer based on that data.
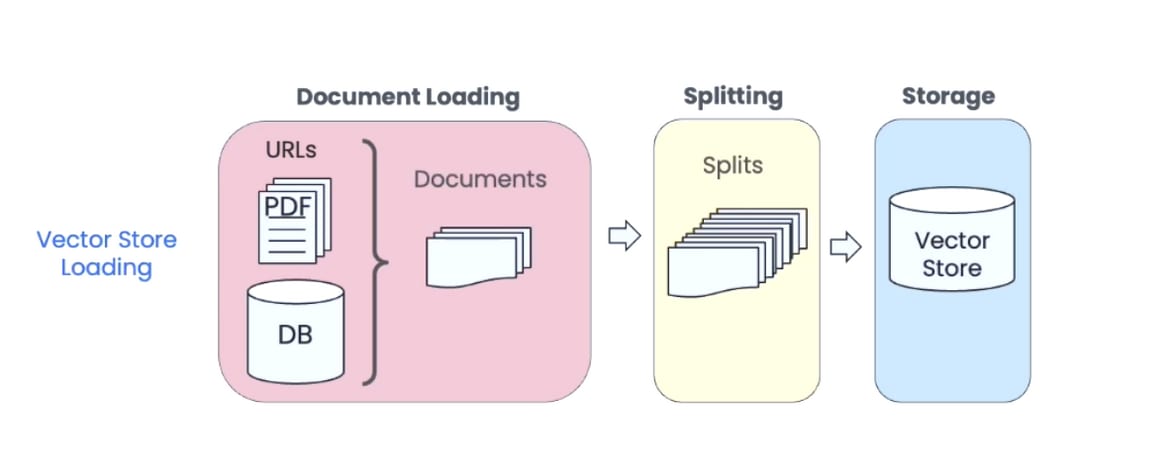
The information storage process is outlined below:
Document Loading: The articles are scraped from various sources such as the ones mentioned above. They are then parsed and stored in an SQL database while making sure that metadata values fields are valid.
Splitting: Then the text content of the documents is broken up into fixed-sized chunks.
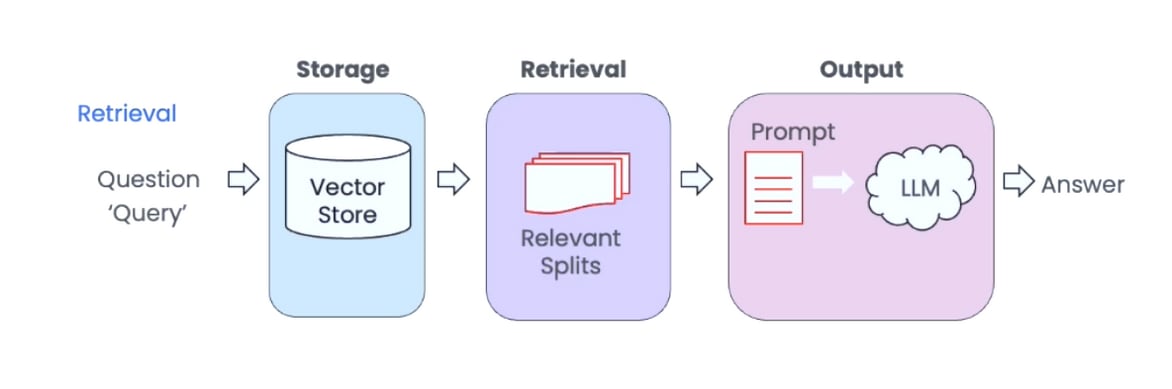
Storage+Retrieval: We retrieve chunks from the vector database that are semantically similar to the user's question.
Prompt: A prompt is formed that includes all the text retrieved from the relevant chunks provided as context, along with additional instructions on how to format citations and structure the answer.
Output: This prompt is then passed to the LLM, which synthesizes an answer based on the relevant chunk of data along with accurate inline citations to the source material.
Additionally, as the answer is generated, a ‘glossary’ is injected with manually written one-sentence definitions of common jargon. The following image example shows what Goodhart’s Law looks like on hover:
With automatic updates, the ARD will periodically fetch new article entries from trusted sources and add or update items to a SQL database. A separate process adds text to the dataset from user suggested sources. This dataset is available on HuggingFace, which includes instructions on how to download and use it. This means that the chatbot will always be able to produce the more relevant and newer information.
We are also experimenting with multiple modes for different audiences. Currently, we offer three options, which produce answers of varying complexity, using the same chunks but adjusting the prompt sent to the LLM.
Hallucinations
Each chunk is attached to some primary source (e.g. an arXiv paper or blog post). When we have our final answer synthesized from these chunks, we can link back to the primary sources from where the information used in generating the answer was gathered. This is one attempt to stop the generation of misinformation. Additionally, we are experimenting with prompt engineering and dataset curation to make sure that only quality articles are included in the dataset. Overall, it is still a work in progress, but we are putting in effort to reduce hallucinations.
Integration with manual distillations
The initial answer will always be generated by the LLM; however, we also integrate with the existing effort by the AISafety.info contributors. So, at the end of every generated answer, the chatbot recommends human-written follow-up questions. To distinguish a human-written answer from a generated one, the background color for human answers is darker as shown in the image below.
Future Plans
A number of planned features aim to enhance the quality of generated content while minimizing hallucinations. We plan to invest more effort into formalizing methods to optimize and evaluate prompts based on current research and best practices. Refinements to the retrieval method show promise for improvement as well.
A UI/UX revamp is underway for the frontend. Some planned features include adding a thumbs up or down option next to completions, so that we can A/B test our prompts. There might also eventually be an option to easily share or save conversation histories to the local machine.
The text of some answers also relies on equations, so we are working on getting properly formatted equations rendered in LaTeX.
Other potential future plans include offering a semantic search of the ARD as an OpenAI API function call or plug-in. We are also considering fine-tuning an LLM with the dataset of human crafted answers to see if it improves generated answers.
Overall, there’s still substantial work ahead, but the potential is encouraging.
Feedback & Contributions
If you have suggestions about the chatbot, such as noticing hallucinations on a certain topic, or if you feel that certain sources should be removed, please use this link to provide feedback.
Alternatively, if you have new sources that you think should be added to the overall alignment research dataset, please suggest including them using this link.
If you want to use the alignment research dataset in your own project, please feel free to download it on HuggingFace and use it. The link also contains detailed instructions on how to get set up.
This is a crosspost from the new Animal Welfare Alignment Newsletter by Anima International. You can subscribe on Substack if you are interested in following these efforts. Audio reading also available on Substack.
The goals of this post are to:
1. Raise a question I see as crucially important to the goal of aligning AI to animal welfare...
Hello! I'm Justin Portela. I got hired by GWWC to make YouTube videos after AI in Context did such a kickass job.
My channel is using that same cinematic, high-production value beauty to talk about everything in the EA universe that isn't AI.
...
This is a linkpost for Request for Proposals: Research and Applied Work on Digital Minds.
I'm glad to announce a request for proposals for research and applied work on digital minds at Longview Ph...






That's amazing, thanks for creating this!