Comments
You can check out the methodology of calculating the most recent dataset (2019). It seems quite legitimate: internationally shared data, Bayesian modeling, compliance with the Guidelines for Accurate and Transparent Health Estimates Reporting (GATHER), etc.
I wonder if any methods/assumptions/biases were carried over from the earlier study that you share. The main bias can be of omission, since health can be a relatively insignificant influence of one's wellbeing. For example, I found (Categorized tab, q4) that only 1/30 slum residents wanted Health to change the most but 8/28 wanted to live 0 additional years (q16). So, people can be healthy (have high QALY) but suffer (low WALY). The dataset can be accurate.
This focus bias can be due to the priority perceptions of the researchers in 1996 (who may have valued health, perhaps since subjective wellbeing improvements were not as readily possible?) in combination with the experimenter bias of the context experts (e. g. due to authority dynamics in these contexts).
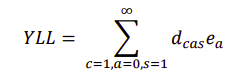





Some/all answers are in here, or in papers linked in that post. https://forum.effectivealtruism.org/posts/Lncdn3tXi2aRt56k5/health-and-happiness-research-topics-part-1-background-on
This is excellent, thanks!
These two papers, in particular, were what I was looking for. The corresponding information on QALYs was also great.
(For future readers of my post, the relevant info is under the "descriptive system" and "valuation methods" subheadings in Derek's post.)
I just had the exact same question, so thanks Aaron for asking this, and Derek for giving this answer :)