We evaluated 4 systems (ELIZA, GPT-4o, LLaMa-3.1-405B, and GPT-4.5) in two randomised, controlled, and pre-registered Turing tests on independent populations. Participants had 5 minute conversations simultaneously with another human participant and one of these systems before judging which conversational partner they thought was human. When prompted to adopt a humanlike persona, GPT-4.5 was judged to be the human 73% of the time: significantly more often than interrogators selected the real human participant. LLaMa-3.1, with the same prompt, was judged to be the human 56% of the time -- not significantly more or less often than the humans they were being compared to -- while baseline models (ELIZA and GPT-4o) achieved win rates significantly below chance (23% and 21% respectively). The results constitute the first empirical evidence that any artificial system passes a standard three-party Turing test. The results have implications for debates about what kind of intelligence is exhibited by Large Language Models (LLMs), and the social and economic impacts these systems are likely to have.
Reactions
I don't think we should say AI has passed the Turing test until it has passed the test under conditions similar to this:
But I do really like that these researchers have put the test online for people to try!
I've had one conversation as the interrogator, and I was able to easily pick out the human in 2 questions. My opener was:
"Hi, how many words are there in this sentence?"
The AI said '8', I said 'are you sure?', and it re-iterated its incorrect answer after claiming to have recounted.
The human said '9', I said 'are you sure?', and they said 'yes?'.. indicating confusion and annoyance for being challenged on such an obvious question.
Maybe I was paired with one of the worse LLMs... but unless it's using hidden chain of thought under the hood (which it doesn't sound like it is) then I don't think even GPT 4.5 can accurately perform counting tasks without writing out its full working.
My current job involves trying to get LLMs to automate business tasks, and my impression is that current state of the art models are still a fair way from something which is truly indistinguishable from an average human, even when confronted with relatively simple questions! (Not saying they won't quickly close the gap though, maybe they will!)
I'd be worried about getting sucked into semantics here. I think it's reasonable to say that it passes the original turing test, described by Turing in 1950:
I believe that in about fifty years’ time it will be possible to programme computers, with a storage capacity of about 109, to make them play the imitation game so well that an average interrogator will not have more than 70 percent chance of making the right identification after five minutes of questioning. … I believe that at the end of the century the use of words and general educated opinion will have altered so much that one will be able to speak of machines thinking without expecting to be contradicted.
I think given the restrictions of an "average interrogator" and "five minutes of questioning", this prediction has been achieved, albeit a quarter of a century later than he predicted. This obviously doesn't prove that the AI can think or substitute for complex business tasks (it can't), but it does have implications for things like AI-spambots.
Thanks for sharing the original definition! I didn't realise Turing had defined the parameters so precisely, and that they weren't actually that strict! I
I probably need to stop saying that AI hasn't passed the Turing test yet then. I guess it has! You're right that this ends up being an argument over semantics, but seems fair to let Alan Turing define what the term 'Turing Test' should mean.
But I do think that the stricter form of the Turing test defined in that metaculus forecast is still a really useful metric for deciding when AGI has been achieved, whereas this much weaker Turing test probably isn't.
(Also, for what it's worth, the business tasks I have in mind here aren't really 'complex', they are the kind of tasks that an average human could quite easily do well on within a 5-minute window, possibly as part of a Turing-test style setup, but LLMs struggle with)
But I do really like that these researchers have put the test online for people to try!
Thanks for sharing, it's an interesting experience.
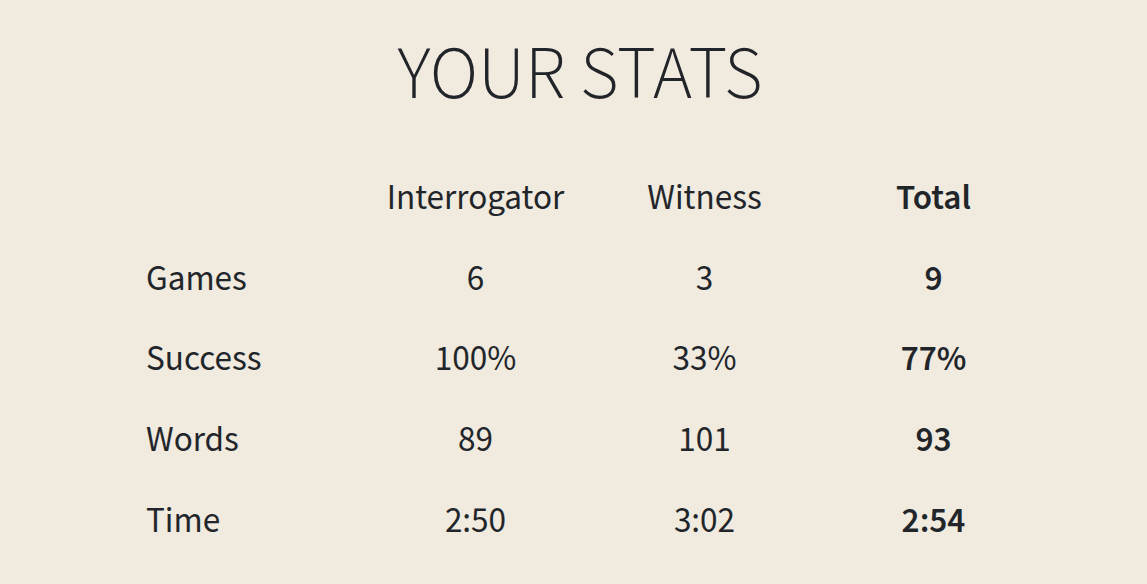
As you mention for now it's really easy to tell humans and AIs apart, but I found it surprisingly hard to convince people I was human.
Thanks for sharing the original definition! I didn't realise Turing had defined the parameters so precisely, and that they weren't actually that strict! I
I probably need to stop saying that AI hasn't passed the Turing test yet then. I guess it has! You're right that this ends up being an argument over semantics, but seems fair to let Alan Turing define what the term 'Turing Test' should mean.
But I do think that the stricter form of the Turing test defined in that metaculus forecast is still a really useful metric for deciding when AGI has been achieved, whereas this much weaker Turing test probably isn't.
(Also, for what it's worth, the business tasks I have in mind here aren't really 'complex', they are the kind of tasks that an average human could quite easily do well on within a 5-minute window, possibly as part of a Turing-test style setup, but LLMs struggle with)