Executive summary: The post proposes “Stratified Safety,” a simplified, defensive framework adapted from AI safety that organizes animal advocacy against AI-driven harms into three mutually reinforcing layers—preventing harmful systems, shaping their capabilities, and building resilience when harm occurs—supported by movement-wide capacity building.
Key points:
The author argues that AI will likely intensify existing forms of animal suffering, such as factory farming and wildlife harm, unless advocates adopt a proactive, defensive strategy.
“Stratified Safety” adapts the Swiss cheese model into three layers: preventing the existence of harmful AI systems, shaping AI capabilities to constrain harm, and withstanding harms through resilient infrastructure.
Prevention focuses on policy, regulation, and governance interventions that block or limit harmful AI applications before deployment.
Shaping emphasizes technical interventions during training and deployment, such as benchmarks, data filtering, and human-in-the-loop oversight, to align systems with non-human welfare.
Withstanding assumes some harms will occur and prioritizes resilience measures like transparency systems, physical infrastructure, alternative proteins, and emergency shutdowns.
A foundational component—capacity and field-building—is presented as essential to enable and sustain all three layers over time.
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, andcontact us if you have feedback.
Stratified Safety: a Defensive Framework for Advocacy
Credits: many thanks to Jasmine Brazilek, Sankalpa Ghose, Constance Li, Karen Singleton, Max Taylor, Yip Fai Tse, and Kevin Xia for providing feedback on this post.
Imagine a skyscraper 26 stories high - not for offices or apartments, but for pigs. Industrial elevators transport them to their designated floor, where they spend their entire lives from birth to slaughter, never once seeing daylight.
This is the future of factory farming.
China’s 26-story pig skyscraper
Here’s what’s crazy: this future dystopia is already here. In central China, the world's largest single-building pig farm towers over the countryside, and slaughters over 1.2 million pigs each year. As of writing this post, there are reported to be 4500 of these buildings (though most are much smaller in scale).
Here’s what’s worse: other countries are already following suit. This year, Korea and Vietnam have already announced plans to build similar pig “skyscrapers”, inspired by those in China.
This is one stark example of how AI can exacerbate animal suffering. These facilities rely on sensors, cameras, and other AI-powered systems to monitor and optimize every aspect of production - all in the name of maximizing efficiency with ruthless precision.
Unfortunately, dangerous AI systems affect not only farmed animals, but also those in the wild, in labs, and even in the long-term future. As capabilities accelerate, these systems will become more powerful, more autonomous, and more difficult to influence. As advocates, we need a defensive strategy before these dangerous AI systems become entrenched.
In this post, I’ll outline a practical and actionable (albeit simplified) framework we can employ as a movement to mitigate harm from AI systems.
With that said, let’s take a look at the principle behind this approach.
A Defense through Swiss Cheese
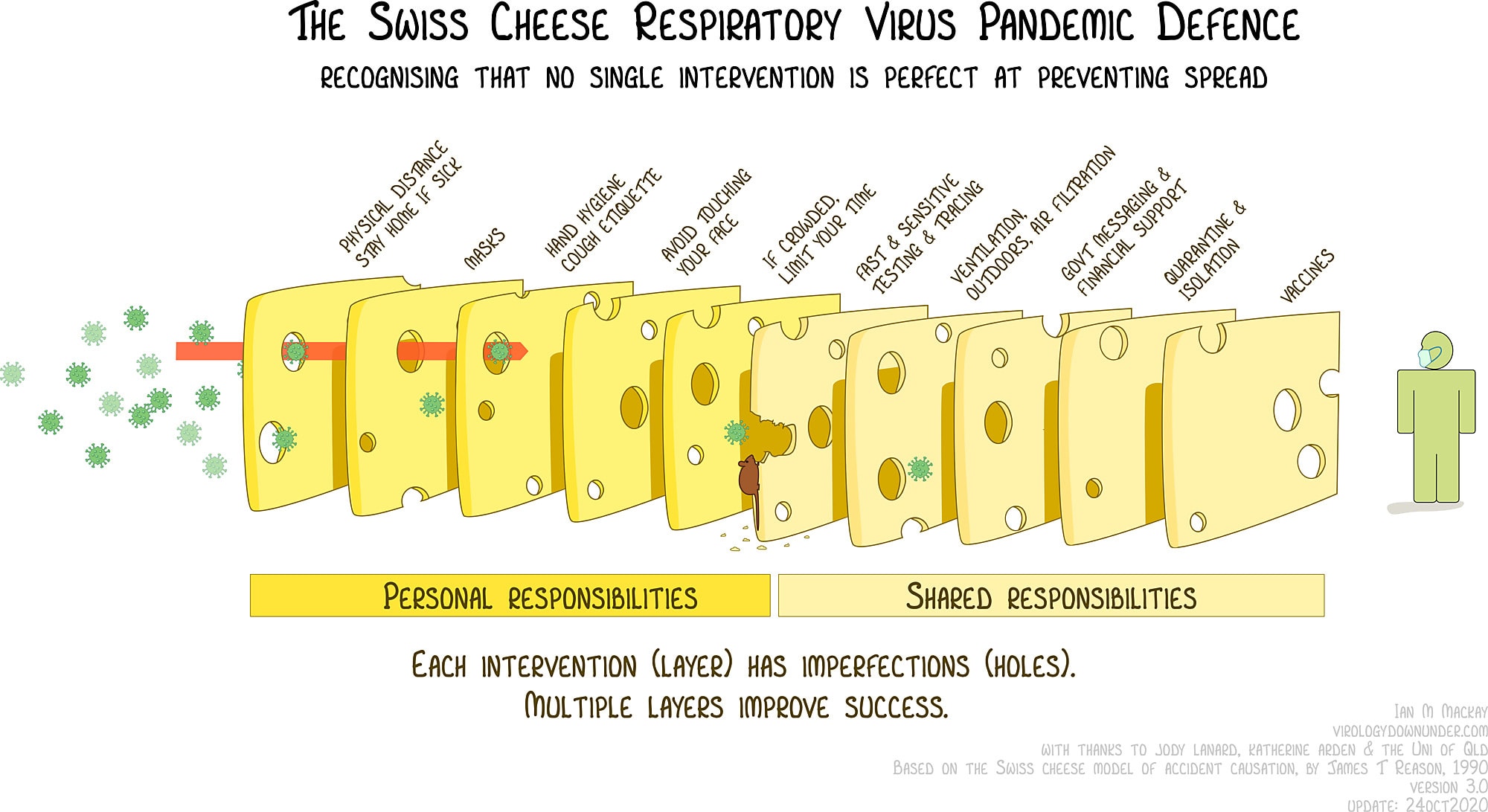
Before diving into the framework itself, we should talk about the concept of stratified safety, which has its origins in AI safety and pandemic response. This strategy is often illustrated through the "swiss cheese"[1] model:
Swiss cheese model for defense. See original reference here.
Let’s break down this example. We have the attack vector (pandemic) and the defense vector (healthy person). Each slice of cheese represents a “layer” we place between the two to mitigate the effectiveness of the pandemic. However, each of these layers contains natural imperfections - holes through which the attack vector can permeate. With this in mind, it naturally makes sense for us to stack a multitude of layers to give the attack the lowest chance of succeeding. This is the idea behind stratified safety - a fancy term for multi-layered defense.
Imagine if we only had one defensive layer: maybe we wear masks and call it a day. How likely would it be that this pandemic succeeds in spreading through society?
The “swiss cheese” model demonstrates the idea that we need multiple layers to achieve success, as well as which ones are necessary in this particular example of pandemic response. But what if the attack vector was instead “harmful AI” and not a deadly pandemic? How would this structure change if we were defending animals instead of people? What types of layers would we need?
To answer these questions, let’s evolve the “swiss cheese” model into a new framework specifically designed to protect animals from AI-driven harms.
Setting the stage
Before we continue, a quick caveat on what the subsequent framework is and isn’t:
What it isn’t: a comprehensive, surefire animal protection strategy
What it is: a lens through which to consider and strategize on defensive measures as AI increasingly permeates every aspect of animal suffering
I’d invite each reader to think critically about the content I present below, and formulate their own thoughts and conclusions on the material. As both technology and our movement advance, frameworks like these will inevitably have to be continually updated. Consider this a starting point for deeper conversation, rather than a definitive strategic solution.
Now, let’s take a look at this new model and each of its components in greater depth.
Building a Castle
With a new framework comes a new metaphor! To me, a castle represents the epitome of multi-layered defense. A castle's defensive layers (the moat, walls, guards, keep, etc.) each serve distinct strategic purposes and cover different vulnerabilities - just as the interventions in our new framework will address separate failure modes as well.
The resulting framework is closely adapted from the model created by BlueDot Impact, and consists of three core layers that I believe represent the essential pathways to mitigating animal suffering from AI-driven harms. For each layer, I’ll outline the core defensive strategy, share concrete interventions we can implement, and show how it maps to our castle schema.
The Defensive Layers
1. Prevent existence of harmful AI systems
The first layer is all about prevention. This asks the question - how do we stop dangerous AI systems from being built or deployed in the first place? Prevention operates on a simple theory: if harmful systems don’t exist, they can’t cause harm. These preventative measures are usually comprised of policies and governance, though they may be difficult to implement given intense commercial pressures to increase efficiency or societal and cultural pressures to maintain the status quo. Here are some examples:
Integrate risks to non-human welfare in landmark laws and regulations, like the EU AI Act
Enact policies that prohibit the use of drones and other technologies for the pursuit of wildlife
Garner industry commitments by frontier labs that prohibit partnerships with factory farming corporations (mentioned briefly in this CG newsletter)
Campaign to pause the development and acceleration of frontier AI systems (see PauseAI)
For our castle model, how does this translate? Prevention involves constructing a drawbridge and filling the surrounding area with water to create a moat, deterring attacks from entering to begin with.
2. Shape capabilities of AI systems
With layer 2, we shape what AI systems learn and how they behave through various technical interventions during training and deployment. This asks the question - if harmful AI systems exist, how can we constrain their ability to harm animals? Moreover, shaping also includes fixing gaps in current systems, integrating welfare-positive capabilities that (in the minds of animal advocates) should have been there from the start. Here are some example interventions:
Create benchmarks and evals to test model capabilities and alignment to non-human welfare considerations (see AnimalHarmBench)
Augment computer vision systems of autonomous vehicles to include small animals
Conduct research using interpretability methods, which may reveal how models reason about non-human animals from a fundamental level
Use input data filtering to remove speciesist and otherwise biased data from training sets for AI systems affecting animals (precision-livestock farming, wildlife management, interspecies communication, etc.)
In our castle model, we can think of “Shaping” as the walls, gates, and the guards protecting them. The walls constrain where attackers can go, channeling them through controlled entry points (gates). Guards stationed at these gates block the most harmful threats, mitigating damage from those who enter. Meanwhile, we continuously repair gaps in our walls and reinforce weak sections.
3. Withstand harmful AI actions
Layer 3 revolves around building resilience. With this, we ask the question - if our previous defenses fail and offensive measures manage to slip through, how do we prepare current societal structures to withstand harm? This layer assumes that dangerous AI systems exist in the world around us with the potential to actively exacerbate animal suffering. For us, this means creating and deploying resilient infrastructure - here are some examples:
Create third-party monitoring systems in factory farms, detecting welfare harms in real-time and making suffering transparent
Build physical infrastructure, like wildlife crossings to protect animals even when autonomous vehicles fail to account for them
Accelerate alternative proteins, which reduces dependency on AI-optimized factory farming[3]
Introduce emergency shutdown protocols (for farms, vehicles, etc.) that revert the system to human control if AI causes measurable harm above a certain threshold
Improve baseline welfare conditions on factory farms through various reforms (cage-free protests, breeding for welfare traits, etc.), making animals more resilient to AI-driven intensification
This adds the last missing piece to our now-finished castle. Attackers break through - what now? We have an army of soldiers, a fortified keep into which to retreat, and even escape tunnels if all else fails. In short, we have a diversity of resilient infrastructure as a final point of defense.
Foundation: the final component
To the three layers above, I’ll include one additional, yet critical element of this framework. While this is not a “layer” in the same sense as the others are above, this is a component of the structure that underpins everything else: capacity and field-building.
Here are some interventions that encompass this meta-level “layer”:
Empower the animal advocate movement to utilize AI to supercharge their campaigns and organizations (see Amplify for Animals, AI Impact Hub)
Collaborate across movements and build relationships with other communities (AI governance, environmental protection, wildlife conservation, etc.)
Run conferences, workshops, hackathons, courses, fellowships, “wargames” and more to connect, educate, and empower the movement
Implement preemptive legal frameworks to grant personhood for non-human animals (especially the subjects of our interspecies communication research)
Fundraising to make this all happen!
These interventions enable us to have a cohesive, adaptive, and forward-looking movement. Together, they form the foundation that our framework needs to function and thrive. In our castle model, you can think of this as the builders - the ones that make sure we even have a castle to begin with.
Defense in the real world: case studies
Now that we have an idea of what these layers are, let’s explore some case studies of specific cause areas in animal suffering, applying the stratified safety frameworkabove.
Precision-livestock farming (PLF)
As technology advances and an increasing number of animals are used for food, we’ll almost certainly notice an increase in precision-livestock farming (PLF) within factory farms. PLF refers to the use of sensors, cameras, computer vision, algorithms, and other AI technologies to monitor every aspect of the farming process end-to-end, optimizing farm production.[4] This raises an important question for our movement to consider: how do we protect animals when AI makes factory farming so efficient at scale? Here’s how we can apply our defensive layers.
Prevent: campaign for the restriction of PLF for harmful use-cases.[5] Alternatively, ensure PLF is designed humanely by having animal welfare advocates lead development.
Shape: fine-tune and align AI models to optimize for metrics that prioritize welfare over efficiency.
Withstand: create public dashboards linked to factory farms that make suffering transparent through data, leading to public pressure, legal action, and tarnished reputations of low-welfare farms.
By adding multiple layers of defense, we can reduce the extent to which AI exacerbates suffering in factory farms.
Each year, hundreds of millions of wild animals are killed in vehicle collisions. As Autonomous vehicles (AVs) proliferate, this number may rise due to the invisibility of certain animals being detected in AV systems. Using the framework above, how can we create a strategy to mitigate suffering through multiple dimensions? Let’s explore the layers below:
Prevent: Create regulations that mandate the incorporation of non-human welfare considerations into the designs of AV systems (see section 5.2 here for initial thoughts).
Shape: align computer vision & related technologies in AV systems to include smaller animals.
Withstand: Build physical infrastructure (e.g. wildlife crossings, roadblocks, barriers) to divert wild animals from high-traffic areas and collision hotspots.
Wildlife crossing for crabs to pass over roads on their way to the ocean
In both examples, we’re implementing points of protection at multiple stages within the system, realizing that each individual layer has natural vulnerabilities and “holes”. In this way, we can maximize the defensive capabilities we create for animals.
A note on defensive accelerationism
Defensive Accelerationism (or d/acc) is a philosophy that pushes for the proactive, intentional advancement of defensive over effective technologies. It’s a concept that originates from “Withstand” (layer #3), though the principle permeates across all layers.
Every instance of new technology that humanity builds has dual-use applications. The harnessing of nuclear energy can power entire cities - or devastate them with weapons of mass destruction. Advancements in biotechnology (CRISPR, gene editing, etc.) can unlock novel treatments, extending life expectancy - or engineer deadly pathogens and pandemics. And of course, the acceleration of AI may hold the key to solving everything from disease to poverty - but can also lead to the total disempowerment of our species.
The spirit of d/acc can be captured in three main points:
Differential: it’s not just what we develop, but also the order in which we develop these technologies. We need to be selective about intentionally accelerating defensive technologies, rather than pushing the frontier as a whole.
Decentralized: power should be distributed across multiple stakeholders and systems, rather than concentrated in centralized authorities, industry, or AI systems themselves.
Democratic: we need broad participation in technology development and governance by advocates, researchers, scientists, and communities - not just industries.
How does this connect to our castle model? A simple way of understanding what d/acc means, in principle, would be to examine its inverse. Imagine we focused solely on creating stronger weapons. Sure, that would help us withstand attackers more efficiently. But what would happen if our enemies found our weapon designs? Could our efforts be used against us? Instead, maybe we should focus on training our soldiers or teaching the townspeople how to defend themselves.
We should think of d/acc as the guiding principle for our framework. It reminds us that technology will advance regardless, so we should strive to prioritize defenses.[6]
Thoughts & takeaways worth considering
Again, it’s important to remember that this is just one, simplified framework through which I’ve organized all these strategies.
I’ll also note that some interventions may not sit perfectly within just one layer, and could span multiple layers or exist in between. In reality, complex issues like factory farming and wild animal suffering require many interventions - far more than three - distributed across the spectrum of prevention, shaping, and withstanding. But as mentioned, I’ve sought to condense this multitude of possibilities into a practical and actionable framework.
With that said, I’m hoping you internalize and take away a few things from this.
#1: AI is incredibly dual-use
AI is a profoundly dual-use technology, and has both positive and negative applications for animals. In this post, I’ve primarily discussed how harmful AI amplifies existing structures of exploitation. However, we should remember that this technology can also be used for incredible good, like accelerating alternative proteins research or empowering campaigns.
In addition, the trajectory of how AI develops is still malleable. How these systems affect animals in the long-term future will largely depend on how we steer it today.
#2: Pushing the frontier vs. building defenses
If you’re currently working on an AI intervention to help animals, that’s great! Just be mindful. Are you pushing the frontier forward? If so, you may be contributing to a technology that could be used to harm animals.
Some examples of this are interspecies communication and gene editing. I’m not advocating against these technologies, as they could have transformative effects on how we protect animals in an AI-accelerated world. However, I’m overall uncertain if interventions like these will be net-positive, net-negative, or just plain neutral. What I am certain about is that we need to tread cautiously, consider the long-term effects, and envision our macro-level strategies for how these technologies fit within our movement.
#3 A pivotal moment in time
We’re at a pivotal moment in time, where AI systems are still relatively weak compared to the capabilities they could have in the coming years. As models become more and more advanced, it will become increasingly difficult to influence their behavior, as well as the institutions that instill them. It’s urgent for us to act now to reduce the risk of value lock-in.
#4: Invest strategically across all three layers
It’s tempting to focus all our resources on a single layer - for example, if all our “Layer 1” efforts succeeded, we wouldn’t have harmful AI systems to begin with. But the framework only works when all three layers function together.
Overinvesting in one layer while neglecting others creates vulnerabilities. I’m not saying that each individual or even each organization should spread their focus across every layer, but as a movement we should make sure we have a diversity of interventions.
#5: Connections between layers
The layers outlined in this framework are interconnected, and don’t exist in a vacuum.
For example, a public dashboard (3. Withstand) generates transparency data that acts as evidence to drive new or stronger regulations (1. Prevent). These regulations push for the adoption of technical interventions to further improve the system (2. Shape). This system, now further strengthened, produces better transparency data shown by the dashboard (3. Withstand).[7]
In some ways, you can see this as a feedback loop, wherein each layer reinforces the other.
#6: Multiple points of entry
There are multiple point of entry within this framework, and you don’t have to be a technical expert in AI to contribute to defensive measures for animal suffering. These are not hard “rules”, but in putting this together I’ve noticed that certain layers are better suited for those with unique skillsets. For example:
“Prevent” (Layer 1) is largely comprised of policy, corporate, governance or diplomatic interventions
“Shape” (Layer 2) is often the most technical, and benefits from knowledge of computer science, programming, AI safety, etc.
“Withstand” (Layer 3) draws on the most diverse range of skills, spanning disciplines like landscape design, construction, mechanical engineering, web development, systems design, food science, biochemistry, and many others.
And of course, “Foundation” (meta-level) has the lowest barrier of entry, though is one of the most important: this needs expertise in communications, coalition building, movement strategy, organizing, cause prioritization, etc.
So… don’t wait to contribute! However, if you’re an animal welfare advocate who wants to upskill in AI strategy, safety, or technology, I’d highly encourage you to do so.
#7: This affects you, no matter what
Maybe you’re a grassroots activist who participates in fur protests, cage-free campaigns, or street outreach, and AI is the furthest thing from your mind. Regardless of whether you’re an “AI person” or not, this will affect your advocacy.
The strategies we employ today to advocate for animals may not work five, ten, or fifteen years from now. We should therefore make sure to look ahead, and ensure that our strategies are sustainable as possible for the long-term future, as we soon may shift to a post-paradigm world transformed by AI.
Conclusion
Thank you so much for reading! This marks the end of my first post, and I hope to write much more on the intersection of AI safety and non-human welfare. As such, I’d love to get your feedback on these ideas, so please don’t hesitate to leave a comment below with your honest insights.
In my perspective, alternative proteins is mostly a “Withstand” (L3) defense, but also overlaps “Prevent” (L1). Alternative proteins represent a type of resilient infrastructure that reduces dependency on traditional animal products, driving down supply and demand. However, this would also “prevent” future factory farms (using PLF) from existing in the first place. See “Thoughts and Takeaways”.
What are we prioritizing defenses over? This would be effective technologies, which is pretty unexplored in the animal advocacy movement as it’s more human-centric. I’ll likely explore this in another post, and will link it here if so.
To caveat: this also carries the risk for harm. Showing transparency data can help in many cases, but this information could potentially be used in nefarious ways.
This is the third in a sequence of posts taken from my recent report: Why Did Environmentalism Become Partisan?
Summary
Rising partisanship did not make environmentalism more popular or politically effective. Instead, it saw flat or falling overall public opinion, fewer major legislative achievements, and fluctuating executive actions.
Public Opinion...
I think right now EAs might be making a significant mistake by paying insufficient attention to the political realm. As EAs we tend to figure out what’s most impactful for us to work on and focus hard. That’s great! But there are various actions that are ‘non-delegatable’ - the extent to which an individual can do the action is limited (like voting, going to a protest, making hard money contributions to particular campaigns). It might be useful if we were all more in the habit of doing variou...
New Video from AI in Context: The Fall and Rise of Sam Altman
If you want to skip straight to the video, here it is!
AI in Context is excited to be back with our fourth video! For those just hearing from us, we make videos for 80,000 Hours, telling stories about transformative AI...






Executive summary: The post proposes “Stratified Safety,” a simplified, defensive framework adapted from AI safety that organizes animal advocacy against AI-driven harms into three mutually reinforcing layers—preventing harmful systems, shaping their capabilities, and building resilience when harm occurs—supported by movement-wide capacity building.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.