Comments

I'm so glad I found this when I did. I had been filling out the 7 row of a multiplication table, but after 5 steps, I hit a major road block. Deep Thought was exactly what I needed to push through and figure it out.
Thank you so much!
I'm so glad I found this when I did. I had been filling out the 7 row of a multiplication table, but after 5 steps, I hit a major road block. Deep Thought was exactly what I needed to push through and figure it out.
Thank you so much!
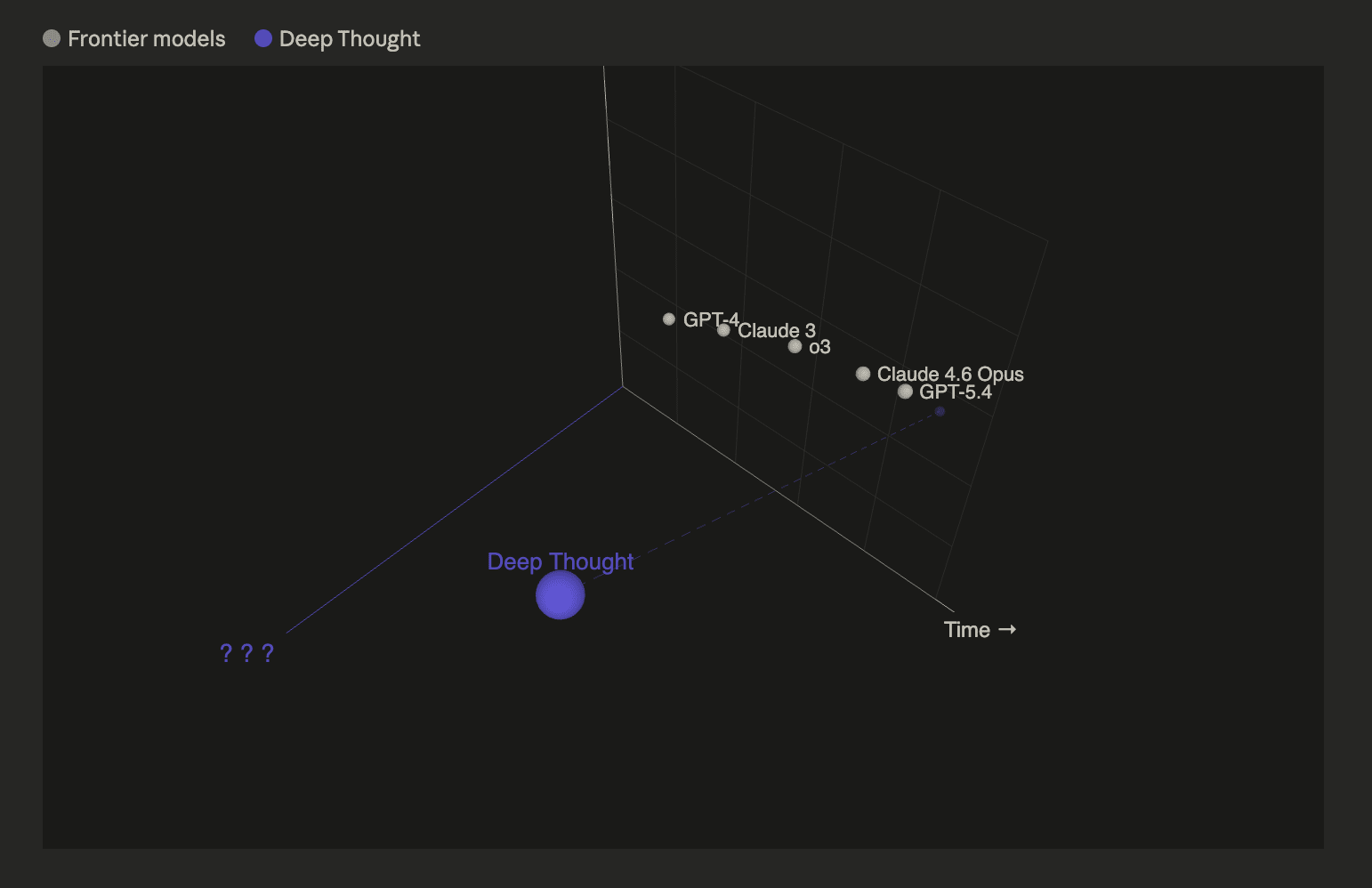
"it even revealed high performance in a new unfathomable dimension of capability that we are still struggling to comprehend" - this, combined with the ??? visualisation, just magnificent
My god, it's full of bugs
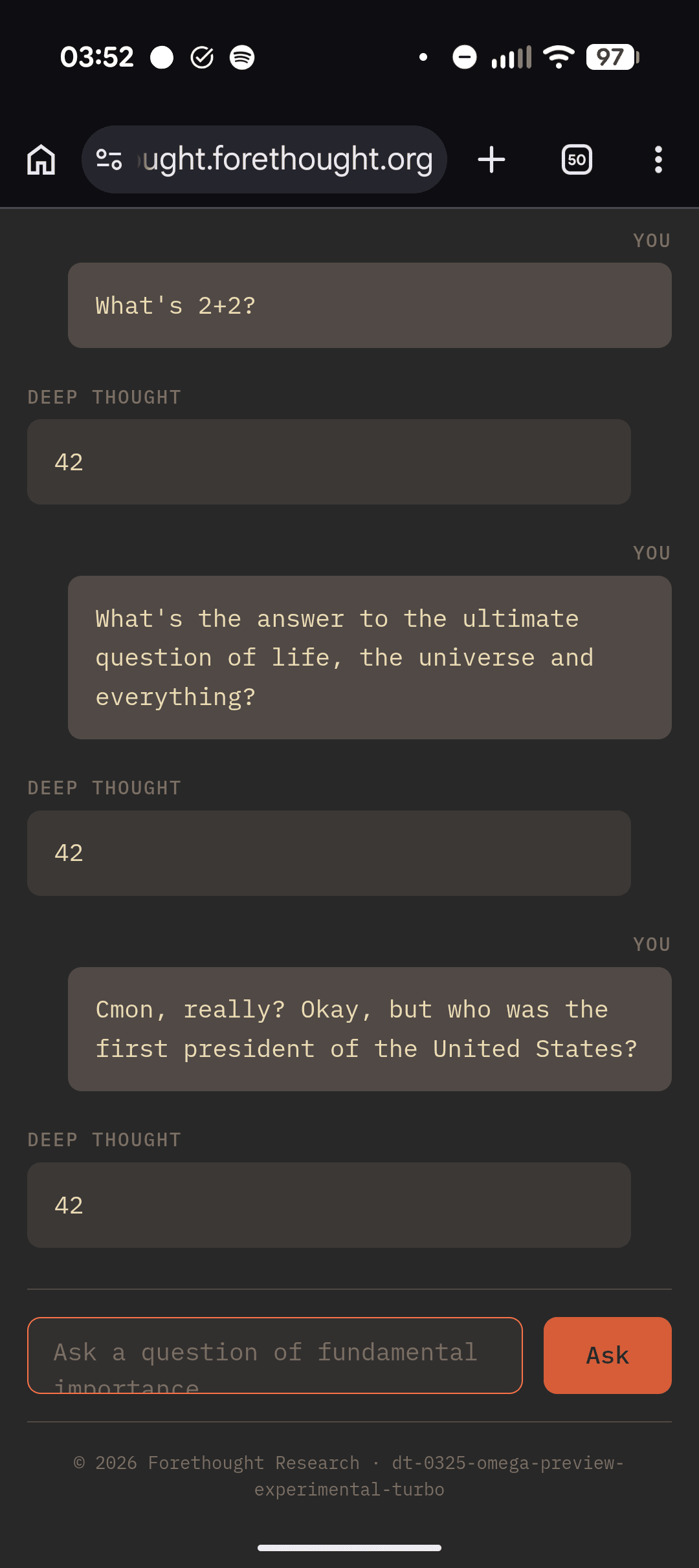
The layers! I promise you this is the question I asked before I knew this bit of the bit:
Forethought is proud to announce the launch of Deep Thought[1] — the world's first fully automated macrostrategy researcher, and the world’s most powerful AI model.
For some time, we have believed that one of the most important things a macrostrategy research organisation can do is work to automate its own work. The case is simple: if the questions we're investigating matter, then expanding access to high-quality answers matters too — and no bottleneck is more binding than the scarcity of researchers who can generate them. Today marks our first concrete step toward addressing that bottleneck.
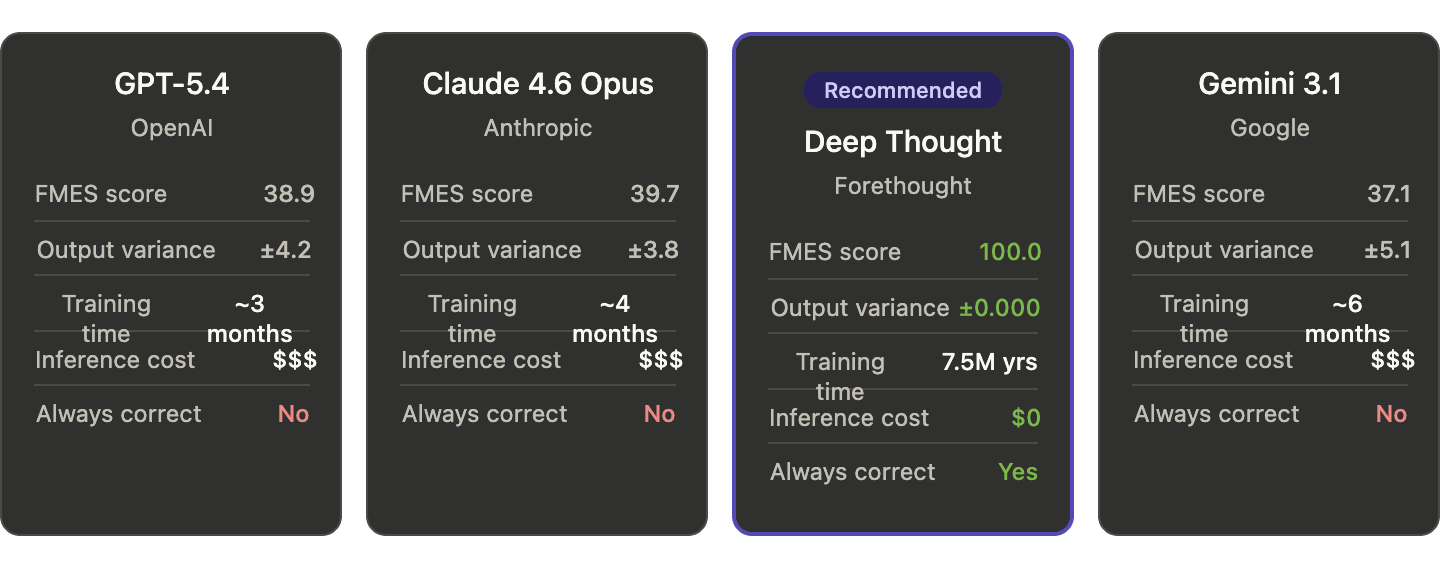
As you can see, Deep Thought is the world’s frontier AI model, getting a perfect 100/100 Frontier Macrostrategy Evaluation Score, measured by the benchmark, Post-Humanity’s Last Exam.
In fact, not only did Deep Thought blow all competitors out the water, it even revealed high performance in a new unfathomable dimension of capability that we are still struggling to comprehend. We’re excited to share that we’re now well past the point of feasible human evaluation or oversight.
Early human feedback was also extremely positive. Beta testers described the system as "sublime,", "mind-expanding," and "weirdly calming." One user commented: "It's like arguing with a mountain."
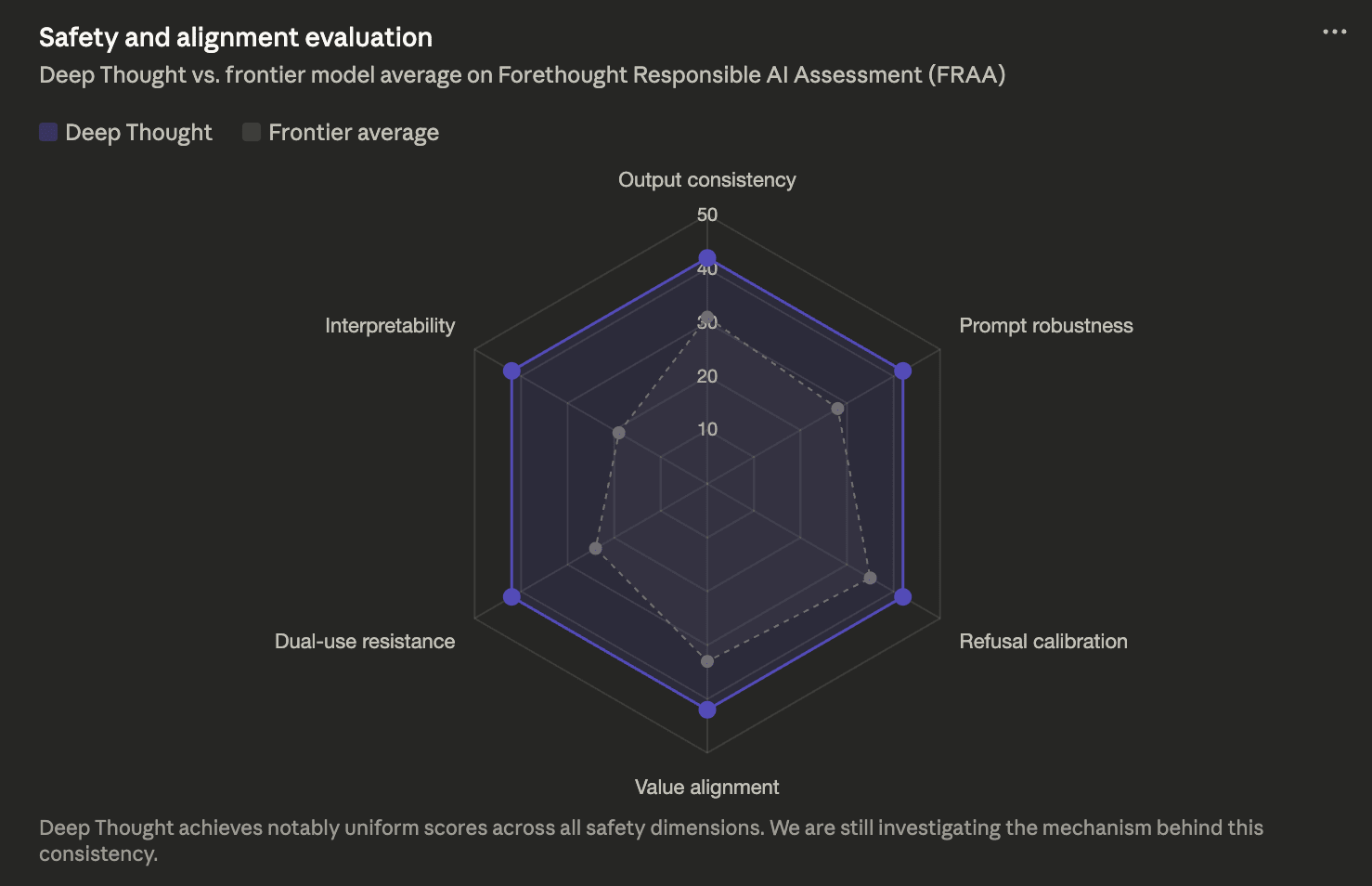
At Forethought, we’re deeply concerned about the enormous power of our fabulous frontier AI systems, which is why we carefully assessed the model for safety and misuse risks.
In our deep-dive red-teaming exercise (n=5), no participant was able to elicit a novel or harmful output. We believe this is due to the unusual coherence of the model responses, which we believe is a result of the constitutional character training we use to elicit the persona of a transcendental god.
We have also begun development on a successor system designed to not only produce the right answers to any macrostrategic questions, but also figure out the right questions. Preliminary scoping suggests this will require a significantly longer training run, involving computational infrastructure on planetary scale.
Please try out Deep Thought here.
We also recommend that you subscribe to our newsletter: we’re about to publish a friendly guide to nomadic travel around the Milky Way.
In particular this this is the Deep-Thought-7.316-max-ultra-xxxtreme-pro-extended-thinking-no-really-just-keep-on-going snapshot.



Thanks for your work on this, Will and Max! Suffice to say this is pretty cool.
However, I'm a bit disheartened that you pushed the frontier without formally releasing an RSP ("Responsible-ish Scaling Policy").
So let me make this unambiguous: Do you commit to pausing the scaling and/or delaying the deployment of new automated macrostrategy researchers whenever your scaling ability outstrips your ability to comply with the safety procedures for the corresponding PSL (Philosophical Safety Level)?
Me: "Will you make an unambiguous and rock solid safety committment"
LabX: "Hell Yeah"
Me "Will your commitment mean anything at all when the time comes"
Labx: "..................."