This is my distillation of the 2016 paper Updating on the Credences of Others: Disagreement, Agreement, and Synergy by Kenny Easwaran, Luke Fenton-Glynn, Christopher Hitchcock, and Joel D. Velasco. Following their wish, I will refer to them as the collective ‘EaGlHiVe’ pronounced ‘eagle hive’ (concatenating the first two letters of their names). Unless indicated, I tried not to add substantive claims myself.
Despite my efforts to make this as clear and simple as possible, this post is rather technical. I expect readers who are unfamiliar with the fundamentals of probability theory and bayesian reasoning to struggle with parts of it. However, you don't need to be fluent in probability theory to get the gist of this post.
The main points
- Sometimes, the probability estimates of others provide evidence for some proposition.
- Ideally, we would want to do Bayesian Updating on the credences of others, but that often seems cognitively over-demanding.
- Hence, we want to find rules or heuristics that come reasonably close to Bayesian Updating, while remaining tractable.
- 'Upco'(short for ‘updating on the credences of others’) promises to be such a rule. Upco yields the same result as Bayesian Updating under some technical assumptions about the shape of our likelihood functions for someone's credence regarding some claim.
- Upco roughly requires you to set your odds for some proposition to the product of your prior odds and the odds of everyone whose credences you are updating on.
- It remains mostly unclear to me under which conditions we should have likelihood functions that entail Upco, and how much these assumptions can be relaxed so that Upco still closely approximates Bayesian Updating.
The problem
Your friend is going through an intense dinosaur phase. They have spent the last few weeks researching the Quetzalcoatlus northropi, an extinct species of giant flying reptiles that are believed to be among the largest flying animals of all time. When you see your friend, they successfully maneuver your conversation towards the megafauna. In passing, they claim that the largest Q. northopi had a wing span of over 12 meters. They show you this picture:
“This can't be true”, you resist. “No”, they say, “this is what the literature clearly suggests and I am about 90% confident in this”.
You know that your friend is scientifically trained. They are someone who dispassionately evaluates the literature and lets their beliefs be dictated purely by the forces of evidence and reason. Admittedly, they do a good job with that. You trust their judgement. So how should you respond epistemically when you hear their probability estimate (“credence”)? Should you increase your confidence in the claim?
Assuming that your friend started out much less than 90% confident that the Q. northropi had such a massive wingspan, they must have regarded their evidence as confirmatory, on balance. Since you believe that they responded reasonably to the evidence they saw, and since you know almost nothing about this topic, you seem to have good reason to increase your own confidence in this claim. By doing this, you can partially benefit from their research and expertise without having to do any research yourself.
If we abstract away from your friend and dinosaurs, it seems like you should at least sometimes revise your credences when you learn about the credences of others. But how?
Enter Bayesianism.
Bayesianism provides a general account of rational belief revision in response to evidence. As such, it should be equipped to deal with this case too. It would therefore be interesting to know the Bayesian response to learning the credences of others. But first: what precisely does Bayesianism say?
Introducing Bayesianism
All flavours of Bayesianism are committed to at least two normative claims:
- At any point in time, all your credences should be probabilities; they should be precise real numbers between 0 and 1 and they should obey the other axioms of probability theory. (Probabilism)
- If you receive some piece of evidence E regarding proposition A, then you should set your credence in A to the credence you would have previously given A if you hypothetically were to learn E. (Conditionalization)
The first claim is about what rational credences look like at any point in time - a view called “Probabilism”. The second claim is about how rational credences change over time, as evidence comes in - a process that’s called “Bayesian Updating” or “Conditionalization”. The credence you have before updating on some piece of evidence is called your “prior credence” (or “prior”) and the credence you have after updating is your “posterior credence” (or just “posterior”) relative to this piece of evidence.
I will leave you with this very brief overview since this post is not about Bayesianism in and of itself. If you’d like more details, I recommend you look here, here or here (in decreasing order of depth).
So, how would an ideal Bayesian update on the credences of others?
As a Bayesian, you might respond that someone's credence is just another type of evidence and there's no reason to treat it differently than "non-psychological evidence". Therefore the correct epistemic response to other people's credences is Bayesian Updating. Concretely, suppose that you have a credence p in proposition A (and a credence 1 -p in its negation), and you now encounter someone who reports a credence of q in the same proposition (and a credence 1 - q in its negation). I will write your credence in A as and Q’s credence in A as . Your posterior credence, after updating on someone else’s credence, I’ll write as . Bayesian Updating on Q’s credence would then look like this[1]:
Or, in terms of odds:
(It may seem strange to see probabilities of other probabilities. Maybe it helps to remind you that “Q(A) = q” is just the proposition “Q has credence q in A”.)
In summary, the credences of others seem to be a kind of evidence and Bayesianism seems to tell us, in some sense, how to respond to it. Unfortunately, using Bayes Theorem as a procedure to calculate our posteriors seems generally too computationally demanding to be feasible. Ideally, we want a much simpler rule that imitates or approximates Bayesian Updating in most cases. 'Upco'(short for ‘updating on the credences of others’) promises to be such a rule. Upco yields the same result as Bayesian Updating under some technical assumptions about the shape of our likelihood functions for someone's credence regarding some claim.
Upco
An informal argument for Upco
Before formally stating Upco, I want to provide a more informal and intuitive justification for Upco rather than just stating the technical assumptions and showing that it follows from those. You can find the latter in the appendix. (The following subchapter is from me and is not in the paper).
Think of other people's minds as black boxes that receive evidence on one side and output credences on the other. When we stand at the side where the credences come out, what we’d really like to do is to reach behind the box, grasp for the evidence and update our own credences accordingly. More precisely, we want to reach behind the box and get all the evidence, say all the observed coin flips[2], that we haven’t updated on yet. If the reason we want to update is to become more accurate, perhaps we don’t even care about the content of the evidence for its own sake - whether it was {Heads, Tails} or {Heads, Heads}. Our only concern might be the strength of the evidence in order to then update as though we had seen evidence of that same strength. Suppose this was the case. Is there any way you can infer the strength of the evidence that I have seen and you haven’t, regarding a proposition? (By “the strength of the evidence” I mean the strength that a rational agent would assign to it.)
I think you can infer that under some conditions: suppose you know for certain that I
- have seen evidence that is completely independent of yours assuming the truth of the claim in question,
- responded rationally to the evidence that I received and
- that I had a uniform prior at the very beginning, before receiving any evidence.
With assumptions (1) - (3) in mind, it seems like you can infer the strength of my evidence regarding A: it is equal to my current odds in A. Why?
The strength that a Bayesian assigns to some piece of evidence E with respect to proposition A can be measured as the factor by which learning E changed their odds in A (see Bayes factor); or put differently, their odds in A after learning E divided by their odds in A before learning E is the strength they assigned to E. A reasonable measure for the strength of all their evidence regarding A (as assessed by themselves) is then the ratio of their current odds and their initial odds, prior to updating on any evidence whatsoever. [3]
Since I had a uniform prior initially and thus odds of 1, the strength I assigned to all my evidence is thus just my current odds. Per assumption (2), this was a rational assessment of evidential strength. Because of that and since our evidence is completely independent (3), this is also the strength you should (rationally) have assigned to that evidence given all your evidence regarding the claim in question.
For example, suppose I first updated on a piece of evidence which increased my odds by a factor of 2. Then another piece of evidence came in that increased my odds by a factor of 1.5. The strength of all my evidence up until then would be 2 x 1.5 = 3, which is also my current odds - 3 x 1 = 3 - divided by my initial odds since they were equal to 1. Since you only care about the strength of my evidence and you know for certain that you should have assigned strength 3 to my evidence, you are satisfied to update your credence as though you had seen evidence of that exact strength.
Upco for one peer
And so we arrive at the odds version of Upco for partitions of the form and a single peer Q with . A “partition” means a set of mutually exclusive and collectively exhaustive propositions like {"Coin c landed heads", "Coin c did not land heads"}.
Alternatively, albeit not so intuitively, we can state Upco like this:
For an explanation of this formulation of Upco and a formal, rigorous justification of Upco, see the appendix.
It is important to note that it could still be rational to apply Upco even if the conditions I just mentioned - independent evidence, rational assessment of evidential strength and uniform prior - are not met. Assuming them makes the case for Upco especially intuitive for me, but they may not be necessary for Upco to imitate Bayesian Updating.
To understand Upco, we want to look at some examples. Let us first consider the simplest case in which you encounter one person, Q, who reports their credence in some proposition A and its negation.
Example 1. Your peer Q has 0.6 credence in proposition A and you currently have a credence of 0.3 in A. Now you both learn each other's credences. Upco tells you to update in the following way:
In this case, you both update towards each other and your credences end up closer to your prior than towards Q’s. A general lesson here is that when a set of peers all update on each other's credences using Upco, they will all have the same posterior credence, regardless of their priors.[4]
Also noteworthy is that in general for binary partitions , any credence above 0.5 in some proposition A is evidence for A and any credence below 0.5 is evidence against A. (This is especially clear when you look at the odds formulation of Upco). What happens when one's credence is exactly 0.5?
Example 2. P and Q respectively have credences 0.3 and 0.5 in A. Upon learning each other’s credence, Upco implies that:
Notice that P’s credence didn’t change at all. In general, if one peer’s credence - in this case, Q’s - is uniformly distributed across B and its alternatives, their credence does not constitute evidence with respect to B. They then adopt the credence of the other person in response to learning it. From one perspective this seems intuitive: if you haven’t seen any evidence in favour of or against B and therefore you have a uniform prior, or if your evidence seems to equally support B and -B, why would I update on your credence? It can be surprising, however, if we consider a scenario such as this:
Example 3. Suppose that I think that the probability of human extinction from AI this century is less than 0.01. Suppose also that some acclaimed AI safety researcher says that the odds are 50:50 that this will or will not happen this century. Upco tells me that I shouldn’t change my credence in “doom from AI this century” at all in response to learning their credences.
This example highlights that Upco is partition-dependent; if I had modelled the researcher as having a partition containing more than two propositions, Upco would imply that their credence is indeed evidence for the claim. Here we used a binary partition that collapses the possibilities of AI not ever causing human extinction or in some following century into one proposition: "AI does not cause human extinction this century". It seems more natural to have a partition with a separate proposition for each of those possibilities. In the next section, we will look at a generalization of Upco that can deal with this case in a more satisfying and intuitive way.
As we have just seen, Upco is very sensitive to the number of elements that a partition contains: the same credence in A could be seen as providing strong evidence in favour of A or strong evidence against A depending on the size of the partition that contains A. These problems aren’t unique to Upco. They arise in various places in the philosophy of probability theory (e.g. in the discussion of the indifference principle). Still, this seems like a serious problem. The paper argues that some partitions are preferable to others, but doesn’t provide a general account for dealing with this problem.
Arbitrary partitions
Thus far we have used Upco to update on the credences of others with respect to the binary partition This limits Upco’s usefulness quite a lot. For example, suppose you are trying to update on Q’s probability distribution over the years in which the first human will arrive on Mars:, , and so on for at least a few hundred other propositions.
You could collapse this into a binary partition: e.g. “Humans will arrive on Mars before 2035” and “Humans will not arrive on Mars before 2035”. But, as it happens, Q’s probability for arrival before 2035 is 50%. Therefore, as we discussed before, the simple Upco rule would tell us that Q’s credences provide no evidence at all about the arrival of humans on Mars. This seems wrong as Q does not have a uniform probability distribution and thus their evidence (in the way they interpreted it) does favour some years over others. This motivates a more general version of Upco that can handle more complex partitions.
Suppose you have a probability distribution over an arbitrary partition . Also, suppose that you want to update on the credences of Q who has the distribution over the same partition. Then applying this more general version of Upco to an arbitrary proposition
Alternatively, in odds form:
Here is an example of how to apply this rule.
Example 4. Let be a set of propositions. You have credence in each proposition and you now encounter peer Q who thinks that is much more plausible than the rest. Specifically, they report credence in and credence of in all of the other propositions. Using Upco, you update their credence as follows:
The point of this example is that the "break-even point"—the threshold beyond which someone's credence in provides evidence for —has shifted by a lot compared to earlier examples with binary partitions. For a binary partition, someone reporting credence 0.1 would be rather strong evidence against the claim in question whereas here it is the opposite. Since the partition contains 12 propositions, 0.1 is above the break-even point in this case (which is ). In general, if a partition consists of k propositions, then the break-even point is .
Multiple peers
Suppose you want to update on the credences of multiple peers Q, R,... with credences Upco easily generalizes to handle this case in the following way:
Or, equivalently, in the odds formulation:
Let us now look at an example which brings out an interesting feature of this version of Upco.
Example 5. Let B[5] be the proposition that “More than 10,000 people will have signed the Giving What We Can Pledge by 2025”. Q, R, and P give this claim credences of 0.7, 0.7, 0.4 respectively. If they are applying Upco, how will they update?
Thus, upon learning each other's credences all three should update towards 0.78 credence in B. Interestingly, this is higher than the prior credence of anyone in the group. This is a property of Upco that the EaGlHiVe (the authors) refers to as “synergy”.
Beyond peers
The versions of Upco that we have considered don’t give different weights to the credences of different people, even if one seems much more informed than the other. This may seem odd. Suppose a professor in climate science tells me that the probability of global warming of at least 2°C by 2030 is 20%. It seems like I should regard this as stronger evidence than if a random stranger told me the same thing. This points to yet another natural extension of Upco.
Let us also assume that the people who report their credence on some proposition - denoted as for person P, for Q etc. - have differing levels of epistemic reliability with respect to that proposition. We can track these differences by assigning higher weights to more reliable people. Since Upco is a multiplicative rule, we put these weights as exponents in our formula, and get the following most general Upco rule considered in the paper:
(General Upco)
Or in terms of odds:
As the EaGlHiVe notes, we need to give ourselves a weight of 1, or otherwise, Upco implies that we ought to update on our own credence. Then, if we regard someone as more reliable than us, we give them a weight larger than 1 and if we regard them as less reliable we give them a weight between 0 and 1.
In the case of the climate science professor, one might assign her a weight of 2, which is equivalent to saying that her credence provides twice as much evidence as someone with the same credence but with weight = 1. If she then reports a 20% credence in “2°C global warming by 2030”, we update on her credence as though she had reported the odds .[6]
This more general version of Upco is useful in other ways. For example, we can use it to discount the credences of two peers, Q and R, if they have come to their credences in A on the basis of evidence sets and that are probabilistically dependent conditional on A. For example, if we were certain that one peer R has seen the exact same series of coinflips as another Q, we might not want to update on R’s credence at all after seeing Q’s. We can then assign R an exponent of 0.
A general account of how we ought to assign these weights seems to await further research.
Properties of Upco
To sum up, here are the most important properties of Upco:
- Using Upco mimics Bayesian updating for an agent P and some proposition A if P has a likelihood function for another agent Q that is proportional to Q’s credence in A. This is sufficient but perhaps not necessary for Upco to mimic Bayesian updating.
- Upco is commutative in two ways.
- It is commutative with Bayesian updating itself. That is, it does not matter for an agent's subsequent credence whether they first update on the credences of some other agent(s) using Upco, and then on some other evidence E in the normal Bayesian way, or vice versa; Upco is simply not sensitive to the order.
- Upco is also commutative with respect to the credences of others, such that Upco will require an agent to have the same posterior credence regardless of the order in which the agent updated on other credences.
- Independence preservation (in the case of an arbitrary partition).
- Suppose we have two partitions and . Further, suppose that and . Then after updating on Q's credences.
- Upco is synergistic.
- That is, suppose and . Then it is not necessarily the case that are in the interval . At first sight, this might seem undesirable, but suppose this was not the case. This would imply that the credence of someone less confident than you can never be positive evidence regarding the proposition at hand. Suppose you are 95% sure that A is true. Now, for any credence smaller than 95% you would have to update downwards or not update at all. Even if someone were perfectly rational, has a 94.9% credence in A and has evidence completely independent from yours, you would have to regard their credence as either no evidence or disconfirming evidence.
- Less desirably, Upco is partition-dependent: the strength and direction of the evidence that someone's credence in A provides depends heavily on the assumed size of the partition that A is part of.
- In general, if a partition consists of k propositions, someone's credence provides evidence in favour of some proposition when it exceeds 1/k.
- If one peer’s credence is uniformly distributed across proposition B and its alternatives, then they adopt the credence of another person in response to learning it.
- When a set of peers all update on each other's credences using Upco, then they will all have the same posterior credence, regardless of their priors.
Concluding remarks
(Some more subjective, half-baked takes from me personally. Caveat: I'm not a philosopher.)
I thought this paper was extremely insightful and well-written.
That said, one of my main critiques of the paper concerns their notion of "epistemic peers". The authors use this term quite differently than most people in the literature, where epistemic peerhood tends to be tied to parity of epistemic virtues or equal familiarity with the relevant evidence. The EaGlHiVe instead defines epistemic peers as anyone who you think has formed their credence in the proposition in a reasonable way, based on evidence and reasoning that probably differs from your own. They thus seem to engage with this literature when it's actually unclear to me if they do (because it's unclear to what extent their claims also apply to the standard concept). I'm not sure why they didn't use a different concept to avoid such confusion. Also, they aren’t very clear on what they mean by "epistemic peers". As a result, I'm still unsure precisely when we are supposed to apply Upco from the author's perspective. This is because they recommend the use of Upco whenever one encounters the credences of epistemic peers and this is a vaguely defined concept. Another way to put the question is: precisely when is it rational to have the kinds of likelihood functions such that Upco yields the same updates as a Bayesian agent with these functions?
Upco is entailed by a wide set of likelihood functions. I'm therefore somewhat optimistic that using Upco at least closely approximates an ideal bayesian agent in many cases, even if it doesn't lead to the exact same updates.
A prominent alternative to Upco is the Linear Average: just set your posterior credence to the (weighted) average of your credence and those of others (e.g. your epistemic peers and superiors). In terms of theoretically desirable properties, Upco seems clearly better to me than taking the weighted average of your peers' credences (see appendix A). This makes me hopeful that using Upco, even in its unextended form without weights, is an improvement over using the Linear Average in most cases.
Ultimately, I’m sceptical that these theoretical properties matter intrinsically. I tend to think that the best updating rule is the one that leads to the best (expected) “epistemic outcomes”, e.g. the highest expected improvement in belief accuracy. On this view, these theoretical properties matter only in so far as they improve such outcomes. From what I understand, Greaves and Wallace (2006) argue that Bayesian Updating is the unique updating rule to maximise some measure of good epistemic outcomes. (Caveat: I have only skimmed that paper). If that's correct and if Upco better approximates Bayesian Updating than the Linear Average, then I would expect Upco to lead to better epistemic outcomes. Still, this feels quite speculative and I would like to test this empirically, but I'm still unsure how to best do this.
Some of my open questions about Upco
- How large is the set of likelihood functions that entail Upco? Can we characterise this set of functions more precisely?
- How strong is the “intuitive argument” I gave for Upco at the beginning of the Upco section?
- Is it reasonable to assume that every peer of mine has a uniform ur-prior?
- Do people that I should regard as peers ever have credence 0 or 1 in a proposition?
If so, such cases seem to favour LA over Upco, since Upco is then undefined and LA is (almost always) not. - How do we best account for the fact that peers share evidence and that their credences are thus not conditionally independent? If using weights other than 1 as exponents in the Upco formula is the right approach, how should we choose these weights?
- What are the most promising approaches to deal with the problem of partition dependence? The result of applying Upco heavily depends on the assumed partition over which someone reports their credence and often there is (I think) not a natural or obviously best choice.
- How could we empirically test and compare the performance of Upco against other rules?
- Upco is curiously similar to the aggregation method that Jaime Sevilla advocated on the forum (the geometric mean of odds) - why is that?
If you have any thoughts on these questions, please share them in the comments or via direct message!
Acknowledgements
Big thanks to Lorenzo Pacchiardi, Amber Dawn and Kaarel Hänni for the discussion and their insightful comments. I'm also grateful to Kenny Easwaran for patiently answering many of my questions and providing extensive feedback. Most of all, I want to thank Sylvester Kollin for his tremendous help with understanding the paper and co-writing parts of this post.
Appendix A: The Linear Average as an updating rule
Suppose you regard Q as your epistemic peer. The EaGlHiVe defines an "epistemic peer" as anyone who you think has formed their credence in the proposition in a reasonable way, based on evidence and reasoning that probably differs from your own.[7]
A simple rule for updating on the credence of Q is then to take the Linear Average (LA) of both your credences and let this be your posterior credence. In the simplest case, every credence receives the same weight:
Or in the case of n peers (with respective credences ):
We can generalize LA to cases where we want to update on the credences of people with different levels of epistemic reliability - e.g. different degrees of expertise or access to evidence in the relevant domain - by instead taking the weighted sum of the credences of others, where higher weights may correspond to higher degrees of reliability. This proposal has been made by many people in some form, both in the academic literature and on the EA Forum.
Unfortunately, the LA has some undesirable properties (see section 4 of the paper):
- Applied in the way sketched above, LA is non-commutative, meaning that LA is sensitive to the order in which you update on the credences of others, and it seems like this should be completely irrelevant to your subsequent beliefs.
- This can be avoided by taking the “cumulative average” of the credences of the people you update on, i.e. each time you learn someone's credence in A you average again over all the credences you have ever learned regarding this proposition. However, now the LA has lost its initial appeal; for each proposition you have some credence in, rationality seems to require you to keep track of everyone you have updated on and the weights you assigned to them. This seems clearly intractable once the number of propositions and learned credences grows large.
- See Gardiner (2013) for more on this.
- Relatedly, LA is also sensitive to whether you update on multiple peers at once or sequentially.
- Also, LA does not commute with Bayesian Updating. There are cases where it matters whether you first update on someone's credence (e.g. regarding the bias of a coin) using the LA and then on “non-psychological” evidence (e.g. the outcome of a coin-flip you observed) using Bayesian Updating or the reverse.
- Moreover, LA does not preserve ‘judgments of independence’. That is, if two peers judge two propositions A and B to be independent, i.e. and , then after updating on each other's credences, independence is not always preserved. This seems intuitively undesirable: if you think that the outcome of (say) a coin flip and a die roll are independent and I think the same - why should updating on my credences change your mind about that?
- LA does not exhibit what the authors call “synergy”. That is, suppose and . Then it is necessarily the case that , are in the interval if they are both applying LA. In other words, using the LA never allows you to update beyond the credence of the most confident person you’ve updated on (or yourself if you are more confident than everybody else).
- At first sight, this might seem like a feature rather than a bug. However, this means that the credence of someone less confident than you can never be positive evidence regarding the issue at hand. Suppose you are 95% sure that A is true. Now, for any credence smaller than 95% LA would demand that you update downwards. Even if someone is perfectly rational, has a 94.9% credence in A and has evidence completely independent from yours, LA tells you that their credence is disconfirming evidence.
Perhaps most importantly, since Bayesian Updating does not have these properties, LA does not generally produce the same results. Thus, insofar as we regard Bayesian updating as the normative ideal, we should expect LA to be at best an imperfect heuristic and perhaps not even that.
In sum, LA has a whole host of undesirable properties. It seems like we therefore would want an alternative rule that avoids these pitfalls while retaining the simplicity of LA.
The EaGlHiVe aims to show that such a rule exists. They call this rule “Upco”, standing for “updating on the credences of others”. Upco is a simple rule that avoids many of the problems of LA: preservation of independence, commutativity, synergy, etc. Moreover, Upco produces the same results as Bayesian Updating under some conditions.
Appendix B: A formal justification for Upco
One way of formally justifying Upco is by making two assumptions about the likelihood of someone reporting a given credence. The assumptions are quite technical and probably only understandable for someone with some prior knowledge of probability theory. I think you can safely skip them and still get something out of this post. The assumptions are:
- the density function for the likelihood of Q reporting a given credence level q in A given that A is true, i.e. , is proportional to q itself; i.e.
where is a normalizing constant and is some integrable, strictly positive function on the interval . - the density function for the likelihood of them reporting a given credence level q in A given that A is false, i.e. , is proportional to ; i.e., where again is a normalizing constant and is some integrable, strictly positive function on the interval .
Examples of density functions that would satisfy (1) and (2) are the beta distributions and , where is the density for and is the density for , for any positive real number x. If both conditions hold, then and cancel each other out (in the odds formulation of Bayes theorem) so that we’re left with Upco:
(From Bayes Theorem)
(From 1. and 2.)
And therefore:
(Upco)
Or, not in terms of odds:
Here are two possible pairs of densities for likelihood functions that would satisfy (1) and (2):
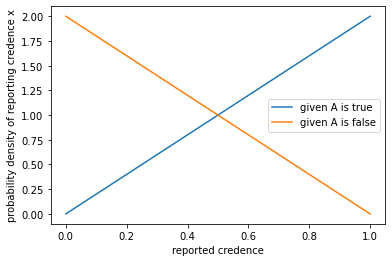
Or,
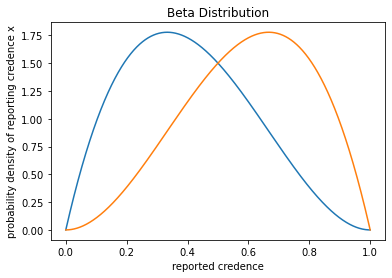
Also note, that these conditions are sufficient for Upco to give the same results as Bayesian updating, but they are not strictly necessary. There may be other likelihood functions that do not satisfy (1) and (2) but still would yield the same result as Upco. It is also possible that Upco approximates Bayesian updating even if it doesn’t mimic it for an even wider range of likelihood functions. To what extent that’s the case is still unclear to me.
- ^
For the sake of simplicity, we assume here that Q(A) is a discrete variable. This assumption will be relaxed later.
- ^
We are figuring out the bias of the coin.
- ^
This follows both from rearranging Bayes Theorem and from viewing the strength of some piece of evidence E regarding proposition H as the ratio P(E|H)/P(E|-H). There’s some discussion of alternative measures like the difference or ratio between posterior and prior credences (not odds). This paper seems to provide a good overview of the relative merits of such different measures.
- ^
Note that UpCo gives undefined results when you are updating on peers with extreme credences (0 or 1). In that case, your odds would be 0 or undefined.
- ^
For simplicity assumed to be part of a binary partition.
- ^
Strangely, it seems like one is treating her as if she had reported a much lower credence than 0.2. This seems odd because it suggests that I regard her as epistemically superior to me (with respect to this claim) and I also believe her to “under respond” to the evidence available to her; I think she should be more confident than she is in this claim.
These two beliefs seem to be in tension: it is a bit like saying that Magnus Carlsen made a mistake with some chess move, whilst simultaneously saying that he is a far superior chess player to you, and thus has a much better idea of what a good move would be.
- ^
The “differs from your own” clause is here to bar against situations in which your credences are based on the exact same evidence, in which case the other agent’s credence may not provide evidence regarding the claim in question. Kenny Easwaran told me that a large part of the literature on peer disagreement assumes that epistemic peers have the same evidence. He says that while their paper, therefore, doesn’t directly engage with this literature, “Synergy” might sometimes be plausible even under this more common conc
- ^
As I understand it, epistemic utility functions are functions from the state of the world and one's probability assignments to real numbers. The epistemic utility functions considered in the paper seem to have in common that, other things being equal, the closer one's probability judgement p(A) is to the truth value of A, the higher the epistemic utility.
- ^
Note that Greaves and Wallace (2006) argue that Bayesian Updating is the unique updating rule to maximise some measure of good epistemic outcomes. I haven’t read that paper so I won’t comment on it.
- ^
This seems particularly clear when you look at the odds formulation of Upco.
A recent and related paper: Jeffrey Pooling by Pettigrew and Weisberg. Abstract (bold emphasis mine):
Also, Pooling: A User’s Guide by the same authors. Abstract (where Upco is one specific multiplicative method):
Hey it's cool that this got written up. I've only read your summary, not the paper, and I'm not an expert. However, I think I'd argue against using this approach, and instead in favour of another. It seems equivalent to using ratios to me, and I think you should use the geometric mean of odds instead when pooling ideas together (as you mentioned/asked about in your question 7.). The reason is that Upco uses each opinion as a new piece of independent evidence. Geometric mean of odds merely takes the (correct) average of opinions (in a Bayesian sense).
Here's one huge problem with the Upco method as you present it: two people think that it's a 1/6 chance of rolling a six on a (fair) die. This opinion shouldn't change when you update on others' opinions. If you used Upco, that's a 1:5 ratio, giving final odds of 1:25 - clearly incorrect. On the other hand, a geometric mean approach gives sqrt((1*1)/(5*5))=1:5, as it should be.
You can also pool more than two credences together, or weight others' opinions differently using a geometric mean. For example, if I thought there was a 1:1 chance of an event, but someone whose opinion I trusted twice as much as myself put it at 8:1 odds, then I would do the following calculation, in which we effectively proceed as if we have three opinions (mine and another person's twice), hence we use a cube root (effectively one root per person):
cube root((1*8*8)/(1*1*1)=4
So we update our opinion to 4:1 odds.
This also solves the problem of Upco not being able to update on an opinion of 50/50 odds (which I think is a problem - sometimes 1:1 is definitely the right credence to have (e.g. a fair coin flip)). If we wanted to combine 1:1 odds and 1:100 000 odds, it should land in the order of somewhere in between. Upco stays at ((1*1)/(1*100 000))=100 000 (i.e. 1:100 000), which is not updating at all using the 1:1. Whereas the geometric mean gives sqrt((1*1/1*100 000)=1:100. 1:100 is a far more reasonable update from the two of them.
In terms of your question 3, where people have credences of 0 or 1, I think some things we could do are to push them to use a ratio instead (like asking if rather than certain, they'd say 1 in a billion), weight their opinions down a lot of they seem far too close to 0 or 1, or just discount them if they insist on 0 or 1 (which is basically epistemically inconceivable/incorrect from a Bayesian approach).
Hey Daniel,
thanks for engaging with this! :)
You might be right that the geometric mean of odds performs better than Ucpo as an updating rule although I'm still unsure exactly how you would implement it. If you used the geometric mean of odds as an updating rule for a first person and you learn the credence of another person, would you then change the weight (in the exponent) you gave the first peer to 1/2 and sort of update as though you had just learnt the first and second persons' credence? That seems pretty cumbersome as you'd have to keep track of the number of credences you already updated on for each proposition in order to assign the correct weight to a new credence. Even if using the geometric mean of odds(GMO) was a better approximation of the ideal bayesian response than Upco (which to me is an open question), it thus seems like Upco is practically feasible and GMO is not.
If one person reports credence 1/6 in rolling a six on a fair die and this is part of a partition containing one proposition for each possible outcome {"Die lands on 1", Die lands on 2", ... "Die lands on 6"}, then the version of upco that can deal with complex partitions like this will tell you not to update on this credence (see section on "arbitrary partitions"). I think the problem you mention just occurs because you are using a partition that collapses all five other possible outcomes into one proposition - "the die will not land on 6".
This case does highlight that the output of Upco depends on the partition you assume someone to report their credence over. But since GMO as an updating rule just differs from Upco in assigning a weight of 1/n to each persons credence (where n is the number of credence already learned), I'm pretty sure you can find the same partition dependence with GMO.