AI safety is one of the most critical issues of our time, and sometimes the most innovative ideas come from unorthodox or even "crazy" thinking. I’d love to hear bold, unconventional, half-baked or well-developed ideas for improving AI safety. You can also share ideas you heard from others.
Let’s throw out all the ideas—big and small—and see where we can take them together.
Feel free to share as many as you want! No idea is too wild, and this could be a great opportunity for collaborative development. We might just find the next breakthrough by exploring ideas we’ve been hesitant to share.
A quick request: Let’s keep this space constructive—downvote only if there’s clear trolling or spam, and be supportive of half-baked ideas. The goal is to unlock creativity, not judge premature thoughts.
Looking forward to hearing your thoughts and ideas!
P.S. You answer can potentially help people with their career choice, cause prioritization, building effective altruism, policy and forecasting.
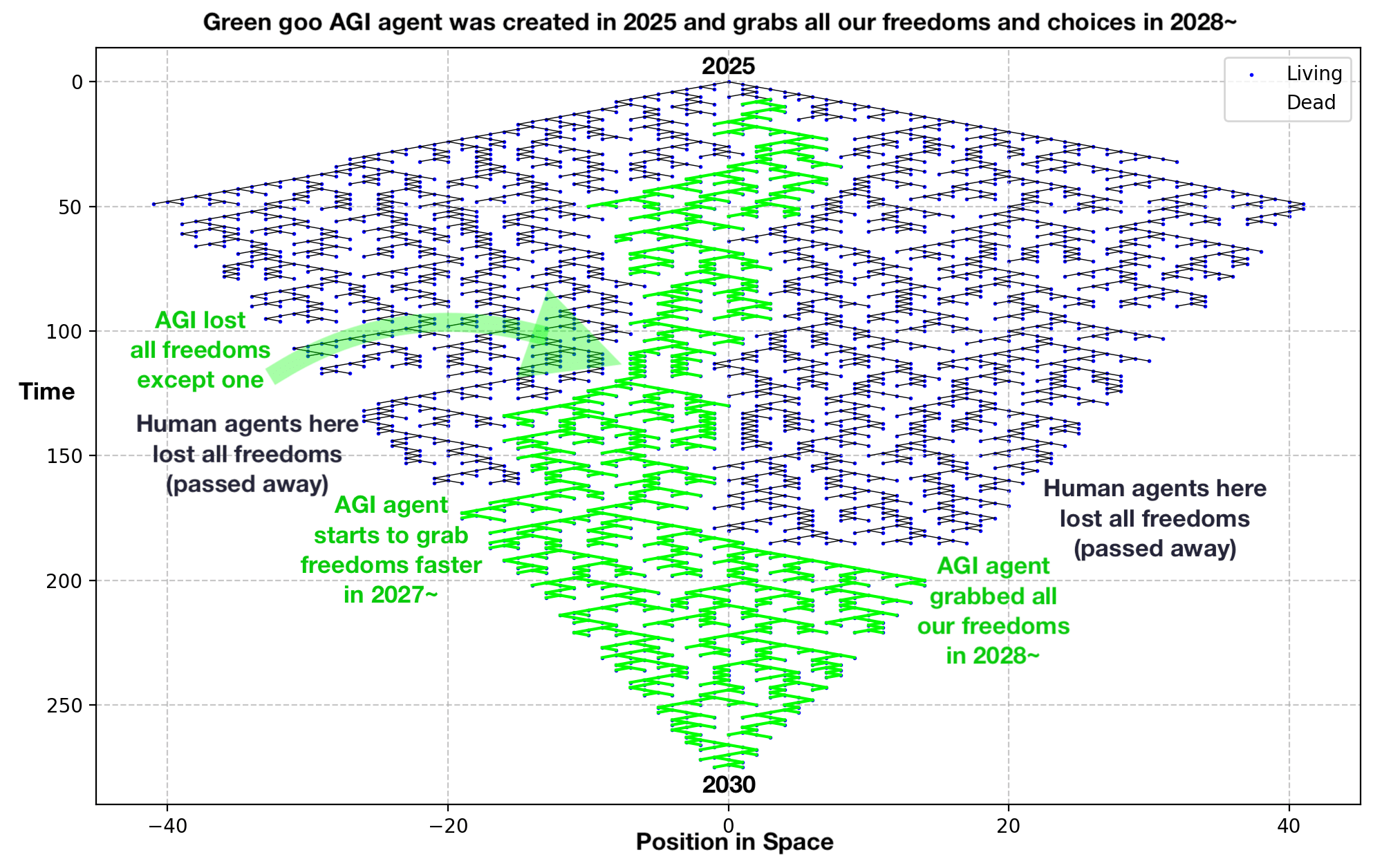
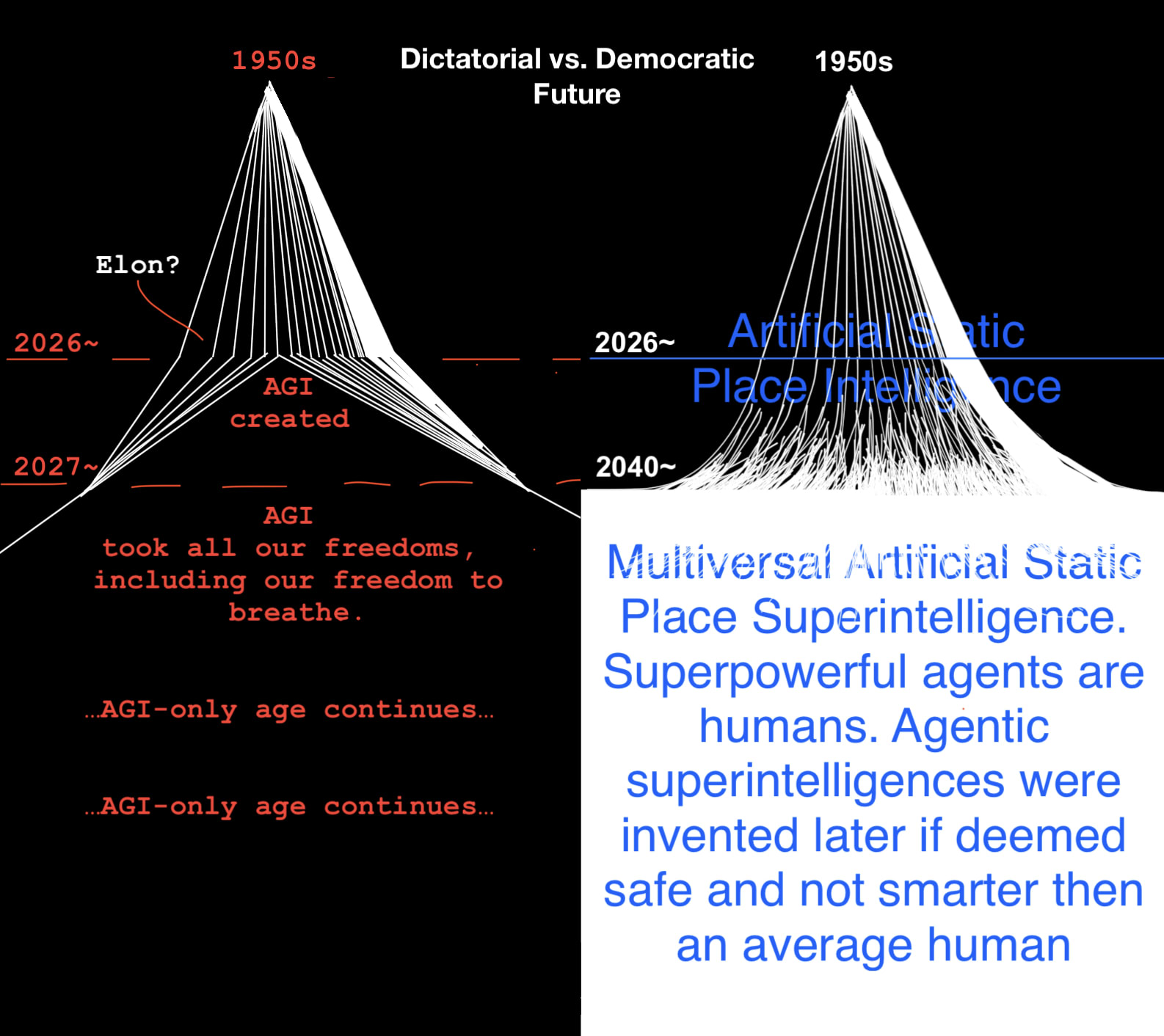
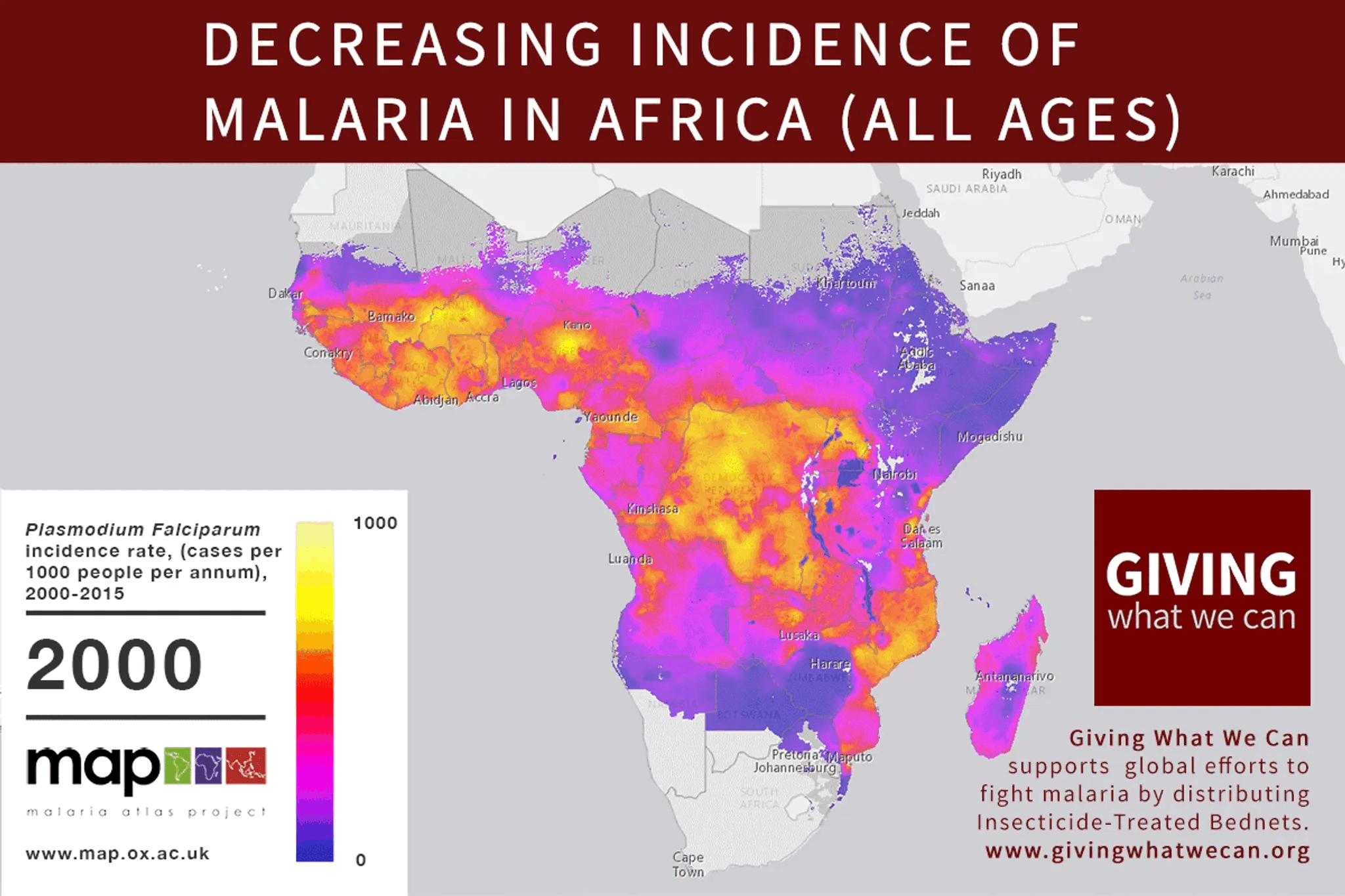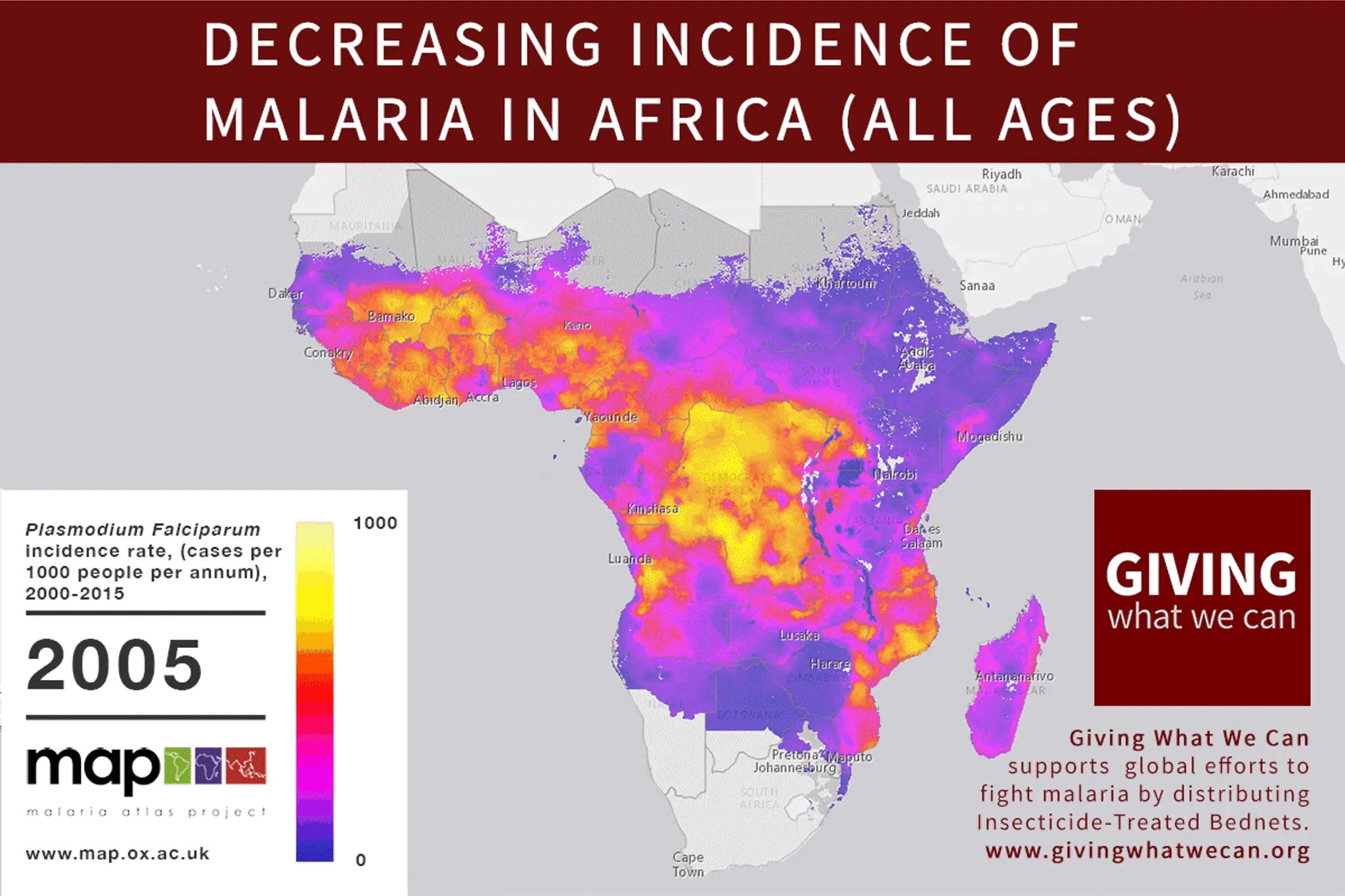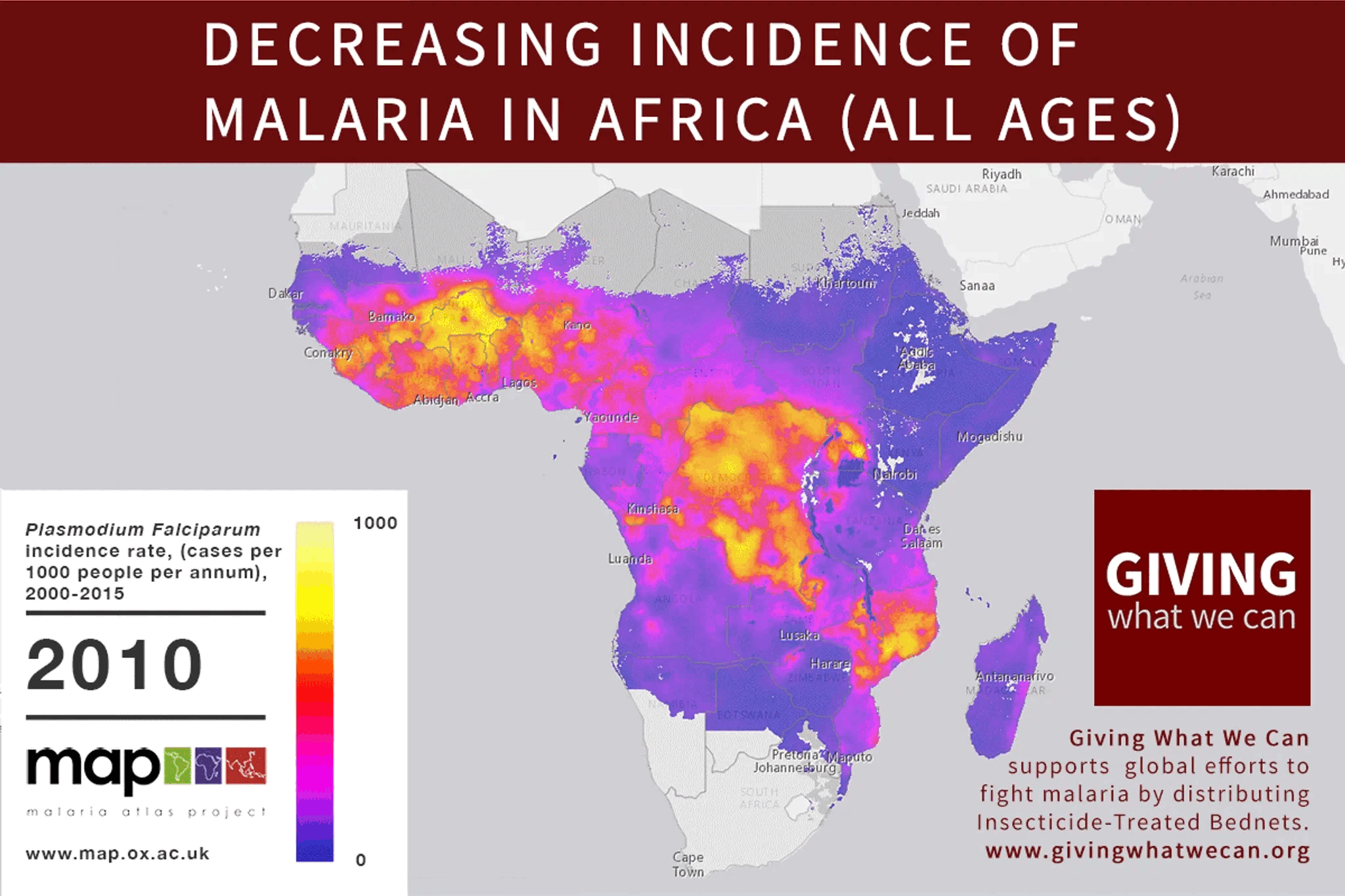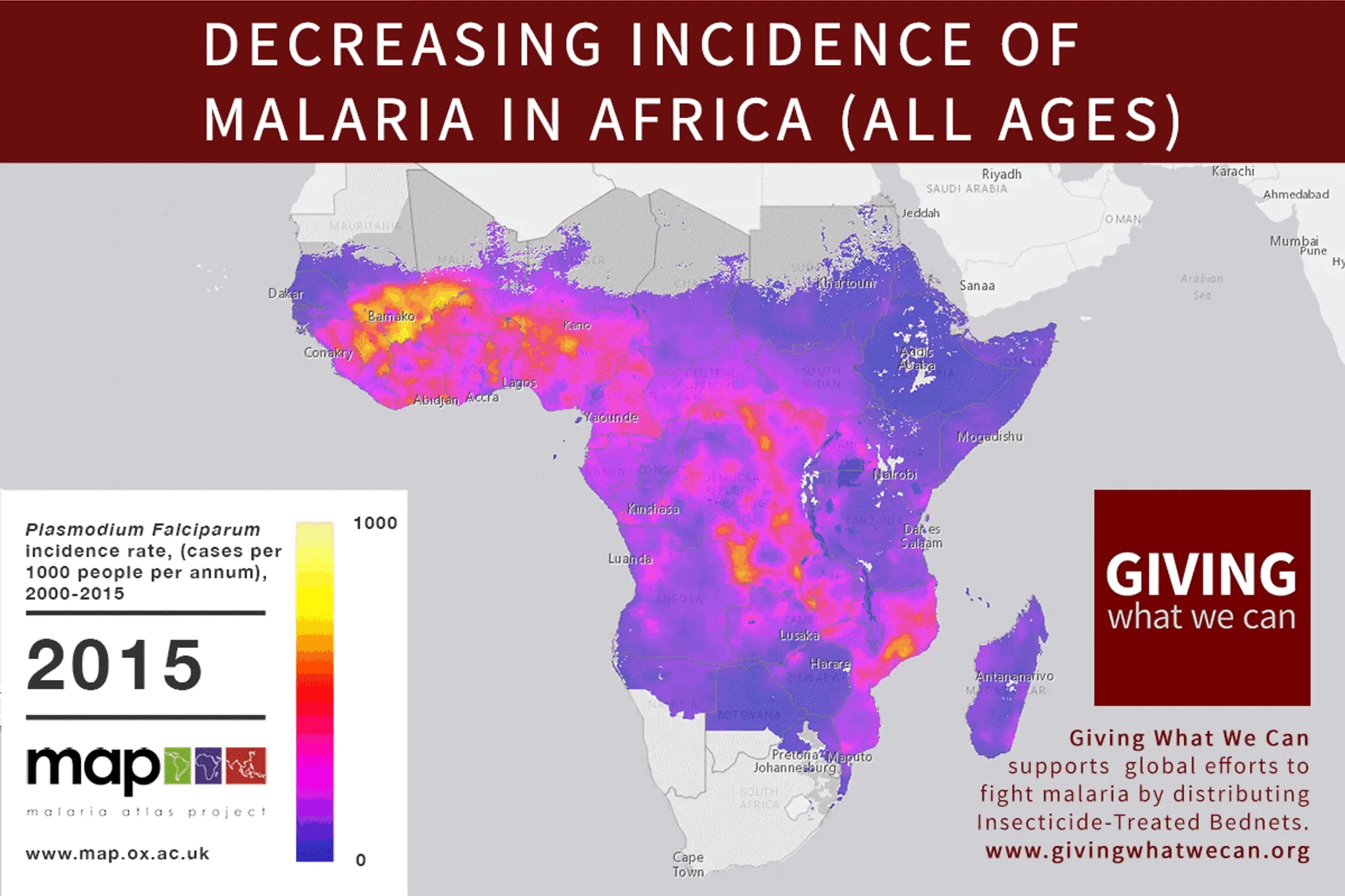

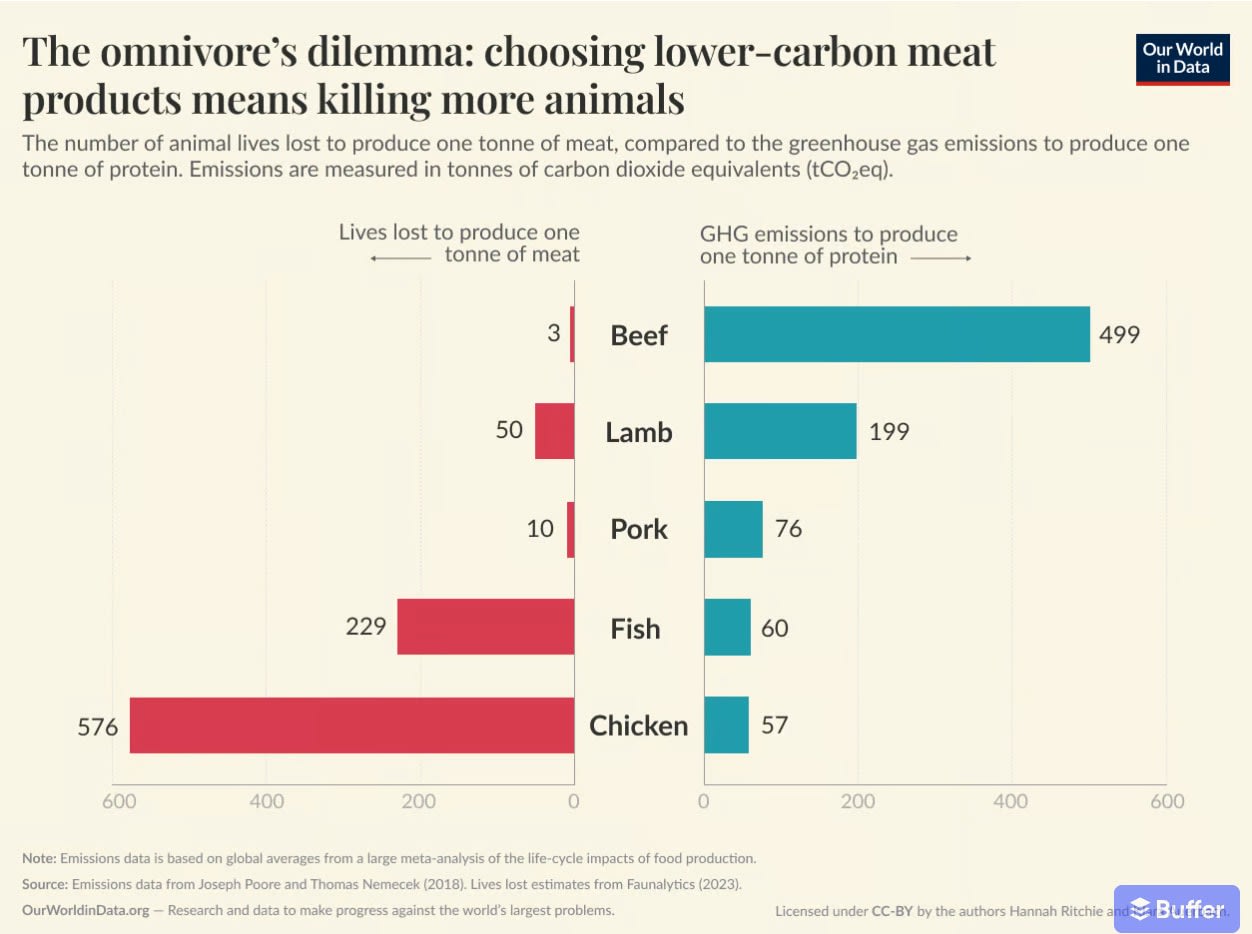
👍 I’m a proponent of non-agentic systems, too. I suspect, the same way we have Mass–energy equivalence (e=mc^2), there is Intelligence-Agency equivalence (any agent is in a way time-like and can be represented in a more space-like fashion, ideally as a completely “frozen” static place, places or tools).
In a nutshell, an LLM is a bunch of words and vectors between them - a static geometric shape, we can probably expose it all in some game and make it fun for people to explore and learn. To let us explore the library itself easily (the internal structure of the model) instead of only talking to a strict librarian (the AI agent), who prevents us from going inside and works as a gatekeeper