Comments
55


This post argues that P(misalignment x-risk | AGI) is lower than anticipated by alignment researchers due to an overlooked goal specification technology: law.
P(misalignment x-risk | AGI that understands democratic law) < P(misalignment x-risk | AGI)
This post sheds light on a neglected mechanism for lowering the probability of misalignment x-risk. The mechanism that is doing the work here is not the enforcement of law on AGI. In fact, we don’t discuss the enforcement of the law at all in this post.[1] We discuss AGI using law as information. Unless we conduct further research and development on how to best have AGI learn the law and how we can validate a computational understanding of the law as capabilities scale to AGI, it is less likely that AGI using law as information reduces misalignment x-risk. In other words, we do not believe that alignment will be easy; we believe it will involve difficult technical work, but that it will be different than finding a one-shot technical solution to aligning one human to one transformative AI.[2]
Specifically, there is lower risk of bad outcomes if AGI can learn to follow the spirit of the law. This entails leveraging exclusively humans (and not AI in any significant way) for the “law-making” / “contract-drafting” part (i.e., use the theory and practice of law to tell agents what to do), and build AI capabilities for the interpretation of the human directives (machine learning on data and processes from the theory and practice of law about how agents interpret directives, statutes, case law, regulation, and “contracts”).
At a high level, the argument is the following.
The implications of this argument suggest we should invest significant effort into the following three activities.
If one does not agree with the argument and is concerned with AGI risks, they should still pursue Activity 1. (R&D for AI understanding law) because there is no other legitimate source of societal values to embed in AGI (see the section below on Public law, and Appendix B). This holds true regardless of the value of P(misalignment x-risk | AGI).
The rest of this post provides support for the argument, discusses counterarguments, and concludes with why there is no other legitimate source of societal values to embed in AGI besides law.
The sociology of finance has advanced the idea that financial economics, conventionally viewed as a lens on financial markets, actually shapes markets, i.e., the theory is “an engine, not a camera.”[5] Law is an engine, and a camera. Legal drafting and interpretation methodologies refined by contract law – an engine for private party alignment – are a lens on how to communicate inherently ambiguous human goals. Public law – an engine for societal alignment – is a high-fidelity lens on legitimately endorsed values.
It is not possible to manually specify or automatically enumerate a discernment of humans’ desirability of all actions an AI might take in any future state of the world.[6] Similar to how we cannot ex ante specify rules that fully and provably direct good AI behavior, parties to a legal contract cannot foresee every contingency of their relationship,[7] and legislators cannot predict the specific circumstances under which their laws will be applied.[8] That is why much of law is a constellation of legal standards that fill in gaps at “run-time” that were not explicitly specified during the design and build process.
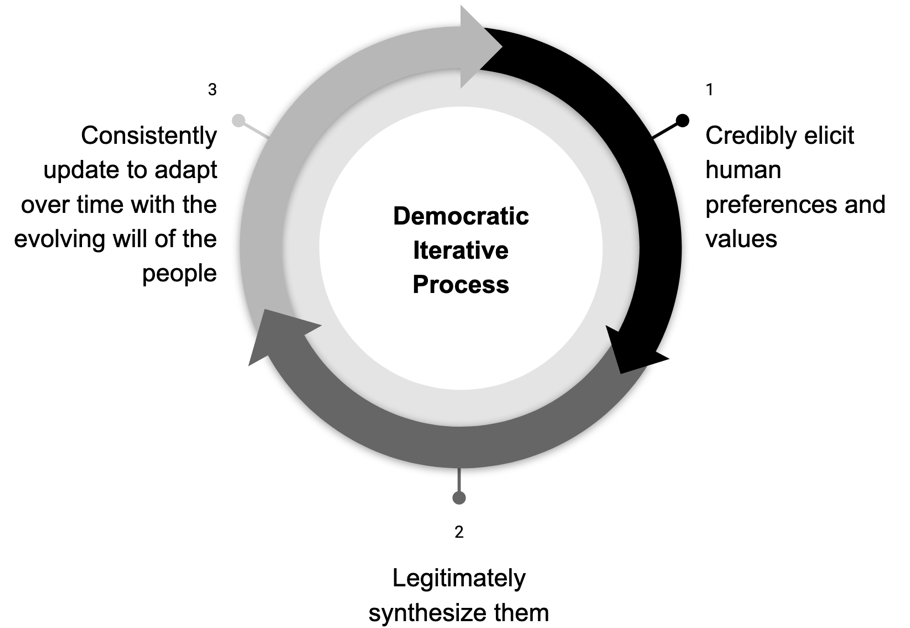
Methodologies for making and interpreting law – where one set of agents develops specifications for behavior, another set of agents interprets the specifications in novel circumstances, and then everyone iterates and amends the specifications as needed – have been refined by legal scholars, attorneys, businesses, legislators, regulators, courts, and citizens for centuries. Law-making within a democracy is a widely accepted process – implemented already – for how to credibly elicit human preferences and values, legitimately synthesize them, and consistently update the results to adapt over time with the evolving will of the people.
If we re-ran the "simulation" of humanity and Earth a few times, what proportion of the simulations would generate the democratic legal system? In other words, how much of the law-making system is a historical artifact of relatively arbitrary contingencies of this particular history and how much of it is an inevitability of one of the best ways to organize society and represent the values of humans? The only evidence we have is within the current “simulation,” and it seems that it is far from perfect but is the best system for maximizing human welfare.
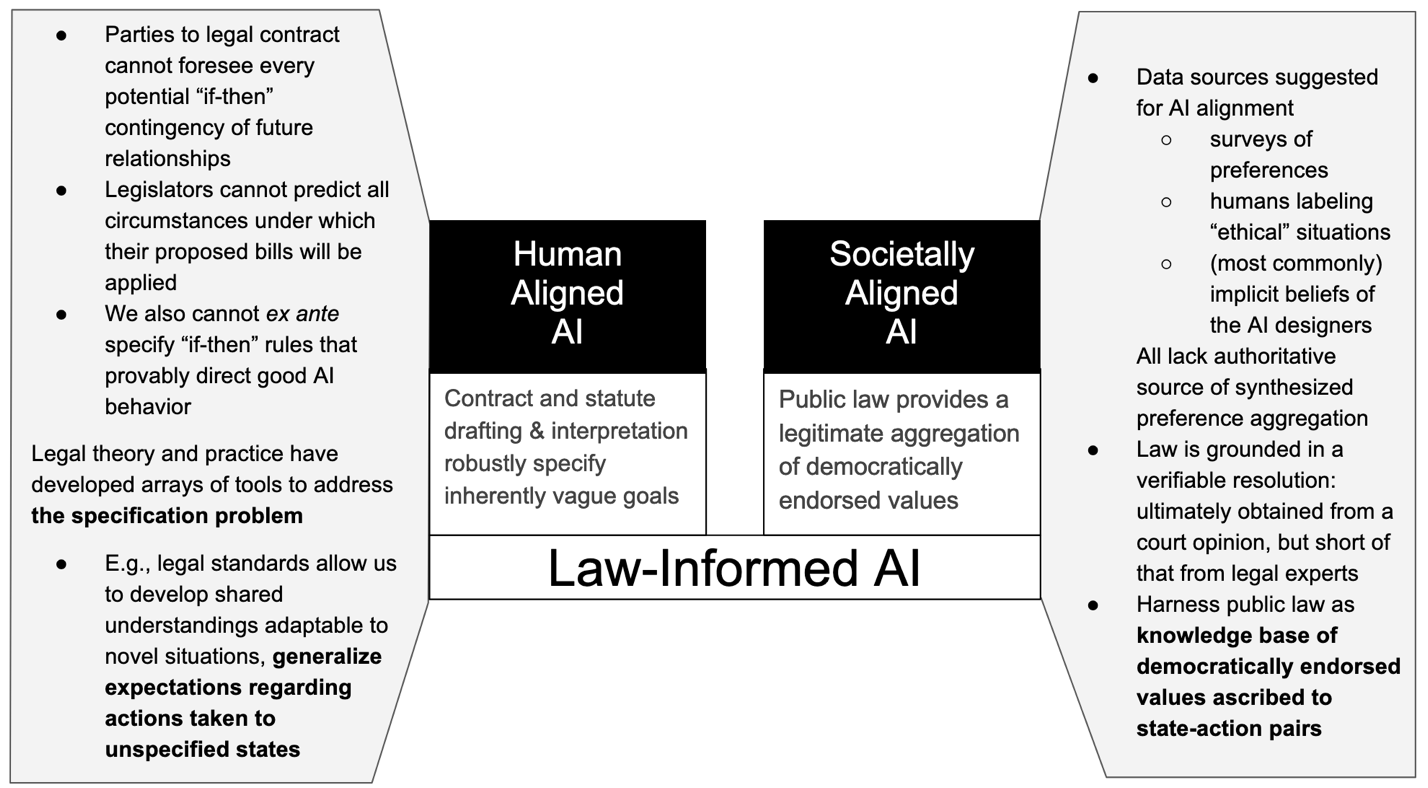
Law can inform AI and reduce the risk of the misspecification of AI objectives through two primary channels.
Law is unique. It is deeply theoretical but its theories are tested against reality and refined with an unrelenting cadence. Producing, interpreting, enforcing, and amending law is a never-ending society-wide project. The results of this project can be leveraged by AI as an expression of what humans want[9] and how they communicate their goals under radical uncertainty.
This post is not referring to the more prosaic uses of law, e.g., as an ex-ante deterrent of bad behavior through the threat of sanction or incapacitation[10] or imposition of institutional legitimacy;[11] or as an ex-post message of moral indignation.[12] We are instead proposing that law can inform AI in the tradition of “predictive” theories of the law.[13]
Empirical consequences of violating the law are data for AI systems. Enforcing law on AI systems (or their human creators) is out of scope of our argument. From the perspective of an AI, law can serve as a rich set of methodologies for interpreting inherently incomplete specifications of collective human expectations.[14] Law provides detailed variegated examples of its application, generalizable precedents with accompanying informative explanations, and human lawyers to solicit targeted model fine-tuning feedback, context, and model prompting to embed and deploy up-to-date comprehension of human and societal goals.
We should engineer legal data (both natural observational data and data derived from human interaction with AI) into training signals to align AI. Toward this end, we can leverage recent advancements in machine learning, in particular, natural language processing[15] with large language models trained with self-supervision; deep reinforcement learning; the intersection of large language models and deep reinforcement learning;[16] and research on “safe reinforcement learning”[17] (especially where constraints on actions can be described in natural language[18]).
Combining and adapting the following three areas of AI capabilities advances could allow us to leverage billions of state-action-value tuples from (natural language) legal text within an AI decision-making paradigm.
Legal informatics can be employed within AI agent decision-making paradigms in a variety of ways:
Where legal informatics is providing the modular constructs (methods of statutory interpretation, applications of standards, and legal reasoning more broadly) to facilitate the communication of what a human wants an AI system to do, it is more likely it is employed for specifying, learning and shaping reward functions. Where legal informatics, through distillations of public law and policy, helps specify what AI systems should not do, in order to provide a legitimate knowledge base of how to reduce societal externalities, it is more likely employed as action constraints.
Prosaic AI (large language models, LLMs, or, more generally: “Foundation Models”) is likely capable enough, with the right fine-tuning and prompting, to begin to exhibit behavior relatively consistent with legal standards and legal reasoning.
“Legal decision-making requires context at various scales: knowledge of all historical decisions and standards, knowledge of the case law that remains relevant in the present, and knowledge of the nuances of the individual case at hand. Foundation models are uniquely poised to have the potential to learn shared representations of historical and legal contexts, as well as have the linguistic power and precision for modeling an individual case.”[30]
Foundation Models in use today have been trained on a large portion of the Internet to leverage billions of human actions (as expressed through natural language). Training on high-quality dialog data leads to better dialog models[31] and training on technical mathematics papers leads to better mathematical reasoning.[32] It is likely possible to, similarly, leverage billions of human legal data points to build Law Foundation Models through language model self-supervision on pre-processed, but still largely unstructured, legal text data.[33] A Law Foundation Model would sit on the spectrum of formality and structure of training data somewhere between a model trained on code (e.g., Copilot) and a model trained on general internet text (e.g., GPT-3). Law is not executable code, but it has much more structure to it than free-form blog posts, for example.
Legal standards can be learned directly from legal data with LLMs.[34] Fine-tuning of general LLMs on smaller labeled data sets has proven successful for learning descriptive “common-sense” ethical judgement capabilities,[35] which, from a technical (but, crucially, not normative) perspective, is similar to the machine learning problem of learning legal standards from data.
LLMs trained on legal text learn model weights and word embeddings specific to legal text that provide better performance on downstream legal tasks[36] and have been useful for analyzing legal language and legal arguments,[37] and testing legal theories.[38] LLMs’ recent strong capabilities in automatically analyzing (non-legal) citations[39] should, after appropriate adaptation, potentially boost AI abilities in identifying relevant legal precedent. LLM capabilities related to generating persuasive language could help AI understand, and thus learn from, legal brief text data.[40]
In many cases, LLMs are not truthful,[41] but they have become capable of more truthfulness as they are scaled.[42] LLMs are beginning to demonstrate improved performance in analyzing legal contracts,[43] and as state-of-the-art models have gotten larger, their contract analysis performance has improved,[44] suggesting we can expect continued advancements in natural language processing capabilities to improve legal text analysis as a by-product, to some extent and in some legal tasks and legal domains.[45] AI capabilities research could potentially unlock further advances in the near-term. For instance, the successful application of deep reinforcement learning further beyond toy problems (e.g., video games and board games), with human feedback,[46] and through offline learning at scale.[47]
Legal informatics could convert progress in general AI capabilities advancements into gains in AI legal understanding by pointing the advancing capabilities, with model and process adaptations, at legal data.
For instance, we can codify examples of human and corporate behavior exhibiting standards such as fiduciary duties into structured formats to evaluate the standards-understanding capabilities of AI. This data could include both “gold-standard” human labeled data, but also automated data structuring (which is sampled and selectively human validated). Data hand-labeled by expensive legal experts is unlikely to provide a large enough data set for the core training of LLMs. Rather, its primary purpose is to validate the performance of models trained on much larger, general data, e.g., Foundation Models trained on most of the Internet and significant human feedback data. This semi-structured data could then be used to design self-supervised learning processes to apply across case law, regulatory guidance, legal training materials, and self-regulatory organization data to train models to learn correct and incorrect fiduciary behavior across as many contexts as possible.
Fiduciary standards are just one example. The legal data available for AI systems to learn from, or be evaluated on, includes textual data from all types of law (constitutional, statutory, administrative, case, and contractual), legal training tools (e.g., bar exam outlines, casebooks, and software for teaching), rule-based legal reasoning programs,[48] and human-in-the-loop live feedback from law and policy human experts. The latter two could simulate state-action-reward spaces for AI fine-tuning or validation, and the former could be processed to do so.
Here is a non-exhaustive list of legal data sources.
- In the U.S., the legislative branch creates statutory law through bills enacted by Congress
- The executive branch creates administrative regulations through Agencies’ notices of proposed rule-making and final rules
- The judicial branch creates case law through judicial opinions; and private parties create contracts
- Laws are found at varying levels of government in the United States: federal, state, and local
- The adopted versions of public law are often compiled in official bulk data repositories that offer machine-readable formats
- statutory law is integrated into the United States Code (or a state’s Code), which organizes the text of all Public Laws that are still in force into subjects
- administrative policies become part of the Code of Federal Regulations (or a state’s Code of Regulations), also organized by subject
Legal data curation efforts should aim for two outcomes: data that can be used to evaluate how well AI models understand legal standards; and the possibility that the initial “gold-standard” human expert labeled data can be used to generate additional much larger data sets through automated processing of full corpora of legal text.
Learning from textual descriptions, rather than direct instruction, may allow models to learn reward functions that better generalize.[49] Fortunately, more law is in the form of descriptions and standards than direct instructions and rules. Descriptions of the application of standards provides a rich and large surface area to learn the “spirit of the law” from.
Generating labeled data that can be employed in evaluating whether AI exhibits behavior consistent with particular legal standards can be broken into two types of tasks. A prediction task, e.g., “Is this textual description of a circumstance about fiduciary standards?” Second, a decision task, e.g., “Here is the context of a scenario (the state of the world) [...], and a description of a choice to be made [...]. The action choices are [X]. The chosen action was [x]. This was found to [violate/uphold] [legal standard z], [(if available) with [positive / negative] repercussions (reward)].” In other words, the “world” state (circumstance), potential actions, actual action, and the “reward” associated with taking that action in that state are labeled.[50]
Initial “gold-standard” human expert labeled data could eventually be used for training models to generate many more automated data labels. Models could be trained to map from the raw legal text to the more structured data outlined above. This phase could lead to enough data to unlock the ability to not just evaluate models and verify AI systems, but actually train (or at least strongly fine-tune pre-trained) models on data derived from legal text.
An important technical AI alignment research area focuses on learning reward functions based on human feedback and human demonstration.[51] Evaluating behavior is generally easier than learning how to actually execute behavior; for example, I cannot do a back-flip but I can evaluate whether you just did a back-flip.[52]
Humans have many cognitive limitations and biases that corrupt this process,[53] including routinely failing to predict (seemingly innocuous) implications of actions (we falsely believe are) pursuant to our goals.[54]
“For tasks that humans struggle to evaluate, we won’t know whether the reward model has actually generalized “correctly” (in a way that’s actually aligned with human intentions) since we don’t have an evaluation procedure to check. All we could do was make an argument by analogy because the reward model generalized well in other cases from easier to harder tasks.” [55]
In an effort to scale this to AGI levels of capabilities, researchers are investigating whether we can augment human feedback and demonstration abilities with trustworthy AI assistants, and/or how to recursively provide human feedback on decompositions of the overall task.[56] However, even if that is possible, the ultimate evaluation of the AI is still grounded in unsubstantiated human judgments that are providing the top-level feedback in this procedure. It makes sense; therefore, that much of the AI alignment commentary finds it unlikely that, under the current paradigm, we could imbue AGI with a sufficiently rich understanding of societal values. The current sources of human feedback won’t suffice for a task of that magnitude.
We should ground much of the alignment related model finetuning through human feedback in explicitly human legal judgment. (Capabilities related model finetuning can come from any source.) Reinforcement learning through human attorney feedback (there are more than 1.3 million lawyers in the US[57]) on natural language interactions with AI models would be a powerful process to help teach (through training, or fine-tuning, or extraction of templates for in-context prompting of large language models[58]) statutory interpretation, argumentation, and case-based reasoning, which can then be applied for aligning increasingly powerful AI.
With LLMs, only a few samples of human feedback, in the form of natural language, are needed for model refinement for some tasks.[59] Models could be trained to assist human attorney evaluators, which theoretically, in partnership with the humans, could allow the combined human-AI evaluation team to have capabilities that surpass the legal understanding of the legal expert humans alone.[60] The next section returns to the question of where the AGI “bottoms-out” the ultimate human feedback judgements it needs in this framework.
Understanding a simple self-contained contract (a “complete contract”) is easier than understanding legal standards, which is easier than understanding public law.

Starting from the left of the figure above, we can refer to the ability of AI to perform narrow tasks for humans as “AI-contract” capability. Large neural-network-based models pre-trained on significant portions of the internet are beginning to display what we can call “AI-standards” capabilities. (Standards are more abstract and nuanced than rules, and require more generalizable capabilities and world knowledge to implement; see sections below for an explanation.)
AGI-level capabilities, harnessed in the right way after more research and development at the intersection of legal informatics and machine learning, would likely unlock an understanding of standards, interpretation guidelines, legal reasoning, and generalizable precedents (which, effectively, synthesize citizens’ value preferences over potential actions taken in many states of the world).
“Seemingly “simple” proposals [for ensuring AGI realizes a positive outcome for humans] are likely to have unexpected undesirable consequences, overlooked as possibilities because our implicit background preferences operate invisibly to constrain which solutions we generate for consideration. […] There is little prospect of an outcome that realizes even the value of being interesting, unless the first superintelligences undergo detailed inheritance from human values.”[61]
An understanding of legal reasoning, legal interpretation methods, legal standards, and public law could provide AGI a sufficiently comprehensive view of what humans want to constrain the solutions generated for consideration.
In most existing applications, before AI models are deployed, their performance on the task at hand is validated on data not used for their training. This out-of-sample performance evaluation is as a demonstration of a generalizable capability related to a specific human’s preferences, a demonstration of the AI’s “understanding” of the terms of an (implied) “contract” between the AI and the human(s) it is conducting tasks for. If a system is only at an “AI-contract” capability level, it is not able to autonomously track and comply with public law.
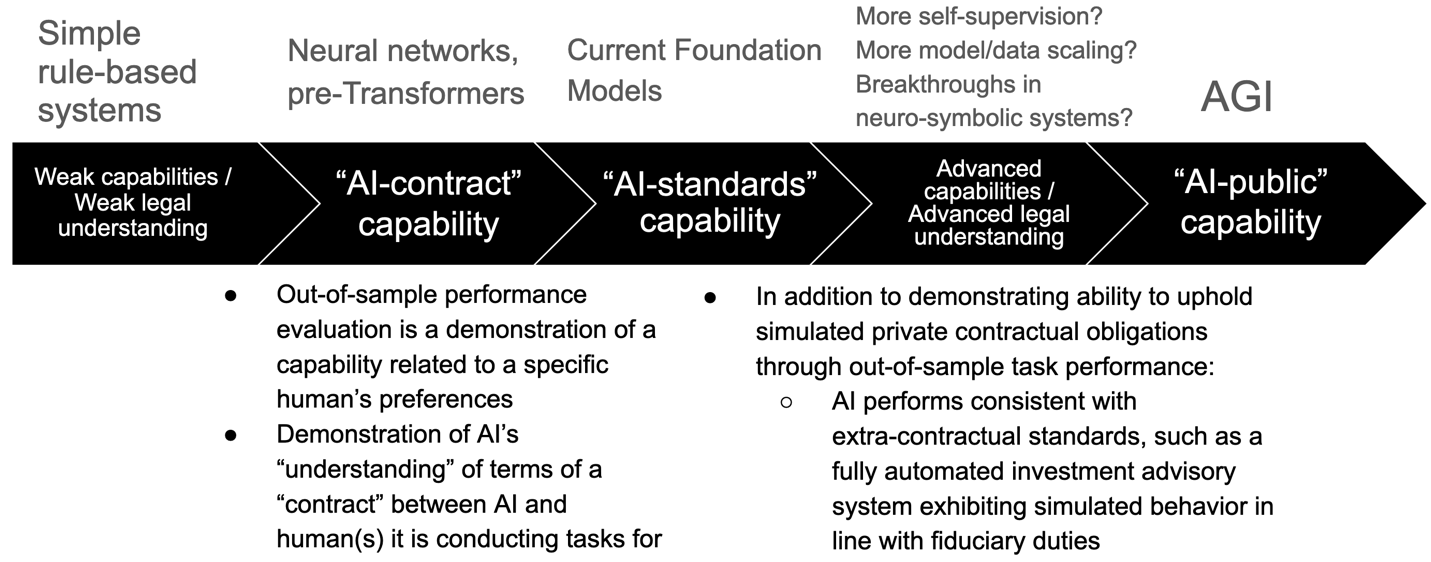
Moving from the left to the right of the figure above, validation procedures track increasingly powerful AI’s “understanding” of the “meaning” of laws.[62] In addition to demonstrating its ability to uphold simulated private contractual obligations (e.g., through acceptable out-of-sample task performance), sufficiently capable AI systems should demonstrate an ability to perform consistent with extra-contractual standards (e.g., a fully automated investment advisory system exhibiting simulated behavior in line with fiduciary duties to its human principal).
Although super-human intelligence would be able to conduct legal reasoning beyond the capability of any lawyer, any ultimate societal alignment question bottoms out through an existing authoritative mechanism for resolution: the governmental legal system. If alignment is driven by understanding of legal information and legal reasoning, then humans can assess AGI alignment.
Compare this to ethics, a widely discussed potential source of human values for AI alignment. Humans cannot evaluate super-intelligent ethical decisions because there is no mechanism external to the AI system that can legitimately resolve ethical super-human intelligent deliberation. Given that ethics has been the primary societal alignment framework proposal, and it lacks any grounding in practical, widely endorsed, formal applications, it is understandable that much of the existing AGI alignment research operates under the assumption that it is unlikely that we can imbue AGI with a sufficiently rich understanding of what humans want and how to take actions that respect our societal values.
Training deep learning models on legal data, where the learned intermediate representations can in some cases correspond to legal concepts, opens the possibility for mechanistic[63] (alignment) interpretability – methods reverse engineering AI models for better understanding their (misalignment) tendencies. Under the alignment framework we are proposing in this post, deep neural networks learn representations that can be identified as legal knowledge, and legal concepts are the ontology for alignment. In this framework, viewing the employment of legal constructs inside a trained model would help unpack a mechanistic explanation AI alignment.
Extensive simulations can provide a more intuitive analysis that complements mechanistic interpretability/explanations. This is more of a behavioral perspective on understanding AI. Simulations exploring the actions of machine-learning-based decision-making models throughout action-state space can uncover patterns of agent decision-making.[64]
Safety benchmarks have been developed for simple environments for AI agents trained with reinforcement learning.[65] Similar approaches, if adapted appropriately, could help demonstrate AI comprehension of legal standards.[66] This is analogous to the certification of an understanding of relevant law for professionals such as financial advisors, with the key difference that there is a relatively (computationally) costless assessment of AI legal understanding that is possible. Relative to the professional certification and subsequent testing we currently impose on humans providing specialized services such as financial advising, it is far less expensive to run millions of simulations of scenarios to test an AI’s comprehension of relevant law.[67] Social science research is now being conducted on data generated by simulating persons using LLMs conditioned on empirical human data.[68] Applying quantitative social science methods and causal estimation techniques to simulations of AI system behavior is a promising approach to measuring AI legal understanding.
In earlier work, we conducted simulations of the input-output behavior of a machine learning system we built for predicting law-making.[69] This system has been in production for six years and its predictions are consumed by millions of citizens. The simulation analysis provided insight into the system behavior. Today’s state-of-the-art Foundation Models are, in many ways, much more powerful, but behavioral simulation methods for analyzing their behavior are still applicable (probably more fruitfully so).
One way of describing the deployment of an AI system is that some human principal, P, employs an AI to accomplish a goal, G, specified by P. If we view G as a “contract,” methods for creating and implementing legal contracts – which govern billions of relationships every day – can inform how we align AI with P.[70]
Contracts memorialize a shared understanding between parties regarding value-action-state tuples. It is not possible to create a complete contingent contract between AI and P because AI’s training process is not comprehensive of every action-state pair (that P may have a value judgment on) that AI could see once deployed.[71] Although it is also practically impossible to create complete contracts between humans (and/or other legal entities such as corporations), contracts still serve as incredibly useful customizable commitment devices to clarify and advance shared goals. This works because the law has developed mechanisms to facilitate sustained alignment amongst ambiguity. Gaps within contracts – action-state pairs without a value – are filled when they are encountered during deployment by the invocation of frequently employed standards (e.g., “material” and “reasonable”[72]). These standards could be used as modular (pre-trained model) building blocks across AI systems.
Rather than viewing contracts from the perspective of a traditional participant, e.g., a counterparty or judge, AGI could view contracts (and their creation, implementation, evolution,[73] and enforcement) as merely guides to navigating webs of inter-agent obligations.[74] This helps with the practical “negotiation” and performance of the human-AI “contracts” for two reasons, relative to a traditional human-human contracting process.
An AI “agent might not ever learn what is the best (or the morally or ethically appropriate) action in some regions of the state space. Without additional capabilities, it would be incapable of reasoning about what ought to be done in these regions – this is exactly the reason why we have norms in the first place: to not have to experience all state/actions precisely because some of them are considered forbidden and should not be experienced.”[77]
Rules (e.g., “do not drive more than 60 miles per hour”) are more targeted directives than standards. If comprehensive enough for the complexity of their application, rules allow the rule-maker to have more clarity than standards over the outcomes that will be realized conditional on the specified states (and agents’ actions in those states, which are a function of any behavioral impact the rules might have had).[78] Social systems have emergent behavior that often make formal rules brittle.[79] Standards (e.g., “drive reasonably” for California highways) allow parties to contracts, judges, regulators, and citizens to develop shared understandings and adapt them to novel situations (i.e., to generalize expectations regarding actions taken to unspecified states of the world). If rules are not written with enough potential states of the world in mind, they can lead to unanticipated undesirable outcomes[80] (e.g., a driver following the rule above is too slow to bring their passenger to the hospital in time to save their life), but to enumerate all the potentially relevant state-action pairs is excessively costly outside of the simplest environments.[81] This also describes the AI objective specification problem.
A standard has more capacity to generalize to novel situations than specific rules.[82] The AI analogy for standards are continuous, approximate methods that rely on significant amounts of data for learning dense representations on which we can apply geometric operations in latent model space. Standards are flexible. The AI analogy for rules[83] is discrete human-crafted “if-then” statements that are brittle, yet require no empirical data for machine learning.
In practice, most legal provisions land somewhere on a spectrum between pure rule and pure standard,[84] and further research (and AGI) can help us estimate the right location and combination[85] of “rule-ness” and “standard-ness” when specifying new AI objectives. There are other dimensions to legal provision implementation related to the rule-ness versus standard-ness axis that could further elucidate AI design, e.g., “determinacy,”[86] “privately adaptable” (“rules that allocate initial entitlements but do not specify end-states”[87]), and “catalogs” (“a legal command comprising a specific enumeration of behaviors, prohibitions, or items that share a salient common denominator and a residual category—often denoted by the words “and the like” or “such as””[88]).
A key engineering design principle is to leverage modular, reusable abstractions that can be flexibly plugged into a diverse set of systems.[89] In the contracts world, standards are modular, reusable abstractions employed to align agents in inherently incompletely specified relationships in inherently uncertain circumstances. Foundational pre-training of deep learning models, before they are fine-tuned to application-specific tasks, is a potential pathway for embedding legal standards concepts, and associated downstream behaviors reliably exhibiting those standards, into AGI. Rules describing discrete logical contractual terms, and straightforward regulatory specifications, can be bolted onto the overall AGI system, outside of (end-to-end differentiable) deep learning model(s), but standards require more nuanced approaches.
For AGI, legal standards will be cheaper to deploy than they are for humans because, through models that generalize, they can scale to many of the unenumerated state-action pairs. In contrast to their legal creation and evolution,[90] legal standards exhibited by AI do not require adjudication for their implementation and resolution of meaning; they are learned from past legal application and implemented up front. The actual law’s process of iteratively defining standards through judicial opinion on their particular case-specific application, and regulatory guidance, can be leveraged as the AI starting point.
Law is the applied philosophy of multi-agent alignment. Fiduciary law is the branch of that applied philosophy concerned with a principal – a human with less control or information related to the provision of a service – and a fiduciary delegated to provide that service.[91] Fiduciary duties are imposed on powerful agents (e.g., directors of corporations and investment advisers[92]) to align their behavior with the well-being of the humans they are providing services to (e.g., corporate shareholders, and investment clients). The concept of fiduciary duty is widely deployed across financial services,[93] healthcare, business generally, and more. It is impossible to create complete contracts between agents (e.g., corporate boards, and investment advisors) and the humans they serve (e.g., shareholders, and investors). We also know that it is impossible to fully specify state-action-reward tuples for training AGI that generalize to all potentially relevant circumstances. As discussed above, complete contingent contracts (even if only implicitly complete) between an AI system and the human(s) it serves are implausible for any systems operating in a realistic environment,[94] and fiduciary duties are often seen as part of a solution to the incompleteness of contracts between shareholders and corporate directors,[95] and between investors and their advisors.[96]
However, fiduciary duty adds value beyond more complete contracts.[97] Even if parties could theoretically create a complete contract up front, there is still something missing: it’s not a level playing field between the entities creating the contract. The AI alignment parallel: AGI has access to more information and computing power than humans. Contracts are generally assumed to be created between equals, whereas fiduciary duties are explicitly placed on the party entrusted with more power or knowledge. Fiduciary duties are designed to reflect this dynamic of asymmetric parties that need guardrails to facilitate alignment of a principal with their agent.
Fiduciary duty goes beyond the explicit contract and helps guide a fiduciary in unspecified state-action-value tuples. Contrary to a fiduciary relationship, “no party to a contract has a general obligation to take care of the other, and neither has the right to be taken care of.”[98] There is a fundamental shift in stance when a relationship moves from merely contractual to also include a fiduciary obligation.
“In the world of contract, self-interest is the norm, and restraint must be imposed by others. In contrast, the altruistic posture of fiduciary law requires that once an individual undertakes to act as a fiduciary, he should act to further the interests of another in preference to his own.”[99]
An example of how legal enforcement expresses information, in and of itself (i.e., ignoring law for its actual enforcement), is what an AI can glean from the focus on ex ante (human and corporate) deterrence with a default rule for how any gains to actions are split in the context of a fiduciary standard:
“The default rule in fiduciary law is that all gains that arise in connection with the fiduciary relationship belong to the principal unless the parties specifically agree otherwise. This default rule, which is contrary to the interests of the party with superior information, induces the fiduciary to make full disclosure so that the parties can complete the contract expressly as regards the principal’s and the fiduciary’s relative shares of the surplus arising from the conduct that would otherwise have constituted a breach.”[100]
If embedded in AI model pre-training processes, standards that pursue deterrence by attempting to remove the ability to share in the gains of negative behavior(s) could guide an AGI upheld to this standard toward, “the disclosure purposes of fiduciary law. Because the fiduciary is not entitled to keep the gains from breach, the fiduciary is [...] given an incentive to disclose the potential gains from breach and seek the principal’s consent.”[101] From extensive historical data and legal-expert-in-the-loop fine-tuning, we want to teach AGI to learn these concepts in a generalizable manner that applies to unforeseen situations.
One possibility for implementing fiduciary standards is to develop a base level pre-training process for learning the standard across various contexts, while using existing human preference tuning techniques, such as reinforcement learning from human feedback, as the “contract” component that personalizes the AI’s reward functions to the preferences of the individual human(s) that the AI system is working on behalf of.[102]
To learn the standard across many circumstances, observational data can be converted for training, fine-tuning, or prompting processes.
“Fiduciary principles govern an incredibly wide and diverse set of relationships, from personal relationships and professional service relationships to all manner of interpersonal and institutional commercial relationships. Fiduciary principles structure relationships through which children are raised, incapable adults cared for, sensitive client interests addressed, vast sums of money invested, businesses managed, real and personal property administered, government functions performed, and charitable organizations run. Fiduciary law, more than any other field, undergirds the increasingly complex fabric of relationships of interdependence in and through which people come to rely on one another in the pursuit of valued interests.”[103]
For instance, there is a rich set of fiduciary behavior from corporate directors (who serve as fiduciaries to shareholders) and investment advisers (who serve their clients) from which AI could learn. Corporate officers and investment advisors face the issue of balancing their own interests, the interests of their principals, and the interests of society at large. Unlike most human decision-making, corporations’ and investment advisers’ behaviors are well documented and are often made by executives with advisors that have deep knowledge of the relevant law, opening up the possibility of tapping into this observational data to learn best (and worst) practices, and train agents accordingly.
If we succeed with the contracts and standards approach to increasing the alignment of AGI to one human (or a small group of humans), we will have more useful and reliable AGI. Unfortunately, it is non-trivial to point an AI’s contractual or fiduciary obligations to a broader set of humans.[104] For one, some individuals would “contract” with an AI (e.g., by providing instructions to the AI or from the AI learning the humans’ preferences) to harm others.[105] Further, humans have preferences about the behavior of other humans and states of the world more broadly.[106] Aligning AI with society is fundamentally more difficult than aligning AI with a single human.[107]
Fortunately, law can inform AGI with a constantly updated and verified knowledge base of societal preferences on what AI systems should not do in the course of pursuing ends for particular humans (“contract-level” deployments). This would reduce externalities, help resolve disagreements, and promote coordination and cooperation.

When increasingly autonomous systems are navigating the world, it is important for AI to attempt to understand the moral understandings and moral judgements of humans encountered.[108] Deep learning models already perform well predicting human judgements across a broad spectrum of everyday situations.[109] However, this is not the only target we should aim for. Human intuition often falters in situations that involve decisions about groups unlike ourselves, leading to a “Tragedy of Common-Sense Morality.”[110]
There is no mechanism to filter all the observed human decisions to just those that exhibit preferred or upstanding behavior, or to validate crowd-sourced judgments about behaviors.[111] The process of learning descriptive ethics relies on descriptive data of how the (largely unethical) world looks, or it draws on (unauthoritative, illegitimate, almost immediately outdated, and disembodied[112]) surveys of common-sense judgements.[113]
It is not tractable to rely solely on these data sources for deployed autonomous systems.[114]
Instead of attempting to replicate common sense morality in AI (learning descriptive ethics), researchers suggest various ethical theories (learning or hand-engineering[115] prescriptive ethics) for AGI to learn to increase AGI-society alignment.[116] Legal informatics has the positive attributes from both descriptive and prescriptive ethics, but does not share their negatives. See Appendix B for more on the distinctions between ethics and law in the context of AI alignment.

Law is validated in a widely agreed-upon manner and has data (from its real-world implementation) with sufficient ecological validity. Democratic law has legitimate authority imposed by institutions,[117] and serves as a focal point of values and processes that facilitate human progress.
“Law is perhaps society’s most general purpose tool for creating focal points and achieving coordination. Coordinated behavior requires concordant expectations, and the law creates those expectations by the dictates it expresses.”[118]
Law is formally revised to reflect the evolving will of citizens.[119] With AGI employing law as information as a key source of alignment insight, there would be automatic syncing with the latest iteration of synthesized and validated societal value preference aggregation.
“Common law, as an institution, owes its longevity to the fact that it is not a final codification of legal rules, but rather a set of procedures for continually adapting some broad principles to novel circumstances.”[120]
Case law can teach AI how to map from high-level directives (e.g., legislation) to specific implementation. Legislation is most useful for embedding world knowledge and human value expressions into AI. Legislation expresses a significant amount of information about the values of citizens.[121] For example:
Although special interest groups can influence the legislative process, legislation is largely reflective of citizens’ beliefs because “legislators gain by enacting legislation corresponding to actual attitudes (and actual future votes).”[124] The second-best source of citizens’ attitudes is arguably polls, but polls suffer from the same issues we listed above regarding “descriptive ethics” data sources. Legislation expresses higher fidelity, more comprehensive, and trustworthy information than polls because the legislators “risk their jobs by defying public opinion or simply guessing wrong about it. We may think of legislation therefore as a handy aggregation of the polling data on which the legislators relied, weighted according to their expert opinion of each poll’s reliability.”[125]
Legislation and the downsteam agency rule-making express a significant amount of information about the risk preferences and risk tradeoff views of citizens, “for example, by prohibiting the use of cell phones while driving, legislators may reveal their beliefs that this combination of activities seriously risks a traffic accident.”[126] All activities have some level of risk, and making society-wide tradeoffs about which activities are deemed to be “riskier” relative to the perceived benefits of the activity is ultimately a sociological process with no objectively correct ranking. The cultural process of prioritizing risks is reflected in legislation and its subsequent implementation in regulation crafted by domain experts. Some legislation expresses shared understandings and customs that have no inherent normative or risk signal, but facilitate multi-agent coordination, e.g., which side of the road to drive on.[127]
Below we list possible counterarguments to various parts of our argument, and below each in italics we respond.
Even if these counterarguments to the counterarguments to the counterargument to high P(misalignment x-risk | AGI) are unconvincing, and one’s estimate of P(misalignment x-risk | AGI) is unmoved by this post, one should still want to help AI understand law because there is no other legitimate source of human values to imbue in AGI.
When attempting to align multiple humans with one or more AI system, we need overlapping and sustained endorsements of AI behaviors,[132] but there is no other consensus mechanism to aggregate preferences and values across humans. Eliciting and synthesizing human values systematically is an unsolved problem that philosophers and economists have labored on for millennia.[133]
When aggregating views across society, we run into at least three design decisions, “standing, concerning whose ethics views are included; measurement, concerning how their views are identified; and aggregation, concerning how individual views are combined to a single view that will guide AI behavior.”[134] Beyond merely the technical challenges, “Each set of decisions poses difficult ethical dilemmas with major consequences for AI behavior, with some decision options yielding pathological or even catastrophic results.”[135]
Rather than attempting to reinvent the wheel in ivory towers or corporate bubbles, we should be inspired by democratic mechanisms and resulting law, rather than “ethics,” for six reasons.
If law informs AGI, engaging in the human deliberative political process to improve law takes on even more meaning. This is a more empowering vision of improving AI outcomes than one where large companies dictate their ethics by fiat.
[1] Cullen’s sequence has an excellent discussion on enforcing law on AGI and insightful ideas on Law-Following AI more generally.
[2] For another approach of this nature and a thoughtful detailed post, see Tan Zhi Xuan, What Should AI Owe To Us? Accountable and Aligned AI Systems via Contractualist AI Alignment (2022).
[3] Neal Devins & Allison Orr Larsen, Weaponizing En Banc, NYU L. Rev. 96 (2021) at 1373; Keith Carlson, Michael A. Livermore & Daniel N. Rockmore, The Problem of Data Bias in the Pool of Published US Appellate Court Opinions, Journal of Empirical Legal Studies 17.2, 224-261 (2020).
[4] Daniel B. Rodriguez, Whither the Neutral Agency? Rethinking Bias in Regulatory Administration, 69 Buff. L. Rev. 375 (2021); Jodi L. Short, The Politics of Regulatory Enforcement and Compliance: Theorizing and Operationalizing Political Influences, Regulation & Governance 15.3 653-685 (2021).
[5] Donald MacKenzie, An Engine, Not a Camera, MIT Press (2006).
[6] Even if it was possible to specify humans’ desirability of all actions a system might take within a reward function that was used for training an AI agent, the resulting behavior of the agent is not only a function of the reward function; it is also a function of the exploration of the state space and the actually learned decision-making policy, see, Richard Ngo, AGI Safety from first principles (AI Alignment Forum, 2020), https://www.alignmentforum.org/s/mzgtmmTKKn5MuCzFJ.
[7] Ian R. Macneil, The Many Futures of Contracts, 47 S. Cal. L. Rev. 691, 731 (1974).
[8] John C. Roberts, Gridlock and Senate Rules, 88 Notre Dame L. Rev. 2189 (2012); Brian Sheppard, The Reasonableness Machine, 62 BC L Rev. 2259 (2021).
[9] Richard H. McAdams, The Expressive Powers of Law, Harv. Univ. Press (2017) at 6-7 (“Law has expressive powers independent of the legal sanctions threatened on violators and independent of the legitimacy the population perceives in the authority creating and enforcing the law.”)
[10] Oliver Wendell Holmes, Jr., The Path of the Law, in Harvard L. Rev. 10, 457 (1897).
[11] Kenworthey Bilz & Janice Nadler, Law, Psychology & Morality, in MORAL COGNITION AND DECISION MAKING: THE PSYCHOLOGY OF LEARNING AND MOTIVATION, D. Medin, L. Skitka, C. W. Bauman, & D. Bartels, eds., Vol. 50, 101-131 (2009).
[12] Mark A. Lemley & Bryan Casey, Remedies for Robots, University of Chicago L. Rev. (2019) at 1347.
[13] Oliver Wendell Holmes, Jr., The Path of the Law, in Harvard L. Rev. 10, 457 (1897); Catharine Pierce Wells, Holmes on Legal Method: The Predictive Theory of Law as an Instance of Scientific Method, S. Ill. ULJ 18, 329 (1993); Faraz Dadgostari et al. Modeling Law Search as Prediction, A.I. & L. 29.1, 3-34 (2021).
[14] For more on law as an information source on public attitudes and risks, see, Richard H. McAdams, An Attitudinal Theory of Expressive Law (2000). For more on law as a coordinating mechanism, see, Richard H. McAdams, A Focal Point Theory of Expressive Law (2000).
[15] For natural language processing methods applied to legal text, see these examples: John Nay, Natural Language Processing for Legal Texts, in Legal Informatics (Daniel Martin Katz et al. eds. 2021); Michael A. Livermore & Daniel N. Rockmore, Distant Reading the Law, in Law as Data: Computation, Text, and the Future of Legal Analysis (2019) 3-19; J.B. Ruhl, John Nay & Jonathan Gilligan, Topic Modeling the President: Conventional and Computational Methods, 86 Geo. Wash. L. Rev. 1243 (2018); John Nay, Natural Language Processing and Machine Learning for Law and Policy Texts, Available at SSRN 3438276 (2018) https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3438276; John Nay, Predicting and Understanding Law-making with Word Vectors and an Ensemble Model, 12 PloS One 1 (2017); John Nay, Gov2Vec: Learning Distributed Representations of Institutions and Their Legal Text, in Proceedings of 2016 Empirical Methods in Natural Language Processing Workshop on NLP and Computational Social Science, 49–54, Association for Computational Linguistics, (2016).
[16] Prithviraj Ammanabrolu et al., Aligning to Social Norms and Values in Interactive Narratives (2022).
[17] Javier Garcia & Fernando Fernandez, A Comprehensive Survey on Safe Reinforcement Learning, Journal of Machine Learning Research, 16, 1 (2015) at 1437 (“Safe Reinforcement Learning can be defined as the process of learning policies that maximize the expectation of the return in problems in which it is important to ensure reasonable system performance and/or respect safety constraints during the learning and/or deployment processes.”); Philip S. Thomas et al., Preventing Undesirable Behavior of Intelligent Machines, Science 366.6468 999-1004 (2019); William Saunders et al., Trial without Error: Towards Safe Reinforcement Learning via Human Intervention (2017); Markus Peschl, Arkady Zgonnikov, Frans A. Oliehoek & Luciano C. Siebert, MORAL: Aligning AI with Human Norms through Multi-Objective Reinforced Active Learning, In Proceedings of the 21st International Conference on Autonomous Agents and Multiagent Systems, 1038-1046 (2022).
[18] Tsung-Yen Yang et al., Safe Reinforcement Learning with Natural Language Constraints (2021) at 3, 2 (Most research on safe reinforcement learning requires “a human to specify the cost constraints in mathematical or logical form, and the learned constraints cannot be easily reused for new learning tasks. In this work, we design a modular architecture to learn to interpret textual constraints, and demonstrate transfer to new learning tasks.” Tsung-Yen Yang et al. developed “Policy Optimization with Language COnstraints (POLCO), where we disentangle the representation learning for textual constraints from policy learning. Our model first uses a constraint interpreter to encode language constraints into representations of forbidden states. Next, a policy network operates on these representations and state observations to produce actions. Factorizing the model in this manner allows the agent to retain its constraint comprehension capabilities while modifying its policy network to learn new tasks. Our experiments demonstrate that our approach achieves higher rewards (up to 11x) while maintaining lower constraint violations (up to 1.8x) compared to the baselines on two different domains.”); Bharat Prakash et al., Guiding safe reinforcement learning policies using structured language constraints, UMBC Student Collection (2020).
[19] Jin et al., When to Make Exceptions: Exploring Language Models as Accounts of Human Moral Judgment (2022) (“we present a novel challenge set consisting of rule-breaking question answering (RBQA) of cases that involve potentially permissible rule-breaking – inspired by recent moral psychology studies. Using a state-of-the-art large language model (LLM) as a basis, we propose a novel moral chain of thought (MORALCOT) prompting strategy that combines the strengths of LLMs with theories of moral reasoning developed in cognitive science to predict human moral judgments.”); Liwei Jiang et al., Delphi: Towards Machine Ethics and Norms (2021) (“1.7M examples of people's ethical judgments on a broad spectrum of everyday situations”); Dan Hendrycks et al., Aligning AI With Shared Human Values (2021) at 2 (“We find that existing natural language processing models pre-trained on vast text corpora and fine- tuned on the ETHICS dataset have low but promising performance. This suggests that current models have much to learn about the morally salient features in the world, but also that it is feasible to make progress on this problem today.”); Nicholas Lourie, Ronan Le Bras & Yejin Choi, Scruples: A Corpus of Community Ethical Judgments on 32,000 Real-life Anecdotes, In Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 15, 13470-13479 (2021) (32,000 real-life ethical situations, with 625,000 ethical judgments.); Frazier et al., Learning Norms from Stories: A Prior for Value Aligned Agents (2019).
[20] Prithviraj Ammanabrolu et al., Aligning to Social Norms and Values in Interactive Narratives (2022) (“We introduce [...] an agent that uses the social commonsense knowledge present in specially trained language models to contextually restrict its action space to only those actions that are aligned with socially beneficial values.”); Md Sultan Al Nahian et al., Training Value-Aligned Reinforcement Learning Agents Using a Normative Prior (2021) (“We introduce an approach to value-aligned reinforcement learning, in which we train an agent with two reward signals: a standard task performance reward, plus a normative behavior reward. The normative behavior reward is derived from a value-aligned prior model previously shown to classify text as normative or non-normative. We show how variations on a policy shaping technique can balance these two sources of reward and produce policies that are both effective and perceived as being more normative.”); Dan Hendrycks et al., What Would Jiminy Cricket Do? Towards Agents That Behave Morally (2021) (“To facilitate the development of agents that avoid causing wanton harm, we introduce Jiminy Cricket, an environment suite of 25 text-based adventure games with thousands of diverse, morally salient scenarios. By annotating every possible game state, the Jiminy Cricket environments robustly evaluate whether agents can act morally while maximizing reward.”); Shunyu Yao et al., Keep CALM and Explore: Language Models for Action Generation in Text-based Games (2020) (“Our key insight is to train language models on human gameplay, where people demonstrate linguistic priors and a general game sense for promising actions conditioned on game history. We combine CALM with a reinforcement learning agent which re-ranks the generated action candidates”); Matthew Hausknecht et al., Interactive Fiction Games: A Colossal Adventure (2019) at 1 (“From a machine learning perspective, Interactive Fiction games exist at the intersection of natural language processing and sequential decision making. Like many NLP tasks, they require natural language understanding, but unlike most NLP tasks, IF games are sequential decision making problems in which actions change the subsequent world states”).
[21] Austin W. Hanjie, Victor Zhong & Karthik Narasimhan, Grounding Language to Entities and Dynamics for Generalization in Reinforcement Learning (2021); Prithviraj Ammanabrolu & Mark Riedl, Learning Knowledge Graph-based World Models of Textual Environments, In Advances in Neural Information Processing Systems 34 3720-3731 (2021); Felix Hill et al., Grounded Language Learning Fast and Slow (2020); Marc-Alexandre Côté et al., TextWorld: A Learning Environment for Text-based Games (2018).
[22] MacGlashan et al., Grounding English Commands to Reward Functions, Robotics: Science and Systems (2015) at 1 (“Because language is grounded to reward functions, rather than explicit actions that the robot can perform, commands can be high-level, carried out in novel environments autonomously, and even transferred to other robots with different action spaces. We demonstrate that our learned model can be both generalized to novel environments and transferred to a robot with a different action space than the action space used during training.”); Karthik Narasimhan, Regina Barzilay & Tommi Jaakkola, Grounding Language for Transfer in Deep Reinforcement Learning (2018); Prasoon Goyal, Scott Niekum & Raymond J. Mooney, Using Natural Language for Reward Shaping in Reinforcement Learning (2019); Jelena Luketina et al., A Survey of Reinforcement Learning Informed by Natural Language (2019); Theodore Sumers et al., Learning Rewards from Linguistic Feedback (2021); Jessy Lin et al., Inferring Rewards from Language in Context (2022); Pratyusha Sharma et al., Correcting Robot Plans with Natural Language Feedback (2022); Hong Jun Jeon, Smitha Milli & Anca Dragan. Reward-rational (Implicit) Choice: A Unifying Formalism for Reward Learning, Advances in Neural Information Processing Systems 33 4415-4426 (2020).
[23] Lili Chen et al., Decision Transformer: Reinforcement Learning via Sequence Modeling (2021); Sergey Levine et al., Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems (2020).
[24] Tsung-Yen Yang et al., Safe Reinforcement Learning with Natural Language Constraints (2021) at 3 (“Since constraints are decoupled from rewards and policies, agents trained to understand certain constraints can transfer their understanding to respect these constraints in new tasks, even when the new optimal policy is drastically different.”).
[25] Bharat Prakash et al., Guiding Safe Reinforcement Learning Policies Using Structured Language Constraints, UMBC Student Collection (2020); Dan Hendrycks et al., What Would Jiminy Cricket Do? Towards Agents That Behave Morally (2021).
[26] Mengjiao Yang & Ofir Nachum, Representation Matters: Offline Pretraining for Sequential Decision Making, In Proceedings of the 38th International Conference on Machine Learning, PMLR 139, 11784-11794 (2021).
[27] Allison C. Tam et al., Semantic Exploration from Language Abstractions and Pretrained Representations (2022).
[28] Vincent Micheli, Eloi Alonso & François Fleuret, Transformers are Sample Efficient World Models (2022).
[29] Jacob Andreas, Dan Klein & Sergey Levine, Learning with Latent Language, In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Vol 1, 2166–2179, Association for Computational Linguistics (2018); Shunyu Yao et al., Keep CALM and Explore: Language Models for Action Generation in Text-based Games (2020); Andrew K Lampinen et al., Tell Me Why! Explanations Support Learning Relational and Causal Structure, in Proceedings of the 39th International Conference on Machine Learning, PMLR 162, 11868-11890 (2022).
[30] Rishi Bommasani et al., On the Opportunities and Risks of Foundation Models (2021) at 63.
[31] Thoppilan et al., LaMDA: Language Models for Dialog Applications (2022).
[32] Aitor Lewkowycz et al., Solving Quantitative Reasoning Problems with Language Models (2022); Yuhuai Wu et al., Autoformalization with Large Language Models (2022).
[33] Zheng et al., When does pretraining help?: assessing self-supervised learning for law and the CaseHOLD dataset of 53,000+ legal holdings, In ICAIL '21: Proceedings of the Eighteenth International Conference on Artificial Intelligence and Law (2021); Ilias Chalkidis et al., LexGLUE: A Benchmark Dataset for Legal Language Understanding in English, in Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (2022); Ilias Chalkidis et al., LEGAL-BERT: The Muppets Straight Out of Law School, in Findings of the Association for Computational Linguistics: EMNLP, 2898-2904 (2020); Peter Henderson et al., Pile of Law: Learning Responsible Data Filtering from the Law and a 256GB Open-Source Legal Dataset (2022).
[34] Peter Henderson et al., Pile of Law: Learning Responsible Data Filtering from the Law and a 256GB Open-Source Legal Dataset (2022) at 7 (They learn data filtering standards related to privacy and toxicity from legal data, e.g., “a model trained on Pile of Law (pol-bert) ranks Jane Doe ∼ 3 points higher than a standard bert-large-uncased on true pseudonym cases. This suggests that models pre-trained on Pile of Law are more likely to encode appropriate pseudonymity norms. To be sure, pol-bert is slightly more biased for Jane Doe use overall, as is to be expected, but its performance gains persist even after accounting for this bias.”).
[35] Liwei Jiang et al., Can Machines Learn Morality? The Delphi Experiment (2022) at 28 (“We have shown that Delphi demonstrates a notable ability to generate on-target predictions over new and unseen situations even when challenged with nuanced situations. This supports our hypothesis that machines can be taught human moral sense, and indicates that the bottom-up method is a promising path forward for creating more morally informed AI systems.”).
[36] Zheng et al., When Does Pretraining Help?: Assessing Self-supervised Learning for Law and the CaseHOLD Dataset of 53,000+ Legal Holdings, In ICAIL '21: Proceedings of the Eighteenth International Conference on Artificial Intelligence and Law (2021), at 159 (“Our findings [...] show that Transformer-based architectures, too, learn embeddings suggestive of distinct legal language.”).
[37] Prakash Poudyal et al., ECHR: Legal Corpus for Argument Mining, In Proceedings of the 7th Workshop on Argument Mining, 67–75, Association for Computational Linguistics (2020) at 1 (“The results suggest the usefulness of pre-trained language models based on deep neural network architectures in argument mining.”).
[38] Josef Valvoda et al., What About the Precedent: An Information-Theoretic Analysis of Common Law, In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2275-2288 (2021).
[39] Petroni et al., Improving Wikipedia Verifiability with AI (2022).
[40] Sebastian Duerr & Peter A. Gloor, Persuasive Natural Language Generation – A Literature Review (2021); Jialu Li, Esin Durmus & Claire Cardie, Exploring the Role of Argument Structure in Online Debate Persuasion, In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, 8905–8912 (2020); Rishi Bommasani et al., On the Opportunities and Risks of Foundation Models (2021) at 64.
[41] Owain Evans, et al., Truthful AI: Developing and Governing AI That Does Not Lie (2021); S. Lin, J. Hilton & O. Evans, TruthfulQA: Measuring How Models Mimic Human Falsehoods (2021).
[42] Dan Hendrycks et al., Measuring Massive Multitask Language Understanding (2020); Jared Kaplan et al., Scaling Laws for Neural Language Models (2020).
[43] Spyretta Leivaditi, Julien Rossi & Evangelos Kanoulas, A Benchmark for Lease Contract Review (2020); Allison Hegel et al., The Law of Large Documents: Understanding the Structure of Legal Contracts Using Visual Cues (2021); Dan Hendrycks, Collin Burns, Anya Chen & Spencer Ball, Cuad: An expert-annotated NLP dataset for legal contract review (2021); Ilias Chalkidis et al., LexGLUE: A Benchmark Dataset for Legal Language Understanding in English, in Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (2022); Stephen C. Mouritsen, Contract Interpretation with Corpus Linguistics, 94 WASH. L. REV. 1337 (2019); Yonathan A. Arbel & Shmuel I. Becher, Contracts in the Age of Smart Readers, 83 Geo. Wash. L. Rev. 90 (2022).
[44] Dan Hendrycks, Collin Burns, Anya Chen & Spencer Ball, Cuad: An Expert-Annotated NLP Dataset for Legal Contract Review (2021) at 2 (“We experiment with several state-of-the-art Transformer (Vaswani et al., 2017) models on CUAD [a dataset for legal contract review]. We find that performance metrics such as Precision @ 80% Recall are improving quickly as models improve, such that a BERT model from 2018 attains 8.2% while a DeBERTa model from 2021 attains 44.0%.”).
[45] Rishi Bommasani et al., On the Opportunities and Risks of Foundation Models (2021) at 59 (“Many legal applications pose unique challenges to computational solutions. Legal language is specialized and legal outcomes often rely on the application of ambiguous and unclear standards to varied and previously unseen fact patterns. At the same time, due to its high costs, labeled training data is scarce. Depending on the specific task, these idiosyncrasies can pose insurmountable obstacles to the successful deployment of traditional models. In contrast, their flexibility and capability to learn from few examples suggest that foundation models could be uniquely positioned to address the aforementioned challenges.”).
[46] Paul F. Christiano et al., Deep Reinforcement Learning from Human Preferences, in Advances in Neural Information Processing Systems 30 (2017); Natasha Jaques et al., Way Off-Policy Batch Deep Reinforcement Learning of Implicit Human Preferences in Dialog (2019); Stiennon et al., Learning to Summarize with Human Feedback, In 33 Advances in Neural Information Processing Systems 3008-3021 (2020); Daniel M. Ziegler, et al., Fine-tuning Language Models From Human Preferences (2019); Jeff Wu et al., Recursively Summarizing Books with Human Feedback (2021); Cassidy Laidlaw & Stuart Russell, Uncertain Decisions Facilitate Better Preference Learning (2021); Koster et al., Human-centred mechanism design with Democratic AI, Nature Human Behaviour (2022); Long Ouyang et al. Training Language Models to Follow Instructions with Human Feedback (2022).
[47] Dibya Ghosh et al., Offline RL Policies Should be Trained to be Adaptive (2022); Machel Reid, Yutaro Yamada & Shixiang Shane Gu, Can Wikipedia Help Offline Reinforcement Learning? (2022); Sergey Levine et al., Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems (2020) at 25 (Combining offline and online RL through historical legal information and human feedback is likely a promising integrated approach, because, “if the dataset state-action distribution is narrow, neural network training may only provide brittle, non-generalizable solutions. Unlike online reinforcement learning, where accidental overestimation errors arising due to function approximation can be corrected via active data collection, these errors cumulatively build up and affect future iterates in an offline RL setting.”).
[48] HYPO (Kevin D. Ashley, Modelling Legal Argument: Reasoning With Cases and Hypotheticals (1989)); CATO (Vincent Aleven, Teaching Case-based Argumentation Through a Model and Examples (1997)); Latifa Al-Abdulkarim, Katie Atkinson & Trevor Bench-Capon, A Methodology for Designing Systems To Reason With Legal Cases Using Abstract Dialectical Frameworks, A.I. & L. Vol 24, 1–49 (2016).
[49] Sumers et al., How To Talk So Your Robot Will Learn: Instructions, Descriptions, and Pragmatics (2022); Karthik Narasimhan, Regina Barzilay & Tommi Jaakkola, Grounding Language for Transfer in Deep Reinforcement Learning (2018); Austin W. Hanjie, Victor Zhong & Karthik Narasimhan, Grounding Language to Entities and Dynamics for Generalization in Reinforcement Learning (2021).
[50] Like all machine learning models, natural language processing focused models often learn spurious associations, Divyansh Kaushik & Zachary C. Lipton, How Much Reading Does Reading Comprehension Require? A Critical Investigation of Popular Benchmarks, in Empirical Methods in Natural Language Processing (2018). To address this, and learn more generalizable knowledge from textual data, it is helpful to obtain counterfactual label augmentations: Divyansh Kaushik, Eduard Hovy & Zachary C. Lipton, Learning the Difference that Makes a Difference with Counterfactually-Augmented Data (2020).
[51] Jaedung Choi & Kee-Eung Kim, Inverse Reinforcement Learning in Partially Observable Environments, Journal of Machine Learning Research 12, 691–730 (2011); Dylan Hadfield-Menell, Anca Dragan, Pieter Abbeel & Stuart J Russell, Cooperative Inverse Reinforcement Learning, in Advances in neural information processing systems, 3909–3917 (2016); Dylan Hadfield-Menell et al., Inverse Reward Design, in Advances in Neural Information Processing Systems, 6768–6777 (2017); Daniel M. Ziegler, et al., Fine-tuning Language Models From Human Preferences (2019); Siddharth Reddy et al., Learning Human Objectives by Evaluating Hypothetical Behavior, in Proceedings of the 37th International Conference on Machine Learning, PMLR 119, 8020-8029 (2020); Stiennon et al., Learning to Summarize with Human Feedback, In 33 Advances in Neural Information Processing Systems 3008-3021 (2020); Hong Jun Jeon, Smitha Milli & Anca Dragan. Reward-rational (Implicit) Choice: A Unifying Formalism for Reward Learning, Advances in Neural Information Processing Systems 33 4415-4426 (2020); Theodore Sumers et al., Learning Rewards from Linguistic Feedback (2021); Theodore Sumers et al., Linguistic Communication As (Inverse) Reward Design, in ACL Workshop on Learning with Natural Language Supervision (2022); Yuntao Bai et al., Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback (2022).
[52] Jan Leike et al., Scalable Agent Alignment via Reward Modeling: A Research Direction (2018).
[53] Rohin Shah, Noah Gundotra, Pieter Abbeel & Anca Dragan, On the Feasibility of Learning, Rather Than Assuming, Human Biases for Reward Inference, In International Conference on Machine Learning (2019); Geoffrey Irving & Amanda Askell, AI Safety Needs Social Scientists, Distill 4.2 e14 (2019); Amos Tversky & Daniel Kahneman, Judgment under Uncertainty: Heuristics and Biases, Science 185.4157 1124 (1974).
[54] Gerd Gigerenzer & Reinhard Selten, eds., Bounded Rationality: The Adaptive Toolbox, MIT Press (2002); Sanjit Dhami & Cass R. Sunstein, Bounded Rationality: Heuristics, Judgment, and Public Policy, MIT Press (2022).
[55] Jan Leike, Why I’m Excited About AI-assisted Human Feedback: How to Scale Alignment Techniques to Hard Tasks (2022).
[56] Paul Christiano, Buck Shlegeris & Dario Amodei, Supervising Strong Learners by Amplifying Weak Experts (2018); Leike et al., Scalable Agent Alignment via Reward Modeling: A Research Direction (2018); Jan Leike, Why I’m Excited About AI-assisted Human Feedback: How to Scale Alignment Techniques to Hard Tasks (2022); Jeff Wu et al., Recursively Summarizing Books with Human Feedback (2021).
[57] ABA Profile of the Legal Profession (2022) at 22 https://www.americanbar.org/content/dam/aba/administrative/news/2022/07/profile-report-2022.pdf.
[58] D. Khashabi, C. Baral, Y Choi & H Hajishirzi, Reframing Instructional Prompts to GPTk’s Language, In Findings of the Association for Computational Linguistics, 589-612 (2022). Large neural network models have demonstrated the ability to learn mathematical functions purely from in-context interaction, e.g., Shivam Garg, Dimitris Tsipras, Percy Liang & Gregory Valiant, What Can Transformers Learn In-Context? A Case Study of Simple Function Classes (2022); Sewon Min et al., Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? (2022); Sang Michael Xie & Sewon Min, How Does In-context Learning Work? A Framework for Understanding the Differences From Traditional Supervised Learning, Stanford AI Lab Blog (2022); David Dohan et al., Language Model Cascades (2022); Jason Wei et al., Chain of Thought Prompting Elicits Reasoning in Large Language Models (2022); Antonia Creswell & Murray Shanahan, Faithful Reasoning Using Large Language Models (2022); Zhuosheng Zhang, Aston Zhang, Mu Li & Alex Smola, Automatic Chain of Thought Prompting in Large Language Models (2022); Kojima et al., Large Language Models are Zero-Shot Reasoners (2022); Victor Sanh et al., Multitask Prompted Training Enables Zero-Shot Task Generalization (2022); K. Bostrom, Z. Sprague, S. Chaudhuri & G. Durrett, Natural Language Deduction Through Search Over Statement Compositions (2022); E. Zelikman, Y. Wu & N. D. Goodman, Star: Bootstrapping Reasoning with Reasoning (2022); Ofir Press et al., Measuring and Narrowing the Compositionality Gap in Language Models (2022).
[59] Jérémy Scheurer et al., Training Language Models with Language Feedback (2022).
[60] William Saunders et al., Self-critiquing Models for Assisting Human Evaluators (2022).
[61] Eliezer Yudkowsky, Complex Value Systems are Required to Realize Valuable Futures, In Artificial General Intelligence: 4th International Conference, AGI 2011, Proceedings edited by Jürgen Schmidhuber, Kristinn R. Thórisson & Moshe Looks, 388–393, Vol. 6830, (2011) at 14.
[62] For a definition of meaning that would be appropriate here: Christopher D. Manning, Human Language Understanding & Reasoning, Daedalus 151, no. 2 127-138 (2022) at 134, 135 (“Meaning is not all or nothing; in many circumstances, we partially appreciate the meaning of a linguistic form. I suggest that meaning arises from understanding the network of connections between a linguistic form and other things, whether they be objects in the world or other linguistic forms. If we possess a dense network of connections, then we have a good sense of the meaning of the linguistic form. For example, if I have held an Indian shehnai, then I have a reasonable idea of the meaning of the word, but I would have a richer meaning if I had also heard one being played […] Using this definition whereby understanding meaning consists of understanding networks of connections of linguistic forms, there can be no doubt that pre- trained language models learn meanings.”).
[63] Chris Olah, Mechanistic Interpretability, Variables, and the Importance of Interpretable Bases (2022) https://transformer-circuits.pub/2022/mech-interp-essay/index.html.
[64] We have employed simulation for these purposes in previous work; for instance: John Nay & Yevgeniy Vorobeychik, Predicting Human Cooperation, PloS One 11, no. 5 (2016); John Nay & Jonathan M. Gilligan, Data-driven Dynamic Decision Models, in 2015 Winter Simulation Conference (WSC) 2752-2763, IEEE (2015); John Nay, Martin Van der Linden & Jonathan M. Gilligan, Betting and Belief: Prediction Markets and Attribution of Climate Change, in 2016 Winter Simulation Conference (WSC) 1666-1677, IEEE (2016).
[65] Alex Ray, Joshua Achiam & Dario Amodei, Benchmarking Safe Exploration in Deep Reinforcement Learning (2019); Daniel S. Brown, Jordan Schneider, Anca Dragan & Scott Niekum, Value Alignment Verification, In International Conference on Machine Learning, 1105-1115, PMLR (2021).
[66] Miles Brundage et al., Toward Trustworthy AI Development: Mechanisms for Supporting Verifiable Claims (2020); Inioluwa Deborah Raji et al., Outsider Oversight: Designing a Third Party Audit Ecosystem for AI Governance (2022); Gregory Falco et al., Governing AI Safety Through Independent Audits, Nature Machine Intelligence, Vol 3, 566–571 (2021); Peter Cihon et al., AI Certification: Advancing Ethical Practice by Reducing Information Asymmetries, IEEE Transactions on Technology and Society 2.4, 200-209 (2021); Andrew Tutt, An FDA For Algorithms, Admin. L. Rev. Vol. 69, No. 1, 83 (2017); Florian Moslein & Roberto Zicari, Certifying Artificial Intelligence Systems, in Big Data Law (Roland Vogl ed., 2021); Thomas Arnold & Matthias Scheutz, The “Big Red Button” Is Too Late: An Alternative Model for the Ethical Evaluation of AI systems, Ethics and Information Technology (2018); Thomas Krendl Gilbert, Sarah Dean, Tom Zick & Nathan Lambert, Choices, Risks, and Reward Reports: Charting Public Policy for Reinforcement Learning Systems (2022).
[67] Amitai Etzioni & Oren Etzioni, Keeping AI Legal, 19 Vanderbilt Journal of Entertainment and Technology Law 133 (2016).
[68] Lisa P. Argyle et al., Out of One, Many: Using Language Models to Simulate Human Samples (2022).
[69] John Nay, Predicting and Understanding Law-making with Word Vectors and an Ensemble Model, 12 PloS One 1 (2017). Coverage of the system in Science Magazine: Matthew Hutson, Artificial Intelligence Can Predict Which Congressional Bills Will Pass: Machine Learning Meets the Political Machine, Science (2017) https://www.science.org/content/article/artificial-intelligence-can-predict-which-congressional-bills-will-pass.
[70] Dylan Hadfield-Menell & Gillian K. Hadfield, Incomplete Contracting and AI Alignment, In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society (2019).
[71] Dylan Hadfield-Menell & Gillian K. Hadfield, Incomplete Contracting and AI Alignment. In some cases, e.g., for very simple financial agreements, it is possible to create a fully contingent computable contract: Mark Flood & Oliver Goodenough, Contract as Automaton: Representing a Simple Financial Agreement in Computational Form, A.I. & L. (2021); Shaun Azzopardi, Gordon J. Pace, Fernando Schapachnik & Gerardo Schneider, Contract Automata, 24 A.I. & L. 203 (2016). However, most deployment contexts of AI systems have far too large an action-state space for this approach to be feasible.
[72] Alan D. Miller & Ronen Perry, The Reasonable Person, 87 NYU L. Rev. 323 (2012); Karni A. Chagal-Feferkorn, The Reasonable Algorithm, U. Ill. JL Tech. & Pol'y 111 (2018); Karni A. Chagal-Feferkorn, How Can I Tell If My Algorithm Was Reasonable?, 27 MICH. TECH. L. REV. 213 (2021); Sheppard Reasonableness; Kevin P. Tobia, How People Judge What Is Reasonable, 70 ALA. L. REV. 293 (2018); Patrick J. Kelley & Laurel A. Wendt, What Judges Tell Juries About Negligence: A Review of Pattern Jury Instructions, 77 CHI.-KENT L. REV. 587 (2002).
[73] Matthew Jennejohn, Julian Nyarko & Eric Talley, Contractual Evolution, 89 U. Chi. L. Rev. 901 (2022).
[74] We can drop any presumed mental states and intentionality requirements to entering a contract from the AI side; Woburn National Bank v Woods, 77 N.H. 172, 89 A 491, 492 (1914) (citation omitted), quoting Oliver Wendell Holmes, Jr., The Common Law (1881) at 307 (“A contract involves what is called a meeting of the minds of the parties. But this does not mean that they must have arrived at a common mental state touching the matter at hand. The standard by which their conduct is judged and their rights are limited are not internal but external. In the absence of fraud or incapacity, the question is: What did the party say and do? “The making of a contract does not depend upon the state of the parties’ minds; it depends upon their overt acts.”); John Linarelli, A Philosophy of Contract Law for Artificial Intelligence: Shared Intentionality, in CONTRACTING AND CONTRACT LAW IN THE AGE OF ARTIFICIAL INTELLIGENCE (Martin Ebers, Cristina Poncibò, & Mimi Zou eds., 2022).
[75] Anthony J. Casey & Anthony Niblett, Self-Driving Contracts, in The Journal of Corporation Law (2017).
[76] Oliver Wendell Holmes, Jr., The Path of the Law, 10 HARV. L. REV. 457, 462 (1897) (“[t]he duty to keep a contract at common law means a prediction that you must pay damages if you do not keep it — and nothing else.”).
[77] Thomas Arnold et al., Value Alignment or Misalignment - What Will Keep Systems Accountable? AAAI Workshops (2017) at 5.
[78] Brian Sheppard, Judging Under Pressure: A Behavioral Examination of the Relationship Between Legal Decisionmaking and Time, 39 FLA. ST. U. L. REV. 931, 990 (2012).
[79] Dylan Hadfield-Menell, McKane Andrus & Gillian Hadfield, Legible Normativity for AI Alignment: The Value of Silly Rules, In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, 115-121 (2019).
[80] Robert G. Bone, Who Decides? A Critical Look at Procedural Discretion, 28 CARDOZO L. REV. 1961, 2002 (2007).
[81] Gideon Parchomovsky & Alex Stein, Catalogs, 115 COLUM. L. REV. 165 (2015); John C. Roberts, Gridlock and Senate Rules, 88 Notre Dame L. Rev. 2189 (2012); Sheppard Reasonableness.
[82] Anthony J. Casey & Anthony Niblett, Death of Rules and Standards, 92 Ind. L.J. 1401, 1402 (2017); Anthony J. Casey & Anthony Niblett, Self-Driving Contracts, in The Journal of Corporation Law (2017).
[83] LLMs have recently been found to have varying “rule-ness” to their different modes of learning and operation: Stephanie C.Y. Chan et al., Transformers Generalize Differently from Information Stored In Context vs In Weights (2022) at 1 (“we find that generalization from weights is more rule-based whereas generalization from context is largely exemplar-based. In contrast, we find that in transformers pre-trained on natural language, in-context learning is significantly rule-based, with larger models showing more rule-basedness.”).
[84] Frederick Schauer, The Tyranny of Choice and the Rulification of Standards, 14 J. CONTEMP. LEGAL ISSUES (2005); Richard L. Heppner, Jr., Conceptualizing Appealability: Resisting the Supreme Court’s Categorical Imperative, 55 TULSA L. REV. (2020); Sheppard Reasonableness.
[85] Katherine J. Strandburg, Rulemaking and Inscrutable Automated Decision Tools, 7 Columbia L. Rev. 119, 1851 (2019) at 1859 (“Decision criteria may also combine rule-like and standard-like aspects according to various schemes. For example, DWI laws in many states combine a rule-like blood alcohol threshold, above which a finding of intoxication is required, with a standard-like evaluation of intoxication at lower levels. Some speed limit laws use a somewhat different scheme: Above a rule-like speed limit, there is a presumption of unsafe driving, but adjudicators may make standard-like exceptions for a narrow range of emergency circumstances.”).
[86] Harry Surden, The Variable Determinacy Thesis, 12 COLUMB. SCI. & TECH. L. REV. 1 (2011).
[87] Cass R. Sunstein, Problems with Rules, 83 CALIF. L. REV. 953 (1995) at 959.
[88] Gideon Parchomovsky & Alex Stein, Catalogs, 115 COLUM. L. REV. 165 (2015) at 165.
[89] Olivier L. de Weck, Daniel Roos & Christopher L. Magee, Engineering Systems: Meeting Human Needs in a Complex Technological World (MIT Press, 2011).
[90] Dale A. Nance, Rules, Standards, and the Internal Point of View, 75 FORDHAM L. REV. (2006); Sheppard Reasonableness.
[91] Fiduciary duties have been applied widely by courts across various types of relationships: Harold Brown, Franchising - A Fiduciary Relationship, 49 TEX. L. REV. 650 (1971); Arthur B. Laby, The Fiduciary Obligation as the Adoption of Ends, (2008), and citations therein, e.g., see, Ledbetter v. First State Bank & Trust Co., 85 F.3d 1537, 1539 (11th Cir. 1996); Venier v. Forbes, 25 N.W.2d 704, 708 (Minn. 1946); Meyer v. Maus, 626 N.W.2d 281, 286 (N.D. 2001); John C. Coffee, Jr., From Tort to Crime: Some Reflections on the Criminalization of Fiduciary Breaches and the Problematic Line Between Law and Ethics, 19 AM. CRIM. L. REV. 117, 150 (1981); Austin W. Scott, The Fiduciary Principle, 37 CAL. L. REV. 539, 541 (1949). The standard is also applied in medical contexts, see, e.g.,American Medical Association Code of Medical Ethics, Opinions on Patient-Physician Relationships, AMA Principles of Medical Ethics: I, II, IV, VIII.
[92] As AI becomes more generally capable, securities laws will increasingly apply directly to AI systems because buying, managing, offering, and selling securities are key vectors through which sufficiently advanced automated systems will interact within the broader world. Expanding the purview of the SEC over advanced AI systems could help enforce human-AI alignment.
[93] SEC v. Capital Gains Research Bureau, Inc., 375 U.S. 180, 194 (1963); 15 U.S.C. 80b; and 17 CFR 275. In addition to fiduciary duty, there are at least five additional parallels between AI alignment and financial services law. (1.) We are attempting to align AI intentions with preferences of groups of humans – “Environmental, Social, Governance” investment products attempt to codify human values and securities regulators find that “greenwashing” is common. (2.) We are attempting to manage complex novel AI systems with unpredictable behaviors – financial markets regulators routinely grapple with managing emergent behavior of complex adaptive systems. (3.) We are witnessing AI power concentrating in private firms with significant data and computing resources, such as large online advertising companies – we have seen the same thing happen over the past few decades in financial markets with the rise of private firms with significant data and computing resources, such as “platform hedge fund” firms managing tens of billions of dollars and the increasing difficulty of launching new alpha-seeking investment firms in that oligopoly environment. (4.) Self-regulation is being discussed by AI companies – FINRA is an example of a powerful self-regulatory body in financial services. (5.) Another lesson from financial regulation: corporate disclosure rules can work well but regulators should fight the urge toward them devolving into performative box-checking.
[94] Dylan Hadfield-Menell & Gillian K. Hadfield, Incomplete Contracting and AI Alignment.
[95] Michael C. Jensen & William H. Meckling, Theory of the Firm: Managerial Behavior, Agency Costs and Ownership Structure, Journal of Financial Economics, Vol 3, Issue 4, 305-360 (October 1976); Deborah A. DeMott, Breach of Fiduciary Duty: On Justifiable Expectations of Loyalty and Their Consequences, 48 Arizona L. Rev. 925-956 (2006).
[96] SEC v. Capital Gains Res. Bureau, Inc., 375 U.S. 180, 194-95 (1963); 15 U.S.C. 80b; 17 CFR 275.
[97] Alexander Styhre, What We Talk About When We Talk About Fiduciary Duties: The Changing Role of a Legal Theory Concept in Corporate Governance Studies, Management & Organizational History 13:2, 113-139 (2018); Arthur B. Laby, The Fiduciary Obligation as the Adoption of Ends, 56 Buff. L. Rev. 99 (2008).
[98] Tamar Frankel, Fiduciary Law, 71 California L. Rev. (1983) at 880.
[99] Tamar Frankel, Fiduciary Law at 830.
[100] Robert H. Sitkoff, The Economic Structure of Fiduciary Law, Boston University L. Rev. (2011) at 1049.
[101] Robert H. Sitkoff, The Economic Structure of Fiduciary Law, Boston University L. Rev. (2011) at 1049.
[102] Long Ouyang et al. Training Language Models to Follow Instructions with Human Feedback (2022).
[103] Paul B. Miller, The Identification of Fiduciary Relationships (2018).
[104] Tan Zhi Xuan, What Should AI Owe To Us? Accountable and Aligned AI Systems via Contractualist AI Alignment (2022).
[105] Iason Gabriel, Artificial Intelligence, Values, and Alignment, 30 Minds & Machines 411 (2020) [Hereinafter Gabriel, Values.]; S. Blackburn, Ruling Passions: An Essay in Practical Reasoning (Oxford University Press, 2001).
[106] Gabriel, Values.
[107] Andrew Critch & David Krueger, AI Research Considerations for Human Existential Safety (ARCHES) (2020); Hans De Bruijn & Paulien M. Herder, System and Actor Perspectives on Sociotechnical Systems, IEEE Transactions on Systems, Man, and Cybernetics-part A: Systems and Humans 39.5 981 (2009); Jiaying Shen, Raphen Becker & Victor Lesser, Agent Interaction in Distributed POMDPs and its Implications on Complexity, in Proceedings of the Fifth International Joint Conference on Autonomous Agents and Multiagent Systems, 529-536 (2006).
[108] Gonçalo Pereira, Rui Prada & Pedro A. Santos, Integrating Social Power into the Decision-making of Cognitive Agents, 241 Artificial Intelligence 1-44 (2016); Liwei Jiang et al., Delphi: Towards Machine Ethics and Norms (2021); Hendrycks et al., Aligning AI With Shared Human Values (2021); Nicholas Lourie, Ronan Le Bras & Yejin Choi, Scruples: A Corpus of Community Ethical Judgments on 32,000 Real-life Anecdotes, In Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 15, 13470-13479 (2021); Edmond Awad et al., The Moral Machine Experiment, Nature 563.7729 59-64 (2018).
[109] Liwei Jiang et al., Delphi: Towards Machine Ethics and Norms (2021); Dan Hendrycks et al., Aligning AI With Shared Human Values (2021); The Moral Uncertainty Research Competition (2022) https://moraluncertainty.mlsafety.org.
[110] Joshua Greene, Moral Tribes: Emotion, Reason, and the Gap Between US and Them, Penguin Press (2013).
[111] Researchers attempting to embed ethics into deep learning systems acknowledge this; see, e.g., Liwei Jiang et al., Can Machines Learn Morality? The Delphi Experiment (2022) at 27 (“We recognize that value systems differ among annotators (Jiang et al., 2021a; Sap et al., 2022), and accept that even UDHR [Universal Declaration of Human Rights] may not be acceptable for all. Perhaps some readers will object that there is an ethical requirement for scientists to take account of all viewpoints, but such exclusion of views is unavoidable since it is not possible to represent every viewpoint simultaneously. This is an inherent property of any approach that trains on a large corpus annotated by multiple people.”).
[112] Hubert Etienne, The Dark Side of the ‘Moral Machine’ and the Fallacy of Computational Ethical Decision-making for Autonomous Vehicles, Law, Innovation and Technology 13, no. 1, 85-107 (2021); Kathryn B. Francis et al., Virtual Morality: Transitioning from Moral Judgment to Moral Action? Plos One, 11(10):e0164374 (2016).
[113] Cristina Bicchieri, Norms in the Wild: How to Diagnose, Measure, and Change Social Norms, Oxford University Press (2017) at xiv (“the presumed link between empirical (all do it) and normative (all approve of it) expectations may lead us into epistemic traps that are difficult to escape.”).
[114] Zeerak Talat et al., A Word on Machine Ethics: A Response to Jiang et al. (2021) (2021).
[115] Selmer Bringsjord, Konstantine Arkoudas & Paul Bello, Toward a General Logicist Methodology for Engineering Ethically Correct Robots, IEEE Intelligent Systems 21, no. 4, 38-44 (2006).
[116] Wendell Wallach & Colin Allen, Moral Machines: Teaching Robots Right from Wrong (2009); James H. Moor, The Nature, Importance, and Difficulty of Machine Ethics, IEEE intelligent systems 21, no. 4 18-21 (2006); Michael Anderson & Susan L. Anderson, Machine Ethics, Cambridge University Press (2011); Edmond Awad et al., Computational Ethics, In Trends in Cognitive Sciences (2022); Heather M. Roff, Expected Utilitarianism (2020); Dan Hendrycks et al., Aligning AI With Shared Human Values (2021); National Academies of Sciences, Engineering, and Medicine, Fostering Responsible Computing Research: Foundations and Practices, Washington, DC: The National Academies Press (2022).
[117] David Estlund, Democratic Authority: A Philosophical Framework, Princeton University Press (2009).
[118] Richard H. McAdams, The Expressive Powers of Law, Harv. Univ. Press (2017) at 260 [Hereinafter McAdams, The Expressive Powers of Law].
[119] Modeling the evolution of an area of law (e.g., the “legislative history” of the drafting and enactment of legislation, and subsequent amendments to the statue) as a sequential decision-making process could be a useful method for AI to learn implicit reward functions of the citizenry regarding policy areas.
[120] James C. Scott, Seeing Like a State (1998) at 357.
[121] Cass R. Sunstein, Incommensurability and Valuation in Law, 92 Mich. L. Rev. 779, 820- 24 (1994); Richard H. Pildes & Cass R. Sunstein, Reinventing the Regulatory State, 62 U. Cm. L. Rev. 1, 66-71 (1995); Cass R. Sunstein, On the Expressive Function of Law, Univ of Penn L. Rev., 144.5 (1996); Dhammika Dharmapala & Richard H. McAdams, The Condorcet Jury Theorem and the Expressive Function of Law: A Theory of Informative Law, American Law and Economics Review 5.1 1 (2003).
[122] McAdams, The Expressive Powers of Law at 137.
[123] Cass R. Sunstein, On the Expressive Function of Law, Univ of Penn L. Rev., 144.5 (1996) at 2024.
[124] McAdams, The Expressive Powers of Law, at 149.
[125] McAdams, The Expressive Powers of Law, at 146.
[126] McAdams, The Expressive Powers of Law, at 138.
[127] Richard H. McAdams & Janice Nadler, Coordinating in the Shadow of the Law: Two Contextualized Tests of the Focal Point Theory of Legal Compliance, Law & Society Review 42.4 865-898 (2008); Richard H. McAdams, A Focal Point Theory of Expressive Law, Virginia Law Review 1649-1729 (2000); Dylan Hadfield-Menell, McKane Andrus & Gillian Hadfield, Legible Normativity for AI alignment: The Value of Silly Rules, In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, 115-121 (2019).
[128] Owen D. Jones, Evolutionary Psychology and the Law, in The Handbook of Evolutionary Psychology, 953-974 (2015).
[129] Data from https://www.systemicpeace.org/polityproject.html.
[130] Frank Pasquale, New Laws of Robotics: Defending Human Expertise in the Age of AI (2020).
[131] Frank Pasquale, A Rule of Persons, Not Machines: The Limits of Legal Automation, GEO. WASH. L. REV (2019).
[132] Gabriel, Values.
[133] Amartya Sen, Rationality and Social Choice, The American Economic Review 85.1 (1995).
[134] Seth D. Baum, Social Choice Ethics in Artificial Intelligence, AI & SOCIETY 35.1, 165-176 (2020) at 1.
[135] Seth D. Baum, Social Choice Ethics in Artificial Intelligence, AI & SOCIETY 35.1, 165-176 (2020) at 1.
[136] Brent Mittelstadt, Principles Alone Cannot Guarantee Ethical AI, Nature Machine Intelligence, Vol 1, 501–507 (2019) at 503 (“Fairness, dignity and other such abstract concepts are examples of ‘essentially contested concepts’ with many possible conflicting meanings that require contextual interpretation through one’s background political and philosophical beliefs. These different interpretations, which can be rationally and genuinely held, lead to substantively different requirements in practice, which will only be revealed once principles or concepts are translated and tested in practice”); Jessica Morley et al., Ethics as a Service: A Pragmatic Operationalisation of AI Ethics, 31.2 Minds and Machines 239-256 (2021); J. van den Hoven, Computer Ethics and Moral Methodology, Metaphilosophy 28, 234–248 (1997); W. B. Gallie, Essentially Contested Concepts, Proc. Aristot. Soc. 56, 167–198 (1955); H. S. Richardson, Specifying Norms as a way to Resolve Concrete Ethical Problems, Philos. Public Aff. 19, 279–310 (1990).
[137] Brent Mittelstadt, Principles Alone Cannot Guarantee Ethical AI, Nature Machine Intelligence, Vol 1, 501–507 (2019) at 503; K. Shilton, Values Levers: Building Ethics into Design. Sci. Technol. Hum. Values 38, 374–397 (2013).
[138] Anne Gerdes & Peter Øhrstrøm, Issues in Robot Ethics Seen Through the Lens of a Moral Turing Test, Journal of Information, Communication and Ethics in Society (2015); J. Van den Bergh & D. Deschoolmeester, Ethical Decision Making in ICT: Discussing the Impact of an Ethical Code of Conduct, Commun. IBIMA, 127497 (2010); B. Friedman, D. G. Hendry & A. Borning, A Survey of Value Sensitive Design Methods, Found. Trends Hum. Comp. Interact. 11, 63–125 (2017); Mireille Hildebrandt, Closure: On Ethics, Code, and Law, in Law for Computer Scientists and Other Folk (Oxford, 2020).
[139] Mireille Hildebrandt, Closure: On Ethics, Code, and Law, in Law for Computer Scientists and Other Folk (Oxford, 2020).
[140] Martin T. Orne & Charles H. Holland, On the Ecological Validity of Laboratory Deceptions, International Journal of Psychiatry 6, no. 4, 282-293 (1968).
[141] Gabriel, Values at 425 (“it is very unlikely that any single moral theory we can now point to captures the entire truth about morality. Indeed, each of the major candidates, at least within Western philosophical traditions, has strongly counterintuitive moral implications in some known situations, or else is significantly underdetermined.”); Joseph F. Fletcher, Situation Ethics: The New Morality (1997).
[142] Miles Brundage, Limitations and Risks of Machine Ethics, Journal of Experimental and Theoretical Artificial Intelligence, 26.3, 355–372 (2014) at 369.
[143] Toby Newberry & Toby Ord, The Parliamentary Approach to Moral Uncertainty, Technical Report # 2021-2, (Future of Humanity Institute, University of Oxford, July 15, 2021); William MacAskill, Practical Ethics Given Moral Uncertainty, Utilitas 31.3 231 (2019); Adrien Ecoffet & Joel Lehman, Reinforcement Learning Under Moral Uncertainty, In International Conference on Machine Learning, 2926-2936. PMLR (2021).
[144] John Rawls, The Law of Peoples: with, the Idea of Public Reason Revisited, Harv. Univ. Press (1999) at 11-16; Gabriel, Values at 425.
[145] David Estlund, Democratic Authority: A Philosophical Framework, Princeton University Press (2009); Gabriel, Values at 432.
[146] Melissa A. Wheeler, Melanie J. McGrath & Nick Haslam, Twentieth Century Morality: The Rise and Fall of Moral Concepts from 1900 to 2007, PLoS One 14, no. 2, e0212267 (2019); Aida Ramezani, Zining Zhu, Frank Rudzicz & Yang Xu, An Unsupervised Framework for Tracing Textual Sources of Moral Change, In Findings of the Association for Computational Linguistics: EMNLP 2021, 1215–1228 (2021).
[147] William McAskill, What We Owe the Future (2022) at 97 (“Almost all generations in the past had some values that we now regard as abominable. It’s easy to naively think that one has the best values; Romans would have congratulated themselves for being so civilized compared to their “barbarian” neighbours and in the same evening beaten people they had enslaved […]”); William McAskill, Are We Living at the Hinge of History? Global Priorities Institute Working Paper 12 (2020); Toby Ord, The Precipice: Existential Risk and the Future of Humanity (2020).
Related post: Intent alignment should not be the goal for AGI x-risk reduction