Comments


Authors - Kathryn O'Rourke, Callum McDougall. Thanks to Joseph Bloom and Denizhan Akar for feedback, and major thank you to all of our wonderful TAs and the MATS London team– your positive contributions to the program have been innumerable.
We ran a bootcamp aimed at teaching people ML engineering for alignment. The goal was to prepare people for the current alignment landscape, both technically and career-wise. Our three primary goals were:
We think these goals were successfully achieved overall - we noticed significant improvements in our participants ability as well as their career opportunities, and we received positive feedback on the course (with some variance between different sections). We aim to run the program again, though with some changes.
If you just want to skim this post, some of the most important sections (in our view) are:
ARENA (Alignment Research Engineer Accelerator) had its second iteration from the 22nd of May to the 30th of June (duration 6 weeks). The program covered the fundamentals of neural networks, transformers and mechanistic interpretability, reinforcement learning, training at scale, and a capstone project for students to advance their work independently.
The project was oriented around three goals:
This report is an analysis of how we attempted to achieve each goal, how we measure our success, and what we might do differently in the future.
The main theory of impact for the program was upskilling participants. For the most part, this was done through the content of the program itself. This is easily also the most straightforward goal to achieve: we aimed to provide participants a place where they could spend at least 240 hours thinking just about alignment, upskilling.
The curriculum was based on a combination of Jacob Hilton’s deep learning curriculum, Redwood Research’s Machine Learning for Alignment Bootcamp, and feedback from the first iteration of ARENA (which also drew a lot of inspiration from both of these courses). It was divided up into four main chapters of content:
Like MLAB, the course placed a lot of emphasis on exercises, so that participants knew how to use these skills rather than just reading about them. We also had participants work on capstone projects at the end of the program, which we’ll discuss more later in this document.
Hands-on engineering experience is a massive bottleneck for starting a career in AI safety. Academic programs are far behind the cutting edge (our participants reported not learning about things like transformer architecture in their undergraduate courses), and independently upskilling is often challenging, or under-resourced. We aimed to provide both a challenging, up-to-date curriculum, a space where people could learn in a group, and have access to experienced TAs. Participants also benefited from in-person pair programming.
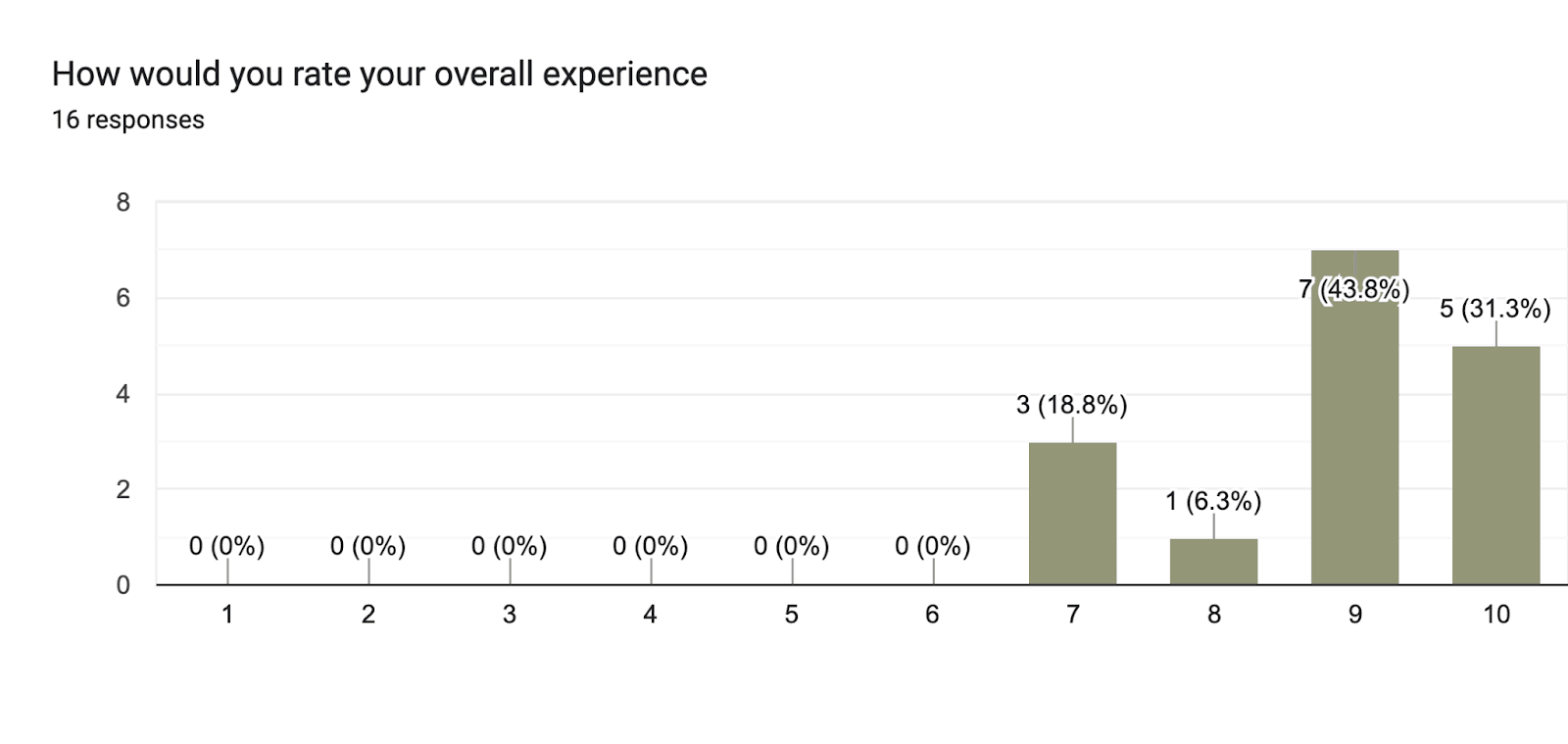
Our primary and most immediate sources of data about the program were our feedback forms. While this is subjective, it also allows us to more directly and immediately address our biggest concerns. For raw data, one can look in the appendix at some graphs that record people’s responses.
Participants’ capstone projects were a chance for them to test their abilities to delve more in depth into specific subjects of the material that was covered. Rather than structured, pre-written exercises, a successful capstone project would show that the participants understood the material in such depth that they could work on it and engage with it unsupervised. See later in this document for a summary of some particularly impressive capstone projects.
There is some difficulty measuring the counterfactual impact we had. There are other programs in which participants can learn these skills, and some resources available online. However, programs are competitive to the extent that it’s valuable to provide more opportunities, and online learning is often less rigorous or good for networking.
Overall, we feel the program did a good job upskilling participants, despite some variations across different sections of the curriculum. This sentiment is supported by our survey data. We asked participants ‘What was the main thing that you hoped you would learn from the program? How well did you learn this thing?’ Answers included:
The majority of our survey respondents said that their expectations were fulfilled, and that they learned what they had set out to learn. However, those that said they wanted to learn about Training at Scale and RLHF felt like they learned a little, but could have been given a deeper understanding. Particularly, they would have preferred more of a from-first-principles approach, rather than working with pre-existing libraries which abstracted away the details which are crucial for developing understanding.
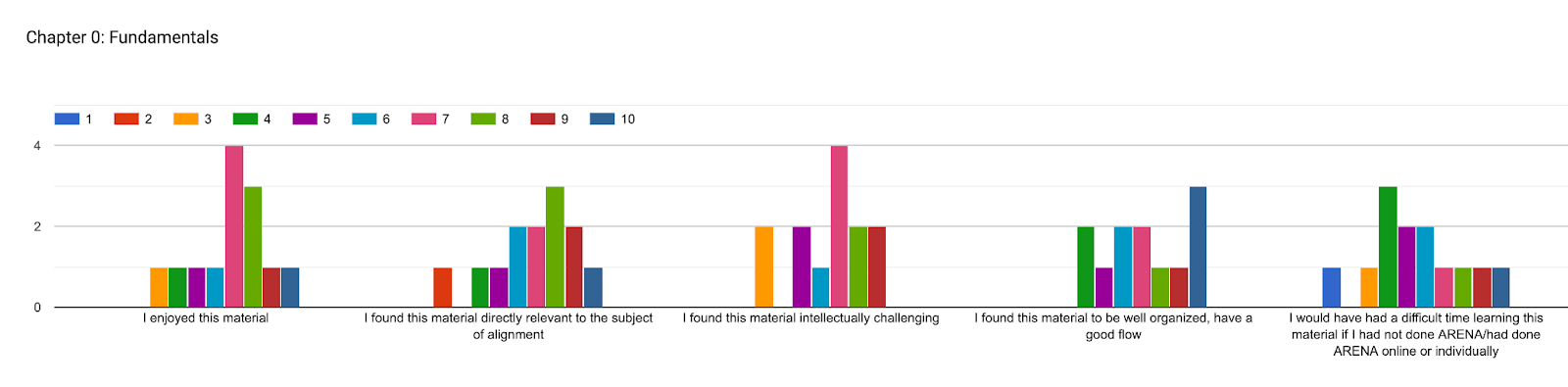
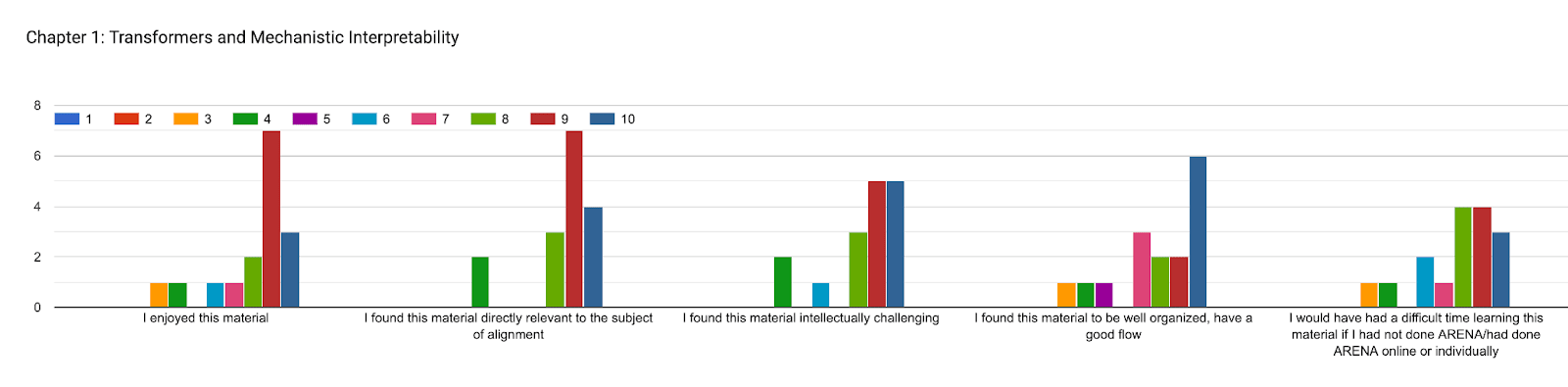
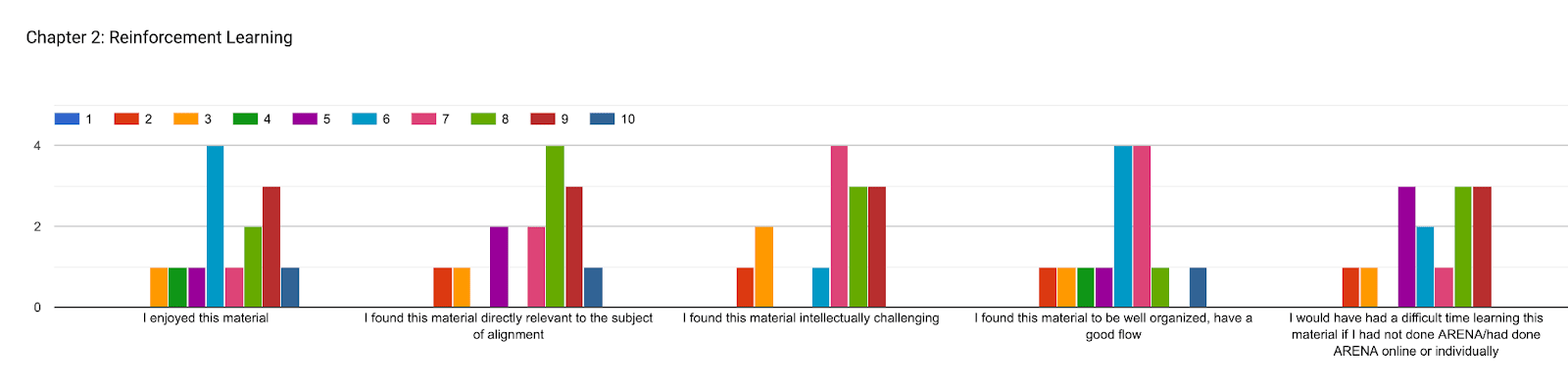
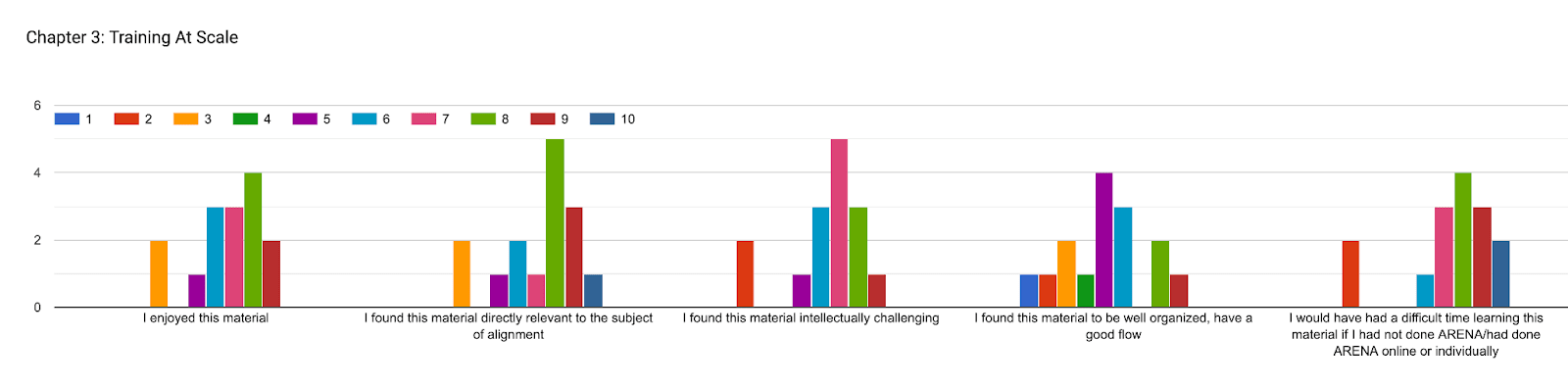
We also asked our participants to rank each section based on various criteria, 1-10, 1 being the least, 10 the most. There are various conclusions one could draw from this data, we have included graphs representing participants’ answers. However, a short summary:
The capstone projects significantly exceeded our expectations, with several participants continuing to work on their capstones long after the program finished. A sample of capstone projects which we found particularly impressive and exciting:
Specifically, we intend to focus more on implementing things from scratch, in order to properly build understanding. The training at scale material will no longer be its own chapter, but instead the most crucial parts of that chapter will be moved into other chapters.
More generally, we think that a large factor in the drop-off in ratings for the last two chapters was that the material was less extensively user-tested (unlike the first two chapters). This is something we are working to address in future iterations, by requesting more feedback from people with domain-specific knowledge.
Each section had unstructured exercises for participants to explore on their own. We would find some metric on which to test their success, so we could see how well they’ve learned through methods other than self-reporting.
Particularly, we think we should have more standardized requirements for reporting on their capstone projects, so we could test for independent research skill as well as depth of understanding. We would in the future want a method to evaluate each project on
Between the other participants and TAs, as well as the many other alignment researchers working out of the MATS London office, and the speakers that we brought in, the participants would get the opportunity to meet people who would be advantageous to their career. Breaking into any field without personal connections is challenging; We believed our participants would benefit from the ability to meet others at varying different stages of their careers. In particular, this helps with having a clearer idea of who is working on similar research agendas, or knowing people who could introduce them to people working on similar research agendas. For example, most of our participants had a 1-on-1 discussion with Joseph Bloom, to discuss their capstone projects & broader questions around independent research.
Throughout the program, we invited several professionals to come speak at Arena. We tried to speak with a variety of workers, including safety work at capabilities labs, academia, independent research, and safety-focused organizations. In addition to this, we had people come speak specifically on not just their work, but specific career paths one could take. We hoped that we would be able to provide participants with an inside view of what kinds of research one can do at different organizations and gauge personal fit.
Again, our exit survey provides useful data about whether or not people feel as though their careers have been accelerated by this program. We tried to engineer the survey to avoid people subjectively self-reporting. In addition, our application had several questions about people’s career goals, so, while their goals might have been updated during the program, this still functions as a good standard against which to measure any career progress.
We plan on reaching out to participants in about six months and seeing what they are doing. At this point, we would want to gauge whether having participated in ARENA was beneficial to getting hired at their current position, and whether the skills they learned at ARENA were useful in their current position, and the network they built while at ARENA has been useful for career opportunities and projects.
Directly after the program ended, recruiters from both OpenAI and Anthropic reached out to ARENA to ask if there were any participants in the program who we were excited about or thought might be a good fit for working there - we consider this a positive signal that the skills ARENA are trying to provide are ones that these orgs are interested in hiring for. We will also see how many participants go on to be hired by highly competitive labs; if this number is high then we will consider this a success on our part. This is a signal which might take some time to come through however, especially since many of our participants were undergraduates during the program, and will not have jobs until at least a year or two after completing ARENA.
In our application, we asked what would be most helpful for people’s career goals. We then put the more common answers in a question that asked them to rank how much they agreed that Arena had helped them meet that goal. The goals were
We also asked people to self-report the biggest updates to their career plans that they’d made during the program. Broadly, the most common responses were:
The final relevant question on our exit survey was asking people about their next steps. Broadly, each participant reported doing one or more of the following:
See previous section, where we discuss this.
As mentioned, we don’t expect this to provide a strong signal immediately. However, we have already had one of our participants hired by OpenAI’s DC Evals team, and another who reached the final rounds of DeepMind’s Research Engineering interview process. This already seems like somewhat strong positive evidence that we were successful in our goal.
We would like for us to be able to provide more specific advice to our participants. If possible, we would like to expand our network of organizations doing safety work in London that our participants could speak to, compile a list of universities that have good graduate programs for safety work, or provide other more clear career recommendations for them.
Additionally, there was a higher quantity of people who left the program more interested in governance than when they came in. Since it is high value that there are technically informed people who work in governance, we might dedicate time to thinking about what governance agendas we are most optimistic about, to running reading groups for governance papers or having policy-oriented speakers.
We intended to facilitate in depth discussions through reading groups and talks from researchers. This way, participants would be deeply exposed to the intricacies of various views on alignment, from multiple perspectives. Reading groups would give them a chance to have structured discussions about specific topics, and talks would give them a chance to see things from a specific perspective.
When working on their capstone projects and some of the unstructured exercises, participants should have gotten to see how certain alignment related theories work in practice, and test if they think the theories empirically function the way they would like. We feel this is a crucial part of the ARENA program; to be able to engage with alignment agendas in an hands-on way rather than just reading about them.
There is a lot of value in having a space where people can consistently share their views with their peers, who are thinking intensely about the same problems.
Our exit survey asks some questions about how participants have changed their mind or updated throughout the program, it also asks for some general information about alignment views. It is somewhat difficult to measure whether we have succeeded here, as there isn’t really a ‘correct’ belief here.
Of all the alignment agendas in this course (either in exercises or discussed in reading groups), mechanistic interpretability took up a very large fraction of total time. There are some good reasons for this: mechanistic interpretability has good feedback loops, helps to convey many of the most difficult parts of current alignment research, can be researched without masses of prior knowledge or access to compute, has many open problems, etc. However, we still feel that the course could be a lot more balanced. Part of the reason mechanistic interpretability is so popular with new researchers is the abundance of educational material from programs like ARENA, and we strongly believe that ARENA is in an ideal position to cover other subfields of technical AI safety with just as much depth.
We will be updating the core content of ARENA in two main ways (1) putting a greater focus on techniques related to model internals which are not just interpretability (e.g. inference-time intervention), and (2) more focus on other alignment agendas such as adversarial training and scalable oversight, especially via the capstone projects / paper replication which will come at the end of the course.
In general, we think that this element of the program was not as organized as we’d have liked, and it could have benefited from a more concrete vision of what we want to discuss, and how to link that to the curriculum. We plan to do this next time, and to this end we’ve planned out a concrete set of reading materials for each week, which tie in directly to the core program content. For example, the reading groups will cover topics like reward misspecification and IDA while the participants are implementing RLHF.
In this section, we address a few different considerations relevant for whether we will be running the program again. Some of these points have already been discussed earlier, but this should provide a short overview of what we think are the most important ones.
The program was quite expensive to run. In the current climate, funding is a tradeoff that requires a lot of attention. Creating good alignment researchers feels like one of the most important problems to be putting money towards, but at the same time, we think we could capture most of the program’s value on a much tighter budget in the future. We have concrete plans for reducing the cost of the program, if we were to run it again (for example, we will be working with the London Initiative for Safe AI which has now attained office space in London, which will bring down the cost per desk from the previous iteration).
An important consideration is whether there are enough full time roles in technical AI alignment to provide for the people who are going through our program. Roles at the top safety labs are rare and highly competitive. That said, we still feel that there are enough roles and demand for highly skilled individuals to fill these roles to make ARENA worthwhile (one of our participants being hired by OpenAI’s DC Evals team, and one reaching the final round for Research Engineering at DeepMind, provides some evidence for this).
A pathway we’re also excited about is moving from ARENA to other programs which will help participants develop as independent researchers, for examples SERI MATS (which will be opening applications later this year), or the ERA Cambridge Summer Research Fellowship (which multiple participants in ARENA 2.0 went on to do once the program finished). We hope that many of these people will continue developing into strong researchers, possibly even being able to start their own organizations (see Marius Hobbahn’s recent post, making the case for there being more AI safety orgs).
If other groups are interested in running programs like ARENA, they might be able to benefit from the material which has been created for ARENA. We have already been contacted by several individuals / groups who are interested in this, including:
Running in-person versions of ARENA can multiply these benefits, because it’s one of the most effective ways of getting rapid feedback on the material.
There are several other ways we feel ARENA can provide value, other than in-person programs:
As we mentioned in the previous point, running ARENA in person is one of the fastest ways we can get feedback on the program & iterate, so all these points either directly or indirectly benefit from more in-person ARENA cohorts. However, they probably make the in-person program slightly less valuable relative to the virtual resources (not necessarily less valuable in absolute terms).
Feedback on Curriculum
In each of the questions below, participants were asked to rate how much they agreed with each statement, on a scale from 1 to 10. Responses were positive overall (especially for chapter 1: transformers & mechanistic interpretability), but with room for improvement in the chapters on reinforcement learning & training at scale.
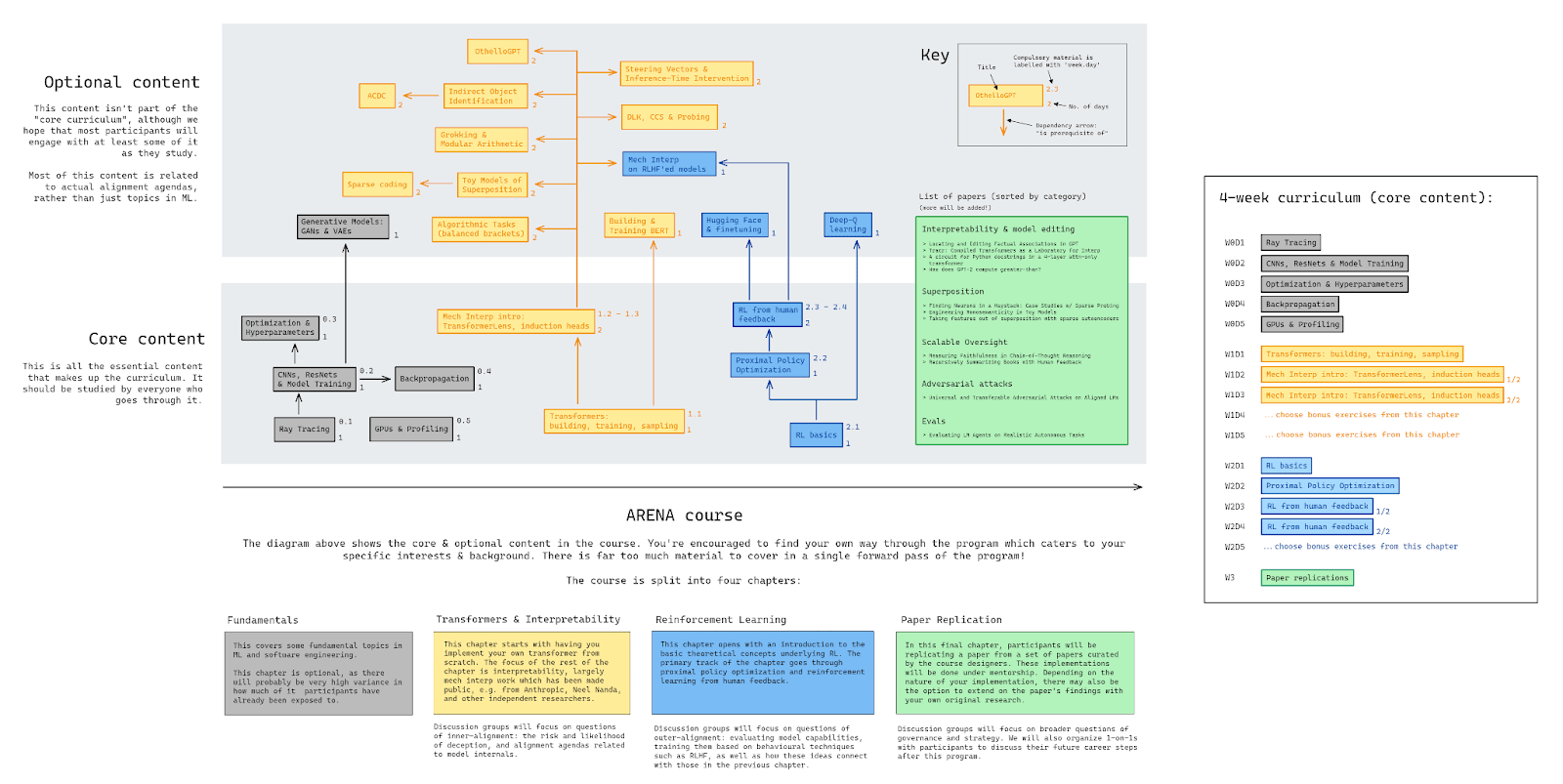
The diagram below summarizes our plans for the next iteration of ARENA, based on the feedback & lessons learned from the second iteration.
The content is split into “core” and “optional”. Note that, although the mechanistic interpretability content significantly outsizes other sections, this isn’t representative of the amount of time that will be spent on this content in the course, only how much content exists at this time. See the box on the right of the diagram for a breakdown of what we imagine the ideal 4-week curriculum might look like.
There are other subfields of technical AI safety which we’re excited to create content for in future iterations, such as:
We are not planning to include these topics in the third iteration of the program (other than as options in the paper replication chapter). This is because we want to work more with experts in these areas, and because all sections might have negative effects on capabilities research if high-quality educational material on them was made widely available.