(Lightly edited) transcript starts here
(FYI: This has a decent amount of overlap with the version I posted here two years ago, but it’s accumulated enough edits over time that I wanted to re-transcribe the latest version.)

Thank you for inviting me! This is going to be based on Intro to Brain-like-AGI Safety series of blog posts on the Alignment Forum. There’s also a PDF preprint version. I live in Boston but I work for Astera Institute, which is a foundation in California.
Part 1/3: General motivation
Let’s jump right into general motivation.
I’m going to be talking about AGI, artificial general intelligence. This part might be old hat to some of you, but just to make sure we’re on the same page, here’s a few words about how I think about AGI and what I’m working on—what’s the problem that I’m trying to solve.

So, AI as we think of it today, we’re usually imagining a tool that humans use. The future AGI that I’m concerned about, it would be best to imagine it as an agent, or a team of agents, that can figure things out, and get stuff done, and make plans, and if the plans don’t work then they come up with another solution, or they go gather more resources, and that can do creative problem solving, and autonomously invent new science and technology—all the things that humans and teams of humans and societies of humans can do, these AGIs would be able to do as well.
Oh, and another thing is: humans can pilot any arbitrary teleoperated robot, after an hour or two of practice, pretty well. I expect AGIs would be able to do that too. You don’t have to do a research project and breed a new type of human when they get a new type of teleoperated robot. They just figure it out. Likewise, I expect AGIs to be able to figure things out in the same way.

AI as we think about it today is normal sounding discourse. The future AGI I’m concerned about sounds like crazy sci-fi stuff. I like to think of it as a new intelligent species on our planet, one which will eventually vastly outnumber us, think faster and be more experienced, competent, creative, and so on.
Lots of things sound like crazy sci-fi stuff and then happen anyway. Heavier-than-air flight sounded like crazy sci-fi stuff in 1800, but it still happened. In fact, if you’re imagining the future and it doesn’t contain any crazy sci-fi stuff whatsoever, then you should be suspicious that you’re omitting something important.

Finally, in AI as we think of it today, we’re worried about bad actors, and war, and inequality, and lots of other things like that. For the future AGI I’m worried about, we still have to worry about all those things, but we also need to worry about the AGIs themselves being bad actors, probably due to human accident. And the AGI would be a bad actor that can instantly make copies of itself, think much faster than humans, and so on. This is the context where people start worrying about human extinction, and I worry about that too. So let’s try to make that less likely!

This is the area where I specifically work in, that I call Brain-like-AGI safety. It’s this scenario that says: maybe future researchers will reverse engineer, or perhaps reinvent, algorithms that are similar to those that power the human brain. So again, humans can do all those things mentioned in the previous slides—invent science and engineering from scratch, found and run companies, and so on—so there’s something in the human brain that allows them to do all those things. And an AGI could do the same thing via the same kinds of algorithms. And this is for better or worse—I’m not endorsing this as a good plan, but rather a scenario that we should be planning for. So if this happens, then how do we get to safe and beneficial AGI? That’s the research area that I work in.

So why am I working in that area? I’ll start with a diplomatic justification for that, which says that, from where we are right now, we don’t have AGIs that can autonomously invent science and engineering, and autonomously found and run companies, and so on. It’s a future technology, and we don’t yet know how it’s going to work algorithmically, so we should be contingency-planning for any algorithm that seems plausible. And surely, something similar to the human brain algorithm at least passes the bar of being a plausible scenario.

In other words if we imagine this giant universe of all algorithms that seem like they might lead to AGI as far as we know right now, we have foundation models over in the top-left corner. In the bottom-left corner, in theory you could emulate animal evolution—you might need to boil the ocean with how much compute that requires, but in in theory you could get AGI that way too. Whereas I’m working down in the bottom-right model-based reinforcement learning corner, the same corner that includes MuZero, and the H-JEPA architecture that Yann LeCun works on. I think that the algorithms powering the human brain are in that box too, for reasons that I’ll get to later in the talk, but they’re different from any model-based RL algorithm that currently exists on arXiv.
So I just got back from an AGI safety and alignment conference, and definitely felt like the guy on the right here…
…But just to be clear, I think that, given the scale and scope of the problem, we should have people working on all of these different scenarios, much more than is currently the case.

And then I have my less diplomatic justification, which says, I am expecting that foundation models will plateau before they get very powerful and dangerous. And I’m not going to defend that in this talk. I like to say “we’ll find out sooner or later”. Given the way people seem to be talking these days—y’know, Dario Amodei and so on—I think we’ll find out quite soon if they’re right or not. So why waste our time arguing about it?
One intuition that I like to offer is that sometimes there’s kinda one best algorithm for some task. For example, if you want to do a Fourier Transform of a big data set, then you should use FFT. It’s been independently reinvented multiple times. If we ever met aliens, I would expect them to be using some variant of FFT as well. So that should at least raise a possibility that maybe brains are by the same token using the one best algorithm for figuring things out in the real world and getting things done. That’s not a strong argument, it’s just trying to raise that as a possibility.

Anyway, I for one am expecting brain-like AGI. But to be clear, this doesn’t necessarily imply long timelines to AGI, by any reasonable standard. For example I like to bring up the fact that deep learning was a back-water just 13 years ago—that’s when AlexNet happened. LLMs didn’t exist seven years ago. So, ask yourself, what paradigm is a back-water today, or doesn’t even exist today, but could be subject to however many billions of dollars of investment, and everybody in the world knows all about it, in as little as five years or ten years? That’s a thing that can happen! So we might have a long time until brain-like AGI, but we also shouldn’t rule out that it’s something that could happen relatively soon. Not “soon” as in “superintelligence in 2027”, like Dario Amodei is talking about, but “soon” as in 2030, or certainly the 2030s, is possible.
Part 2/3: Very big picture of brain algorithms
So that was the introduction, and I’ll move on to a very big picture of brain algorithms.
So the whole idea of brain-like AGI is that it’s a tractable research program, because we know something about these algorithms that we’re trying to prepare for, because we can study brains. So in particular, this requires that we know enough about brains to say any useful things at all about this hypothetical future brain-like AGI.

So I do sometimes get pushback to this claim by people who say “no no no, the brain is obscenely, ridiculously complicated, we have not made any progress, and we’re still many centuries if not millennia away from understanding it”. People joke about this. I joke about it too, as you see here.

…But what I really believe is that brain complexity as it pertains to AGI is very easy to overstate, and is very often overstated, and the basic reason is that “understanding the brain well enough to make brain-like AGI” is a different and much simpler task than just “understanding the brain”. So if neuroscientists see “understanding the brain” as their goal, then yeah of course they’ll see it as really complicated, but that’s not the bar that I’m concerned about. I’m concerned about this much easier task.
There’s a few reasons for that.

The first reason is that learning algorithms are much simpler than the trained models that they create. So probably many of you in the room can train a convolutional neural net, and understand how that works, but probably nobody in this room and nobody in the world can take the 100 million parameters of a trained convolutional neural net and explain exactly step by step how it classifies a fish, via these giant lists of numbers in the trained weights. So by the same token, if you look at an adult human, and you ask a Cognitive Science question, like how does the adult human do such-and-such task, that’s at least partly a question about the adult human’s trained models, and they’ve been thinking and learning and trying things out for a billion seconds of their life, and they’ve wound up with all of these learned habits and learned models and so on that are informing their behavior as an adult. I think that, just like we already can train ConvNets, by the same token, we’ll be building brain-like AGI long before we can answer those kinds of Cognitive Science questions.
Then another reason that brain complexity is very easy to overstate, is that algorithms in general are much simpler than their physical instantiations. So again, many of you in the room can train a ConvNet, but few if any of you can explain top to bottom, starting from the laws of physics, how your physical chip is implementing that learning algorithm, which includes everything from integrated circuit physics and engineering, to CUDA compilers, and so on. So by the same token if you look at the brain you don’t just see the algorithm, you see the physical implementation, and if you zoom in on any neuron then you can see this fractal-like complexity, in that the more you zoom, the more complexity you find, but I think that people will be building brain-like AGI long before we have reverse-engineered all these gory details of protein cascades and everything else about molecular biology related to neuroscience.

And then last but not least, the parts of the brain algorithm that are necessary for general intelligence are much simpler than the entire brain algorithm. Here’s a picture of a guy with no cerebellum, who is happily holding down a job. People are born missing an entire cerebral cortex hemisphere. There’s some little bit of the brainstem that is wired up in such a way that it encodes this motor program that the right way to vomit if you’re a human is to contract such-and-such muscles in such-and-such order, and release certain hormones, and so on. Nobody needs to reverse engineer or reinvent those parts of the brain in order to make brain-like AGI.

OK, so hopefully we’re feeling more like we have a can-do attitude about understanding the brain well enough to make progress on this research program. And to move forward, one of the key concepts that I go back to all the time when I talk about the brain is “learning from scratch”.
Here’s two examples of things that are “learning from scratch”, and then I’ll say what they have in common. The first example is any machine learning algorithm whatsoever that’s initialized from random weights, and the second example is a blank flash drive that you just bought from the store, and the bits are all random, or they’re all zeros or or whatever. So what do these have in common? They initially can only emit signals that are random garbage, or otherwise useless, but over time they can emit more and more useful signals thanks to a learning algorithm that adjusts some memory store inside them. So in the case of an ML algorithm, again let’s say a ConvNet image classifier, all of its labels are going to be random garbage when you first turn it on, but gradient descent updates the weights and then it winds up doing all this cool useful image classifications for us. And, likewise a blank flash drive is very useful, but you can’t pull any information off of it until after you’ve already written information onto it. So “learning from scratch” is sort of referring to memory systems, in a very broad sense.

And my hypothesis is that more than 90% of the human brain “learns from scratch” in this sense, including the whole cortex, including neocortex and hippocampus, the striatum including nucleus accumbens, the amygdala, and the cerebellum. But the big exceptions are the hypothalamus and the brainstem.

(This little bit at the bottom near the spine.)

So that’s a hypothesis. Should we believe it? Well, I believe it. My take is that there’s actually a lot of strong evidence in favor of this hypothesis, and you can see my blog post “Learning From Scratch” in the Brain for that whole discussion. I find that a few neuroscientists agree with me, and a few disagree, and it seems like the vast majority have never considered that hypothesis in the first place.
So for example, horses can walk within an hour of birth. Here’s two theories that could explain that. The first says that the horse brain has learning algorithms, and the learning algorithms are pre-trained by evolution. And then a different theory is the horse brain has learning algorithms, but it also has other stuff which are just not learning algorithms at all, but rather innate reflexes of various sorts. I favor the second hypothesis over the first hypothesis, but you can find papers that discuss the first hypothesis at length without ever mentioning that the second hypothesis is even a possibility at all. Tony Zador’s “Critique of Pure Learning” is in that category. But if you look at the neonatal literature, I think there’s good evidence that neonatal behavior really doesn’t have much at all to do with the cortex, but is rather driven by the hypothalamus and brainstem, which again are not learning algorithms.
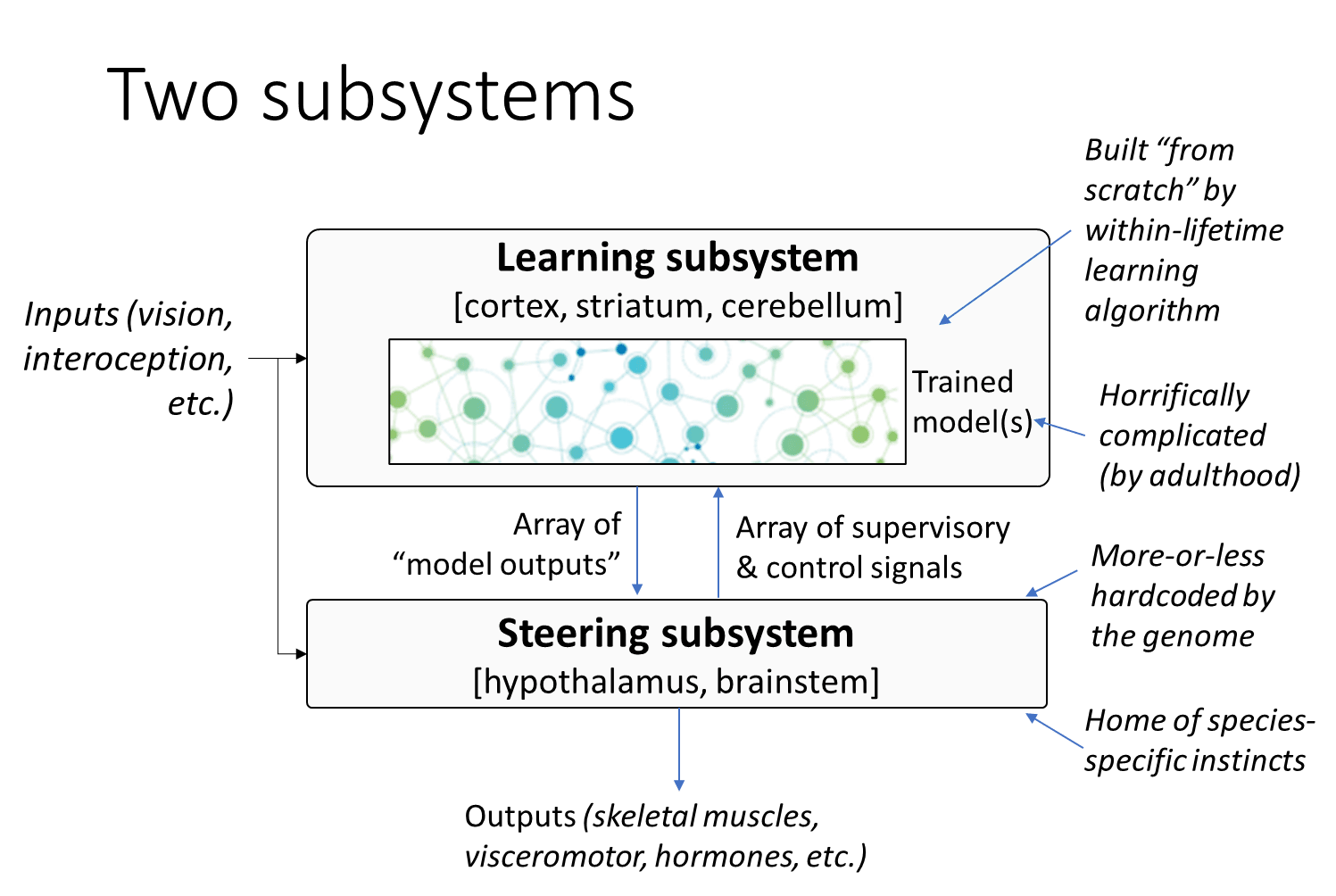
OK, so if you buy what I’ve said so far, then you wind up with this picture of the brain in which there are two subsystems. The first is the Learning Subsystem that has all of the within-lifetime learning algorithms, and it gets horrifically complicated by the time you’re an adult, because you’ve had a billion seconds of learning, and then there’s the Steering Subsystem with the hypothalamus and the brainstem, that contains all of the species-specific instincts like how to vomit, and these are interconnected to each other and to inputs and outputs.
Whenever I show people that two-subsystem picture, they tend to pattern-match it to a lot of things that I don’t endorse. So here’s some more clarifications along those lines.

The first thing that this two subsystem picture is NOT: it is not “old brain, new brain” or “triune brain”. These are discredited theories of brain evolution from like the 1970s. For one thing, I draw the boundaries in a different place. For example, people like to lump the amygdala and the hypothalamus together, whereas from my perspective the amygdala is definitely a learning algorithm, and the hypothalamus is definitely not. And also, both subsystems are extremely old. Lizards have both a Learning Subsystem and a Steering Subsystem. Even 500 million years ago, our tiny wormlike ancestors had both a Learning Subsystem and a Steering Subsystem. Of course, both were much simpler than ours, but both are extremely old.

Another thing that my two-subsystem picture is NOT, is a blank slate theory, or nurture over nature.
For one thing, the Steering Subsystem has all these specific instincts in them that are playing a very important role.
And also, learning algorithms have internal structure! They are not blank slates. Many of you in this room know how to program a learning algorithm, and what you DON’T do to program a learning algorithm is open a blank python interpreter and say “well I’m done, that’s my learning algorithm”. No! You need neural architecture, you need learning rules, you need hyperparameters, you need a loss function, on and on. So by the same token, the genome has a lot of work to do to create a learning algorithm, it’s not just a sponge that somehow absorbs information.
And then finally, “learning” is different from “a human is deliberately teaching me”, which is what people usually talk about in the context of “nurture”. For example, animals will learn to control their own bodies using internal loss functions and using reinforcement learning and trial and error. So this is learning, and it’s learning from scratch, but parents don’t have any control over that process.

Another thing that my two-subsystem picture is NOT, is a distinction between plasticity and non-plastic parts of the brain. So plasticity, in the context of brain plasticity or synaptic plasticity—well, people sometimes use the term “plasticity” in a non-rigorous way to sort of invoke magical thinking about some animistic force that makes your brain do intelligent adaptive things, but what plasticity really should mean is that there are some persistent variables in the brain algorithm, and under such-and-such conditions they’re updated in such-and-such ways.
So if you have a learning algorithm, it definitely needs plasticity, because all of the weights need to be updated. But many other algorithms need plasticity as well! For example, if there’s a counter variable that you sometimes increment by one, that would be plasticity. And there’s a real example that’s a little bit like this: there’s an experimental result that, the more that a rat has won fights in its life, the more aggressive it will act. So that’s kind of like there’s a counter variable in its brain that’s just counting how many fights it’s won, and every time it wins a fight, the counter goes up. And when people did that measurement, they found some set of cells in the hypothalamus that had plasticity. But that’s not “learning” in the sense of “learning from scratch” or “learning algorithms”. It’s really just a counter variable.

And then the last thing my two-subsystem picture is NOT, is some brilliant idea unknown in machine learning. Quite the contrary, every ML GitHub repository has lots of code that is not the core learning algorithm itself. For example, this is an AlphaZero clone, seeing whether it’s checkmate, as part of the reward function. The fact that there is code which is not implementing the core learning algorithm is just so obvious in machine learning that people don’t talk about it. But in the brain, everything is neurons and synapses, you don’t have labeled variables and folders like you do on GitHub, so people can fall into this trap of saying: there are neurons everywhere in the brain, therefore everything in the brain is a learning algorithm.
Part 3/3: The “Steering Subsystem” as the ultimate source of motivations, drives, values, etc.
Moving on to the third part of the talk, I’ll discuss the Steering Subsystem, which is very close to my heart, and I will claim that it’s the ultimate source of motivations and drives and values, and how this is related to AGI safety.

OK, so I mentioned earlier that we should think of brain-like AGI as a kind of model-based reinforcement learning. I mean this in a pretty minimal sense.
- There’s a model—I can make predictions. I know that if I jump in the lake then I’m going to get wet, and if I get wet then I’m going to be cold.
- The model is updated by self-supervised learning. If I drop a ball, and I didn’t expect it to bounce, but it bounces anyway, then the next time I drop the ball then I’m going to expect it to bounce.
- And there’s reinforcement learning. If I touch a hot stove then I won’t do it again.
- And the model is connected to the reinforcement learning, to enable planning. If I don’t like being cold then I won’t jump in the lake.

So, model based reinforcement learning is a very big tent; there’s probably 500 different kinds of model-based reinforcement learning algorithms on arXiv, and they’re all different from each other, and they’re all different from the brain. The details of model-based RL in the brain are something that I’m not going to get into, but you can read all about it in the blog post series.

So why am I using the term “steering subsystem”? Well, one particularly important thing it does is to steer the learning subsystem to emit ecologically useful outputs by sending it rewards. So, you touch a hot stove, and then you get negative reward, and then you’re less likely to do it again. This is analogous to how in AlphaZero, you have your RL reward function, and it “steers” the trained AlphaZero to behave in certain ways. If you have AlphaZero-chess and there’s a reward for winning, then it’s going to get very good at winning at chess, whereas if there’s a reward for losing, then it’s going to get very good at losing at chess.

So by the same token, there’s something like that in your brain, and in the case of humans it says pain is bad (other things equal) and eating when you’re hungry is good, there’s a curiosity drive, and so on. You don’t have to train a mouse to dislike being in pain, it comes that way right out of the box—umm, out of the womb, I guess.

So if people make future AGIs using the same kind of algorithmic architecture, then they too get to choose a reward function, and what is it going to be? I don’t know! Whatever they decide to put in. If you look at the RL literature today, you’ll notice that people put all kinds of reward functions without thinking too hard about it. It’s usually “what reward function is going to get me a NeurIPS paper”, “what’s going to impress the investors”, get a high score in the game, whatever.
And the default result if you just do whatever looks cool as your reward function, is that I claim it will grow into an AGI that has callous indifference to human welfare. So if we want to avoid that, then picking the right reward function is a huge part of solving that problem. It’s not the whole solution, because there’s also training environment, or you could do interpretability, whatever. But I think that the reward function is really a big part of the solution.

So again if you look in humans, pain is bad, eating when you’re hungry is good, and so on, but a big one that I didn’t mention is social instincts. I claim that human social instincts are upstream of all of the social and moral things that we do—compassion, friendship, spite, norm-following, etc.
That’s not to say that we’re insensitive to culture, we do pick up habits from culture all the time, but we pick up things from culture because we want to pick up things from culture. It’s incentivized by our reward function. If you see something in culture, you don’t necessarily absorb it like a sponge. If the cool kid in school is wearing pink sunglasses then you’re going to start thinking that wearing pink sunglasses is cool, but if the dumbest kid in school that you hate is wearing pink sunglasses, then you don’t want to wear pink sunglasses. So this whole process goes back to the reward function, even if it involves the environment.
So if we understand how human social instincts work, that could be a good jumping-off point for AGI, because hey, we want our AGIs to have compassion and norm-following. Not so sure about the spite and the status-seeking, but at least those first two seem pretty good, so we should try to figure out how they work.
First I wanted to just say loud and clear, so that you don’t miss this point, that hyper-competent brain-like AGI does not inevitably come along with compassion and friendship and other social motivations and feelings. I think that high functioning sociopaths are a great example here; well, they do have some social instincts, but they have very different social instincts from typical, and yet they can found companies, they can do science and engineering using the same kinds of algorithmic tricks that everybody else uses.
And not only that, but it will actually be easier for future AGI programmers to leave out pro-social motivations—those motivations need to be proactively added into the source code, and we don’t know how.

So that brings us to: how do human innate drives work? That’s a million-dollar question, and the reason it’s a tricky question is that the hypothalamus and the brainstem—the Steering Subsystem—are kind of stupid. They don’t understand the world, they don’t know what’s going on, they don’t have any circuits for being in debt and for Alice from accounting, they don’t have any of that in their circuitry, they’re wired up to things like vomiting. But somehow the hypothalamus and brainstem are in charge of figuring out when exactly to provide ground truth reward. So how does that work?

Well, here’s one part of the answer: the steering subsystem has its own too-often-ignored sensory processing systems.
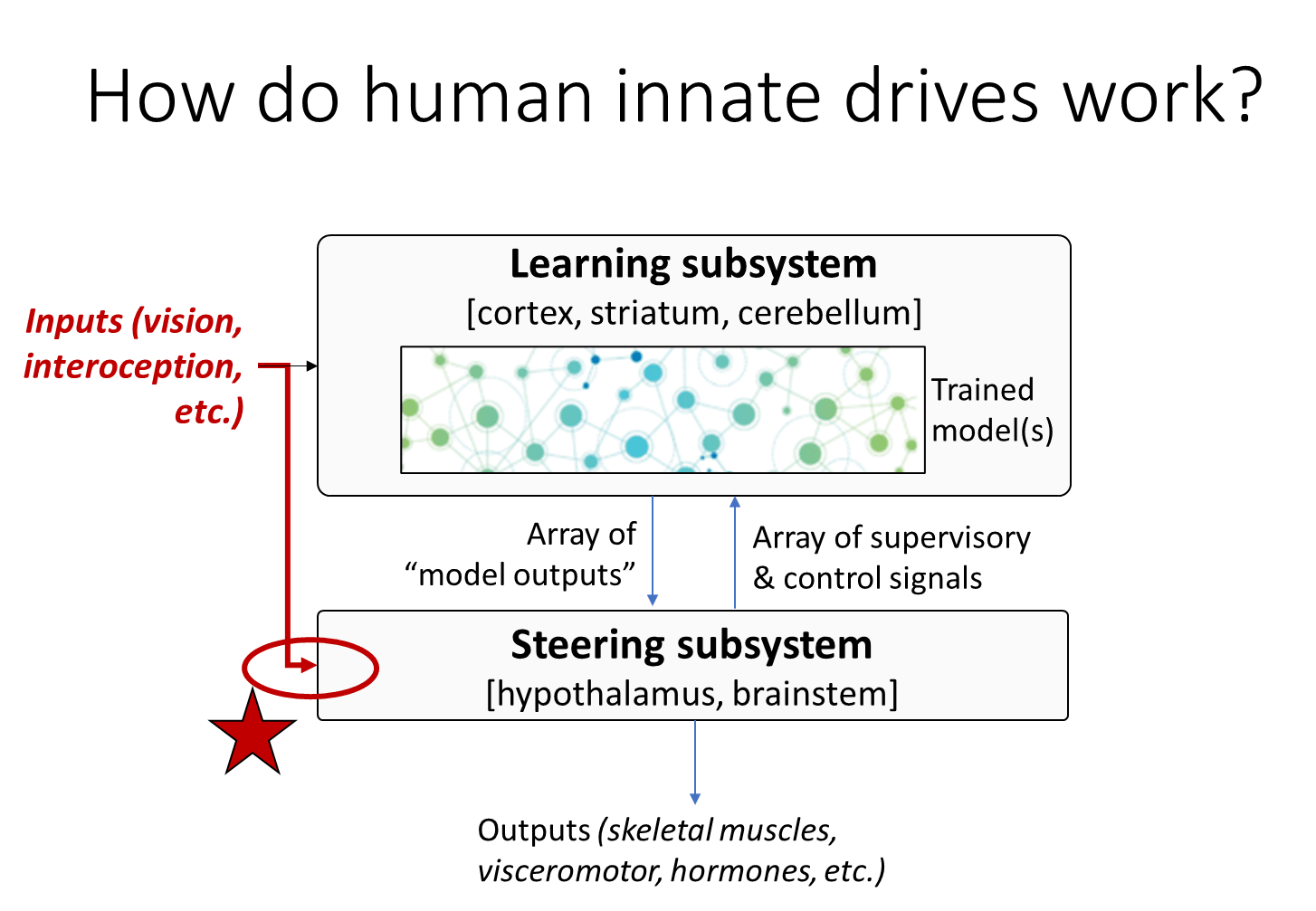
I actually already showed that, if you remember this diagram from earlier in the talk, this red arrow here shows that sensory inputs go straight to the Steering Subsystem.
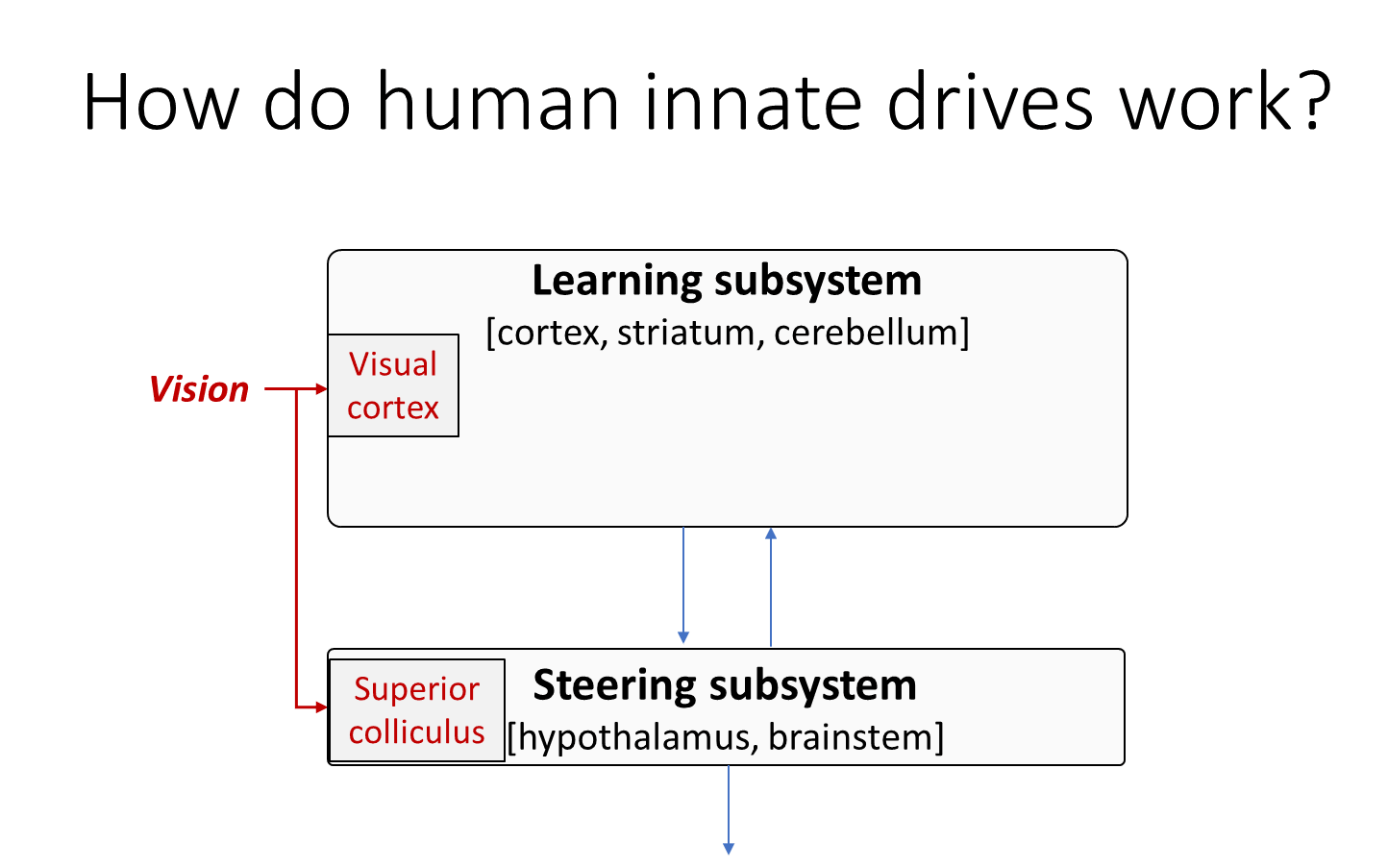
So for example, visual information goes to the visual cortex but it also goes straight to the superior calculus in the brainstem.
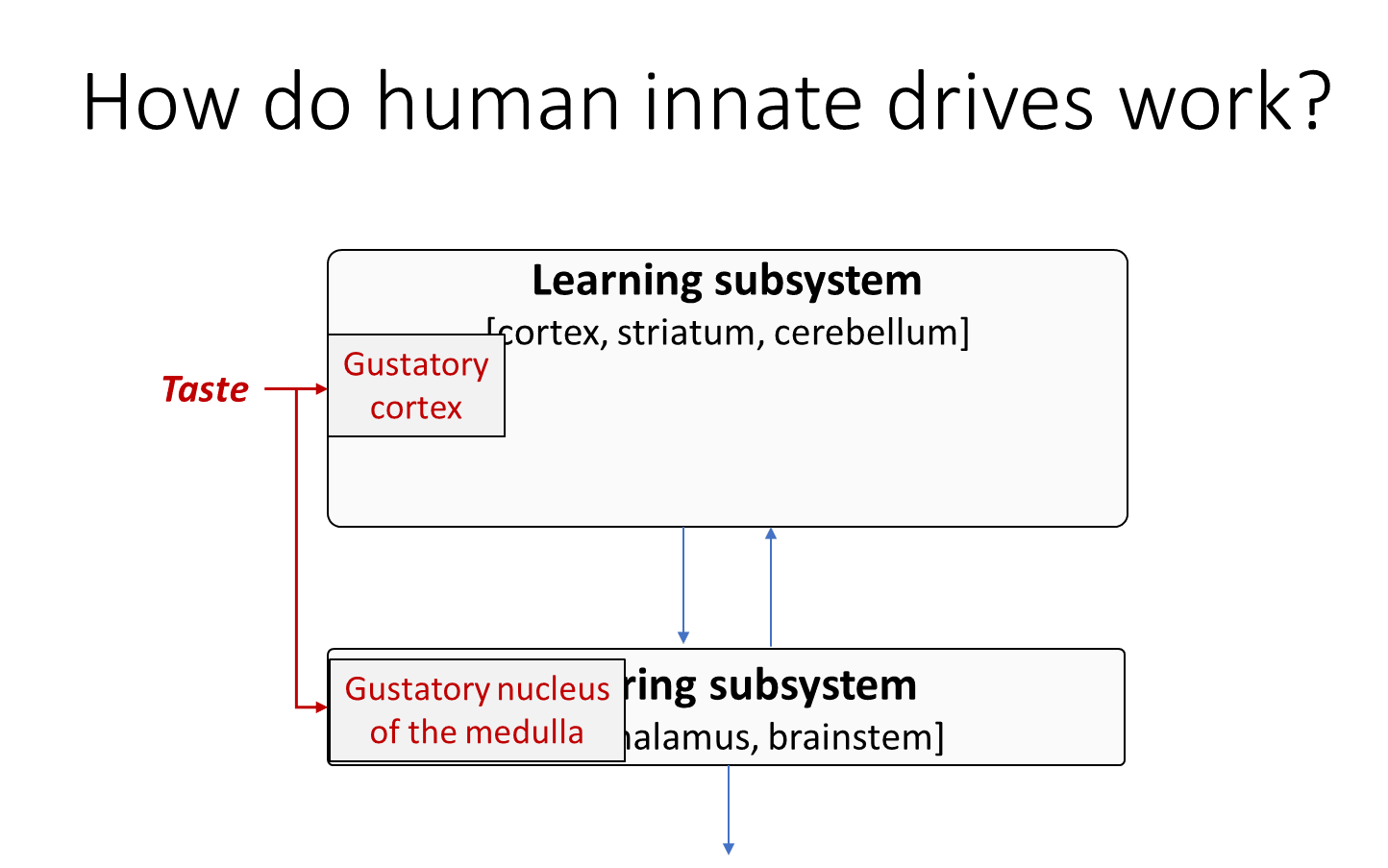
Likewise taste has its own route to the brainstem in the medulla, and smell has this obscure “necklace glomeruli” route to a different obscure part of the Steering Subsystem, on and on with all of the different senses.

Then what happens? Well the superior calculus has direct access to sensory information and that’s connected to a hardwired face detector, and also I think a detector of slithering snakes, or at least things that slither kind of like a snake, and skittering spiders so on. A lot of your innate drives or primary rewards are connected to sensory inputs in this way—the smell of rotten meat, the taste of sugar, feel of pain, fear of heights, all of those things can be wired up in in the obvious way just by processing sensory information and matching them against innate evolved heuristics.
But that’s not the whole answer because, for example, think about spite. Your brain cannot calculate when to feel spite from simple heuristics on sensory inputs. It requires understanding language and situations and context that is far beyond what the hypothalamus and brainstem are capable of. So there’s really a symbol grounding problem that the brain somehow solves, in the sense that there’s sorta learned symbols in your cortex, which is the intelligent part of the human brain that’s learning language and learning about Alice from accounting, and then the hypothalamus and brainstem have to somehow figure out what’s the meaning of these symbols, at least as it pertains to triggering innate reactions.

So this has been the main research program that I’ve been working on for the past three years or so. I do other stuff too but this has been a major research interest of mine. And I think I’ve made some progress, especially with this recent post called Neuroscience of Human Social Instincts: A Sketch, that catches up with where I’m at right now. I wind up believing that there’s this long and somewhat convoluted story, it’s not terribly elegant, it has a lot of ingredients, but I claim that all of the ingredients in the story are things that are definitely in our brain, things that correspond to neuroanatomy in a specific way, things that makes sense evolutionarily, things that have homologies in mice, things that are related to famous reactions like orienting to a loud sound.
Anyway, it starts with these innate sensory heuristics, as I just mentioned, but then those are used as ground truth for a bunch of supervised learning algorithms in the amygdala and elsewhere, and then the learned content of those algorithms is sculpted by learning rate modulation and something that I call involuntary attention, and then this eventually leads into a way for the hypothalamus and the brainstem to detect and process what I call “transient empathetic simulations” where it figures out that I’m thinking of a different person who is angry right now, for example, and then if you wire those up correctly you can wind up with compassion and spite and status-seeking and so on.

…But this is a sketchy outline, there’s plenty more work to do even if I’m on the right track.

OK so then, are human social instincts a jumping off point for AGI? Well slavishly copying them into an AGI is for sure a terrible idea. One reason is that normally human social instincts are combined with growing up in a human body in a human culture at human speed, and feral children do wind up pretty messed up, so the human social instincts are not enough if you don’t spend any time thinking about training environments, or adjusting for that. And also of course human social instincts leave something to be desired! I don’t want my AGI to have bloodlust and teenage angst and status seeking.

But if it’s a jumping-off point, then OK, let’s jump off of it and start thinking directly about brain like AGI! What should the reward function be, what should the training environment be, so on and so forth. That’s what I’ve been pondering since writing that post a few months ago, and I got my work cut out, I don’t have any good plan for brain-like AGI, so if anyone else wants to work on it you there’s still plenty of important open problems. We don’t have a good plan, and I hope nobody invents brain-like AGI before we come up with one.

So in conclusion, if people invent brain-like AGI, it’s going to be a very big deal, certainly the best or worst, probably the last, thing that will ever happen to humanity, but there’s technical work that we can do today to increase the odds that things go well! Thank you for listening.
Executive summary: This updated transcript outlines the case for preparing for “brain-like AGI”—AI systems modeled on human brain algorithms—as a plausible and potentially imminent development, arguing that we can and should do technical work now to ensure such systems are safe and beneficial, especially by understanding and designing their reward mechanisms to avoid catastrophic outcomes.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.