Summary: Like for quantified risk, we can sometimes hedge against deep uncertainty and moral uncertainty: we can sometimes choose a portfolio of interventions which looks good in expectation to all (or more) worldviews - empirical and ethical beliefs - we find plausible, even if each component intervention is plausibly harmful or not particularly good in expectation according to some plausible worldview. We can sometimes do better than nothing in expectation when this wasn't possible by choosing a single intervention, and we can often improve the minimum expected value. I think doing so can therefore sometimes reduce complex cluelessness.
My recommendations are the following:
- We should, when possible, avoid portfolios (and interventions) which are robustly dominated by any other in expectation - those worse in expectation than another under some plausible worldview and no worse on any plausible worldview (or those ruled out by the maximality rule; EA Forum post on the paper). I think this is rationally required under consequentialism, assuming standard rationality axioms under uncertainty.
- I further endorse choosing portfolios among those that are robustly positive in expectation - better in expectation than doing nothing under all worldviews we find plausible - if any are available. However, this is more a personal preference than a (conditional) requirement like 1, although I think something that's often implicitly assumed in EA. I think this would lead us to allocate more to work for nonhuman animals and s-risks.
- EAs should account for interactions between causes and conflicts in judgements about the sign of the expected value of different interventions according to different worldviews. I think this is being somewhat neglected as many EA organizations or divisions in EA organizations are cause-specific.
- Approaches for moral uncertainty and deep uncertainty are better applied to portfolios of interventions than to each intervention in isolation, since portfolios can promote win-wins.
- We should not commit to priors arbitrarily. If you don't feel justified in choosing one prior over all others (see the reference class problem), this is what sensitivity analysis and other approaches to decision making under deep uncertainty are for, and sometimes hedging can help, as I hope to illustrate in this post.
- EDIT: It's not always necessary to hedge against the negative side effects of our interventions we choose at the same time as we work on or fund those interventions. We can sometimes address them later or assume we (or others) will.
Introduction
EAs have often argued against diversification and for funding only the most cost-effective intervention, at least for individual donors where the marginal returns on donations are roughly constant. However, this assumes away a lot of uncertainty we could have; we might not believe any specific intervention is the most cost-effective. Due to deep uncertainty, we might not be willing to commit to a specific single joint probability distribution for the effects of our interventions, since we can't justify any choice over all others. Due to moral uncertainty, we might not be confident in how to ethically value different outcomes or actions. This can result in complex cluelessness, according to which we just don't know whether we should believe a given intervention is better or worse than another in expectation; it could go either way.
Sometimes, using a portfolio of interventions can be robustly better in expectation than doing nothing, while none of the best individual interventions according to some worldview are, since they're each plausibly harmful in expectation (whether or not we're committed to the claim that they definitely are harmful in expectation, since we may have deep or moral uncertainty about that). For example, cost-effective work in one cause might plausibly harm another cause more in expectation, and we don't know how to trade off between the two causes.
We might expect to find such robustly positive portfolios in practice where the individual interventions are not robust, because the interventions most robustly cost-effective in one domain, effect or worldview will not systematically be the most harmful in others, and if they aren't so harmful that they can't be cost-effectively compensated for with interventions optimized for cost-effectiveness in those other domains, effects or worldviews. The aim of this post is to make a more formal and EA-relevant illustration of the following reason for hedging:
We can sometimes choose portfolios which look good to all (or more) worldviews we find plausible, even if each component intervention is plausibly harmful or not particularly good in expectation according to some plausible worldview.
Diversification is of course not new in the EA community; it's an approach taken by Open Phil, and this post builds upon their "Strong uncertainty" factor, although most organizations tend not to consider the effects of interventions on non-target causes/worldviews, where hedging becomes useful.
An illustrative example
I will assume, for simplicity, constant marginal cost-effectiveness across each domain/effect/worldview, and that the effects of the different interventions are independent of one another. Decreasing marginal cost-effectiveness is also a separate reason for diversification, so by assuming a constant rate (which I expect is also approximately true for small donors), we can consider the uncertainty argument independently. (Thanks to Michael_Wiebe for pointing this out.) EDIT: I'm also assuming away moral uncertainty (e.g. about relative moral weight of nonhuman animals vs humans, conditional on empirical facts) here; see this article for some discussion.
Suppose you have deep or moral uncertainty about the effects of a given global health and poverty intervention on nonhuman animals, farmed or wild, enough uncertainty that your expected value for the intervention ranges across positive and negative values, where the negative comes from effects on nonhuman animals, due to moral empirical uncertainty related to how to weigh the experiences of nonhuman animals and welfare in the wild, the meat eater problem (it may increase animal product consumption) and deep uncertainty about the effects on wild animals.
You could represent the expected cost-effectiveness across these components as a set of vectors with ranges. Assuming independent effects on each component, you might write this as the following set, a box in 3 dimensions:
H=[100,200]×[−300,50]×[−50,50]={(x,y,z)∈R3 | 100≤x≤200, −300≤y≤50, −50≤z≤50}
Here, the first component, [100,200], is the range of expected cost-effectiveness for the humans (living in poverty), the second, [−300,100], for farmed animals, and the third, [−50,50], for wild animals. These aren't necessarily in the same comparable utility units across these three components. The point is that two of the components are plausibly negative in expectation, while the first is only positive in expectation, and it's plausible that the intervention does more harm than good in expectation or does more good than harm in expectation. (Depending on your kind of uncertainty, you might be able to just add each of the components instead, e.g. as H=[100,200]+[−300,50]+[−50,50]=[100−300−50,200+50+50]=[−250,300], but I will continue to illustrate with separate components, since that's more general and can capture deeper uncertainty and worse moral uncertainty.)
You might also have an intervention targeting farmed animals and deep or moral uncertainty about its effects on wild animals. Suppose you represent the expected cost-effectiveness as follows, with the effects on humans first, then on farmed animals and then on wild animals, as before:
F=[−10,10]×[100,1000]×[−100,100]
You represent the expected effectiveness for a wild animal intervention as follows, with the effects on humans first, then on farmed animals and then on wild animals:
W=[−10,10]×[−10,10]×[100,1000]
And finally, you have a default "do nothing" or "business as usual" option, e.g. spending selfishly:
N={(0,0,0)}
I model N as all 0s, since I'm considering the differences in value with doing nothing, not the expected value in the universe.
Now, based on this example, we aren't confident that any of these interventions are better in expectation than N, doing nothing, and generally, none of them definitely beat any other in expectation, so on this basis, we might say all of them are permissible according to the maximality rule. However, there are portfolios of these interventions that are better than doing nothing. Assuming a budget of 10 units, one such portfolio (better than 10N) is the following:
H+4F+5W=[100−4∗10−5∗10,200+4∗10+5∗10]× [−300+4∗100−5∗10,50+4∗1000+5∗10]× [−50−4∗100+5∗100,50+4∗100+5∗1000]=[10,290]×[50,4100]×[50,5450]
That is, you spend 4 times as much on F as H, and 5 times as much on W as H. We can divide by 10 to normalize. Notice that each components is strictly positive, so that this portfolio is good in expectation - better than N (and 10N) - for humans, farmed animals and wild animals simultaneously.
According to recommendation 1, N, doing nothing, is now ruled out, impermissible. This does not depend on the fact that I took differences with doing nothing, since we can shift them all the same way.
According to recommendation 2, which I only weakly endorse, each individual intervention is now ruled out, since each was plausibly negative (compared to doing nothing) in expectation, and we must choose among the portfolios that are robustly positive in expectation. Similarly, portfolios with only two interventions are also ruled out, since at least one of their components will have negative values in its range.
I constructed this example by thinking about how I could offset each intervention's harms with another's. The objection that offsetting is suboptimal doesn't apply, since, by construction, I can't decide which of the interventions is best in expectation, although I know it's not doing nothing.
Note also that the cost-effectiveness values do not depend on when the effects occur. Similarly, we can hedge over time: the plausible negative effects of one intervention can be made up for with positive effects from another that occur far earlier or later in time.
Dependence
We assumed the interventions' components were independent of one another and of the other interventions' components. With dependence, all the portfolios that were robustly at least as good as doing nothing will still be robustly as good as doing nothing, since the lower bounds under the independent case are lower bounds for the dependent case, but we could have more such portfolios. On the other hand, different portfolios could become dominated by others when modelling dependence that weren't under the assumption of independence.
Lexicality and deontological constraints
Under some deontological ethical theories, rule violations (you commit) can't be compensated for, no matter how small. You could represent rule violations as −∞ - or multiples of it, without multiplying through, or using vectors for individual components to capture lexicality. Portfolios that include interventions that violate some rule will generally also violate that rule. However, we should be careful to not force cardinalization on theories that are only meant to be ordinal and do not order risky lotteries according to standard rationality axioms; see some quotes from MacAskill's thesis here on this, and this section from MichaelA's post.
Other potential examples
- Pairing human life-saving interventions with family planning interventions can potentially minimize externalities due to human population sizes, which we may have deep uncertainty about (although this requires taking a close look at the population effects of each, and it may not work out). These interventions could even target different regions based on particular characteristics, e.g. average quality of life, meat consumption. Counterfactually reducing populations where average welfare is worse (or meat consumption is higher) and increasing it the same amount where it's better (or meat consumption is lower) increases average and total human welfare (or total farmed animal welfare, assuming net negative lives) without affecting human population size. Of course, this is a careful balancing act, especially under deep uncertainty. Furthermore, there may remain other important externalities.
- We might find it plausible that incremental animal welfare reform contributes to complacency and moral licensing and have deep uncertainty about whether this is actually the case in expectation, but we might find more direct advocacy interventions that can compensate for this potential harm so that their combination is robustly positive.
- Extinction risk interacts with animal welfare in many ways: extinction would end factory farming, could wipe out all wild animals if complete, could prevent us from addressing wild animal suffering if only humans go extinct, and if we don't go extinct, we could spread animal suffering to other planets. There are other interactions and correlations with s-risks, too, since things that risk extinction could also lead to far worse outcomes (e.g. AI risk, conflict), or could prevent s-risks.
- Animal advocacy seems good for reducing s-risks due to moral circle expansion, but there are also plausible effects going in the opposite direction, like correlations with environmentalism or "wrong" population ethics or near-misses.
- In the wild animal welfare space, I've been told about pairing interventions that reduce painful causes of death with population control methods to get around uncertainty about the net welfare in the wild. In principle, with a portfolio approach, it may not be necessary to pair these interventions on the same population to ensure a positive outcome in expectation, although applying them to the same population may prevent ecological risks and reduce uncertainty further.
- Substitution effects between animal products. We might have moral uncertainty about the sign of the expected value of an intervention raising the price of fish, in case it leads consumers to eat more chicken, and similarly for an intervention raising the price of chicken, in case it leads consumers to eat more fish. Combining both interventions can reduce both chicken and fish consumption. As before, these interventions do not have to even target the same region, as long as the increase in fish consumption in the one region is smaller than the increase in the other (assuming similar welfare, amount of product per animal, etc. or taking these into account), and the same for chicken consumption.
Questions and possible implications
- I think recommendation 2 would push us partially away from global health and poverty work and extinction risk work and towards work for nonhuman animals and s-risks, due to the interactions I discuss above.
- Should we choose portfolios as individuals or as a community? If as a community, and we endorse recommendation 2 for the community, i.e. we should do robustly better in expectation than doing nothing, individuals may be required to focus on plausible domains/worldviews/effects according to which the community is plausibly doing more harm than good in expectation, if any exists. This could mean many more EAs should focus on work for nonhuman animals and s-risks, since global health and poverty work and extinction risk work, some of the largest parts of the EA portfolio, are plausibly net negative due to interactions with these.
- I personally doubt that we have fundamental reasons to decide as a community (coordination and cooperation are instrumental reasons). Either our (moral) reasons are agent-relative or agent-neutral/universal; they are not relative to some specific and fairly arbitrarily defined group like the EA community.
- Should we model the difference compared to doing nothing and use doing nothing as a benchmark as I endorse in recommendation 2, or just model the overall outcomes under each intervention (or, more tractably, all pairwise differences, allowing us to ignore what's unaffected)? What I endorse seems similar to similar risk-aversion with respect to the difference you make by centering the agent, which Snowden claims is incompatible with impartiality. In this case, rather than risk-aversion, it's closer to uncertainty/ambiguity aversion. It also seems non-consequentialist, since it treats one option differently from the rest, and consequentialism usually assumes no fundamental difference between acts and omissions (and the concept of omission itself may be shaky).
- What other plausible EA-relevant examples are there where hedging can help by compensating for plausible expected harms?
- Can we justify stronger rules if we assume more structure to our uncertainty, short of specifying full distributions? What if I think one worldview is more likely than another, but I can't commit to actual probabilities? What if I'm willing to say something about the difference or ratio of probabilities?
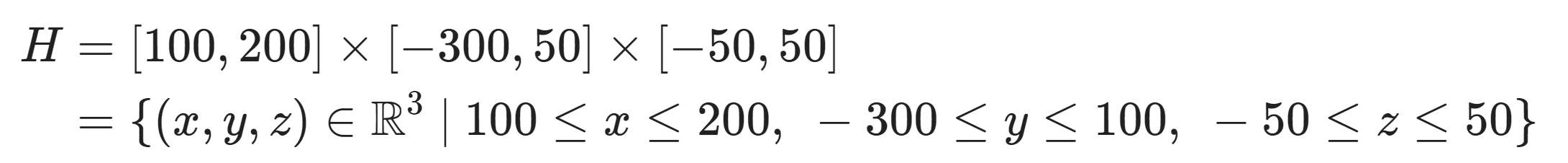
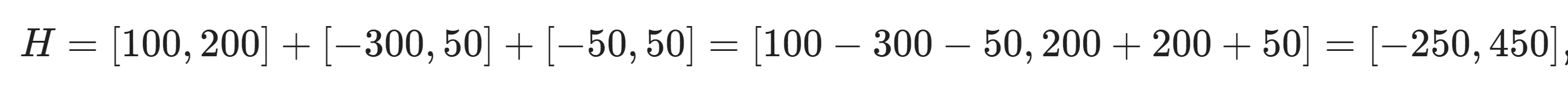


Thanks for writing this, that was an interesting read!
Whether or not you think you can add separate components seems pretty important for the hedging approach.
Indeed, if a portfolio dominates the default on each individual component, then some interventions in the portfolio must dominate the default overall.[1] So if you can compare interventions based on their total effects, the existence of such portfolios imply that some interventions dominate the default. Intuitively then, you would prefer investing in one of those interventions over hedging? (Although a complication I haven't thought about is that you should compare interventions with one another too, unless you think the default has a privileged status.)
Given the above, a worry I have is that the hedging approach doesn't save us from cluelessness, because we don't have access to an overall-better-than-the-default intervention to begin with.
To put my two questions in more concrete terms:
Sketch of proof: Let wi be ressources allocated to intervention Ai in your portfolio, and let aji be the worst-case effect of intervention Ai on component j. Then
∑i,jwiaji=∑i(∑jaji)wi≥0and there is an intervention for which worst-case effects are in aggregate non-negative.
Hi Nicolas, thanks for commenting!
Ah, good point. (You're assuming the separate components can be added directly (or with fixed weights, say).)
I guess the cases where you can't add directly (or with fixed weights) involve genuine normative uncertainty or incommensurability. Or, maybe some cases of two envelopes problems where it's too difficult or unjustifiable to set a unique common scale and use the Bayesian solution.
In practice, I may have normative uncertainty about moral weights between species.
If you're risk neutral, probably. Maybe not if you're difference-making risk averse. Perhaps helping insects is robustly positive in expectation, but highly likely to have no impact at all. Then you might like a better chance of positive impact, while maintaining 0 (or low) probability of negative impact.
For my illustration, that's right.
However, my illustration treats the components as independent, so that you can get the worst case on each of them together. But this need not be the case in practice. You could in principle have interventions A and B, both with ranges of (expected) cost-effectiveness [-1, 2], but whose sum is exactly 1. Let the cost-effectiveness of B be 1-"the cost-effectiveness of A". Having things cancel out so exactly and ending up with a range that's a single value is unrealistic, but I wonder if we could at least get a positive range this way.
Ya, the default doesn't seem privileged if you're a consequentialist. See this post.
Hi Michael.
Effects along different dimensions can be added under expectational total hedonistic utilitarianism, precise credences, and moral realism?
I think not, due to gradations and multiple reference points (even within hedonic scales only).