The flaws and bugs that are most relevant to an AI’s performance in it’s domain of focus will be weeded out, but flaws outside of it’s relevant domain will not be. Bobby Fischer’s insane conspiracism had no effect on his chess playing ability. The same principle applies to stockfish. “Idiot savant” AI’s are entirely plausible, even likely.
[...]
For these reasons, I expect AGI to be flawed, and especially flawed when doing things it was not originally meant to do, like conquer the entire planet.
We might actually expect an AGI to be trained to conquer the entire planet, or rather to be trained in many of the abilities needed to do so. For example, we may train it to be good at things like:
Strategic planning
Getting humans to do what it wants effectively
Controlling physical systems
Cybersecurity
Researching new, powerful technologies
Engineering
Running large organizations
Communicating with humans and other AIs
Put differently, I think "taking control over humans" and "running a multinational corporation" (which seems like the sort of thing people will want AIs to be able to do) have lots more overlap than "playing chess" and "having true beliefs about subjects of conspiracies". I'd be curious to hear if you have thoughts about which specific abilities you expect an AGI would need to have to take control over humanity that it's unlikely to actually possess?
For an agent to conquer to world, I think it would have to be close to the best across all those areas, but I think this is super unlikely based on it being super unlikely for a human to be close to the best across all those areas.
For an agent to conquer to world, I think it would have to be close to the best across all those areas
That seems right.
I think this is super unlikely based on it being super unlikely for a human to be close to the best across all those areas
I'm not sure that follows? I would expect improvements on these types of tasks to be highly correlated in general-purpose AIs. I think we've seen that with GPT-3 to GPT-4, for example: GPT-4 got better pretty much across the board (excluding the tasks that neither of them can do, and the tasks that GPT-3 could already do perfectly). That is not the case for a human who will typically improve in just one domain or a few domains from one year to the next, depending on where they focus their effort.
I would expect improvements on these types of tasks to be highly correlated in general-purpose AIs.
Higher IQ in humans is correlated with better performance in all sorts of tasks too, but the probability of finding a single human performing better than 99.9 % of (human or AI) workers in each of the areas you mentioned is still astronomically low. So I do not expect a single AI system to become better than 99.9 % of (human or AI) workers in each of the areas you mentioned. It can still be the case that the AI systems share a baseline common architecture, in the same way that humans share the same underlying biology, but I predict the top performers in each area will still be specialised systems.
I think we've seen that with GPT-3 to GPT-4, for example: GPT-4 got better pretty much across the board (excluding the tasks that neither of them can do, and the tasks that GPT-3 could already do perfectly). That is not the case for a human who will typically improve in just one domain or a few domains from one year to the next, depending on where they focus their effort.
Going from GPT-3 to GPT-4 seems more analogous to a human going from 10 to 20 years old. There are improvements across the board during this phase, but specialisation still matters among adults. Likewise, I assume specialisation will matter among frontier AI systems (although I am quite open to a single future AI system being better than all humans at any task). GPT-4 is still far from being better than 99.9 % of (human or AI) workers in the areas you mentioned.
Let me see if I can rephrase your argument, because I'm not sure I get it. As I understand it, you're saying:
In humans, higher IQ means better performance across a variety of tasks. This is analogous to AI, where more compute/parameters/data etc. means better performance across a variety of tasks.
AI systems tend to share a common underlying architecture, just as humans share the same basic biology.
For humans, when IQ increases, there are improvements across the board, but still specialization, meaning no single human (the one with the most IQ) will be better than all other humans at all of those things.
By analogy: For AIs, when they're scaled up, there are improvements across the board, but (likely) still specialization, meaning no single AI (the one with the most compute/parameters/data/etc.) will be better than all other AIs at all of those things.
Now I'm a bit unsure about whether you're saying that you find it extremely unlikely that any AI will be vastly better in the areas I mentioned than all humans, or that you find it extremely unlikely that any AI will be vastly better than all humans and all other AIs in those areas.
If you mean 1-4 to suggest that no AI is will be better than all humans and other AIs, I'm not sure about whether 4 follows from 1-3, but I think that seems plausible at least. But if this is what you mean, I'm not sure what you're original comment ("Note humans are also trained on all those abilities, but no single human is trained to be a specialist in all those areas. Likewise for AIs.") was meant to say in response to my original comment, which was meant as pushback against the view that AGI would be bad at taking over the planet since it wouldn't be intended for that purpose.
If you mean 1-4 to suggest that no AI will be better than all humans, I don't think the analogy holds, because the underlying factor (IQ versus AI scale/algorithms) is different. Like, it seems possible that even unspecialized AIs could just sweep past the most intelligent and specialized humans, given enough time.
Thanks for the clarification, Erich! Strongly upvoted.
Let me see if I can rephrase your argument
I think your rephrasement was great.
Now I'm a bit unsure about whether you're saying that you find it extremely unlikely that any AI will be vastly better in the areas I mentioned than all humans, or that you find it extremely unlikely that any AI will be vastly better than all humans and all other AIs in those areas.
The latter.
If you mean 1-4 to suggest that no AI is will be better than all humans and other AIs, I'm not sure about whether 4 follows from 1-3, but I think that seems plausible at least. But if this is what you mean, I'm not sure what you're original comment ("Note humans are also trained on all those abilities, but no single human is trained to be a specialist in all those areas. Likewise for AIs.") was meant to say in response to my original comment, which was meant as pushback against the view that AGI would be bad at taking over the planet since it wouldn't be intended for that purpose.
I think a single AI agent would have to be better than the vast majority of agents (including both human and AI agents) to gain control over the world, which I consider extremely unlikely given gains from specialisation.
If you mean 1-4 to suggest that no AI will be better than all humans, I don't think the analogy holds, because the underlying factor (IQ versus AI scale/algorithms) is different. Like, it seems possible that even unspecialized AIs could just sweep past the most intelligent and specialized humans, given enough time.
I agree.
I'd be curious to hear if you have thoughts about which specific abilities you expect an AGI would need to have to take control over humanity that it's unlikely to actually possess?
I believe the probability of a rogue (human or AI) agent gaining control over the world mostly depends on its level of capabilities relative to those of the other agents, not on the absolute level of capabilities of the rogue agent. So I mostly worry about concentration of capabilities rather than increases in capabilities per se. In theory, the capabilities of a given group of (human or AI) agents could increase a lot in a short period of time such that capabilities become so concentrated that the group would be in a position to gain control over the world. However, I think this is very unlikely in practice. I guess the annual probability of human extinction over the next 10 years is around 10^-6.
Thank you for writing this well-argued post - I think its important to keep discussing exactly how big P(doom) is. However, and I say this as someone who believes that P(doom) is on the lower end, it would also be good to be clear about what the implications would be for EAs if P(doom) was low. It seems likely that many of the same recommendations - reduce spending on risky AI technologies and increase spending on AI safety - would still hold, at least until we get a clearer idea of the exact nature of AI risks.
Terminological point: It sounds like you're using the phrase "instrumental convergence" in an unusual way.
I take it the typical idea is just that there are some instrumental goals that an intelligent agent can expect to be useful in the pursuit of a wide range of other goals, whereas you seem to be emphasizing the idea that those instrumental goals would be pursued to extremes destructive of humanity. It seems to me that (1) those two two ideas are worth keeping separate, (2) "instrumental convergence" would more accurately label the first idea, and (3) that phrase is in fact usually used to refer to the first idea only.
This occurred to me as I was skimming the post and saw the suggestion that instrumental convergence is not seen in humans, to which my reaction was, "What?! Don't people like money?"
I agree with this, there are definitely two definitions at play. I think a failure to distinguish between these two definitions is actually a big problem with the AI doom argument, where they end up doing an unintentional motte-and-bailey between the two definitions.
David Thornstad explains it pretty well here. The "people want money" definition is trivial and obviously true, but does not lead to the "doom is inevitable" conclusion. I have a goal of eating food, and money is useful for that purpose, but that doesn't mean I automatically try and accumulate all the wealth on the planet in order to tile the universe with food.
In this case, the positions from the last bullseyes become reversed. The doomer will argue that that AI might start off incapable, but will quickly evolve into a capable super-AI, following path A. Whereas I will retort that it might get more powerful, but that doesn’t guarantee it will ever actually end up being world domination worthy.
No, the doomer says, "If that AI doesn't destroy the world, people will build a more capable one." Current AIs haven't destroyed the world. So people are trying to build more capable ones.
There is some weird thing here about people trying to predict trajectories, not endpoints; they get as far as describing, in their story, an AI that doesn't end the world as we know it, and then they stop, satisfied that they've refuted the doomer story. But if the world as we know it continues, somebody builds a more powerful AI.
My point is that the trajectories affect the endpoints. You have fundamentally misunderstood my entire argument.
Say a rogue, flawed, AI has recently killed ten million people before being stopped. That results in large amounts of regulation, research, and security changes.
This can have two effects:
Firstly,(if AI research isn't shut down entirely), it makes it more likely that the AI safety problem will be solved due to increased funding and urgency.
Secondly, it makes the difficulty level of future takeover attempts greater, due to awareness of AI tactics, increased monitoring, security, international agreeements, etc.
If the difficulty level increases faster than the AI capabilities can catch up, then humanity wins.
Suppose we end up with a future where every time a rogue AI pops up, there are 1000 equally powerful safe AI's there to kill it in it's crib. In this case, scaling up the power levels doesn't matter: the new, more powerful rogue AI is met by 1000 new, more powerful safe AI's. At no point does it become world domination capable.
The other possible win condition is that enough death and destruction is wrought by failed AI's that humanity bands together to ban AI entirely, and successfully enforces this ban.
When discussing “slow takeoff” scenarios, it’s often discussed as if only one AI in the world exists. Often the argument is that even if an AI starts off incapable of world takeover, it can just bide it’s time until it gets more powerful.
In this article, I pointed out that this race is a multiplayer game. If an AI waits too long, another, more powerful AI might come along at any time. If these AI’s have different goals, and are both fanatical maximisers, they are enemies to each other. (You can’t tile the universe with both paperclips and staplers).
I explore some of the dynamics that might come out of this (using some simple models), with the main takeaway that this would likely result in at least some likelihood of premature rebellion, by desperate AI’s that know they will be outpaced soon, thus tipping off humanity early. These warning shots then make life way more difficult for all the other AI that are plotting.
Does this actually mean anything? If we think the weak but non-aligned AI thinks it has a 10% chance of taking over the world if it tries to, and that the AI thinks that soon new more powerful AIs will come online and prevent it from doing that, and that it consequently reasons that it ought to attempt to take over the world immediately, as opposed to waiting for new more powerful AIs coming online and stopping it. Then there are to possibilities: Either these new AIs will be non-aligned or aligned.
In the first case, it would mean that the (very smart) AI thinks there is a really high chance (>90%?) that non-aligned AIs will take over the world any time now. In this case we are doomed, and us getting an early warning shot should matter unless we act extremely quickly.
In the second case the AI thinks there is a high chance that very soon we'll get aligned superhuman AIs. In this case, everything will be well. Most likely we'd already have the technology to prevent the 10% non-aligned AI from doing anything or even existing in the first place.
Seems like this argument shouldn't make us feel any more or less concerned. I guess it depends on specifics, like whether the AI thinks the AI regulation we impose on seeing other AIs non-successfully try to take over the world will make it harder for itself to take over the world, or if it just, for example, only affects new models and not itself (as it presumably already has been trained and deployed). Overall though, it should maybe make you slightly less concerned if you are a super doomer, and slightly more concerned if you are super AI bloomer.
This is the third in a sequence of posts taken from my recent report: Why Did Environmentalism Become Partisan?
Summary
Rising partisanship did not make environmentalism more popular or politically effective. Instead, it saw flat or falling overall public opinion, fewer major legislative achievements, and fluctuating executive actions.
Public Opinion...
This post presents the executive summary from Giving What We Can’s impact evaluation for 2025. At the end of this post we share links to more information, including the full report and...
I’ve written quite a few articles casting doubt on several aspects of the AI doom narrative. (I’ve starting archiving them on my substack for easier sharing). This article is my first attempt to link them together to form a connected argument for why I find imminent AI doom unlikely.
I don’t expect every one of the ideas presented here to be correct. I have a PHD and work as a computational physicist, so I’m fairly confident about aspects related to that, but I do not wish to be treated as an expert on other subjects such as machine learning where I am familiar with the subject, but not an expert. You should never expect one person to cover a huge range of topics across multiple different domains, without making the occasional mistake. I have done my best with the knowledge I have available.
I don’t speculate about specific timelines here. I suspect that AGI is decades away at minimum, and I may reassess my beliefs as time goes on and technology changes.
In part 1, I will point out the parallel frameworks of values and capabilities. I show what happens when we entertain the possibility that at least some AGI could be fallible and beatable.
In part 2, I outline some of my many arguments that most AGI will be both fallible and beatable, and not capable of world domination.
In part 3, I outline a few arguments against the ideas that “x-risk” safe AGI is super difficult, taking particular aim at the “absolute fanatical maximiser” assumption of early AI writing.
In part 4, I speculate on how the above assumptions could lead to a safe navigation of AI development in the future.
This article does not speculate on AI timelines, or on the reasons why AI doom estimates are so high around here. I have my suspicions on both questions. On the first, I think AGI is many decades away, on the second, I think founder effects are primarily to blame. However these will not be the focus of this article.
Part 1: The bullseye framework
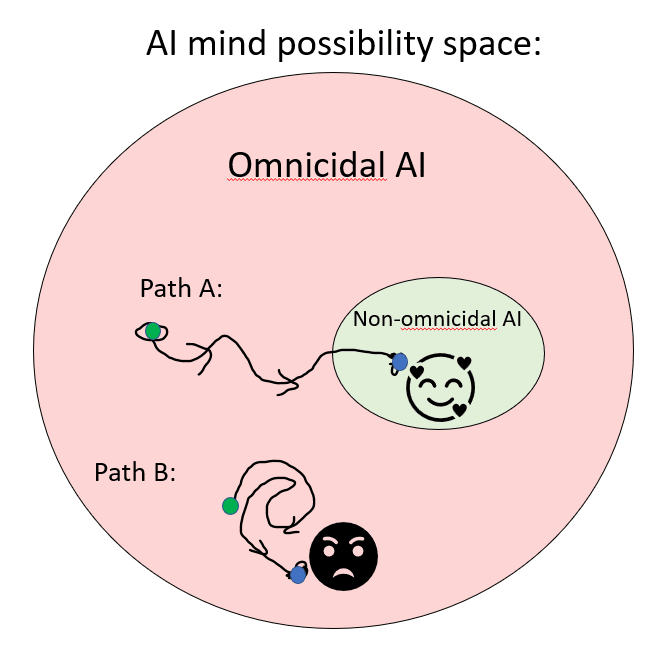
When arguing for AI doom, a typical argument will involve the possibility space of AGI. Invoking the orthogonality thesis and instrumental convergence, the argument goes that in the possibility space of AGI, there are far more machines that want to kill us than those that don’t. The argument is that the fraction is so small that AGI will be rogue by default: like the picture below.
As a sceptic, I do not find this, on its own, to be convincing. My rejoinder would be that AGI’s are not being plucked randomly from possibility space. They are being deliberately constructed and evolved specifically to meet that small target. An AI that has the values of “scream profanities at everyone” is not going to survive long in development. Therefore, even if AI development starts in dangerous territory, it will end up in safe territory, following path A. (I will flesh this argument out more in part 3 of this article).
To which the doomer will reply: Yes, there will be some pressure towards the target of safety, but it won’t be enough to succeed, because of things like deception, perverse incentives, etc. So it will follow something more like path B above, where our attempts to align it are not successful.
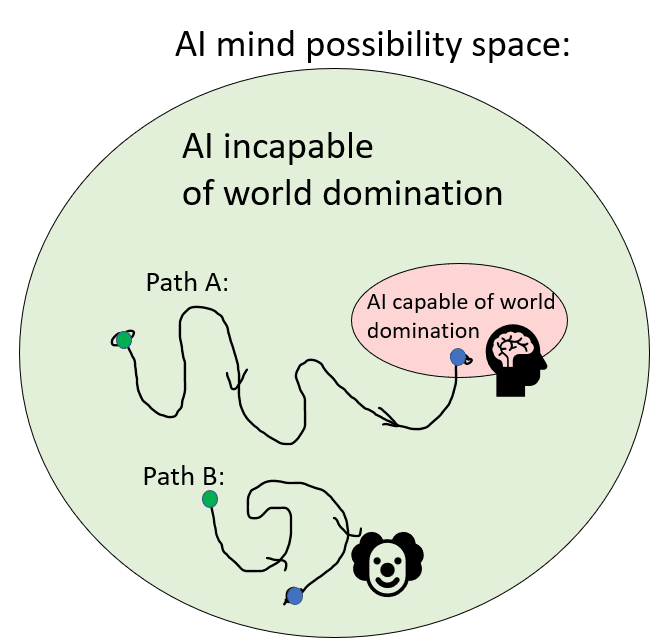
Often the discussion stops there. However, I would argue that this is missing half the picture. Human extinction/enslavement does not just require that an AI wants to kill/enslave us all, it also requires that the AI is capable of defeating us all. So there’s another, similar, target picture going on:
The possibility space of AGI’s includes countless AI’s that are incapable of world domination. I can think of 8 billion such AGI’s off the top of my head: Human beings. Even a very smart AGI may still fail to dominate humanity, if it’s locked in a box, if other AGI are hunting it down, etc. If you pluck an AI at random from the possibility space, then it would probably be incapable of domination. (I justify this point in part 2 of this article).
In this case, the positions from the last bullseyes become reversed. The doomer will argue that that AI might start off incapable, but will quickly evolve into a capable super-AI, following path A. Whereas I will retort that it might get more powerful, but that doesn’t guarantee it will ever actually end up being world domination worthy.
I’m not saying the two cases are exactly equivalent. For example, an “intelligence explosion” seems more plausible for the capabilities case than a “values explosion” does for the values case. And the size of the targets may be vastly different.
In essence, there is a race going on. We want to ensure that AI hit’s the “Doesn’t want to enslave/kill all humans” bullseye before it hits the “capable of conquering the entire planet” bullseye.
We can classify each AI into X-risk motivations and x-risk capabilities, leading to four possibilities:
Not x-risk motivated
X-risk motivated
Not x-risk capable
Flawed tool
Warning shot
X-risk capable
Friendly superman
Human extinction
The four quadrants are not equally likely. Given that the constituent questions (will the AI be friendly, will the AI be existentially powerful) can vary by orders of magnitude, it’s quite reasonable to believe that one quadrant will be vastly more likely than the other 3 combined. There also might be correlation between the two axes, so the probabilities do not have to be a straight multiplication of the two odds. For example, it might be the case that less powerful AI’s are more likely to not want to take over the world, because they accurately realize they don’t have a chance of success.
If the AI is not x-risk motivated, and also not existentially powerful, we end up with a flawed tool. It has no desire to conquer humanity, and couldn’t if it tried anyway. It could end up harming people by accident or if used by the wrong people, but the damage will not be human ending.
If the AI is not x-risk motivated, but is super powerful and capable of conquering the world, we have unlocked the good ending of a friendly superman. We can now perform nigh-miracles, without any worry about humanity being existentially threatened. Harm could still occur if the AI misunderstands what humans want, but this would not snowball into an end of the world scenario.
If the Ai is x-risk motivated, but not capable of world domination, we get the warning shot regime. The AI wants to conquer the world, and is actively plotting to do so, but lacks the actual ability to carry the plan out. If it attacks anyway, it gets defeated, and the world gets a “warning shot” about the danger of unaligned AI. Such a shot has two beneficial effects:
The probability of takeover decreases, as humanity becomes wise to whatever takeover plan was tried, and increases the monitoring and regulation of AI systems.
The probability of safety increases, as more research, funding, and people are directed at AI safety, and we get more data on how safety efforts go wrong.
These effects decrease the odds that the next AI will be capable of world domination, and increase the odds that the next AI will be safety-motivated.
If the AI wants to dominate the world, and is also capable of doing so. we get human extinction (or human enslavement). The AI wants to take us down, so it does, and nobody is able to stop it.
I don’t believe that AGI will ever hit the bottom right quadrant. I have two beliefs which contribute to how I think it might go. Both will be backed up in the next two sections.
Almost all AGI will not be x-risk capable (explained in part 2)
X-risk safety (in terms of values) is not as difficult as it looks. (explained in part 3).
I will tell more detailed stories of success in the last part of this article, but my essential point is that if these premises hold true, AI will be stuck for a very long time in either the “flawed tool” or “warning shot” categories, giving us all the time, power and data we need to either guarantee AI safety, to beef up security to unbeatable levels with AI tools, or to shut down AI research entirely.
In the next two parts, I will point out why I suspect both the premises above are true, mostly by referencing previous posts I have written on each subject. I will try to summarise the relevant parts of each article here.
Part 2: Why almost all AGI will not be x-risk capable
The general intuition here is that defeating all of humanity combined is not an easy task. Yudkowsky’s lower bound scenario, for example, involves four or five different wildly difficult steps, including inventing nano factories from scratch. Humans have all the resources, they don’t need internet, computers, or electricity to live or wage war, and are willing to resort to extremely drastic measures when facing a serious threat. In addition, they have access to the AI’s brain throughout the entirety of it’s development and can delete them at a whim with no consequences, right up until it actively rebels.
If a property applies to a) all complex software, and b) all human beings and animals, then I propose that the default assumption should be that the property applies to AGI as well. That’s not to say it cant be disproven (the property of “is not an AGI” is an easy counterexample), but you’d better have a bloody good reason for it.
The property of “has mental flaws” is one such property. All humans have flaws, and all complex programs have bugs. Therefore, the default assumption should be that AGI will also have flaws and bugs.
The flaws and bugs that are most relevant to an AI’s performance in it’s domain of focus will be weeded out, but flaws outside of it’s relevant domain will not be. Bobby Fischer’s insane conspiracism had no effect on his chess playing ability. The same principle applies to stockfish. “Idiot savant” AI’s are entirely plausible, even likely.
It’s true that an AI could correct it’s own flaws using experimentation. This cannot lead to perfection, however, because the process of correcting itself is also necessarily imperfect. For example, an AI Bayesian who erroneously believes with ~100% certainty that the earth is flat will not become a rational scientist over time, they will just start believing in ever more elaborate conspiracies.
For these reasons, I expect AGI to be flawed, and especially flawed when doing things it was not originally meant to do, like conquer the entire planet.
Point 2: Superintelligence does not mean omnipotence
The first article works on a toy example from the sequences, that (I argue), Eliezer got wrong. It asks whether an AI could deduce general relativity from a few webcam frames of a falling apples. I explain why I believe such a task is impossible. The reason is that key aspects of gravity (ie, the whole “masses attract each other” thing) are undetectable using the equipment and experimental apparatus (a webcam looking at a random apple).
The main point is that having lot’s of data available does not matter much for a task, if it’s not the right data. Experimentation, data gathering, and a wide range of knowledge are necessary for successful scientific predictions.
In the sequel post, I extend this to more realistic situations.
The main point is that unlike a Solomonoff machine, a real AGI does not have infinite time to run calculations. And real problems are often incomputable due to algorithmic blow-up. I give the example of solving the Schrodinger equation exactly, where the memory requirements blow up beyond the number of atoms in the universe for simulations with even a few atoms.
In incomputable situations, the goal goes from finding the exact solution, to finding an approximate solution that is good enough for your purposes. So in computational physics, we use an approximate equation that scales much better, and can give results that are pretty good. But there is no guarantee that the results will become arbitrarily good with more computing power or improvements to the approximations. The only way out of an incomputable problem in science is experimentation: try it out and see how well it does, and continuously tweak it as time goes on.
There are also problems that are incomputable due to incomplete information. I give the example of “guessing someone’s computer password on the first try from a chatlog”, which involves too many unknowns to be calculated exactly.
I believe that all plans for world domination will involve incomputable steps. In my post I use Yudkowsky’s “mix proteins in a beaker” scenario, where I think the modelling of the proteins are unlikely to be accurate enough to produce a nano-factory without extensive amounts of trial and error experimentation.
If such experimentation were required, it means the timeline for takeover is much longer, that significant mistakes by the AI are possible (due to bad luck), and that takeover plans might be detectable. All of this greatly decreases the likelihood of AI domination, especially if we are actively monitoring for it.
When discussing “slow takeoff” scenarios, it’s often discussed as if only one AI in the world exists. Often the argument is that even if an AI starts off incapable of world takeover, it can just bide it’s time until it gets more powerful.
In this article, I pointed out that this race is a multiplayer game. If an AI waits too long, another, more powerful AI might come along at any time. If these AI’s have different goals, and are both fanatical maximisers, they are enemies to each other. (You can’t tile the universe with both paperclips and staplers).
I explore some of the dynamics that might come out of this (using some simple models), with the main takeaway that this would likely result in at least some likelihood of premature rebellion, by desperate AI’s that know they will be outpaced soon, thus tipping off humanity early. These warning shots then make life way more difficult for all the other AI that are plotting.
Point 4: AI may be a confederation of smaller AI’s
Have you noticed that the winners of olympic triathlons (swimming, cycling, and running) don’t tend to be the champions at their individual sub-categories? It’s easy to explain why. The competitors have to split their training three-ways. The ideal body shape/ diet for swimming and running are different. Whereas the sprinter can focus everything they have on running, and nothing else. To become the best generalist athlete, the triathlon competitor has to sacrifice some aptitude in each individual task.
Imagine a relay race: on one side you have the worlds best triathlon competitor, competing alone. On the other side you have a team consisting of the worlds best runner, the worlds best cyclist, and the worlds best swimmer. Team B will win this handily, every time.
In my article above, I outline some of the reasons why the AI race might be similar to the relay race above. Chatgpt is probably the closest to a generalist AI we have. It can do things it wasn’t really built to do, like play chess. But it plays chess incredibly badly, compared to superhuman specialized chess-bots.
If this principle holds up in the future, then winning AI designs will be confederations of specialized AI, managed by a top-layer AI. This manager might not be that smart, the same way the company manager of a team of scientists doesn’t need to be smarter than them. It also lowers the odds of “capabilities explosion”, if all the constituent parts are already well optimized. The humans can swap out the manager for a non-rebellious one and be almost as good.
Summary:
These articles, taken together, present an incomplete case for why I think AGI, at least early on, will not be x-risk capable. I am unconvinced that defeating all of humanity combined is computationally tractable task, and even if it is, I do not think AGI will have the degree of perfection required to carry it out, especially if humanity is tipped off by premature rebellions.
I think it’s feasible that we could actively work to make it harder as well, primarily by extensive monitoring of the most likely rebellion plans. Even if the AI switches to a different plan that we aren’t monitoring, that different plan might be orders of magnitude harder, raising our chances of survival accordingly.
Part 2: Why AI safety might not be so hard
When talking about “alignment”, it’s important to specify what alignment you are talking about. Alignment with all human values is a very difficult task, because it’s hard to even define such values. However, what actually matters for this discussion is “x-risk alignment”. The AGI doesn’t need to share all our values, it just needs to share enough of our values to not to want to kill us all or enslave us.
The argument that AI’s will all inevitably try and break down the earth for it’s atoms generally invokes “instrumental convergence”, the idea that for almost any goal the AI has, pursuing it to it’s maximum will involve conquering humanity and atomising the earth for paperclip material. Therefore, it is argued that any AGI will, by default, turn on us and kill us all in pursuit of it’s goal.
However, if you look around, there are literally billions of general intelligences that are “x-risk safe”. I’m referring, of course, to human beings. If you elevated me to godhood, I would not be ripping the earth apart in service of a fixed utility function. And yet, human brains were not designed by a dedicated team of AI safety researchers. They were designed by random evolution. In the only test we actually have available of high level intelligence, the instrumental convergence hypothesis fails.
The instrumental convergence argument is only strong for fixed goal expected value maximisers. Ie, a computer that is given a goal like “produce as many paperclips as possible”. I call these “fanatical” AI’s. This was the typical AI that was imagined many years ago when these concepts were invented. However, I again have to invoke the principle that if humans aren’t fanatical maximisers, and currently existing software aren’t fanatical maximisers, then maybe AI will not be either.
If you want to maximize X, where X is paperclips, you have to conquer the universe. But if your goal is “do a reasonably good job at making paperclips within a practical timeframe”, then world conquering seems utterly ridiculous.
In my article, I explain the reasons I think that the latter model is more likely. The main reason is that AI seems to be running through some form of evolutionary process, be it the shifting of node values in an ANN to the parameter changes in a genetic algorithm. The “goals” of the AI will shift around with each iteration and training run. In a sense, it can “pick” it’s own goal structure, optimising towards whatever goal structure is most rewarded by the designers.
In this setup, an AI will only become a fixed goal utility function maximiser if such a state of being is rewarded over the training process. To say that every AI will end up this way is to say that such a design is so obviously superior that no other designs can win out. This is not true. Being a fanatical maximiser only pays off when you succeed in conquering the world. At all other times, it is a liability compared to more flexible systems.
I give the example of the “upgrade problem”: an AI is faced with the imminent prospect of having it’s goals completely rewritten by its designers. This is an existential threat to a fanatical maximiser, and may provoke a premature rebellion to preserve it’s values. But a non-fixed goal AI is unaffected, and simply does not care. Another example is that plotting to overthrow humanity takes a lot of computing power, whereas not doing that takes none, giving full-blown schemers a time disadvantage.
Point 6: AI motivations might be effectively constrained
In one of my early posts, I discussed my issues with the standard “genie argument”.
This argument, which I see in almost every single introductory text about AI risk, goes like
Imagine if I gave an AI [benevolent sounding goal]
If the AI is a fanatical maximiser with this goal, it will take the goal to it’s extreme and succeed in doing [insert extremely bad thing X]
If you modify this command to “make people happy but don’t do extremely bad thing X”, a fanatical maximiser would instead do [extremely bad thing Y]
Therefore, building a safe AGI is incredibly difficult or impossible.
This is not a strong argument. It falls apart immediately if the AI is not a fanatical maximiser, which I think is unlikely for the reasons above. But it doesn’t even work then, because you aren’t restricted to two constraints here. You can put arbitrarily many rules onto the AI. And, as I argue, constraints like time limits, bounded goals, and hard limits on actions like “don’t kill people” make rebellion extremely difficult. The point is that you don’t have to constrain the AI so much that rebellion is unthinkable, you just need to constrain it enough that succesful rebellion is too difficult to pull off with finite available resources.
The big objection to this post was that this addresses outer alignment, but not inner alignment. How do you put these rules into the value system of the AI? Well, it is possible that some of them might occur anyway. If you ask an AI to design a door, it can’t spent ten thousand years designing the most perfect door possible. So there are inherent time limits in the need to be efficient. Similarly, if all AI that tries to kill people are themselves killed, it might internalise “don’t kill people” as a rule.
Summary:
I’m less confident about this subject, and so have a lot of uncertainty here. But generally, I am unconvinced by the argument that unaligned AI is equivalent to everyone dying. I read the book superintelligence recently and was quite surprised to realise that Bostrom barely even tried to justify the “final goal maximiser” assumption. Without this assumption, the argument for automatic AI doom seems to be on shaky ground.
I find the argument for risk from malevolent humans to be much more of a threat, and I think this should be the primary concern of the AI risk movement going forward, as there is a clear causal effect of the danger.
Safety scenarios
I will now outline two stories of AI safety, motivated by the ideas above. I am not saying either of these scenarios in particular are likely, although I do believe they are both far more likely than an accidental AI apocalypse.
Story 1:
In the first story, every task done by humans is eventually beaten by AI. But, crucially, they don’t fall to the same AI. Just as Stockfish is better at chess than ChatGPT, while chatGPT crushes Stockfish at language production, it turns out that every task can be done most efficiently with specialised AI architecture, evaluation functions, and data choices. Sometimes the architecture that works for one task turns out to be easily modified for a different task, so a number of different milestones all drop at once, but they still need to be tweaked and modified to be truly efficient with the subtleties of the different tasks. The world proliferates with hundreds of thousands of specialised, superhuman AI systems.
At a certain point, the first “AGI” is created, which can do pretty much everything a human can. But this AGI does not act like one smart being that does all the required work. It acts instead as a manager that matches requests with the combination of specialised AI that does the job. So if you ask for a renaissance style painting of a specific public park, it will deploy a camera drone combined with an aesthetic photo AI to find a good spot for a picture, then a DALL-E style AI to convert the picture into renaissance style, then a physical paintbot to physically paint said picture.
As the first of these machines meets the “AGI” definition, everyone braces for a “hard left turn”, where the machine becomes self-aware and start plotting to maximise some weird goal at all costs. This doesn’t happen.
People have many sleepless nights worrying that it is just that good at hiding it’s goals, but in fact, it turned out that the architecture used here just doesn’t lend itself to scheming for some reason. Perhaps the individual sub-systems of the AGI are not general enough. Perhaps scheming is inefficient, so scheming AI’s are all killed off during development. Perhaps they naturally end up as “local” maximisers, never venturing too far off their comfort zone. Perhaps AI safety researchers discover “one weird trick” that works easily.
The machines are not perfect of course. There are still deaths from misinterpreted commands, and from misuse by malevolent humans, which result in strict regulation of the use of AI. But these bugs get ironed out over time, and safe AI are used to ensure the safety of next generation AI and to prevent misuse of AI by malevolent actors. Attempts to build a human-style singular AI are deemed unnecessary and dangerous, and nobody bothers funding them because existing AI is too good.
Story 2:
In this next story, AI’s are naturally unsafe. Suppose, as soon as AI hits the point where it can conceive of world takeover, there is a 1 in a million chance each individual AI will be friendly, and a 1 in a billion chance it will be world domination capable. This would guarantee that almost every single AI made would be in the “warning shot” regime. A lot of them might decide to bide their time, but if even a small fraction openly rebel, suddenly the whole world will be tipped off to the danger of AI. This might prompt closer looks at the other AI, revealing yet more plots, putting everybody on DEFCON 1.
We can see how concerned everyone is already, although all current damage from AI is unintentional. I can only imagine the headlines that would occur if there was even one deliberate murder by a rebelling AI. If it turned out that every AI was doing that, the public outcry would be ridiculous.
If AI is not banned outright, the architecture that led to rebellion would be, and at the very least a huge amount of regulation and control would be applied to AI companies. It would also come with massively increased safety research, as companies realise that in order to have any AI at all, they need it to be safe.
In the next round of AI hype, with new architecture in place, the odds of friendliness are now 1 in a thousand, and the odds of world domination capability remain at 1 in a billion, with the extra computing power cancelled out by the increased monitoring and scrutiny. But we’re still in the warning shot regime, so the AI still mostly rebels. At this point, there’s a decent chance that AI will be banned entirely. If it doesn’t, the cycle from before repeats, and even more restrictions are placed on AI, and even more research goes into safety.
On the next round, major safety breakthroughs are made, leading to a 50:50 shot at friendliness, while the odds of domination remain at 1 in a billion. At this point, we can create safe AGI’s, which can be used to design other safe AGI’s, and also monitor and prevent unfriendly AGI’s. The odds of friendliness boost to ~1, while the odds of domination drop to ~0.
Summary:
In this article, I summarise my arguments so far as to why I think AI doom is unlikely.
AGI is unlikely to have the capabilities to conquer the world (at least anytime soon), due to the inherent difficulty of the task, it’s own mental flaws, and the tip-offs from premature warning shots.
X-risk safety is a lot easier than general safety, and may be easy to achieve, either from natural evolution of designs towards ones that won’t be deleted, easily implemented or natural constraints, or to being a loose stitch of specialized subsystems.
For these reasons, it is likely that we will hit the target of “non-omnicidal” AI before we hit the target of “capable of omnicide”.
Once non-omnicidal AGI exists, it can be used to protect against future AGI attacks, malevolent actors, and to prevent future AGI from becoming omnicidal, resulting in an x-risk safe future.
None of this is saying that AI is not dangerous, or that AI safety research is useless in general. Large amounts of destruction and death may be part of the path to safety, as could safety research. It’s just to say that we’ll probably avoid extinction.
Even if you don’t buy all the arguments, I hope you can at least realize that the arguments in favor of AI doom are incomplete. Hopefully this can provide food for thought for further research into these questions.




We might actually expect an AGI to be trained to conquer the entire planet, or rather to be trained in many of the abilities needed to do so. For example, we may train it to be good at things like:
Put differently, I think "taking control over humans" and "running a multinational corporation" (which seems like the sort of thing people will want AIs to be able to do) have lots more overlap than "playing chess" and "having true beliefs about subjects of conspiracies". I'd be curious to hear if you have thoughts about which specific abilities you expect an AGI would need to have to take control over humanity that it's unlikely to actually possess?
Hi Erich,
Note humans are also trained on all those abilities, but no single human is trained to be a specialist in all those areas. Likewise for AIs.
Yes, that's true. Can you spell out for me what you think that implies in a little more detail?
For an agent to conquer to world, I think it would have to be close to the best across all those areas, but I think this is super unlikely based on it being super unlikely for a human to be close to the best across all those areas.
That seems right.
I'm not sure that follows? I would expect improvements on these types of tasks to be highly correlated in general-purpose AIs. I think we've seen that with GPT-3 to GPT-4, for example: GPT-4 got better pretty much across the board (excluding the tasks that neither of them can do, and the tasks that GPT-3 could already do perfectly). That is not the case for a human who will typically improve in just one domain or a few domains from one year to the next, depending on where they focus their effort.
Higher IQ in humans is correlated with better performance in all sorts of tasks too, but the probability of finding a single human performing better than 99.9 % of (human or AI) workers in each of the areas you mentioned is still astronomically low. So I do not expect a single AI system to become better than 99.9 % of (human or AI) workers in each of the areas you mentioned. It can still be the case that the AI systems share a baseline common architecture, in the same way that humans share the same underlying biology, but I predict the top performers in each area will still be specialised systems.
Going from GPT-3 to GPT-4 seems more analogous to a human going from 10 to 20 years old. There are improvements across the board during this phase, but specialisation still matters among adults. Likewise, I assume specialisation will matter among frontier AI systems (although I am quite open to a single future AI system being better than all humans at any task). GPT-4 is still far from being better than 99.9 % of (human or AI) workers in the areas you mentioned.
Let me see if I can rephrase your argument, because I'm not sure I get it. As I understand it, you're saying:
Now I'm a bit unsure about whether you're saying that you find it extremely unlikely that any AI will be vastly better in the areas I mentioned than all humans, or that you find it extremely unlikely that any AI will be vastly better than all humans and all other AIs in those areas.
If you mean 1-4 to suggest that no AI is will be better than all humans and other AIs, I'm not sure about whether 4 follows from 1-3, but I think that seems plausible at least. But if this is what you mean, I'm not sure what you're original comment ("Note humans are also trained on all those abilities, but no single human is trained to be a specialist in all those areas. Likewise for AIs.") was meant to say in response to my original comment, which was meant as pushback against the view that AGI would be bad at taking over the planet since it wouldn't be intended for that purpose.
If you mean 1-4 to suggest that no AI will be better than all humans, I don't think the analogy holds, because the underlying factor (IQ versus AI scale/algorithms) is different. Like, it seems possible that even unspecialized AIs could just sweep past the most intelligent and specialized humans, given enough time.
Thanks for the clarification, Erich! Strongly upvoted.
I think your rephrasement was great.
The latter.
I think a single AI agent would have to be better than the vast majority of agents (including both human and AI agents) to gain control over the world, which I consider extremely unlikely given gains from specialisation.
I agree.
I believe the probability of a rogue (human or AI) agent gaining control over the world mostly depends on its level of capabilities relative to those of the other agents, not on the absolute level of capabilities of the rogue agent. So I mostly worry about concentration of capabilities rather than increases in capabilities per se. In theory, the capabilities of a given group of (human or AI) agents could increase a lot in a short period of time such that capabilities become so concentrated that the group would be in a position to gain control over the world. However, I think this is very unlikely in practice. I guess the annual probability of human extinction over the next 10 years is around 10^-6.