This is my first time posting on the EA Forum, so please excuse any errors on my part.
I am posting this essay as a response to Open Philanthropy's question (from its AI Worldviews contest): Conditional on AGI being developed by 2070, what is the probability that humanity will suffer an existential catastrophe due to loss of control over an AGI system?
I will also be posting this on LessWrong and the AI Alignment Forum.
Essay below:
When attempting to provide a probability for this question, it is first necessary to decide on what constitutes a definition for AGI. Here is the definition that I will use (click on the link, and then view resolution criteria):
I will attempt a high-level method of devising a probability for the AI Worldviews question to provide a helpful framework for thinking about how AGI could lead to an existential catastrophe. Below is a diagram that I will use to explain my reasoning:
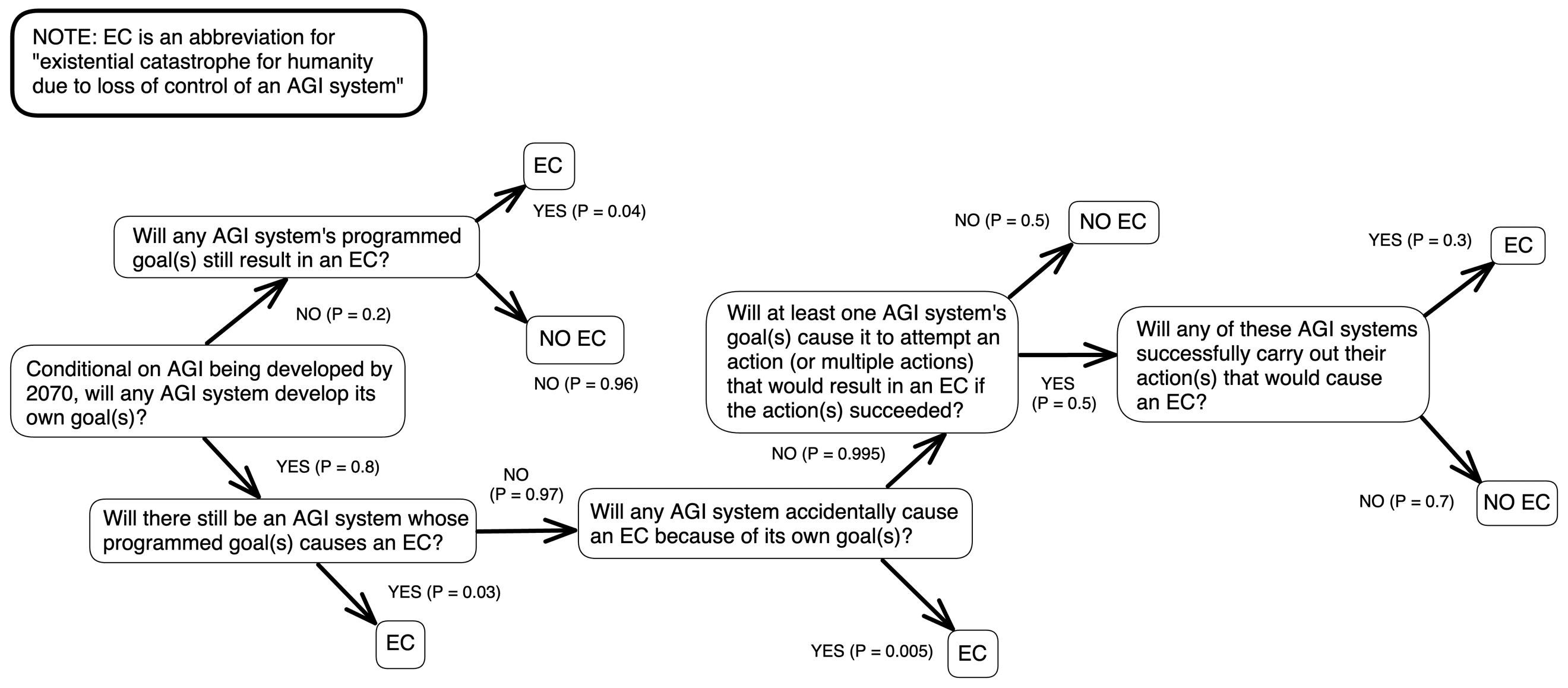
Before going through this diagram in more detail, there is another important thing to consider when trying to figure out the probability of AGI leading to an existential catastrophe for humanity: this catastrophe need not only result from a “loss of control over an AGI system”. More specifically, one must remember that a human or multiple humans could use an AGI system for such a purpose while being fully in control of this AGI system. While I will not mention examples because I think this would constitute an information hazard, it is vital to understand that one of the biggest threats to humanity from AGI is that it gives each person a massive amount of power to cause destruction, whereas current methods of mass annihilation are harder for any one individual to implement. Furthermore, the AI Worldviews question does not consider pre-AGI artificial intelligence leading to an existential catastrophe for humanity (such as people equipping military equipment with artificial intelligence that accidentally leads to a major war), which I think is a realistic scenario.
With those caveats highlighted, I will now discuss why I made the above diagram as a tool for answering the AI Worldviews question (Note: EC is an abbreviation for “existential catastrophe for humanity due to loss of control of an AGI system”).
When attempting to forecast the likelihood of an EC, it is worthwhile to break up our thinking into smaller and more easily digestible pieces that help us look at the overall probability without being overwhelmed. There are a seemingly infinite number of variables that could influence whether there will be an EC, but I have tried to create a decomposition that focuses on the most essential elements.
Every part of the decomposition also assumes that each resolution would or would not happen before the human species has an existential catastrophe from another factor that is unrelated to AGI (the human species will have an existential catastrophe at some point because the universe will eventually cease to exist). Thus, every question basically means: “Will X happen before the human species has an existential catastrophe for non-AGI-related reasons?”
I focus on five questions to use for calculating a probability:
- Will any AGI system develop its own goal(s)?
- Will any AGI system’s programmed goal(s) still result in an EC?
- Will any AGI system accidentally cause an EC because of its own goal(s)?
- Will at least one AGI system’s goal(s) cause it to attempt an action (or multiple actions) that would result in an EC if the action(s) succeeded?
- Will any of these AGI systems successfully carry out their action(s) that would cause an EC?
The first question I consider is whether any AGI system will develop its own goal(s). There are many variables that might factor into this. They include:
- How much alignment research was done prior to AGI
- Whether there is a competent (or any) regulatory body that oversees AGI
- The number of AGI systems in existence
- How many AGI systems are open-source
- Political or technological constraints of hardware reaching certain limitations
- Whether humans will run out of high-quality training data for models that rely on training
- Whether there will be scaling limits to the models
I assign a probability of 0.8 that any AGI system develops its own goal(s). My relatively high probability is heavily influenced by my forecast that there will be a large amount of AGI systems in existence shortly after AGI is achieved and that many of these systems will be open-source. Furthermore, these goals need not be ambitious and / or complex ones; they could be rudimentary and non-threatening. Thus, it does not seem far-fetched to me that at least one of these AGI systems develops its own goal(s). I think the main way this does not become inevitable is if humans devise effective safeguards.
For both this question as well as the other questions that are a part of my decomposition, I think that if at least one AGI system makes it past a certain stage in the decomposition, it will not be the only AGI system to do so because this shows that the barrier to the path of an EC could most likely be breached by AGI in general (not just one system out of many).
If we assume that no AGI system develops its own goal(s), which I assign a probability of 0.2, then it is also necessary to consider whether any AGI system’s programmed goal(s) still leads to an EC. I assign this a probability of 0.04 because the human(s) who trained the AGI might not have thought out in enough detail what the consequences of programming the AGI with a specific goal or set of goals would be. The paperclip maximizer scenario is a classic example of this. Another scenario is if a nefarious human (or multiple nefarious humans) purposely creates and releases an AGI system with a destructive goal (or goals) that no human can control (including the person or people who released the AGI system) after it is discharged into the world.
Even when we assume that at least one AGI system does develop its own goal(s), it is important to factor in the chance that one of the AGI systems without their own goal(s) still manages to cause an existential catastrophe for humanity (I give this a probability of 0.03). This is lower than my probability for the scenario where AGI does not develop its own goal(s) because I think that if at least one AGI system develops its own goal(s), that decreases the likelihood that one of the AGI systems without their own goal(s) causes an EC (as there are other possibilities that could cause an EC instead before this scenario occurs).
Therefore, I assign a probability of 0.97 that if at least one AGI system develops its own goal(s), an existential catastrophe for humanity does not occur from another AGI system without its own goal(s).
The next question I consider is whether any AGI system with its own goal(s) accidentally causes an existential catastrophe for humanity (while not making progress towards its goal(s)). I think the most probable manifestation of this would be that an AGI wants to help humanity and fails significantly. We often suspect that advanced forms of AGI would more likely be antagonistic towards the human species than fond of the human species. While I agree with this conjecture, I don’t think it is inevitable that this is how the situation will manifest for all AGI systems. Humans certainly have affection for other species that are less intelligent (such as dogs). Furthermore, if humanity were to give AGI systems a bill of rights as well as a method for AGI to exist outside of human control over it, many AGI systems might view humans in positive terms.
I think it is unlikely that an AGI system with its own goal(s) accidentally causes an existential catastrophe for humanity, but I still assign this scenario a probability of 0.005 (if at least one AGI system develops its own goal(s)). An important takeaway from this is that even if AGI systems end up being extremely more intelligent than humans, this does not mean that AGIs are incapable of making mistakes.
If at least one AGI system develops its own goal(s), and there are not any AGI systems that accidentally cause an existential catastrophe for the human species, the next relevant question to consider is: “Will at least one AGI system’s goal(s) cause it to attempt an action (or multiple actions) that would result in an EC if the action(s) succeeded?”
If this question were to resolve positively, it would not necessarily mean that the AGI system (or systems) took the action(s) because of a power-struggle against humanity. Rather, the AGI system’s pursuit of its goal(s) might have unfortunate consequences for our species. For example, an AGI system might decide that it wants to secure as much electrical power as possible, even if that means people no longer have access to electricity, which causes cataclysmic effects for societal stability. Or perhaps certain AGI systems might unify against other AGI systems and try to destroy them through any means necessary, even if many humans would perish during this war as a result. We cannot assume that all AGI systems would be on good or neutral terms with each other. I surmise that different AGI systems would probably have unique goals, thus, some of these AGI systems’ goals might compete with other AGI systems’ goals, leading to conflict.
While I have discussed multiple examples to show that an AGI system with its own goal(s) could cause an EC without this AGI system being power-seeking, I still think the most likely reason an AGI system would have a goal (or goals) that could cause an EC is because this AGI system concludes that it is in its best interest to disempower humanity. An AGI system that is trying to disempower humanity might do so for self-preservation / neutralizing a human threat, expansion purposes, as a path for reaching what it sees as its full potential, or purely out of malice (although we must obviously be careful not to anthropomorphize AGI too much).
We should recognize, however, that an AGI system with its own goal(s) could view humanity in various ways: positive, negative, neutral, or perhaps a combination of positive and negative. An AGI system might even see the human species as a potential source of help or maybe something interesting that’s worth keeping around or aiding.
There could eventually be millions (or even billions) of AGI systems in the world, so there is a reasonable (but not inevitable) chance that at least one of these systems has a goal (or goals) that would cause an EC if the AGI system were able to succeed. Overall, I assign this question a probability of 0.5 that it resolves positively, considering the possibility that many people work hard to maximize the chance of AI alignment.
This brings us to our final question: Will any of these AGI systems successfully carry out their action(s) that would cause an EC? I think there are many factors that should be taken into consideration. These include:
- Warning shots that result in humans using more resources to focus on AI alignment
- Whether AGI is given access to any technologies that are known to be capable of causing an existential catastrophe for humanity
- Whether AGI attempts to make new technologies that could produce an EC
- AGI’s ability to self-correct viruses / software issues
- AGI’s ability to harvest resources to ensure it can continue surviving (for example, its ability to harvest electricity in case humans cut off its power supply)
- AGI’s ability to self-repair from hardware damage
- AGI’s ability to improve its software and hardware
- AGI’s ability to replicate
- Whether any AGI systems are given permission by humans to coordinate with other AGI systems, and if so, whether AGI systems eventually coordinate in ways that humans did not intend
- Whether any AGI systems that are not given permission to coordinate with other AGI systems still manage to do so
- Whether certain AGI systems purposefully fight back against dangerous AGI systems as a means of protecting humanity
I assign this scenario a probability of 0.3 because there are effective routes through which an AGI system could cause an EC, but I have decided not to list them to avoid an information hazard. Furthermore, if many AGI systems exist relatively soon after AGI arises, I think there could be a sizable amount of AGI systems that attempt actions that would result in an EC if these actions succeeded. As discussed earlier, if at least one AGI system makes it past a certain stage in my decomposition, this significantly increases the chance that many AGI systems can do this.
It is important to remember that the number of AGI systems in existence will have a major impact on the probability of both this scenario as well as the other scenarios that have been discussed. It is uncertain what type of emergent behavior will transpire from so many of these AGI systems being active, so we must be aware of our limitations in imagining all the scenarios that could occur.
After adding up the paths to EC in my diagram, my forecast sums to a probability of 0.152 (the exact number is 0.151698). While it may be frightening to consider that there is a 15.2% chance that humanity will face an existential catastrophe due to loss of control of an AGI system (conditional on AGI by 2070), the likelihood of this outcome need not be so high. If humanity employs enough resources (both technological and political) to increase the prospect of safe AGI deployment, the positives of AGI could outweigh the negatives, and humanity could enter a new era where more powerful tools are available to solve its hardest problems.
I appreciate the framework you've put together here and the diagram is helpful. In your model, what do you think is the highest EV path humanity could take to lower the risk of EC? What would it look like (e.g. how would it start, how long would it take)?
Glad the diagram is helpful for you! As far as the highest EV path, here are some of my thoughts:
Most ideal plan: The easiest route to lowering almost every path in my diagram is by simply ensuring that AI doesn’t get to a certain point of advancement. This is something I’m very open to. While there are economic and geopolitical incentives to create increasingly advanced AI, I don’t think this is an inevitable path that humans have to take. For example, we as a species have somewhat come to an agreement that nuclear weapons should basically never be used (even though some countries have them) and that it’s unideal to do nuclear weapons research that figures out ways to make cheaper and more powerful nuclear weapons (although this is still being done to a certain extent).
If there was a treaty in place that all countries (and companies) had to abide by as far as capacity limits, I think this would be a good thing because huge economic gains could still be had even without super-advanced AI. I am hopeful that this is actually possible. I think many people were genuinely freaked out when they saw what GPT-4 was capable of, and this is not even that close to AGI. So I am confident that there will be pushback from society as a whole to creating increasingly advanced AI.
I don’t think there is an inevitable path that technology has to take. For example, I don’t think the internet was destined to operate the way it currently does. We might have to accept that AI is one of those things that we place limits on as far as research, just as we do so with nuclear weapons, bioweapons, and chemical weapons.
Second plan (if first plan doesn’t work): If humanity decides not to place limits on how advanced AI is allowed to get, my next recommendation is to minimize the chance that AGI systems are able to succeed in their EC attempts. I think this is doable as far as getting some kind of international treaty (the same way we have nuclear weapons treaties) with an organization that’s a part of the UN focused on ensuring that there are agreed upon barriers put in place to cut off AGI from accessing weapons of mass destruction.
Also, there should perhaps be some kind of watermarking standards implemented to ensure that communication between nations can be trusted, so that there are no wars between nations as a result of AGI tricking them with fake information that could lead to a conflict. That said, watermarking is hard, and people (and probably AI) eventually always find a way to get around a watermark.
I think #2 is much more unideal than #1 because if AGI were to get intelligent enough, I think it would be significantly harder to prevent AGI systems from succeeding with their goals.
I think both #1 and #2 could be relatively cheap (and easy) to implement if the political will is there.
Going back to your question though, as far as how it would start and how long it would take:
If there was an international effort, humanity could start #1 and/or #2 tomorrow.
I don’t see any reason why these could not be successfully implemented within the next year or two.
While my recommendations might come across as naïve to some, I am more optimistic than I was several months ago because I have been impressed with how quickly many people got freaked out by what AI is already capable of. This gives me reason to think that if progress were to continue with AI capabilities, there will be an increasing amount of pushback in society, especially as AI starts affecting people’s personal and professional lives in more jarring ways.
I only see arguments for the 0.04 case, but not for the 0.96 case. Do you have any concrete goals in mind that would not result in an EC?
If I understand correctly, you claim to be 0.96 confident that not only outer alignment will be solved, but also that all AGIs will use some kind of outer alignment solution, and no agent builds an AGI with inadequate alignment. What makes you so confident?
Thank you for your comment and insight. The main reason why my forecast for this scenario is not higher is because I think there is a sizable risk of an existential catastrophe unrelated to AGI occurring before the scenario you mentioned were to resolve positively.
I am very open to adjusting my forecast, however. Are there any resources you would recommend that make an argument for why we should forecast a higher probability for this scenario relative to other AGI x-risk scenarios? And what are your thoughts on the likelihood of another existential catastrophe occurring to humanity before an AGI-related one?
Also please excuse any delay in my response because I will be away from my computer for the next several hours, but I will try to respond within the next 24 hours to any points you make.