Comments
Forecasting Newsletter: February 2021

Sign up here or browse past newsletters here.
A new US company, Kalshi, has gotten regulatory approval from the Commodity Futures Trading Commission to create a betting platform. I don't really have many thoughts given that they haven't launched yet. I expect them to use newer technologies than PredictIt just because they are newer, and I expect them to have somewhat lower fees because it would make business sense. They are planning to open in March. From the Wall Street Journal (unpaywalled archive link):
Alfred Lin, a partner at Sequoia and a Kalshi board member, said Kalshi’s embrace of regulation was one of the reasons his firm invested in the startup. “They’re taking regulation fairly seriously,” he said. “Companies that move fast and break things are not going to work in this regulated environment.”
Hypermind has a new forecasting tournament: Where will AI be in 2023?, with a prize pot worth $7,000 so far.
Forecasters on Good Judgment Open have the opportunity to receive feedback from superforecasters if they participate in the Think Again challenge, make 10 predictions and complete a survey.
With QURI, I've been improving Metaforecast, a search tool for probabilities. It now has more prediction platforms, a nicer interface, and more search options. Readers might be interested in COVID predictions, readers from the EA movement might be particularly interested in all GiveWell and OpenPhilanthropy predictions.
Biden ordered the creation of a National Center for Epidemic Forecasting and Outbreak Analytics (secondary source). The new agency looks somewhat related to a previous proposal mentioned in this newsletter: Forecasting the next COVID-19.
Suboptimal demand forecasting for semiconductor chips has led to pausing automobile production in the US. On the one hand, automakers struggle to compete for chips against more profitable tech products—e.g., iPhones—on the other hand, US sanctions on China’s Huawei and SMIC put even more pressure on semiconductor production capacity.
Hewlett Packard has built a new supercomputer dedicated to weather forecasting for the U.S. Air Force. The new system advertises a peak performance of 7.2 petaflops. This is comparable to estimates of the human brain, and around two orders of magnitude lower than the fastest supercomputer.
Future Returns: Using the Past to Forecast the Future of the Markets. An analyst at Fidelity looks at the historical base rate for market behavior in situations similar to the current, COVID-19-affected, performance.
Where The Latest COVID-19 Models Think We're Headed — And Why They Disagree, by FiveThirtyEight
Boring is back, baby! Experienced PredictIt bettor discusses the future profitability of political predictions:
The political betting community has been quietly dreading the potential boringness of the Biden presidency – without politics being so crazy, engagement should fall off and so should the deposits of new accounts coming in to bet on whatever wild stuff Trump was up to next
I’d more or less written off this year as one in which I’d be happy to earn a third what I did last year on PredictIt and maybe try doing some grown-up work or something (lol, as if). Then it turns out January was one of the most interesting months in politics of the entire Trump presidency (to put it mildly) and engagement has remained fairly substantial. But that doesn’t mean the doldrums aren’t coming.
The following three articles, among others, won a “Forecasting Innovations Prize” I had previously co-organized under QURI.
Crowd-Forecasting Covid-19 describes the results of a COVID-19 crowd-forecasting project created during the author's PhD. This is probably the one app in which human forecasters can conveniently forecast different points in a time series, with confidence intervals. The project’s forecasts were submitted to the German and Polish Forecast Hub, and they did surprisingly well in comparison with other groups.They are looking for forecasters, and will soon expand to cover 32 European countries as part of the yet-to-be-launched European Forecast Hub.
Incentivizing forecasting via social media explores the implications of integrating forecasting functionality with social media platforms. The authors consider several important potential issues at length, propose possible solutions, as well as give recommendations regarding next steps. The scenario they consider— if it were to occur—could possibly have a large impact on the “information economy”.
Central Limit Theorem investigation visualizes how quickly the central limit theorem works in practice, i.e., how many distributions of different types one has to sum (or convolve) to approximate a Gaussian distribution in practice (rather than in the limit). The visualizations are excellent and give the readers intuitions about how long the central limit theorem takes to apply. As a caveat, the post requires understanding that the density of the sum of two independent variables is the convolution of their densities. That is, that when the post mentions “the number of convolutions you need to look Gaussian”, this is equivalent to “the number of times you need to sum independent instances of a distribution in order for the result to look Gaussian”. This point is mentioned in an earlier post of the same sequence.
I stumbled upon Alert Foxes, a blog with a few forecasting posts by Alex Foster (perfect anagram!). I particularly enjoyed the decompositions of his predictions on US election questions.
Vitalik Buterin writes about his experience betting on the US election using crypto prediction markets.
AstralCodexTen—previously SlateStarCodex, a blog I hold in high regard—has started a weekly series discussing forecasting questions (1, 2, 3).
A piece of feedback I got at the end of last year about this newsletter was to talk more about my own predictions, so here are two which I recently got wrong and one that I got right:
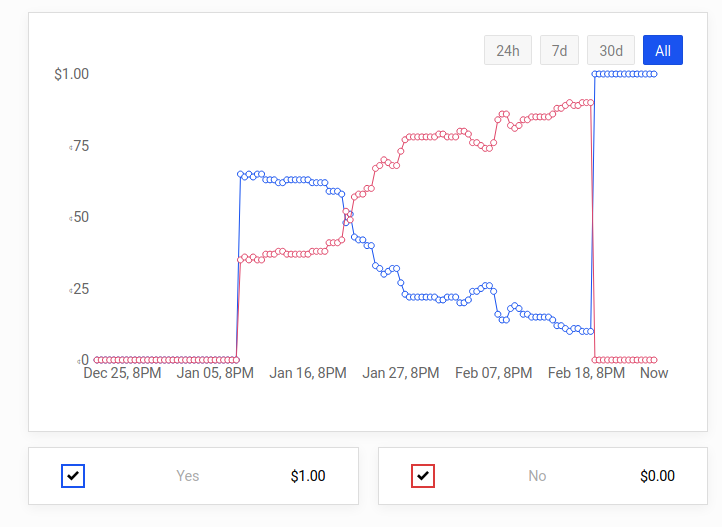
The first one was Will Kim Kardashian or Kanye West file for divorce before March 1, 2021?. After some investigation, I thought that they would try to time the divorce to maximize news about the last season of Keeping Up with the Kardashians, and was quite surprised when they didn't. Other bettors were also surprised, as the price on Polymarket looked as follows:
The second prediction I got grievously wrong was How much new funding will facial recognition companies raise between July 1 and December 31, 2020, inclusive?, on CSET-foretell. With the passage of time I updated away from the option "Less than $200 million", which ended up being chosen for resolution. The resolution source, Crunchbase, describes Acceso Digital as "a developer of facial recognition and identification technology created to solve document and process management", but doesn't classify it in the "facial recognition" category. In September 2020, Acesso Digital raised R$580M (circa $90 million), which would have been enough to raise the final question resolution to the next category ("More than $200 million but less than or equal to $500 million").
Thirdly, I assigned a 50% probability to winning an EA forum prize for a research project, which I did.
The Illinois Commission on Government Forecasting and Accountability is a government agency in charge of making e.g., revenue predictions. Judging by its webpage, it seems somewhat outdated. A similar agency in California appears to be more up to date. It might be interesting for platforms like Metaculus to try to partner with them.
Meta and consensus forecast of COVID-19 targets (secondary source) provides a variety of forecasts about COVID. They provided forecasts about US deaths conditional on vaccination rates, which could have been particularly action-guiding. They also find that forecasts which aggregate predictions from infectious disease experts and “trained forecasters” have wider uncertainty intervals than the COVID-19 Forecast Hub.
Upstart, a company which uses machine learning/data analysis to predict loan repayment, is looking for one or more forecasters with a good track record to do some consulting work. If you're interested, let me know.
Evaluating Short-term Forecast among Different Epidemiological Models under a Bayesian Framework (supporting data, webpage). The authors notice that the relative merits of different epidemic forecasting methods and approaches are difficult to compare. This is because they don’t normally have access to the same data or computational capacity in the wild. The authors set out to carry out that comparison themselves, but they don’t arrive to any sharp conclusions, other than ARIMA not being able to keep up with stochastic approaches.
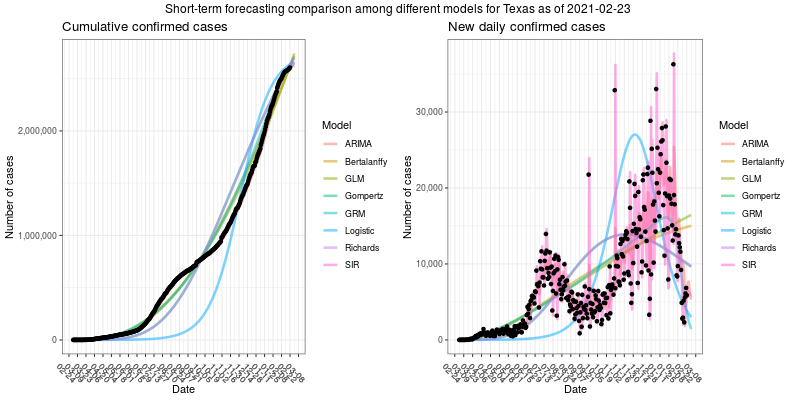
We calibrate stochastic variants of growth models and the standard SIR model into one Bayesian framework to evaluate their short-term forecasts.
Broadly speaking, there are five types of approaches to forecasting the number of new cases or the expected total mortality caused by the COVID-19: 1) time-series forecasting such as autoregressive integrated moving average (ARIMA) [...]; 2) growth curve fitting based on the generalized Richards curve (GRC) or its special cases [...]; 3) compartmental modeling based on the susceptible-infectious-removed (SIR) models or its derivations [...]; 4) agent-based modeling [...]; 5) artificial intelligence (AI)-inspired modeling.
There has been a growing debate amongst researchers over model performance evaluation and finding the best model appropriate for a certain feature (cases, deaths, etc.), a particular regional level (county, state, country, etc.), and more. Fair evaluation and comparison of the output of different forecasting methods have remained an open question, since models vary in their complexity in terms of the number of variables and parameters that characterize the dynamic states of the system.
Although a comparison of predictive models for infectious diseases has been discussed in the literature, to our best knowledge, no existing work systematically compares their performances, particularly with the same amount of data information.
None of the models proved to be golden standards across all the regions in their entirety, while the ARIMA model underperformed all stochastic models proposed in the paper
Comparing weather forecasts in Tasmania now to those made 30 years ago, a news article mentions that the amount of available data has increased 13.5 million times.
The Kelly Criterion, visualized in 3D.
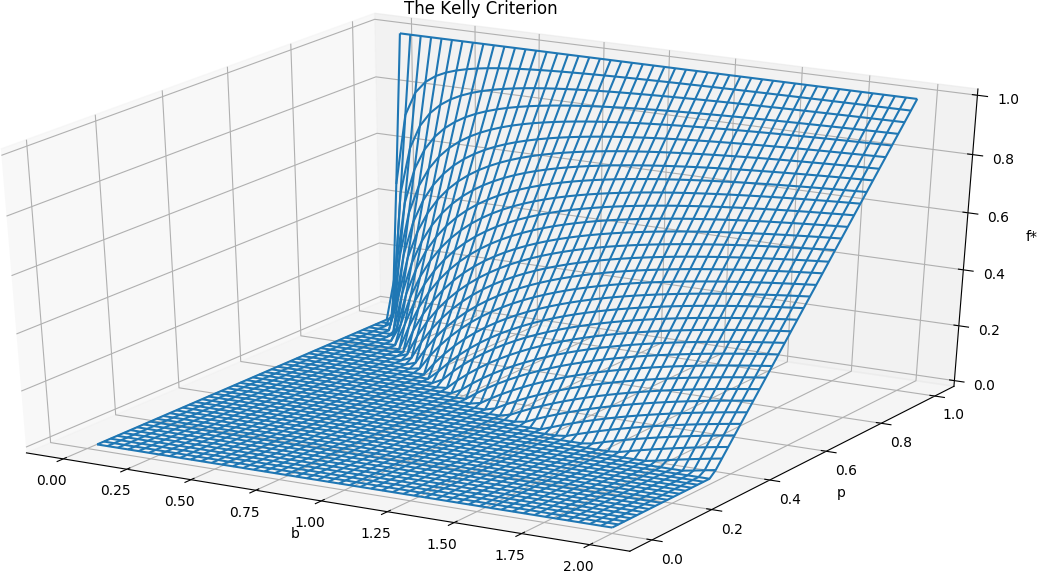
On the topic of Kelly, see also Kelly isn't (just) about logarithmic utility, Kelly *is* (just) about logarithmic utility and Never Go Full Kelly.
The EpiBench Platform to Propel AI/ML-based Epidemic Forecasting: A Prototype Demonstration Reaching Human Expert-level Performance (secondary source).
During the COVID-19 pandemic, a significant effort has gone into developing ML-driven epidemic forecasting techniques. However, benchmarks do not exist to claim if a new AI/ML technique is better than the existing ones. The "covid-forecast-hub" is a collection of more than 30 teams, including us, that submit their forecasts weekly to the CDC.
It is not possible to declare whether one method is better than the other using those forecasts because each team's submission may correspond to different techniques over the period and involve human interventions as the teams are continuously changing/tuning their approach. Such forecasts may be considered "human-expert" forecasts and do not qualify as AI/ML approaches, although they can be used as an indicator of human expert performance.
We are interested in supporting AI/ML research in epidemic forecasting which can lead to scalable forecasting without human intervention. Which modeling technique, learning strategy, and data pre-processing technique work well for epidemic forecasting is still an open problem. To help advance the state-of-the-art AI/ML applied to epidemiology, a benchmark with a collection of performance points is needed and the current "state-of-the-art" techniques need to be identified. We propose EpiBench a platform consisting of community-driven benchmarks for AI/ML applied to epidemic forecasting to standardize the challenge with a uniform evaluation protocol.
In this paper, we introduce a prototype of EpiBench which is currently running and accepting submissions for the task of forecasting COVID-19 cases and deaths in the US states and We demonstrate that we can utilize the prototype to develop an ensemble relying on fully automated epidemic forecasts (no human intervention) that reaches human-expert level ensemble currently being used by the CDC.
In an experiment, the researchers compared 3 AI and machine learning forecasting methods and 30 methodologies pulled from published research using EpiBench. They found that while many of the forecasts reportedly used the same model (SEIR), they predicted “drastically” different outcomes. Moreover, two methodologies identical except that one smoothed data over 14 days versus the other’s 7 days varied “significantly” in their performance, suggesting that data preprocessing played a nontrivial role.
Note to the future: All links are added automatically to the Internet Archive. In case of link rot, go here and input the dead link.
"I never think of the future. It comes soon enough".
Albert Einstein, said probably as a joke (source).
