Applications are open for the ML Alignment & Theory Scholars (MATS) Summer 2025 Program, running Jun 16-Aug 22, 2025. First-stage applications are due Apr 18!
MATS is a twice-yearly, 10-week AI safety research fellowship program operating in Berkeley, California, with an optional 6-12 month extension program for select participants. Scholars are supported with a research stipend, shared office space, seminar program, support staff, accommodation, travel reimbursement, and computing resources. Our mentors come from a variety of organizations, including Anthropic, Google DeepMind, OpenAI, Redwood Research, GovAI, UK AI Security Institute, RAND TASP, UC Berkeley CHAI, Apollo Research, AI Futures Project, and more! Our alumni have been hired by top AI safety teams (e.g., at Anthropic, GDM, UK AISI, METR, Redwood, Apollo), founded research groups (e.g., Apollo, Timaeus, CAIP, Leap Labs), and maintain a dedicated support network for new researchers.
If you know anyone who you think would be interested in the program, please recommend that they apply!
Program details
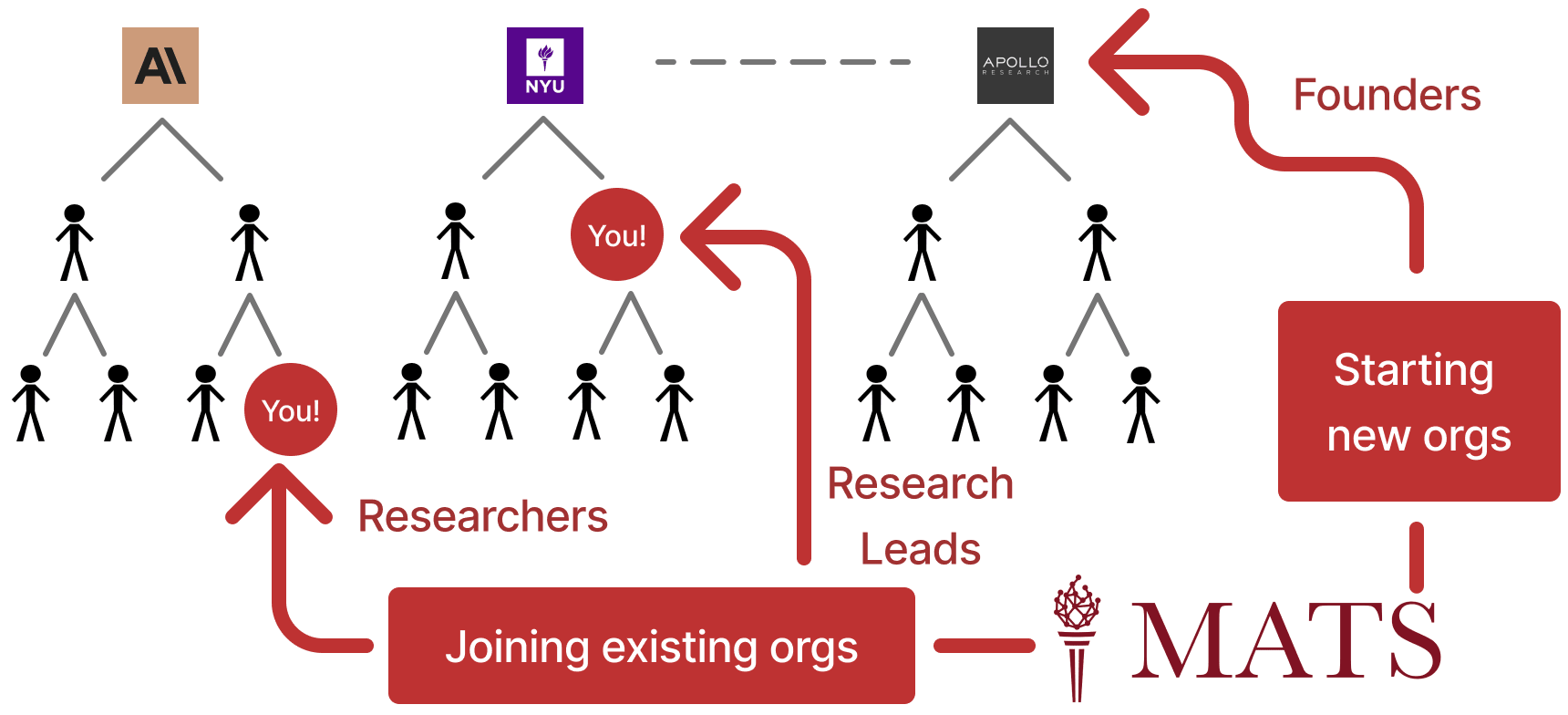
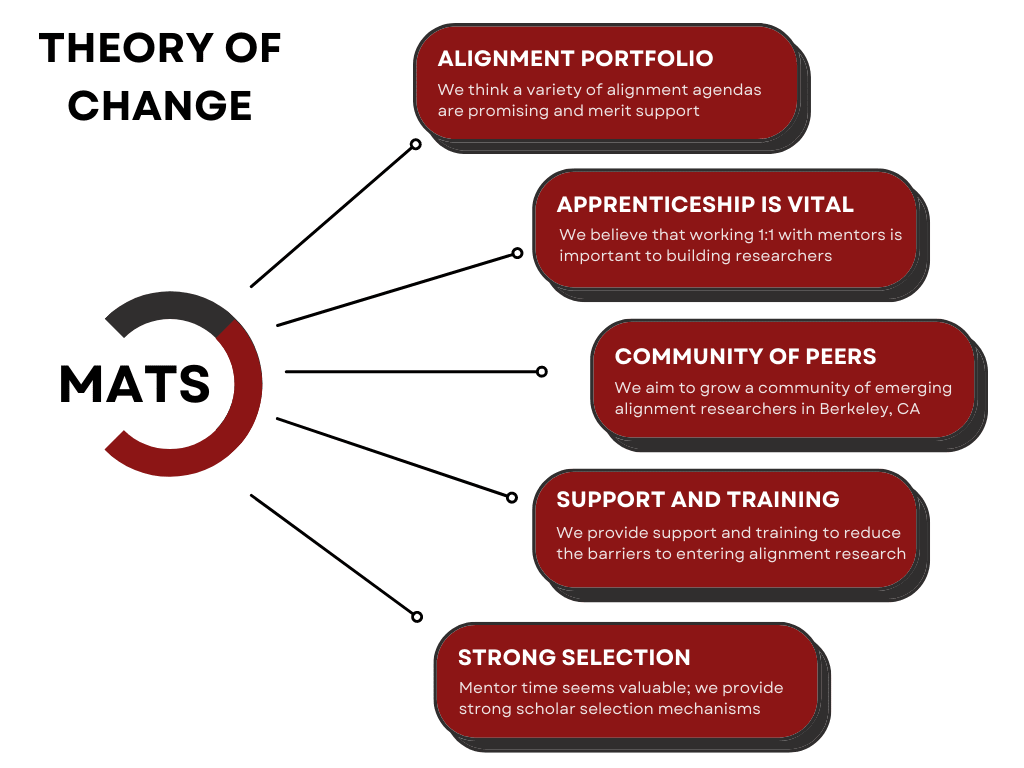
MATS is an educational seminar and independent research program (generally 40 h/week) in Berkeley, CA that aims to provide talented scholars with talks, workshops, and research mentorship in the fields of AI alignment, security, and governance, and connect them with the San Francisco Bay Area AI alignment research community. MATS provides scholars with housing in Berkeley, CA, as well as travel support, a co-working space, and a community of peers. The main goal of MATS is to help scholars develop as AI alignment researchers. You can read more about our theory of change here.
Based on individual circumstances, we may be willing to alter the time commitment of the program and arrange for scholars to leave or start early. Please tell us your availability when applying. Our tentative timeline for the MATS Summer 2025 program is below.
Scholars will receive a USD 12k stipend from AI Safety Support for completing the Training and Research Phases.
Applications (now!)
Applications open: Mar 19
Applications are due: Apr 18
Note: Neel Nanda's applications follow a modified schedule and are now closed.
Research phase (Jun 16-Aug 22)
The core of MATS is a two-month Research Phase. During this Phase, each scholar spends at least one hour a week working with their mentor, with more frequent communication via Slack. Mentors vary considerably in terms of their:
- Influence on project choices;
- Attention to low-level details vs. high-level strategies;
- Emphasis on outputs vs. processes;
- Availability for meetings.
Our Research Management team complements mentors by offering dedicated 1-1 check-ins, research coaching, debugging, and general executive help to unblock research progress and accelerate researcher development.
Educational seminars and workshops will be held 2-3 times per week. We also organize multiple networking events to acquaint scholars with researchers in the SF Bay Area AI alignment community.
Research milestones
Scholars complete two milestones during the Research Phase. The first is a Research Plan outlining a threat model or risk factor, a theory of change, and a plan for their research. This document will guide their work during the remainder of the program, which culminates in a research symposium attended by members of the SF Bay Area AI alignment community. The second milestone is a ten-minute Poster Presentation at the symposium.
Community at MATS
The Research Phase provides scholars with a community of peers, who share an office, meals, and housing. In contrast to pursuing independent research remotely, working in a community grants scholars easy access to future collaborators, a deeper understanding of other research agendas, and a social network in the AI safety community. Scholars also receive support from full-time Community Managers.
In the past, each week of the Research Phase included at least one social event, such as a party, game night, movie night, or hike. Weekly lightning talks provided scholars with an opportunity to share their research interests in an informal, low-stakes setting. Outside of work, scholars organized social activities, including road trips to Yosemite, visits to San Francisco, pub outings, weekend meals, and even a skydiving trip.
Extension phase
At the conclusion of the Research Phase, scholars can apply to continue their research in a 6-12 month Extension Phase, in London by default. Acceptance decisions are largely based on mentor endorsement and double-blind review of the mid-program Research Plan milestone. By this phase, we expect scholars to pursue their research with high autonomy.
Post-MATS
After completion of the program, MATS alumni have:
- Been hired by leading organizations like Anthropic, Google DeepMind, OpenAI, UK AISI, METR, Redwood Research, RAND TASP, Open Philanthropy, ARC, Apollo Research, FAR.AI, MIRI, CAIF, CLR, Haize Labs, Conjecture, Magic, and the US government, and joined academic research groups like UC Berkeley CHAI, NYU ARG, Mila, Cambridge KASL, and MIT Tegmark Group.
- Co-founded AI safety organizations, including Apollo Research, Athena, Atla, Cadenza Labs, Catalyze Impact, Contramont Research, Center for AI Policy, Leap Labs, Luthien, PRISM Eval, Simplex, and Timaeus, and joined start-up accelerator programs like Y Combinator, Entrepeneur First def/acc, and Catalyze Impact.
- Pursued independent research with funding from Open Philanthropy, EA Funds Long-Term Future Fund, CAIF, Foresight Institute, Manifund, and Lightspeed Grants.
- Scholars have helped develop new AI alignment agendas, including activation engineering, externalized reasoning oversight, conditioning predictive models, developmental interpretability, evaluating situational awareness, formalizing natural abstractions, and gradient routing.
You can read more about MATS alumni here.
Who should apply?
Our ideal applicant has:
- An understanding of the AI safety research landscape equivalent to having completed AI Safety Fundamentals' Alignment Course (if you are accepted into the program but have not previously completed this course, you are expected to do so before the Training Phase begins);
- Previous experience with technical research (e.g. ML, CS, math, physics, neuroscience, etc.), generally at a postgraduate level; or
- Previous policy research experience or a background conducive to AI governance (e.g. government positions, technical background, strong writing skills, AI forecasting knowledge, completed AISF Governance Course);
- Strong motivation to pursue a career in AI safety research.
Even if you do not meet all of these criteria, we encourage you to apply! Several past scholars applied without strong expectations and were accepted.
Applying from outside the US
Scholars from outside the US can apply for B-1 visas (further information here) for the Research Phase. Scholars from Visa Waiver Program (VWP) Designated Countries can instead apply to the VWP via the Electronic System for Travel Authorization (ESTA), which is processed in three days. Scholars who receive a B-1 visa can stay up to 180 days in the US, while scholars accepted into the VWP can stay up to 90 days. Please note that B-1 visa approval times can be significantly longer than ESTA approval times, depending on your country of origin.
How to apply
Applications are now open. Submissions for most mentors are due on April 18th.
Candidates first fill out a general application, then apply to work under a particular mentor who will independently review their application. Applications are evaluated primarily based on responses to mentor questions and prior relevant research experience. Information about our mentors' research agendas and application questions can be found on the MATS website.
Before applying, you should:
- Read through the descriptions and agendas of each stream and the associated candidate selection questions;
- Prepare your answers to the questions for streams you’re interested in applying to. These questions can be found on the application;
- Prepare your LinkedIn or resume.
The candidate selection questions can be quite hard, depending on the mentor! Make sure you allow adequate time to complete your application. A strong application to one mentor may be of higher value than moderate applications to several mentors (though each application will be assessed independently).
If you have any questions about the program or application process, contact us at applications@matsprogram.org. Sign up here!