Introduction
When a system is made safer, its users may be willing to offset at least some of the safety improvement by using it more dangerously. A seminal example is that, according to Peltzman (1975), drivers largely compensated for improvements in car safety at the time by driving more dangerously. The phenomenon in general is therefore sometimes known as the “Peltzman Effect”, though it is more often known as “risk compensation”.[1] One domain in which risk compensation has been studied relatively carefully is NASCAR (Sobel and Nesbit, 2007; Pope and Tollison, 2010), where, apparently, the evidence for a large compensation effect is especially strong.[2]
In principle, more dangerous usage can partially, fully, or more than fully offset the extent to which the system has been made safer holding usage fixed. Making a system safer thus has an ambiguous effect on the probability of an accident, after its users change their behavior.
There’s no reason why risk compensation shouldn’t apply in the existential risk domain, and we arguably have examples in which it has. For example, reinforcement learning from human feedback (RLHF) makes AI more reliable, all else equal; so it may be making some AI labs comfortable releasing more capable, and so maybe more dangerous, models than they would release otherwise.[3]
Yet risk compensation per se appears to have gotten relatively little formal, public attention in the existential risk community so far. There has been informal discussion of the issue: e.g. risk compensation in the AI risk domain is discussed by Guest et al. (2023), who call it “the dangerous valley problem”. There is also a cluster of papers and works in progress by Robert Trager, Allan Dafoe, Nick Emery-Xu, Mckay Jensen, and others, including these two and some not yet public but largely summarized here, exploring the issue formally in models with multiple competing firms. In a sense what they do goes well beyond this post, but as far as I’m aware none of their work dwells on what drives the logic of risk compensation even when there is only one firm, and it isn’t designed to build intuition as simply as possible about when it should be expected to be a large or a small effect in general.
So the goal of this post is to do that, using x-risk from AI as the running example. The post is about risk compensation in general, not about AI risk, and I don’t know whether risk compensation should be expected to be a large or small effect in the AI domain (or any other), but hopefully having an example in mind makes it easier to follow the reasoning and decide how large you expect risk compensation effects to be in a given domain you’re familiar with. The post also introduces some distinctly “economic” intuitions around risk compensation which I found helpful and have not quite seen spelled out before (though they don’t differ much in spirit from Appendix B of Peltzman’s original paper).
Model
An AI lab’s preferences
In this model, a deployed AI system either immediately causes an existential catastrophe or is safe. If it’s safe, it increases the utility of the lab that deployed it. Referring to the event that it turns out to be safe as “survival”, the expected utility of the lab is the product of two terms:
= (the probability of survival) ⨉ (the lab’s utility given survival).
That is, without loss of generality, the lab’s utility level in the event of the catastrophe is denoted 0. Both terms are functions of two variables:
- some index of the resources invested in safety work, denoted (“safety work”), and
- some index of how capable the AI is and/or how widely it’s deployed, denoted (“capabilities”).
Utility given survival
Starting with the second term: we will say that the lab’s utility given survival
a1. increases continuously and unboundedly in and
a2. is independent of . That is, given that survival was achieved, the lab does not care intrinsically about how much effort was put into safety.
Under these assumptions, we can posit, without loss of generality, that
for some (not necessarily positive) constant . If is positive, the people at the lab consider life without AI better than being wiped out in an AI-induced existential catastrophe. If is negative, they consider it worse.
Positing that the lab’s expected utility given survival is linear in capabilities, at least up to some threshold, is not a restriction on the model because we can stipulate that what “+1 unit of capabilities” means is simply “an increase in capabilities large enough to generate +1 util for the lab”. The assumption that increases unboundedly in is a more serious restriction, and relaxing it is discussed below.
Probability of survival
We will say that the probability of survival
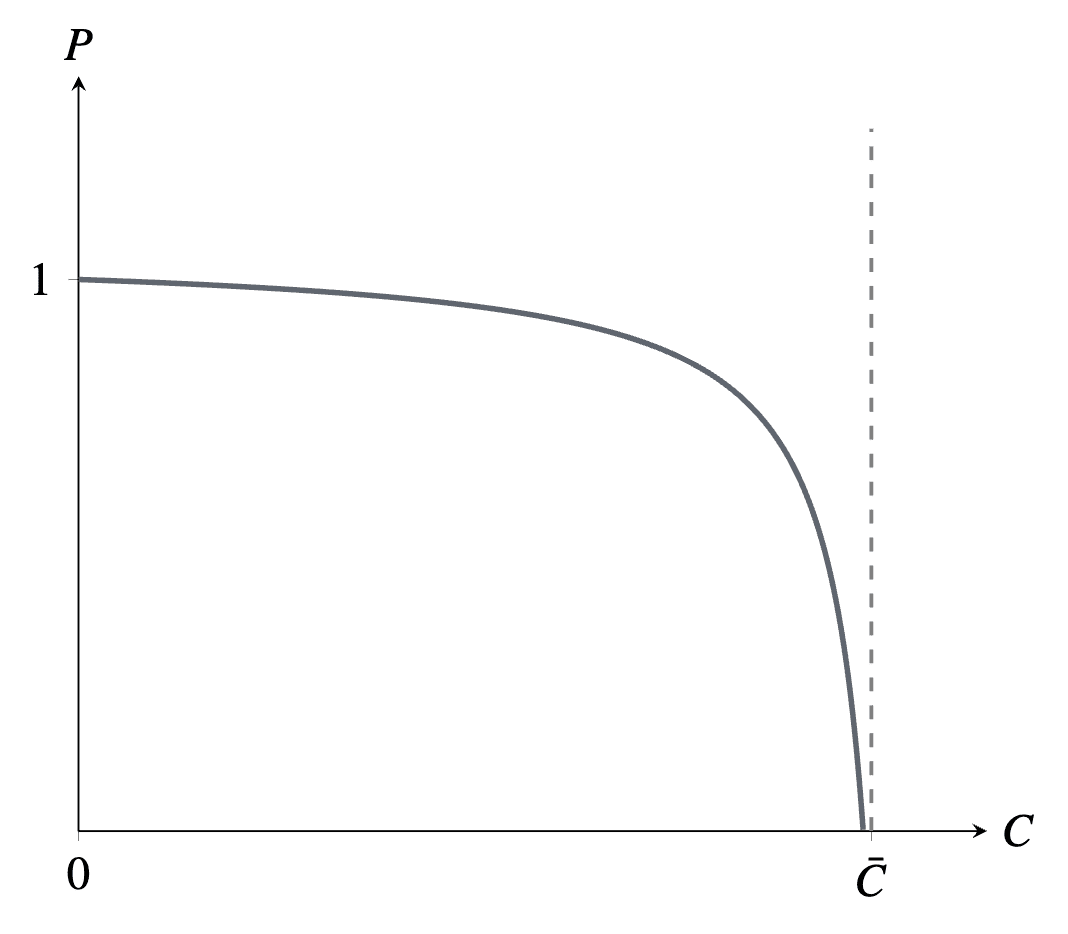
b1. equals 1 when ,
b2. decreases continuously in ,[4] and
b3. increases in given .
In this section and most of the next two, I’ll assume that is a particular function satisfying these conditions:
.
Unlike , this choice of is a considerable loss of generality beyond the listed assumptions. A section below considers the extent to which the survival function can be changed before the results significantly change.
Summary
In sum, at least until the “changing the assumptions” section,
.
Of course nothing about a function of this shape has anything to do with existential catastrophe in particular. A utility function of this form could just as well capture the preferences of anyone deploying anything with some probability of one outcome whose utility is fixed, with increasing in “”, and probability of a different outcome whose utility increases in “”. then represents the size of the utility-gap between “good outcome but ” and “bad outcome”. We’ll keep referring to survival and so on mainly just to have a concrete case in mind.
Defining the game
If doing safety work (increasing ) does not change , the probability of survival increases when more safety work is done. This is what happens in a two-stage game in which
- The lab chooses a baseline level of safety work () and a degree of capabilities ().
- People outside the lab do () units of safety work. These top up the baseline, so .
In this game, whatever the lab’s policy, higher straightforwardly results in higher , and so higher probability of survival . There is no room for risk compensation.
But in reality the world is a messy dynamic game. People choose what to do with their time in light of what work others have already done, after some lag; others respond likewise; and so on. The “others choose, then you choose” model illustrated above, on which people often seem to intuitively operate,[5] must have some truth to it: if you go into some career, others typically won’t adjust their behavior instantaneously. But so does the “you choose, then others choose” model at the other end of the spectrum, as might be illustrated here by a two-stage game in which
- People outside the lab do units of safety work.
- The lab chooses . It also puts units of effort into safety, so .
This is the sort of model that most fully allows for risk compensation. Here, higher may induce the lab to choose lower and/or higher , so the effect of increasing on is unclear.
Indeed, it would be more standard to refer to the phenomenon of higher inducing lower as crowding out of safety work, which is not the subject of this post, and to reserve the term risk compensation for the phenomenon of higher inducing higher . To focus on risk compensation in this sense, therefore, we will spend the rest of the post considering the even simpler game in which
- People outside the lab choose .
- The lab chooses
Relative to the second game, this third game removes one of the two channels through which safety work done outside the lab can fail to increase : since the lab is not bothering (or is not able) to do any safety work at all, there is no way for safety work done outside the lab to decrease the amount done by the lab. Nevertheless, as illustrated below, even the risk compensation effect in isolation (higher inducing higher ) can be extreme.
Result & explanations
Result: the effect of safety work on probability of survival
To find the lab’s optimal choice of given , i.e. how far it wants to push capabilities without over-doing the risk of an accident, take the derivative of its expected utility with respect to and set it to zero:
.
(If and , the lab’s optimal choice under the constraint is to set .)
If —if the people at the lab consider life without AI to be as bad an outcome as an AI-induced existential catastrophe—then the probability of survival here equals , which is independent of S. The safety benefits of doing more safety work S are fully offset by inducing the lab to choose higher . has no effect on the probability of survival.
If —the (presumably more typical) case that people at the lab consider life without AI to be a better outcome than an AI-induced existential catastrophe—then probability of survival here equals 1 if (because then ), and if , which decreases in S. Safety work backfires.
Only if , with AI-less life considered worse than death, does the probability of survival increase in S.
Alternative explanation
The lab sets so that
a) the proportional increase to from marginally increasing , i.e. , equals
b) the proportional decrease to from marginally increasing .
(b) is constant, across values of , for any given . But is inversely proportional to (b).
So: suppose is doubled, so (b) halves. Then the lab wants to halve (a). So:
- When , it has to more than double to halve . With doubled but more than doubled, rises, and falls.
- When () , it has to more (less) than double to halve . With doubled but more (less) than doubled, rises (falls), and falls (rises).
Let’s dwell a bit more on the intuition for the case, since it’s arguably both the most plausible and the most counterintuitive.
Suppose , so that life is worth living even at . If S is too low, the lab doesn't want to set at all. E.g. if , even setting just brings near-certain death () for little benefit. But if is high enough—more than —then setting becomes worthwhile, and falls from 1.
Once we recognize that increasing can induce a shift from to , it is clear that safety increases have historically increased the incidence of accidents in all sorts of domains. I think it’s safe to say that if airplanes still crashed as frequently as the Wright brothers’ first prototypes, no one would use them (life without flight is still better than death), and the number of airplane crashes would therefore be even lower than it is.
The importance of the unbounded C assumption
Incidentally, in the case of airplanes, after they became safe enough to be widely used, further safety work greatly lowered the probability of a crash per flight. So in this context, the relationship between safety work and probability of survival is evidently U-shaped.

{kind=link}
It makes sense that safety work would eventually not be offset much in the airplane context because here, recalling that is denominated in units of utility given survival, cannot be set arbitrarily high. Even if a plane were flown as fast and recklessly as would be optimal if safety were not a concern at all, this would not offer passengers infinite utility: other than a slightly cheaper ticket, and saving a few minutes on the safety video at the beginning, I’m not sure it would offer much utility at all.
As noted in the previous section, the assumption that can be set arbitrarily high is a strong one, producing simpler but more extreme risk compensation effects than follow when is bounded. Given bounded (and ), I expect that the U-shaped relationship between safety work and probability of survival is typical, and that the results we came to under the assumption that is unbounded roughly hold only when is far from its bound. This is discussed in the section below on bounded utility.
Economic intuition
There is also a more thoroughly “economic” intuition about the main result so far that I find helpful. I think it’s especially helpful for thinking about what changes when the survival function is different or is bounded, so this is put off to the next section.
Carrots and potatoes
Consider a consumer with preferences over two goods: carrots and potatoes . She has a budget constraint, and a favorite basket subject to the budget constraint:
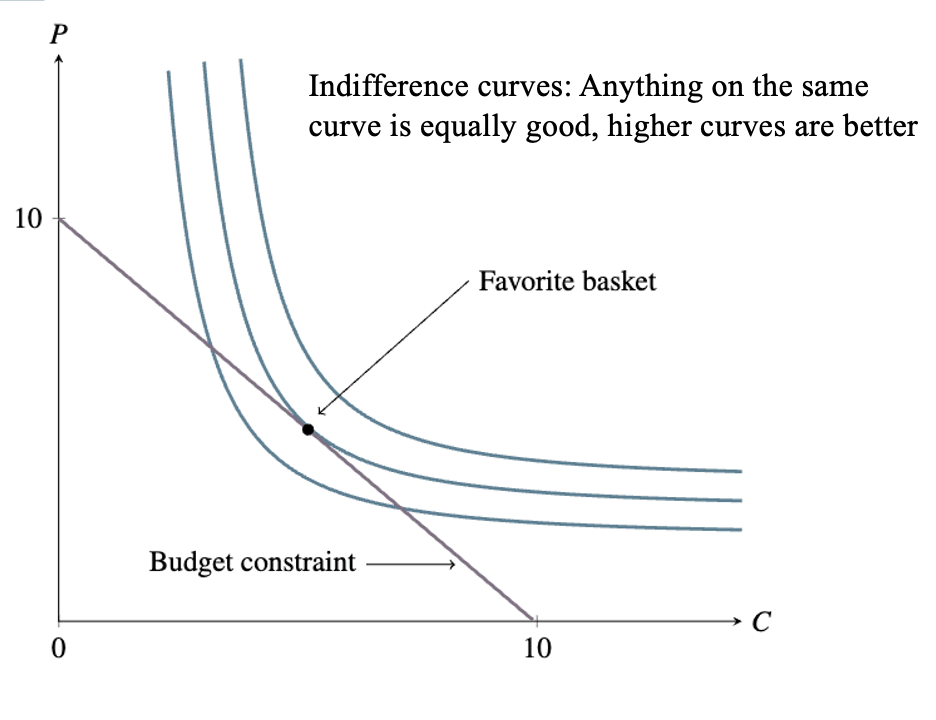
At first, say, the prices of the vegetables are equal. It takes as much land, water, farmer effort, etc. to grow one as to grow the other.
Now suppose the government wants people to eat more carrots, so it funds an improvement to carrot-farming technology. Once this improvement is developed, 1.2 carrots can be developed using the land (etc.) which it used to take to grow 1 carrot, and which it still takes to grow 1 potato. Assuming that the markets are competitive, carrots will now accordingly be cheaper than potatoes, and the consumer’s budget constraint will change. She will probably not want to buy fewer carrots than before, but the number of potatoes she wants to buy might well be more than, less than, or the same as before:
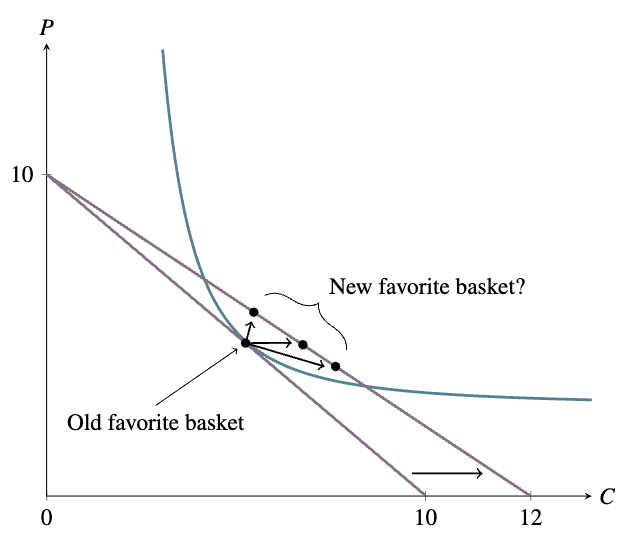
If she sees carrots and potatoes as very substitutable, such that a thought along the lines of “carrots and potatoes are basically the same, and carrots are cheaper now” predominates, the number of potatoes she buys will fall. If she sees the two vegetables as very complementary, such that a thought along the lines of “I like my stew to have a certain ratio of carrot to potato, so to some extent I’ll use the money I’m saving now that carrots are cheaper to buy more potatoes as well” predominates, the number of potatoes she buys will rise.
For an example of perfect substitutability, suppose the consumer’s utility function is
for some . This describes, for example, the case in which the consumer just cares about how many calories she gets and a potato has times as many calories as a carrot. In this case, letting and denote the prices of carrots and potatoes respectively, if she only buys potatoes; if she only buys carrots; and if she doesn’t care how she splits her budget. Starting from the case in which and she buys some of each, if falls at all, her potato demand plummets (she switches to only buying carrots), and if rises at all, her potato demand jumps (she switches to only buying potatoes).
There is a central case, in which the consumer’s demand for one good (potatoes) doesn’t depend on the price of the other (carrots). This is the case in which the consumer’s utility function is “Cobb-Douglas”. Without getting into Cobb-Douglas utility in general, the special case of Cobb-Douglas utility that will be relevant here is
.
Why doesn’t our consumer’s demand for one good depend on the price of the other here?
- Whatever the prices are, she will always want to buy a positive amount of each good. If she buys zero of either, her utility is zero; if she buys a positive amount of both, her utility is positive.
- Given that she is buying a positive amount of each good, her basket is optimal only if the extra utility she gets by spending a bit more on carrots equals the extra utility she gets by spending a bit more on potatoes:
.
Otherwise she can increase her utility by spending a bit less on one and a bit more on the other. (The extra utility you get by spending a bit more on carrots equals the extra utility you get by getting a bit more carrot, , times the number of carrots you get by spending a bit more on carrot, which is . Likewise for potatoes.) - To maintain the equality above, whenever the price of carrots is multiplied by , the number of carrots bought has to be multiplied by .[6]
Safety work as carrot-farming technology
In the model of the previous section, instead of defining the lab’s utility as a function of capabilities and safety effort , we can define it as a function of capabilities and probability of survival :
.
The lab, like the consumer, faces a tradeoff between and . This tradeoff depends on :
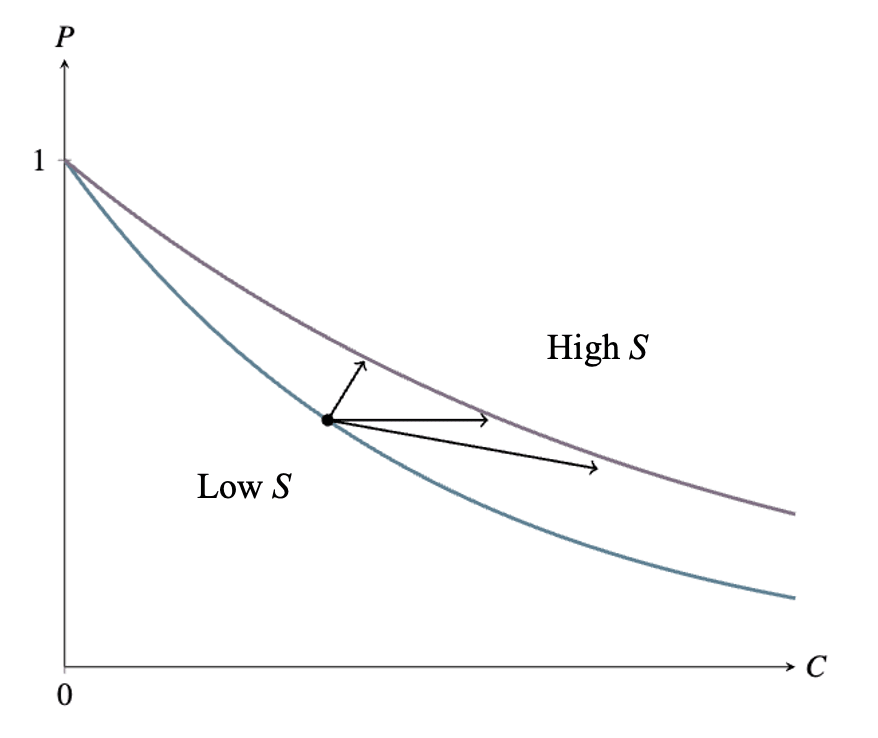
On the original framing, the variable the lab directly chooses is , and this in turn yields some level of as a side effect. On the new framing, the lab, like a consumer, directly chooses and subject to a constraint. It is hopefully clear that the two framings are equivalent. One could just as well describe a consumer as directly choosing a number of carrots to buy, and winding up with some number of potatoes (the number affordable with all the money not spent on carrots) as a side effect.
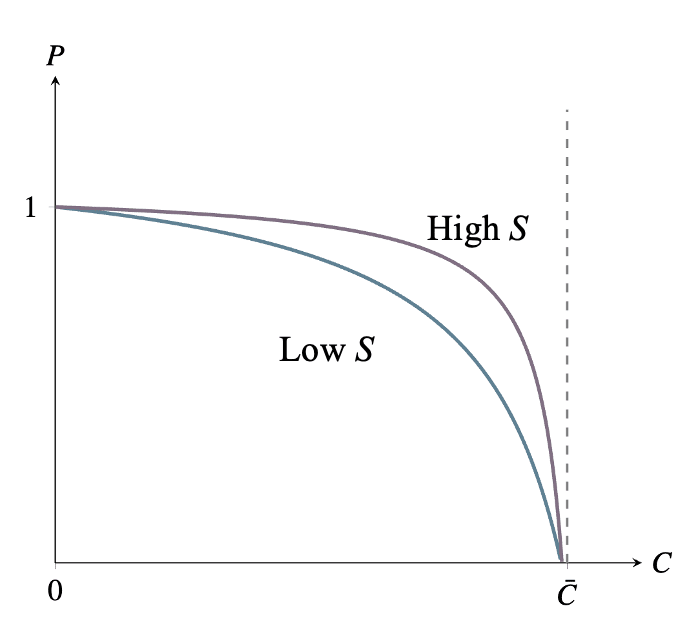
But the new framing makes it clearer that increases in safety work are effectively decreases to the “price” of , at least under the survival function . Here, when is multiplied by , the lab can multiply by while keeping fixed (“buying the same number of potatoes”). On the graph above, whatever the starting levels of and , a given increase to shifts the level of affordable at each level of to the right by the same proportion. Though S stands for Safety, we shouldn’t be misled by the label: it’s precisely what we identified above as carrot-farming technology. It’s the thing a government should fund if it wants people to have more , not more .
When , the lab’s preferences over and are Cobb-Douglas: . It therefore responds to a cut in the price of (i.e. an increase to ) by increasing and keeping fixed, as we have seen.
When , the lab’s preferences are . When , this case is, as it looks, somewhere between the Cobb-Douglas and perfect-substitutability cases. The lab therefore responds to a cut in the price of by increasing to the point of lowering , as we have also seen.
Generalizing the model
Probability of survival
Other survival functions
We have seen that, under the survival function , increases to S amount to “decreases in the price of .” Increases to do not amount to decreases in the price of under all survival functions satisfying b1-b3.
This relationship does hold well beyond the case, however. That particular survival function was chosen for simplicity when differentiating with respect to , but given b2 and b3, the “↑ ≡ ↓” relationship holds whenever satisfies
(*) there is a function such that, for all , , and , .
The interpretation is hopefully clear: (*) is precisely the condition under which moving from to is the same as dividing the price of by , because whatever the original levels of and , if the lab goes for times more after the -change, it gets the original . For example, survival function
also satisfies (*) (and indeed also with ), so all our results also hold with this survival function.
Furthermore, there is a sense in which, for any survival function satisfying b1 and b3, -increases have to look more like decreases to the price of than like decreases to the price of , “on average”. When rises, the new curve lies above the old curve at all (by b3)—but not at , because for any (by b1). The amount by which the new curve lies above the old curve must therefore rise on average as rises from 0 to any positive number (though it does not necessarily rise monotonically).
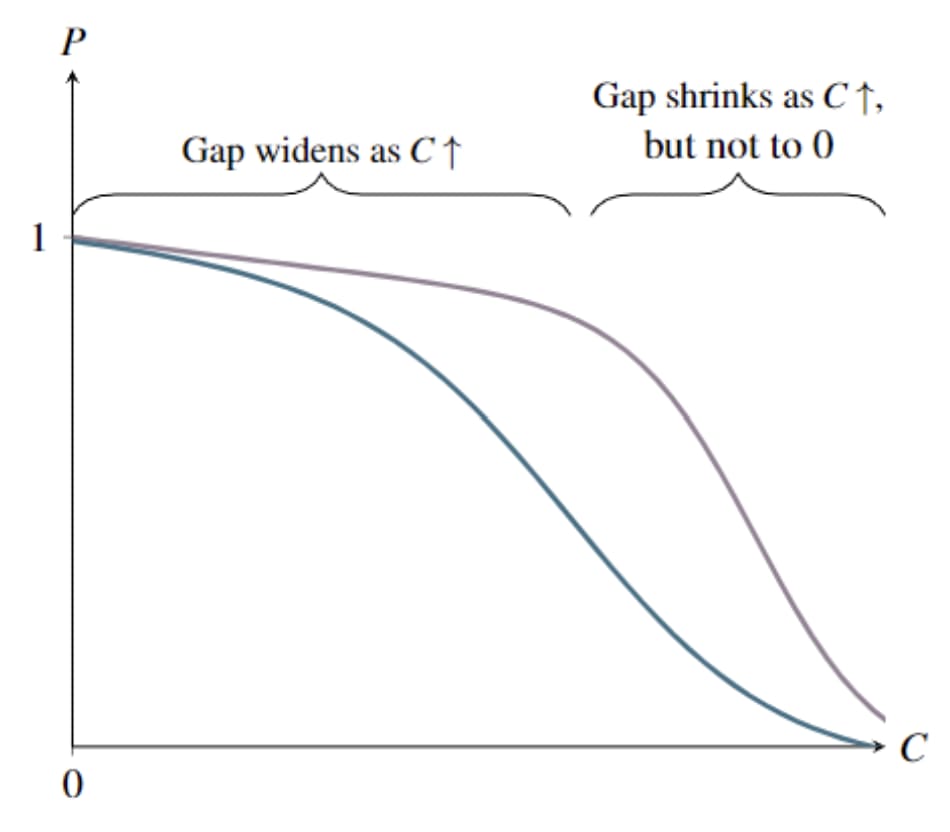
Given a “decrease to the price of potatoes”, the number of extra potatoes you can buy is higher the fewer carrots you buy. Here, that cannot happen. However few carrots you buy, you get at most one potato.
Misperceptions
So far, we have assumed that the lab knows what the survival function is. But a lab might be misperceiving it. Of course, many who work on AI safety believe that the big labs are currently generating greater risks than they are aware of.
This is not a reason to dismiss the logic of risk compensation, since while misperception can shrink the size of the effect, it can also exacerbate it or have no effect on it. Indeed, when Googling for existing materials on risk compensation, many of the top results introduce it with something like “people’s perception of risk decreases, and so people may feel that they can now afford to make riskier decisions” (from here). At least to my reading, wording like this suggests that one of the main concerns people have around risk compensation is that safety work can raise risk because people think the work is more effective than it is.
Given survival function , a misperception never affects the sign of the effect of safety work on the probability of survival iff the perceived survival function also satisfies (*) with .[7] For example, suppose that : i.e. that the lab always thinks things are as safe as if twice as much safety work has been done than actually has been done. Then it sets . So again, an increase to induces a decrease to (so, an increase to the actual probability of survival) iff , and so on.
Likewise, given survival function and perceived survival function satisfying (*) with , the misperception magnifies the risk compensation induced by a move from to iff , and lessens it iff the inequality is reversed. For example, if , then satisfies (*) with . Given , therefore, we have
and so magnified risk compensation if , and
and so lessened risk compensation if .
Utility given survival
Bounded utility
So far, our only significant assumption on utility given survival has been that increases unboundedly in . Put another way, since is denominated in units of utility, we have assumed that there is no upper bound on achievable utility given survival.
But this assumption is unrealistic, especially once we note that increases to can lower the lab’s utility given survival simply by being expensive. Presumably, at any given time, higher choices of come with higher profits but also higher costs, so that even in the event that safety is no concern—even if for all , — is maximized at some finite level by some finite amount of capabilities and deployment.[8]
The simplest way to impose this restriction is to modify the game so that, in “stage 2”, the lab chooses for some finite , rather than any . Under this modification, the lab’s optimal choice of is not { if ; otherwise} but { if ; if ; otherwise}. Increases to then have the effects we have seen up to the point that , past which further increases to have no impact on and raise in the intuitive way.
This observation is enough to capture the important point: if capabilities are running up against an upper bound, then safety work cannot be offset. But the framework above has a somewhat suspicious discontinuity. For any value of , an increase to induces a one-for-one increase to until , past which increasing does not affect at all. A more reasonable-seeming result, at least to my mind, would have been one in which, however high is, the induced choice of is still constrained at least a little bit by safety. Making planes 1% safer wouldn’t increase pilot carelessness (or miles flown) by 1%, but come on, at least in expectation it would increase these a little.
The reason for the implausible discontinuity can be seen if we describe utility given survival as a function of some more conventional measure of capabilities—say, denoted , so that utility given survival is with . If is differentiable, then if it is maximized at some —i.e. if —we must have . In other words, increases to capabilities-as-conventionally-understood c have almost no impact on around . It then follows that a unit of increase to must, around its maximum value of , consist of a huge increase to capabilities-as-conventionally-understood, and thus, presumably, a huge decrease to . The chosen level of thus remains at least slightly below its maximum, and there is always at least a little bit of room for safety work to induce an increase to it.
After this modification, the survival function cannot globally satisfy (*). It might approximately satisfy (*) for ranges of , , and with for —that is, safety work might act like a decrease to the relative price of capabilities when the chosen level of capabilities would be far from its upper bound both before and after the safety improvement. Indeed, by the argument of the section above on other survival functions, it is still the case that, over some range, increases to must produce greater increases to the probability of survival the higher the choice of and so act roughly like subsidies on . But probably doesn’t come close to satisfying (*) for levels of given , , with for or . Instead, the gap between the graphs of and probably widens as moves to the left. Around , safety work subsidizes potatoes after all.
Implications of bounded utility
To try a thought experiment: heroin is much less widely used than alcohol, despite apparently being more enjoyable, presumably because it is so much more dangerous.[9] This implies that the utility currently being derived from heroin is a very small fraction of what it would be if heroin were only as harmful as alcohol, let alone what it would be if heroin were harmless: . Given the logic outlined above, this in turn predicts that it would not be surprising if risk compensation were more than complete in the heroin case, on the current margin. And indeed, when we compare heroin deaths to alcohol deaths, this conclusion seems reasonable. Heroin currently causes fewer deaths than alcohol, but if it were made precisely as safe as alcohol, it seems likely that it would (eventually) be more widely used than alcohol currently is, and would thus (eventually) cause more deaths than alcohol currently does.
Likewise, if indeed risk compensation is more extensive in NASCAR racing than in ordinary driving, and more extensive in driving than it currently is in flying, I expect “distance from the utility bound” is a large part of the explanation why. The feasible utility gains to driving or (especially) flying as recklessly as if safety were no concern are small: in these domains, is already near . In NASCAR, by contrast, it is often the case that driving just a little bit faster significantly increases a driver’s probability of victory. To the extent that safety concerns are constraining drivers’ choices of at all, therefore, they are often constraining them to levels significantly below , and something closer to the “unbounded ” logic applies.
Incidentally, the NASCAR observation brings us closer to an intuition for why risk compensation appears to generally be a more significant worry in “arms race” scenarios, as studied by Trager and the others cited in the introduction, than in the single-actor scenarios considered here. Beyond noting this, since those scenarios are more complicated, and since (as cited) there are already materials designed to build intuition around them, I won’t get into them here.
Even if one lab pulls far enough ahead in AI development that the relevant model is closer to a single-actor model than to an arms race model, however, the reasoning above suggests that risk compensation will eventually be a more significant factor than it currently is. Today, while even the most advanced AI systems are neither very capable nor very dangerous, safety concerns are not constraining much below . If technological advances unlock the ability to develop systems which offer utopia if their deployment is successful, but which pose large risks, then the developer’s choice of at any given is more likely to be far below
, and the risk compensation induced by increasing is therefore more likely to be strong.
Takeaways
On how significant risk compensation is
It should sometimes be expected to be more than full
Anecdotally, there seems to be a widespread impression that, when people are being rational, risk compensation should, at worst, only partially nullify the effects of safety work. But as we’ve seen, it can go either way, depending on the details. If (a) life without deployment is better than suffering the catastrophe () and (b) the utility being achieved from current deployment is far from the level that would be achieved if safety were no concern (), then safety work should typically be expected to induce risk compensation that is more than complete. This suggests to me that risk compensation is a possibility worth taking very seriously.
But, probably, it is usually only partial
When measured, efforts to make systems safer usually seem to have some effect in the intuitive direction. This makes sense, for at least two reasons. First, conditions (a) and (b)—especially (b), I think—can fail to hold. Second, others typically respond to an increase in safety work only with a lag. Between when safety work has been done and when the capabilities and/or deployment have ramped up accordingly, accident probability is unambiguously lower.
Measurement
On the other hand, the lag makes it harder to know what effect a given bit of safety work has in the long run. The sense “I haven’t seen capabilities or deployment speed up because of my safety paper from last month” might be misleading. If there is work I don’t know about that attempts to estimate the degree of risk compensation in various existential-risk-relevant domains, then it will be great if someone comments about it! If not, it might be worth thinking about whether it could be estimated in some of these domains; and in the meantime, hopefully theory-informed guesses are better than nothing.
On what to do in light of it
I expect that people actually working on reducing risk (existential or otherwise) in some domain will have more precise ideas than I do about the practical implications of risk compensation. But here are at least a few broad conclusions that come to my own mind, if only to illustrate the idea. I assume throughout that your goal is just to maximize the “probability of survival”.
When doing safety work, seek weak-risk-compensation domains
All else equal, prefer to do safety work in domains…
- In which there is a long lag between when the safety measure will be implemented and when it will be possible to compensate for it by implementing more capabilities in the relevant area.
- That “lowers the price of rather than ”. That is, look for work that increases the probability of survival at lower levels of capabilities (as measured by utility given survival) by more, not less, than it increases the probability of survival at higher levels of capabilities. The ideal scenario is to make it much safer to deploy the medium-capability system that was going to be deployed anyway, without also making it much safer to deploy the high-capability system that wasn’t going to be deployed due to risk fears. (To reiterate, the claim is just that risk compensation pushes in this direction, all else equal. There are many other reasons to focus on making highest-capability systems safer in particular. For instance, if more work is already going into the medium-capability systems already on the verge of deployment than on the high-capability systems that will not be deployed for years, then work of the latter kind runs less risk of being nullified by crowding out of safety work.)
- In which “” is...
- lower, if the work is primarily “lowering the price of capabilities”. For instance, maybe the value of life without AI () is higher in the US than in China, since the US is the richer country. If so, then in the event that the US and China are working on very different kinds of AI systems, work that makes the American-style systems safer in a way where the benefits of the safety work increase the more advanced or widely deployed the systems are should be expected to induce more risk compensation than work on making the Chinese-style systems safer in such a way (again, all else equal). (If life without AI is better for the relevant decision-makers in China than in the US, this goes the other way.)
- higher, if the work is primarily “lowering the price of survival”. Again, recall that the higher is, the more substitutable and are, so slightly lowering the price of one of the two goods motivates a more significant shift toward that good.
- In which “”. That is, prefer work that is perceived to lower risk by less than it does. (An extreme case would be to raise secretly, if this is possible. But in practice, presumably, an insight about how to make an AI system safer doesn’t have any impact—and so doesn’t really constitute an increase to —unless the lab is aware of it and implements it.)
Seek ways of increasing safety other than “safety work”
Naturally, if safety work seems likely to induce significant risk compensation, it may make sense to look for work that won’t. Not all work to lower the chance of a catastrophe consists of safety work in the sense defined here, i.e. work “actually making the thing safer”. For example, you might push for policy that raises and imposes a cap on . Or, if you think that the risk associated with implementing a given is higher than the relevant decision-maker thinks it is, you might try to communicate this, e.g. via model evaluations (or “evals”). These approaches might backfire to some extent too, of course, but if so it will be for different reasons.
Thanks to Guive Assadi, Tom Davidson, Isabel Juniewicz, Fin Moorhouse, GovAI lunch-and-learn attendees (especially Jamie Bernardi), and many others who have given helpful comments on various iterations of this content. Thanks to Tom Houlden for making the graphs.
- ^
The term “risk homeostasis” is also sometimes used, but typically reserved for the case in which risk compensation is enough to return risk precisely to its original level.
- ^
Many studies in other domains (including some follow-ups to Peltzman) have found little or no risk compensation, and this leads some to conclude that the whole idea is just a theoretical possibility that turns out not to be real. I don’t think this is the right conclusion, for two reasons. First, there’s no way this conclusion holds in the extreme. To repeat one famous thought experiment, drivers would obviously drive more carefully if seat belts were banned and steering wheels had giant metal spikes pointing at the driver’s chest. Second, risk compensation can be difficult to observe for a few reasons. For example, it might be found that the number of car accidents doesn’t jump up (or, not much) once a safety measure is implemented. But it seems likely that even if a measure does eventually affect driver behavior, it does so only with a long lag, since it takes time for drivers to appreciate the fact that their cars have become safer (via, say, seeing fewer injured friends and relatives or repeatedly viewing commercials emphasizing the new features); for drivers to adjust their driving habits; and for substitutionary measures such as speed limits to adjust. This lag issue in particular is discussed a bit more in the “defining the game” section and the conclusion.
- ^
Note that this is distinct from the possibility that RLHF itself allowed for the development of more advanced capabilities, discussed e.g. by Christiano (2023).
- ^
That is, we will say that what we mean by setting is setting capabilities at the maximum level for which the probability of survival is 1. Note that, when this is the case, we can harmlessly impose the constraint that , since it will never be optimal for the lab to choose .
- ^
And which is an implicit premise of e.g. the “ITN” formula, at least as presented on the 80,000 Hours page about it.
- ^
That is, as long as her budget stays fixed. If is multiplied by more [less] than , must rise [fall] for the equality to be maintained. Since the price of potatoes has not changed, this would mean spending more [less] on both goods.
- ^
Given that is high enough to motivate on both and (·).
- ^
Note that this is not a philosophical discussion about the plausibility of unbounded utility in principle, but a discussion about whether, given the technological possibilities available at a given time, it is possible to achieve any level of utility given survival by putting out AI that is sufficiently capable or widely deployed.
- ^
And because it is illegal and socially discouraged, but of course this is also largely because it is so dangerous.
Thanks for exploring this, I found it quite interesting.
I'm worried that casual readers might come away with the impression "these dynamics of compensation for safety work being a big deal obviously apply to AI risk". But I think this is unclear, because we may not have the key property C≪¯¯¯¯C (that you call assumption (b)).
Intuitively I'd describe this property as "meaningful restraint", i.e. people are holding back a lot from what they might achieve if they weren't worried about safety. I don't think this is happening in the world at the moment. It seems plausible that it will never happen -- i.e. the world will be approximately full steam ahead until it gets death or glory. In this case there is no compensation effect, and safety work is purely good in the straightforward way.
To spell out the scenario in which safety work now could be bad because of risk compensation: perhaps in the future everyone is meaningfully restrained, but if there's been more work on how to build things safely done ahead of time, they're less worried so less restrained. I think this is a realistic possibility. But I think that this world is made much safer by less variance in the models of different actors about how much risk there is, in order to avoid having the actor who is an outlier in not expecting risk being the one to press ahead. Relatedly, I think we're much more likely to reach such a scenario if many people have got on a similar page about the levels of risk. But I think that a lot of "technical safety" work at the moment (and certainly not just "evals") is importantly valuable for helping people to build common pictures of the character of risk, and how high risk levels are with various degrees of safety measure. So a lot of what people think of as safety work actually looks good even in exactly the scenario where we might get >100% risk compensation.
All of this isn't to say "risk compensation shouldn't be a concern", but more like "I think we're going to have to model this in more granularity to get a sense of when it might or might not be a concern for the particular case of technical AI safety work".
Good to hear, thanks!
I‘ve just edited the intro to say: it’s not obvious to me one way or the other whether it's a big deal in the AI risk case. I don't think I know much about the AI risk case (or any other case) to have much of an opinion, and I certainly don't think anything here is specific enough to come to a conclusion in any case. My hope is just that something here makes it easier to for people who do know about particular cases to get started thinking through the problem.
If I have to make a guess about the AI risk case, I'd emphasize my conjecture near the end, just before the "takeaways" section, namely that (as you suggest) there currently isn't a ton of restraint, so (b) mostly fails, but that this has a good chance of changing in the future:
If lots/most of AI safety work (beyond evals) is currently acting more "like evals" than like pure "increases to S", great to hear--concern about risk compensation can just be an argument for making sure it stays that way!
What you call the "lab's" utility function isn't really specific to the lab; it could just as well apply to safety researchers. One might assume that the parameters would be set in such a way as to make the lab more C-seeking (e.g. it takes less C to produce 1 util for the lab than for everyone else).
But at least in the case of AI safety, I don't think this is the case. I doubt I could easily distinguish a lab capabilities researcher (or lab leadership, or some "aggregate lab utility function") from an external safety researcher if you just gave me their utility functions over C and S. (AI safety has significant overlap with transhumanism; relative to the rest of humanity they are way more likely to think there are huge benefits to development of safe AGI.) In practice it seems like the issue is more like epistemic disagreement.
You could still recover many of the conclusions in this post by positing that an increase to S leads to a proportional decrease in probability of non-survival, and the proportion is the same between the lab and everyone else, but the absolute numbers aren't. I'd still feel like this was a poor model of the real situation though.
Okay great, good to know. Again, my hope here is to present the logic of risk compensation in a way that makes it easy to make up your mind about how you think it applies in some domain, not to argue that it does apply in any domain. (And certainly not to argue that a model stripped down to the point that the only effect going on is a risk compensation effect is a realistic model of any domain!)
As for the role of preference-differences in the AI risk case—if what you’re saying is that there’s no difference at all between capabilities researchers’ and safety researchers’ preferences (rather than just that the distributions overlap), that’s not my own intuition at all. I would think that if I learn
my guess about who was who would be a fair bit better than random.
But I absolutely agree that epistemic disagreement is another reason, and could well be a bigger reason, why different people put different values on safety work relative to capabilities work. I say a few words about how this does / doesn’t change the basic logic of risk compensation in the section on "misperceptions": nothing much seems to change if the parties just disagree in a proportional way about the magnitude of the risk at any given levels of C and S--though this disagreement can change who prioritizes which kind of work, it doesn’t change how the risk compensation interaction plays out. What really changes things there is if the parties disagree about the effectiveness of marginal increases to S, or really, if they disagree about the extent to which increases to S decrease the extent to which increases to C lower P.
In any event though, if what you’re saying is that a framing more applicable to the AI risk context would have made the epistemic diagreement bit central and the preference disagreement secondary (or swept under the rug entirely), fair enough! Look forward to seeing that presentation of it all if someone writes it up.
Tbc if the preferences are written in words like "expected value of the lightcone" I agree it would be relatively easy to tell which was which, mainly by identifying community shibboleths. My claim is that if you just have the input/output mapping of (safety level of AI, capabilities level of AI) --> utility, then it would be challenging. Even longtermists should be willing to accept some risk, just because AI can help with other existential risks (and of course many safety researchers -- probably the majority at this point -- are not longtermists).
Nice post, Phil!
e−1 is missing after "here equals".
e−(1−k/S) is missing before "if S>k".
Whoops, thanks! Issues importing from the Google doc… fixing now.
A small point of confusion: taking U(C) = C (+ a constant) by appropriate parametrization of C is an interesting move. I'm not totally sure what to think of it; I can see that it helps here, but it makes it seem quite hard work to develop good intuitions about the shape of P. But the one clear intuition I have about the shape of P is that there should be some C>0 where P is 0, regardless of S, because there are clearly some useful applications of AI which pose no threat of existential catastrophe. But your baseline functional form for P excludes this possibility. I'm not sure how much this matters, because as you say the conclusions extend to a much broader class of possible functions (not all of which exclude this kind of shape), but the tension makes me want to check I'm not missing something?
Thanks for noting this. If in some case there is a positive level of capabilities for which P is 1, then we can just say that the level of capabilities denoted by C = 0 is the maximum level at which P is still 1. What will sort of change is that the constraint will be not C ≥ 0 but C ≥ (something negative), but that doesn't really matter since here you'll never want to set C<0 anyway. I've added a note to clarify this.
Maybe a thought here is that, since there is some stretch of capabilities along which P=1, we should think that P(.) is horizontal around C=0 (the point at which P can start falling from 1) for any given S, and that this might produce very different results from the e−CS example in which there would be a kink at C=0. But no--the key point is whether increases to S change the curve in a way that widens as C moves to the right, and so "act as price decreases to C", not the slope of the curve around C=0. E.g. if P=1−C2/S (for C∈[0,√S], and 0 above), then in the k=0 case where the lab is trying to maximize (1−C2/S)C, they set C=√S/3, and so P is again fixed (here, at 2/3) regardless of S.
Executive summary: Risk compensation, where safety improvements lead to more dangerous usage, can partially, fully, or more than fully offset the benefits of safety work, and deserves more attention in analyzing existential risk reduction efforts.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.
A corollary of this might be "it is worthwhile to put effort into showing how little risk mitigation has actually been accomplished by the risk-reducing efforts" in order to minimize risk compensation.
I don't follow--are you saying that (i) AI safety efforts so far have obviously not actually accomplished much risk-reduction, (ii) that this is largely for risk compensation reasons, and (iii) that this is worth emphasizing in order to prevent us from carrying on the same mistakes?
If so, I agree that if (i)-(ii) are true then (iii) seems right, but I'm not sure about (i) and (ii). But if you're just saying that it would be good to know whether (i)-(ii) are true because if they are then it would be good to do (iii), I agree.
I am saying something like: If actual risk is reduced by a quantity A, but the perceived reduction is actually B, then it's worth spending time telling people the difference in cases where B>>A, else the effects of the project have been negative (like the effects of green-washing or more relevantly safety-washing). This is not about AI safety in general but for a particular intervention on a case by case basis.
Ah I see, sorry. Agreed