Quick Intro: My name is Strad and I am a new grad working in tech wanting to learn and write more about AI safety and how tech will effect our future. I'm trying to challenge myself to write a short article a day to get back into writing. Would love any feedback on the article and any advice on writing in this field!
As AI becomes more intelligent, people are thinking more about how AI could cause harm. As a result, the emphasis on AI safety has been increasing. One potential strategy towards creating safer AI is a field of research called Mechanistic Interpretability (MI). The aim of the field is to discover methods that would allow us to understand how AI models truly think so that we can control them better.
While a very promising tool for AI safety, MI research has had to deal with a significant road block to interpreting AI systems known as superposition. This is a phenomenon that arises within the inner workings of AI models which makes discerning their thought process quite difficult.
In order to understand the problem of superposition, it is important to first have an idea of how current AI models represent ideas in the real world.
How do LLMs Represent Ideas?
Lets take the example of Large Language Models. LLMs utilize a neural network architecture which takes in text input and outputs useful responses. In order to do this, LLMs need to somehow gain an understanding of the underlying concepts these text inputs represent (i.e. dogs, trees, politics, etc.).
LLMs do this by turning these words into embeddings. Embeddings are numerical representations of words which an LLM can then map onto a coordinate system with n dimensions.
For example, below is a coordinate system with 3 dimensions and an arrow representing an embedding/word. An LLM takes a coordinate system like this (but with much more dimensions) and creates an arrow for every word. The placement and direction of these arrows relative to each other helps encode the actually meaning of the words so that the LLM can understand them. How the model determines where to put these arrows to get an accurate understanding is learned during its training process.
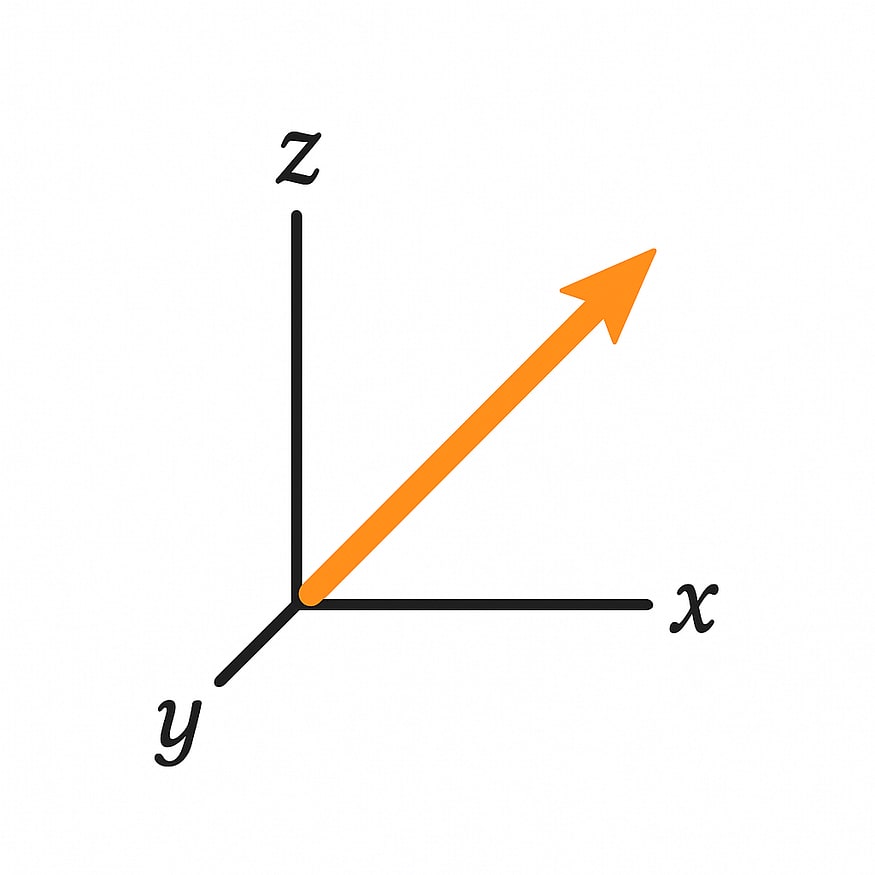
The concepts an LLM learns about the world are encoded into the coordinate system itself through the different directions an arrow could potentially point. Each of these directions, represents a given concept in the real world such as gender, or color.
This correlation between direction and concepts is so strong that you can actually do arithmetic using these directions to get from one concept to another. For example, if you start at the embedding for the word “king” and subtract the embedding for “man” and then add the embedding for “women” you get close to the embedding for “queen.”
Where This Framework Creates Obstacles for Interpretability
The amount of dimensions within this coordinate system is determined by the amount of neurons within the neural network. Each of the axes of the coordinate system corresponds to one of these neurons. Interpretability work often uses the activation patterns of these neurons to infer which directions, and therefore concepts, an AI model is relying on at any given point during its thought process.
Since we use the activations of neurons to view these concepts, and internally the concepts are represented using directions in the coordinate system, there was a hope in the field of MI that these directions for each concept would align perfectly with the axes of the coordinate system. If this were the case, then each concept would be cleanly represented by a single neuron making it easy to interpret a model.
However, if this was true, then a model would only be able to learn as much concepts as their were neurons in its architecture. What researchers saw though was that models seemed to have learned a large breadth of concepts based on their outputs.
In order to be effective, models are optimized to prioritize learning the most important concepts for understanding the world. However, models with a relatively small amount of neurons showed an understanding of pretty niche concepts. If the one-neuron-per-concept assumption were true, these niche concepts would likely have not been useful enough to make the cut.
What researchers have found, is that in order to actually make room for all these extra concepts, LLMs have learned to utilize combinations of neurons to represent concepts. In other words, any arbitrary direction in the coordinate system can be used to represent concepts. The amount of possible directions a model can use is far larger than the amount of neurons in its architecture, significantly increasing the limit for the amount of concepts it can learn.
This results in the phenomenon of superposition, where one neuron can be part of the representation for many different concepts, and many neurons are used for the representation of one concept. This means concepts can share neurons. This is possible because many of the internal concepts the model learns rarely activate concurrently. For example, it is rare a model will have to think of “pizza” and “The Roman Empire” at the same time. The low risk of interference between two concepts allows their neuronal representations to overlap.
This is what makes interpreting models so difficult. Instead of having a single neuron light up for a single concept, many can light up for multiple concepts. This results in the concepts being “tangled up” within the model’s neurons, making it difficult for an interpreter to distinguish between them.

This is an issue for AI safety efforts because effective interpretation of AI models relies on the ability to decompose the representation space, in which AI encodes its internal thought processes, into these individual concepts. This is important because, not only do we need to understand the concepts a model is using, but we also need to understand how the model connects these concepts to see how the model actually uses them to execute higher level reasoning. This becomes much more difficult to do if we can’t isolate distinct concepts within the model to work as building blocks.
One popular method for dealing with superposition utilizes a tool called a sparse autoencoder (SAE). An SAE is a neural-network-based tool that can be used to better extract and display the representations of concepts learned in a given model.
The concepts being used by a model at a given time, along with the associated activity patterns of its neurons, are collected and fed into an SAE. The SAE, through training on this data, learns how to reconstruct these activations using a set of clearer, more interpretable representations of concepts. The key to this process is that these new representations are designed to activate sparsely, meaning only a few can fire for any given input. By forcing only a few representations to activate, rather than all of them at the same time, the SAE helps disentangle the model’s representations from one another allowing any interpreter to more easily distinguish between them.
Looking Ahead
While SAEs have been a huge breakthrough in interpretability research, we are still far from fully solving the issues around superposition. SAEs don't always reliably capture all the concepts learned by the model. They also can only work for parts of the model at any given time.
Current research strategies to help with superposition include improving the effectiveness and scale of SAEs while also looking into strategies for training models to decrease the amount of overlap between their representations.
The better we get at disentangling the effects of superposition, the better we get at truly interpreting AI models allowing us to better ensure their safety for the future.

