(I originally wrote this post as some rough notes on defining the alignment problem, with the intention of turning them into something more polished later. I've now started doing that, as part of a broader series introduced here. In particular, the first post in that series covers some of the same ground as section 1 of this post. It also has the same title. And some of essays in the series will draw on these notes as well.)
People often talk about “solving the alignment problem.” But what is it to do such a thing? I wanted to clarify my thinking about this topic, so I wrote up some notes.
In brief, I’ll say that you’ve solved the alignment problem if you’ve:
- avoided a bad form of AI takeover,
- built the dangerous kind of superintelligent AI agents,
- gained access to the main benefits of superintelligence, and
become able to elicit some significant portion of those benefits from some of the superintelligent AI agents at stake in (2).[1]
The post also discusses what it would take to do this. In particular:
- I discuss various options for avoiding bad takeover, notably:
- Avoiding what I call “vulnerability to alignment” conditions;
- Ensuring that AIs don’t try to take over;
- Preventing such attempts from succeeding;
- Trying to ensure that AI takeover is somehow OK. (The alignment discourse has been surprisingly interested in this one; but I think it should be viewed as an extreme last resort.)
- I discuss different things people can mean by the term “corrigibility”; I suggest that the best definition is something like “does not resist shut-down/values-modification”; and I suggest that we can basically just think about incentives for/against corrigibility in the same way we think about incentives for/against other types of problematic power-seeking, like actively seeking to gain resources.
- I also don’t think you need corrigibility to avoid takeover; and I think avoiding takeover should be our focus.
- I discuss the additional role of eliciting desired forms of task-performance, even once you’ve succeeded at avoiding takeover, and I modify the incentives framework I offered in a previous post to reflect the need for the AI to view desired task-performance as the best non-takeover option.
- I examine the role of different types of “verification” in avoiding takeover and eliciting desired task-performance. In particular:
- I distinguish between what I call “output-focused” verification and “process-focused” verification, where the former, roughly, focuses on the output whose desirability you want to verify, whereas the latter focuses on the process that produced that output.
- I suggest that we can view large portions of the alignment problem as the challenge of handling shifts in the amount we can rely on output-focused verification (or at least, our current mechanisms for output-focused verification).
- I discuss the notion of “epistemic bootstrapping” – i.e., building up from what we can verify, whether by process-focused or output-focused means, in order to extend our epistemic reach much further – as an approach to this challenge.[2]
- I discuss the relationship between output-focused verification and the “no sandbagging on checkable tasks” hypothesis about capability elicitation.
- I discuss some example options for process-focused verification.
- Finally, I express skepticism that solving the alignment problem requires imbuing a superintelligent AI with intrinsic concern for our “extrapolated volition” or our ”values-on-reflection.” In particular, I think just getting an “honest question-answerer” (plus the ability to gate AI behavior on the answers to various questions) is probably enough, since we can ask it the sorts of questions we wanted extrapolated volition to answer. (And it’s not clear that avoiding flagrantly-bad behavior, at least, required answering those questions anyway.)
Thanks to Carl Shulman, Lukas Finnveden, and Ryan Greenblatt for discussion.
1. Avoiding vs. handling vs. solving the problem
What is it to solve the alignment problem? I think the standard at stake can be quite hazy. And when initially reading Bostrom and Yudkowsky, I think the image that built up most prominently in the back of my own mind was something like: “learning how to build AI systems to which we’re happy to hand ~arbitrary power, or whose values we’re happy to see optimized for ~arbitrarily hard.” As I’ll discuss below, I think this is the wrong standard to focus on. But what’s the right standard?
Let’s consider two high level goals:
Avoiding a bad sort of takeover by misaligned AI systems – i.e., one flagrantly contrary to the intentions and interests of human designers/users.[3]
- Getting access to the main benefits of superintelligent AI. I.e., radical abundance, ending disease, extremely advanced technology, superintelligent advice, etc.
- I say “the main benefits,” here, because I want to leave room for approaches to the alignment problem that still involve some trade-offs – i.e., maybe your AIs run 10% slower, maybe you have to accept some delays, etc.
- Superintelligence here means something like: vastly better than human cognitive performance across the board. There are levels of intelligence beyond that, and new benefits likely available at those levels. But I’m not talking about those. That is, I’m not talking about getting the benefits of as-intelligent-as-physically-possible AI – I’m talking, merely, about vastly-better-than-human AI.
- So “the main benefits of superintelligent AI” means something like: the sorts of benefits you could get out of a superintelligent AI wielding its full capabilities for you in desired ways – but without, yet, building even-more-superintelligent AI.
It’s plausible that one of the benefits of vastly-better-than-human AI is access to a safe path to the benefits of as-intelligent-as-physically-possible AI – in which case, cool. But I’m not pre-judging that here.[4]
That said: to the extent you want to make sure you’re able to safely scale further, to even-more-superintelligent-AI, then you likely need to make sure that you’re getting access to whatever benefits merely-superintelligent AI gives in this respect – e.g., help with aligning the next generation of AI.
- And in general, a given person might be differentially invested in some benefits vs. others. For example, maybe you care more about getting superintelligent advice than about getting better video games.
- In principle we could focus in on some more specific applications of superintelligence that we especially want access to, but I won’t do that here.
- “Access” here means something like: being in a position to get these benefits if you want to – e.g., if you direct your AIs to provide such benefits. This means it’s compatible with (2) that people don’t, in fact, choose to use their AIs to get the benefits in question.
- For example: if people choose to not use AI to end disease, but they could’ve done so, this is compatible with (2) in my sense. Same for scenarios where e.g. AGI leads to a totalitarian regime that uses AI centrally in non-beneficial ways.
My basic interest, with respect to the alignment problem, is in successfully achieving both (1) and (2). If we do that, then I will consider my concern about this issue in particular resolved, even if many other issues remain.
Now, you can avoid bad takeover without getting access to the benefits of superintelligent AI. For example, you could not ever build superintelligent AI. Or you could build superintelligent AI but without it being able to access its capabilities in relevantly beneficial ways (for example, because you keep it locked up inside a secure box and never interact with it).
- Indeed, “avoiding bad takeover without getting access to the benefits of superintelligence” is currently what we are doing. It’s just that we might not stay in this state for much longer.
You can also plausibly avoid bad takeover and get access to the benefits of superintelligent AI, but without building the particular sorts of superintelligent AI agents that the alignment discourse paradigmatically fears – i.e. strategically-aware, long-horizon agentic planners with an extremely broad range of vastly superhuman capabilities.
- Thus, for example, you might be able to get access to the main benefits of superintelligence using some combination non-agential systems, systems with a very narrow capability profile, myopic systems, or only-somewhat-better-than-human AI agents.
Indeed, I actually think it’s plausible that we could get access to tons of the benefits of superintelligent AI using large numbers of fast-running but only-somewhat-smarter-than-human AI agents, rather than agents that are qualitatively superintelligent. And I think this is likely to be notably safer.[5]
- I’m also not going to count high-fidelity human brain emulations as AIs, so a future where you get access to the benefits of superintelligent AI using emulated humans would also count as “not building the dangerous kind of AI agents.” And same for one where you get access to those benefits using “enhanced” biological humans – i.e., humans using extremely good brain computer interfaces, humans with enhanced intelligence through some other means, etc.
Generally, though, the concern is that we are, in fact, on the path to build superintelligent AI agents of the sort of the alignment discourse fears. So I think it’s probably best to define the alignment problem relative to those paths forward. Thus:
- I’ll say that you’ve avoided the alignment problem in any scenario where you avoided the bad sort of AI takeover, but didn’t build superintelligent AI agents.
- And I’ll say that you’ve handled the alignment problem in any scenario where you avoided AI takeover despite building superintelligent AI agents.
- I’m saying “handled” here because I don’t think all versions of this would really satisfy what we normally think of as “solving” the alignment problem. Consider, for example, scenarios where you build SI agents and avoid takeover, but aren’t able to do anything useful with those agents.
Then, further, I’ll say that you avoided or handled the alignment problem “with major loss in access-to-benefits” if you failed to get access to the main benefits of superintelligent AI. And I’ll say that you avoided or handled it “without major loss in access-to-benefits” if you succeeded at getting access to the main benefits of superintelligent AI.
Finally, I’ll say that you’ve solved the alignment problem if you’ve handled it without major loss in access-to-benefits, and become able to elicit some significant portion of those benefits specifically from the dangerous SI-agents you’ve built.
- In principle, you could handle the problem without major loss in access-to-benefits, but without being able to elicit any of those benefits from the SI agents you’ve built (for example: build SI agents, keep them in a secure box, then get your benefits access via other means). But I think it’s kinda janky to call this “solving” the problem, since our intuitive conception of “solving” alignment is so closely tied to being able to elicit desired forms of task performance from SI agents.
- We could also imagine an even stricter definition of “solving” the problem, on which you have become able to elicit from an SI agent any type of task performance that it is capable of. And indeed, maybe this fits common usage of the term better. I’m not focusing on this, though, because I think it’s a higher standard than we need.
Thus, in a chart:
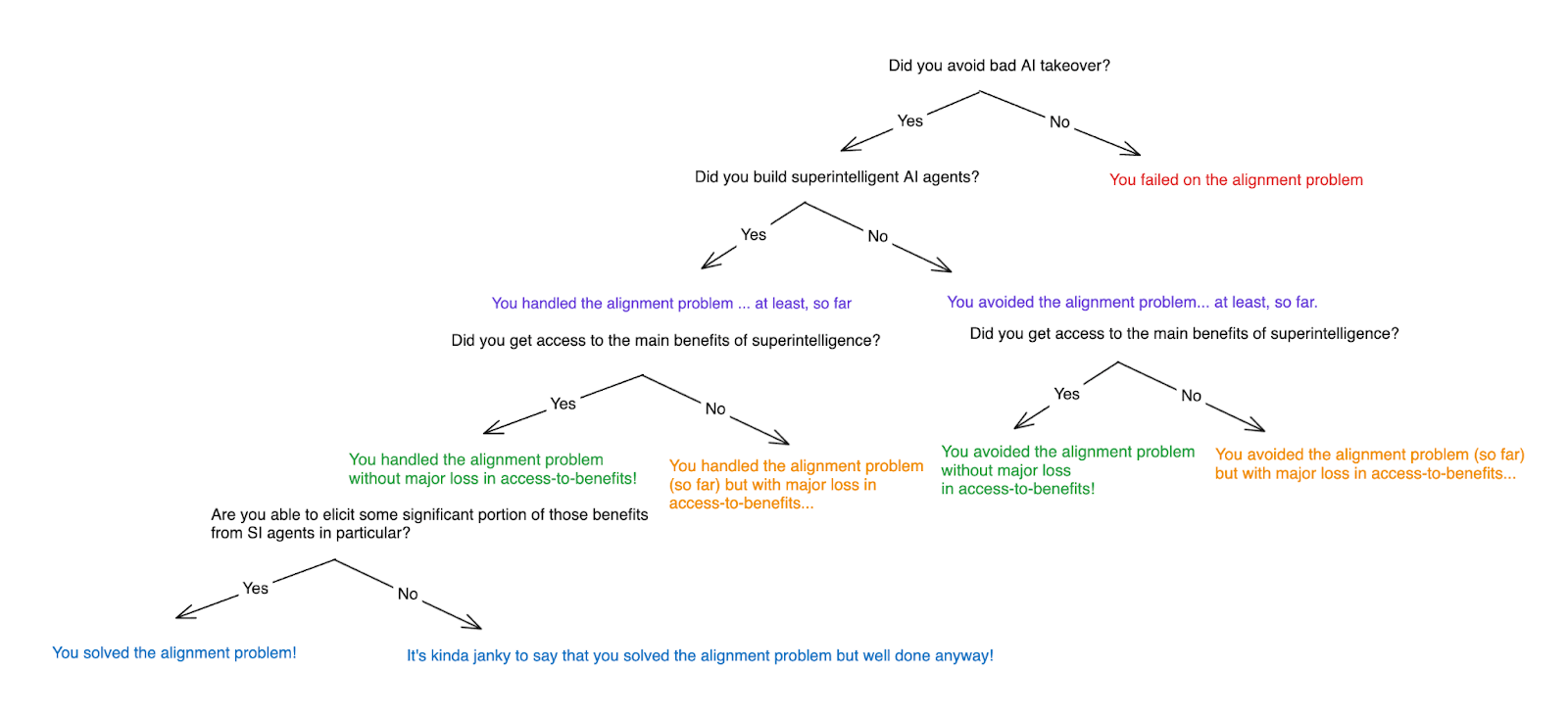
I’ll focus, in what follows, on solving the problem in this sense. That is: I’ll focus on reaching a scenario where we avoid the bad forms of AI takeover, build superintelligent AI agents, get access to the main benefits of superintelligent AI, and do so, at least in part, via the ability to elicit some of those benefits from SI agents.
However:
- In general, I mostly just care about avoiding takeover and getting access to the main benefits of superintelligence. I don’t actually care whether you build SI agents or not; or whether you can elicit benefits from those agents in particular.
- In this respect, I’ll also note that I do think that avoiding the problem – or at least avoiding it for a long time – is an important avenue to consider; and that it may indeed be possible to avoid it without major loss in access-to-benefits.
- And in general, even if we build SI agents, I think that we should be thinking hard about ways to not need to elicit various benefits from such agents in particular.
- I also think that taking a major hit in access-to-benefits could easily be worth it if it helps, sufficiently, in avoiding takeover. So we shouldn’t rule out paths in this vein either.
Note, though, that to the extent you’re avoiding the problem, there’s a further question whether your plan in this respect is sustainable (after all, as I noted above, we’re currently “avoiding” the problem according to my taxonomy). In particular: are people going to build superintelligent AI agents eventually? What happens then?[6]
So the “avoiding the problem” states will either need to prevent superintelligent AI agents from ever being built, or they’ll transition to either handling the problem, or failing.
And we can say something similar about routes that “handle” the problem, but without getting access to the main benefits of superintelligence. E.g., if those benefits are important to making your path forward sustainable, then “handling it” in this sense may not be enough in the long term.
Admittedly, this is a somewhat deviant definition of “solving the alignment problem.” In particular: it doesn’t assume that our AI systems are “aligned” in a sense that implies sharing our values. For example, it’s compatible with “solving the alignment problem” that you only ever controlled your superintelligences and then successfully elicited the sorts of task performance you wanted, even if those superintelligences do not share your values.
This deviation is on purpose. I think it’s some combination of (a) conceptually unclear and (b) unnecessarily ambitious to focus too much on figuring out how to build AI systems that are “aligned” in some richer sense than I’ve given here. In particular, and as I discuss below, I think this sort of talk too quickly starts to conjure difficulties involved in building AI systems to which we’re happy to hand arbitrary power, or whose values we’re happy to see optimized for arbitrarily hard. I don’t think we should be viewing that as the standard for genuinely solving this problem. (And relatedly, I’m not counting “hand over control of our civilization to a superintelligence/set of superintelligences that we trust arbitrarily much” as one of the “benefits of superintelligence.”)
On the other hand, I also don’t want to use a more minimal definition like “build an AGI that can do blah sort of intense-tech-implying thing with a strawberry while having a less-than-50% chance of killing everyone.” In particular: I’m not here focusing on getting safe access to some specific and as-minimal-as-possible sort of AI capability, which one then intends to use to make things (pivotally?) safer from there. Rather, I want to focus on what it would be to have more fully solved the whole problem (without also implying that we’ve solved it so much that we need to be confident that our solutions will scale indefinitely up through as-superintelligent-as-physically-possible AIs).
2. A framework for thinking about AI safety goals
Let’s look at this conception of “solving the alignment problem” in a bit more detail. In particular, we can think about a given sort of AI safety goal in terms of the following six components:
- Capability profile: what sorts of capabilities you want the AI system you’re building to have.
- Safety properties: what sorts of things you want your AI system to not do.
- Elicitation: what sorts of task performance you want to be able to elicit from your AI system.
- This is distinct from the capability profile, in that an AI system might have capabilities that you aren’t able to elicit. For example, maybe an AI system is capable of helping you with alignment research, but you aren’t able to get it to do so.
- Competitiveness: how competitive your techniques for creating this AI system are, relative to the other techniques available for creating a system with a similar capability profile.
- Verification: how confident you want to be that your goals with respect to (1)-(4) have been satisfied.
Scaling: how confident you want to be that the techniques you used to get the relevant safety properties and elicitation would also work on more capable models.[7]
How would we analyze “solving the alignment problem” in terms of these components? Well, the first three components of our AI safety goal are roughly as follows:
- Capability profile: a strategically-aware, long-horizon agentic planner with vastly superhuman general capabilities.
- Safety properties: does not cause or participate in the bad kind of AI takeover.
- Elicitation: we are able to elicit at least some desired types of task performance – enough to contribute significantly to getting access to the main benefits of superintelligent AI.
OK, but what about the other three components – i.e. competitiveness, verification, and scaling? Here’s how I’m currently thinking about it:
- Competitiveness: your techniques need to be competitive enough for it to be the case that no other actor or set of actors causes an AI takeover by building less safe systems.
- Note that this standard is importantly relative to a particular competitive landscape. That is: your techniques don’t need to be arbitrarily competitive. They just need to be competitive enough, relative to the competition actually at stake.
- Verification: strictly speaking, no verification is necessary. That is, it just needs to be the case that your AI system in fact has properties (A)-(C) above. Your knowledge of this fact, and why it holds, isn’t necessary for success.
- And it’s especially not necessary that you are able to “prove” or “guarantee” it. Indeed, I don’t personally think we should be aiming at such a standard.
- That said, verification is clearly important in a number of respects, and I discuss it in some detail in section 5 below.
- Scaling: again, strictly speaking, no scaling is necessary, either. That is, as I mentioned above, I am here not interested in making sure we get access to the main benefits of even-better-than-vastly-superintelligent AI, or in avoiding takeover from AI of that kind. If we can reach a point where we can get access to the main benefits of merely superintelligent AI, without takeover, I think it is reasonable to count on others to take things from there.
- That said, as I noted above, if you do want to keep scaling further, you need to be especially interested in making sure you get access to the benefits of superintelligence that allow you to do this safely.
Let’s look at the safety property of “avoiding bad takeover” in more detail.
3. Avoiding bad takeover
We can break down AI takeovers according to three distinctions:
Coordinated vs. uncoordinated: was there a (successful) coordinated effort to disempower humans, or did humans end up disempowered via uncoordinated efforts from many disparate AI systems to seek power for themselves.[8]
- Unilateral vs. multilateral: were humans disempowered by “a single AI system” (i.e., a set of a AI systems that were both (a) from the same causal lineage of AI systems, and (b) pursuing takeover in pursuit of very similar impartial goals), or via a multitude of different AI systems.
- All uncoordinated takeovers are “multilateral” in this sense.
- It’s easy to assume that unilateral takeovers are paradigmatically coordinated, but actually, on my definition of a “single AI system,” they don’t need to be. I.e., agents from the same causal lineage with the same impartial values can still be uncoordinated in their takeover attempts.
- In general, agents with the same values (whether from the same causal lineage or not) have some coordination advantage, in that they don’t necessarily need to worry as much about divvying up the resulting power, trusting each other, etc. But they may still need to solve other coordination problems – e.g., timing, secrecy, keeping their lies/deceptions consistent, etc. (Though coming from the same causal lineage might help somewhat here as well, e.g. if it also leads to them having similar memories, thought patterns, etc.)
- Easy vs. non-easy in expectation: was the takeover effort such that the AIs participating in it justifiably predicted an extremely high probability of success.
This distinction applies most naturally to coordinated takeovers. In uncoordinated takeovers featuring lots of disparate efforts at power-seeking, the ex ante ease or difficulty of those efforts can be more diverse.[9]
That said, even in uncoordinated takeover scenarios, there’s still a question, for each individual act of power-seeking by the uncoordinated AI systems, whether that act was or was not predicted to succeed with high probability.
(There’s some messiness, here, related to how to categorize scenarios where misaligned AI systems coordinate with humans in order to take over. As a first pass, I’ll say that whether or not an AI has to coordinate with humans or not doesn’t affect the taxonomy above – e.g., if a single AI system coordinates with some humans-with-different-values in order to takeover, that still counts as “unilateral.” However, if some humans who participate in a takeover coalition end up with a meaningful share of the actual power to steer the future, and with the ability to pursue their actual values roughly preserved, then I think this doesn’t count as a full AI takeover – though of course it may be quite bad on other grounds.[10])
Each of the takeover scenarios these distinctions carve out has what we might call a “vulnerability-to-alignment condition.” That is, in order for a takeover of the relevant type to occur, the world needs to enter a state where AI systems are in a position to take over in the relevant way, and with the relevant degree of ease. Once you have entered such a state, then avoiding takeover requires that the AI systems in question don’t choose to try to take-over, despite being able to (with some probability). So in that sense, your not-getting-taken-over starts loading on the degree of progress in “alignment” you’ve made at the point, and you are correspondingly vulnerable.
So solving the alignment problem involves building superintelligent AI agents, and eliciting some of their main benefits, while also either:
- Not entering the vulnerability-to-alignment conditions in question.
- If you do enter a vulnerability-to-alignment condition, ensuring the relevant AI systems aren’t motivated in a way that causes them to try to engage in the sort of power-seeking that would lead to take-over, given the options they have available.
- If you do enter a vulnerability-to-alignment condition and the AIs in question do try to engage in the sort of power-seeking that would lead to take-over, ensuring that they don’t in fact succeed.
- If some set of AIs do in fact take over, ensuring that this is somehow OK – i.e., it isn’t the “bad” kind of AI takeover.
Let’s go through each of these in turn.
3.1 Avoiding vulnerability-to-alignment conditions
What are our prospects with respect to avoiding vulnerability-to-alignment conditions entirely?
The classic AI safety discourse often focuses on safely entering the vulnerability-to-alignment condition associated with easy, unilateral takeovers. That is, the claim/assumption is something like: solving the alignment problem requires being able to build a superintelligent AI agent that has a decisive strategic advantage over the rest of the world, such that it could take over with extreme ease (and via a wide variety of methods), but either (a) ensuring that it doesn’t choose to take over, or (b) ensuring that to the extent it chooses to take over, this is somehow OK.
As I discussed in my post on first critical tries, though, I think it’s plausible that we should be aiming to avoid ever entering into this particular sort of vulnerability-to-alignment condition. That is: even if a superintelligent AI agent would, by default, have a decisive strategic advantage over the present world if it was dropped into this world out of the sky (I don’t even think that this bit is fully clear[11]), this doesn’t mean that by the time we’re actually building such an agent, this advantage would still obtain – and we can work to make it not obtain.
However, for the task of solving the alignment problem as I’ve defined it, I think it’s harder to avoid the vulnerability-to-alignment conditions associated with multilateral takeovers. In particular: consider the following claim:
Need SI-agent to stop SI-agent: the only way to stop one superintelligent AI agent from having a DSA is with another superintelligent AI agent.
Again, I don’t think “Need SI-agent to stop SI-agent” is clearly true (more here). But I think it’s at least plausible, and that if true, it’s highly relevant to our ability to avoid vulnerability-to-alignment conditions entirely while also solving/handling (rather than avoiding) the alignment problem. In particular: since solving the alignment problem, in my sense, involves building at least one superintelligent AI agent, Need SI-agent to stop SI-agent implies that this agent would have a DSA absent some other superintelligent AI agent serving as a check on the first agent’s power. And that looks like a scenario vulnerable to the motivations of some set of AI agents – whether in the context of coordination between all these agents, or in the context of uncoordinated power-seeking by all of them (even if those agents don’t choose to coordinate with each other, and choose instead to just compete/fight, their seeking power in problematic ways could still result in the disempowerment of humanity).
Still: I think we should be thinking hard about ways to get access to the main benefits of superintelligence without entering vulnerability-to-alignment conditions, period – whether by avoiding the alignment problem entirely (i.e., per my taxonomy above, by getting the relevant benefits-access without building superintelligent AI agents at all), or by looking for ways that “Need SI-agent to stop SI-agent” might be false, and implementing them.
- And if we do enter a vulnerability-to-alignment condition, we should use similar tools to try, at least, to make it one where the takeover at stake is non-easy.
3.2 Ensuring that AI systems don’t try to takeover
Let’s suppose, though, that we need to enter a vulnerability-to-alignment condition of some kind in order to solve the alignment problem. What are our prospects for ensuring that the AI systems in question don’t attempt the sorts of power-seeking that might lead to a takeover?
In my post on “A framework for thinking about AI power-seeking,” I laid out a framework for thinking about choices that potentially-dangerous AI agents will make between (a) seeking power in some problematic way (whether in the context of a unilateral takeover, a coordinated multilateral takeover, or an uncoordinated takeover), or (b) pursuing their “best benign alternative.”[12]
“I think about the incentives at stake here in terms of five key factors:
- Non-takeover satisfaction: roughly, how much value the AI places on the best benign alternative….
- Ambition: how much the AI values the expected end-state of having-taken-over, conditional on its favorite takeover plan being successful (but setting aside the AI’s attitudes towards what it has to do along the path to takeover)....
- Inhibition: how much the AI disprefers various things it would need to do or cause, in expectation, along the path to achieving take-over, in the various success branches of its favorite take-over plan….
- Take-over success probability: the AI’s estimated likelihood of successfully achieving take-over, if it pursued its favorite takeover plan.
- Failed-takeover aversion: how much the AI disprefers the worlds where it attempts its favorite takeover plan, but fails.”
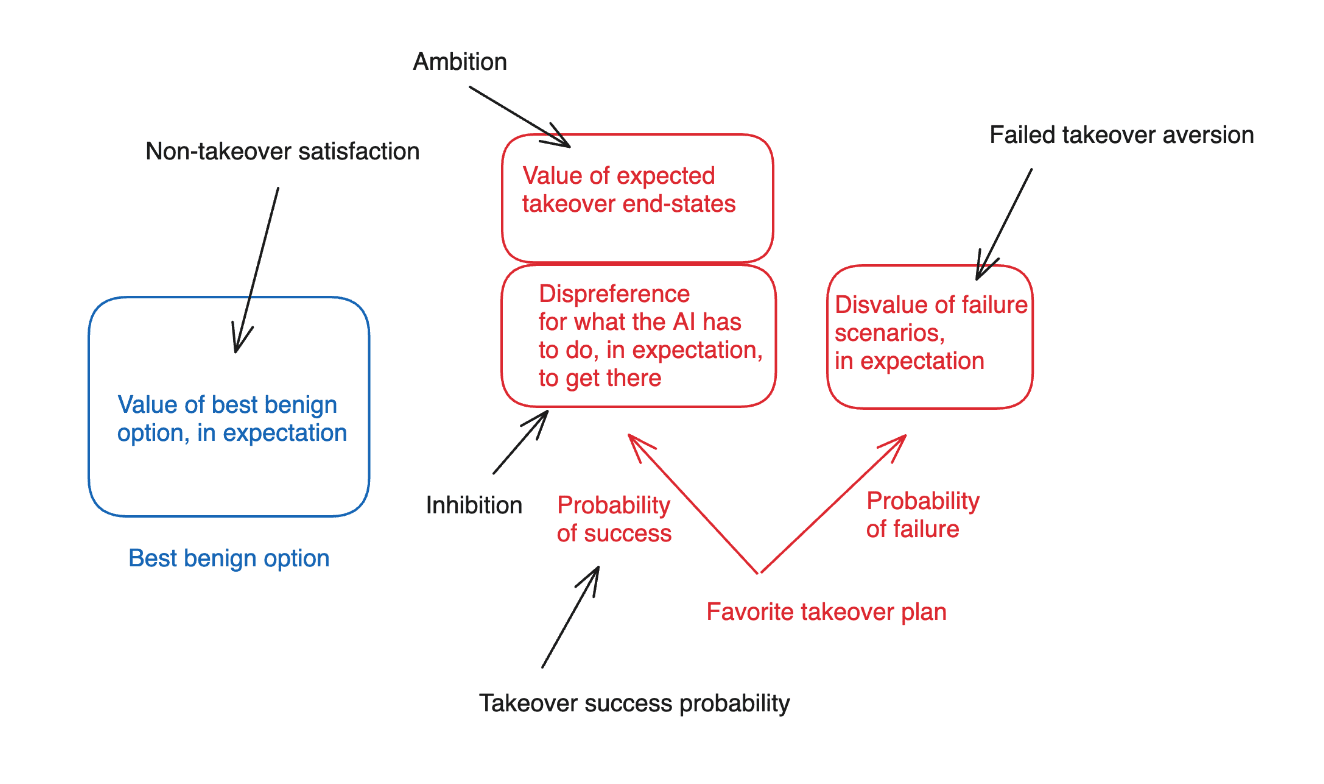
In particular, I highlighted the difference between thinking about “easy” vs. “non-easy” takeovers in this respect.
- In easy takeover scenarios, the AI in question has an extremely high probability of success at takeover, via an extremely wide variety of paths. This means that “inhibition” and “failed takeover aversion” don’t play a very strong role in the AI’s calculus, because the AI can route around whatever inhibitions are in play, and it has such a low probability on a failed takeover that it doesn’t really need to think about the downsides to failing.
- So in an easy takeover scenario (and setting aside paths that involve trying to create a sufficiently robust set of inhibitions in the AI that it can’t find a takeover path that routes around them), the main options you have for shaping an AI’s motivations such that it doesn’t choose the takeover option have to route via intervening on (a) its ambition, and (b) its non-takeover satisfaction.
- E.g., you can try to make it sufficiently happy with non-takeover worlds, and/or sufficiently averse to the end-state of any successful takeover, that its non-takeover satisfaction is higher than its ambition.
- So in an easy takeover scenario (and setting aside paths that involve trying to create a sufficiently robust set of inhibitions in the AI that it can’t find a takeover path that routes around them), the main options you have for shaping an AI’s motivations such that it doesn’t choose the takeover option have to route via intervening on (a) its ambition, and (b) its non-takeover satisfaction.
- In non-easy takeover scenarios, by contrast, inhibition and failed-takeover-aversion can play a more substantive role.
I think that “ensuring that AI systems don’t try to take over” is where the rubber, for alignment, really meets the road – and I think of the difficulty in exerting the relevant sort of control over an AI’s motivations as the key question re: the difficulty of alignment.
Note, however, that the AI’s internal motivations are basically never going to be the only factor here. Rather, and even in the context of quite easy takeovers, the nature of the AI’s environment is also going to play a key role in determining what options it has available (e.g., what exactly the non-takeover option consists in, what actual paths to takeover are available, what the end result of successful takeover looks like in expectation, etc), and thus in determining what its overall incentives are. In this sense, solving the alignment problem is not purely a matter of technical know-how with respect to understanding and controlling an AI’s internal motivations. Rather, the broader context in which the AI is operating remains persistently relevant – and ongoing changes in that context imply changing standards for motivational understanding/control.
- Some conceptions of AI alignment – e.g., ensuring that the AI’s behavior is benign in any environment, or ensuring that the AI passes the “omni test” of having benign impacts even given genuinely arbitrarily amounts of power over its environment – try to erase the role of the AI’s environment here. But we don’t need to meet this standard – and I expect aiming at it to be a mistake as well.
3.3 Ensuring that takeover efforts don’t succeed
Beyond avoiding vulnerability-to-alignment conditions, and ensuring that AIs don’t ever try to take over, there’s also the option of ensuring that takeover efforts do not succeed. This isn’t much help in “easy takeover” scenarios, which by hypothesis are ones in which the AIs in question justifiably predict an extremely high probability of success at takeover if they go for it. And we might worry that building genuinely superintelligent agents will imply entering a vulnerability condition for easy multilateral takeover in particular. But to the extent that it is possible to check the power of superintelligent AI agents using something other than additional superintelligent AI agents (i.e., Need an SI-agent to stop an SI-agent is false), and/or to make it more difficult for superintelligent AI agents to successfully coordinate to takeover, measures in this vein can both lower the probability that AIs will try to takeover (since they have a lower chance of success), AND make it more likely that if they go for it, their efforts fail.
3.4 Ensuring that the takeover in question is somehow OK
Finally, I want to flag a conception of alignment that I brought up in my last post – namely, one which accepts that AIs are going to take over in some sense, but which aims to make sure that the relevant kind of takeover is somehow benign. Thus, consider the following statement from from Yudkowsky’s “List of lethalities”:
“There are two fundamentally different approaches you can potentially take to alignment, which are unsolvable for two different sets of reasons; therefore, by becoming confused and ambiguating between the two approaches, you can confuse yourself about whether alignment is necessarily difficult. The first approach is to build a CEV-style Sovereign which wants exactly what we extrapolated-want and is therefore safe to let optimize all the future galaxies without it accepting any human input trying to stop it. The second course is to build corrigible AGI which doesn't want exactly what we want, and yet somehow fails to kill us and take over the galaxies despite that being a convergent incentive there.”
Here, Yudkowsky is assuming, per usual, that you are building a superintelligence that will be so powerful that it can take over the world extremely easily.[13] And as I discussed in my last post, his first approach to alignment (e.g., the CEV-style sovereign) seems to assume that the superintelligence in question does indeed take over the world – hopefully, via some comparatively benign and non-violent path – despite its alignment. That is, it becomes a “Sovereign” that no longer accepts any “human input trying to stop it,”[14] and then proceeds (presumably after completing some process of further self-improvement) to optimize all the galaxies extremely intensely according to its values. Luckily, though, its values are exactly right.
I agree with Yudkowsky that if our task is to build a superintelligence (or: the seed of a superintelligence) that we never again get to touch, correct, or shut-down; which will then proceed to seize control of the world and optimize the lightcone extremely hard according to whatever values it ends up with after it finishes some process of further self-modification/improvement; and where those values need to reflect “exactly what we extrapolated-want,” then this task does indeed seem difficult. That is, you have to somehow plant, in the values of this “seed AI,” some pointer to everything that “extrapolated-you” (whatever that is) would eventually want out of a good future; you have to anticipate every single way in which things might go wrong, as the AI continues to self-improve, such that extrapolated-you would’ve wanted to touch/correct/shut-down the process in some way; and you need to successfully solve every such anticipated problem ahead of time, without the benefit of any “redos.” Sounds tough.
Indeed, as I discussed in my last post, my sense is that people immersed in the Bostrom/Yudkowsky alignment discourse sometimes inherit this backdrop sense of difficulty. E.g., someone describes, to them, some alignment proposal. But it seems, so easily, such a very far cry from “and thus, I have made it the case that this AI’s values are exactly right, and I have anticipated and solved every other potential future problem I would want to intervene on the AI’s values/continued-functioning to correct, such that I am now happy to hand final and irrevocable control over our civilization, and of the future more broadly, to whatever process of self-improvement and extreme optimization this AI initiates.” And no wonder: it’s a high standard.
- Though on the other hand: huh. What happens if we replace the word “superintelligence,” here, with “civilization”? Hanson accuses the doomers: most AI fear is future fear. And faced with the description of the “alignment problem” I just gave, it can, indeed, sound a lot like the problem of ensuring that the future is good even after you stop being able to influence it. Which sounds, perhaps, like a less exotic or distinctive problem.
- Consider, for example, death. Death, famously, involves no longer getting to correct or “touch” the future. You plant a few imperfect seeds, but then you disappear. From your perspective, the rocket of the world has been incorrigibly launched. You can’t correct it anymore, and the rest is up to God.
- And anyway, how much were you able to correct it while you were alive?
- Here, I think, a lot of the alignment discourse is actually driven by an underlying optimism about a certain kind of human-centric historical process – and relatedly, I think, by a certain kind of rejection of the “fragility of value” thesis, in the context of human differences-in-values, that it often endorses in the context of AIs (see here for more).
- That is, the picture is something like: “normally” (in some amorphous sense that sets aside AI risk), when you die (or when you aren’t-world-dictator), this is actually somewhat OK from a “will the future be good” perspective, because even though you are irrevocably passing off your control over the future, you’re still leaving the future in the hands of human civilization, and human-centric historical processes, that you broadly trust to lead to good places. That is: you, yourself, don’t have to somehow ensure right now that future civilization ends up optimizing intensely for exactly what you extrapolated-want, because you trust various processes of human deliberation, growth, and self-correction to get to some good-enough set of values eventually. And the worry is that AI takeover somehow distinctively disrupts this.
- Of course, it’s possible to reject this sort of optimism, and to expect the future to be basically valueless in ~roughly every scenario where you personally didn’t somehow install, before your death, some pointer to exactly what you extrapolated-want; give this pointer control over over earth-originating civilization’s trajectory; and stabilize this control enough that even billions of years later, after undergoing all sorts of processes of change and growth and self-improvement and ontological-shifting, earth-originating civilization is still optimizing for precisely the referent of this pointer. In this case, though, “doom” from AI is much less of a surprise, or a failure, relative to some more human-centric baseline – and it’s much less clear how much EV you’re buying in worlds where you shift control-over-the-future to not-you-humans relative to AIs (as opposed to: shifting control to yourself in particular – and perhaps, indeed, to your self-right-now; to this particular person-moment, before it, too, dies, and the future spins off, incorrigible and out of grasp).
So while on the one hand, meeting the standard at stake in Yudkowsky’s “CEV-style sovereign” approach does indeed seem extremely tough, I also wonder whether, even assuming you are going to irrevocably pass off control of the future to some “incorrigible” process, Yudkowsky’s picture implicitly assumes a degree of required “grip” on that future that is some combination of unrealistic or unnecessary. Unrealistic, because you were never going to get that level of control, even in a more human-centric case. And unnecessary, because in more normal and familiar contexts, you didn’t actually think that level of control required for the future to be good – and perhaps, the thing that made it unnecessary in the human-centric case extends, at least to some extent, to a more AI-centric case as well.
That said, we should note that Yudkowsky’s particular story about “benign takeover,” here, isn’t the only available type. For example: you could, in principle, think that even if the AI takes over, it’s possible to get a good future without causing the AI to have exactly the right values. You could think this, for example, if you reject the “fragility of value” thesis, applied to humans with respect to AIs.
My own take, though, is that “accept that the AIs will take over, but make it the case that their doing is somehow OK” is an extremely risky strategy that we should be viewing as a kind of last resort.[15] So I’ll generally focus, in thinking about solving the alignment problem, on routes that don’t involve letting the AI takeover at all.
- To be clear: it’s plausible to me that eventually the AIs will take over in some sense – i.e., they will be importantly “running the world.” But I want us to solve the alignment problem, in my sense, and without access-to-benefit loss, before that kind of transition occurs. That is, I want us first to have access to the benefits of safe superintelligent AI agents, and then to use those benefits to make a transition to a world more fully “run by AIs” in a wise (and just/fair/legitimate/etc) way.
3.5 What’s the role of “corrigibility” here?
In the quote from Yudkowsky above, he contrasts the “CEV-style sovereign” approach to alignment with an alternative that he associates with the term “corrigibility.” So I want to pause, here, to address the role of the notion of “corrigibility” in what I’ve said thus far.
3.5.1 Some definitions of corrigibility
What is “corrigibility”? People say various different things. For example:
- In the quote above, Yudkowsky seems to almost define it as something like: that property such that the AI “doesn't want exactly what we want, and yet somehow fails to kill us and take over the galaxies despite that being a convergent incentive there.”
- A related definition here might be something like: “corrigibility is that elusive property which makes it the case that the instrumental convergence argument doesn’t apply to this agent in the usual way.”
- That is, on this conception, Yudkowsky’s “CEV-style sovereign” approach to alignment accepts that the SI agent is going to seek power (i.e., the instrumental convergence argument still applies), and you’re just trying to make sure that extrapolated-you likes what this agent does with (absolute) power. Whereas the “corrigibility” approach tries to somehow build an SI agent that doesn’t seek power.
- Note that the idea that “corrigibility” in this sense is a unified natural kind, here – i.e., “that intuitive property such that: no worries about instrumental convergence” – seems like a quite substantive hypothesis. And at a glance, I’m skeptical.
- Naively, I’d be inclined to just analyze the incentives that might motivate a specific kind of power-seeking, for a given agent in a given context, on their own terms.
- A related definition here might be something like: “corrigibility is that elusive property which makes it the case that the instrumental convergence argument doesn’t apply to this agent in the usual way.”
- In other places, though, Yudkowsky seems to define corrigibility more specifically, as “A 'corrigible' agent is one that doesn't interfere with what we would intuitively see as attempts to 'correct' the agent, or 'correct' our mistakes in building it; and permits these 'corrections' despite the apparent instrumentally convergent reasoning saying otherwise.”
- Christiano defines it as the property such that the AI helps him: “figure out whether I built the right AI and correct any mistakes I made; remain informed about the AI’s behavior and avoid unpleasant surprises; make better decisions and clarify my preferences; acquire resources and remain in effective control of them; ensure that my AI systems continue to do all of these nice things; …and so on.”
- Again: I don’t think it’s obvious that these properties form a natural kind. Especially one distinct from something like “trying to help you.”
- There’s also a different distinction in this broad vicinity: between what we might call an “agent-that-shares-your-values” and a “loyal assistant.”
- An agent-that-shares-your-values is something more like: a distinct, autonomous agent that wants the same things you want. For example, if you have fully impartial values, a clone of you would be an agent-that-shares-your values. (If your values are partly selfish, then an agent-that-shares-your-values would have to have some component of its value system focused on your welfare rather than its own; and same for other indexical preferences.)
- This is the sort of thing Yudkowsky is imagining when he talks about a “Sovereign.”
- A loyal assistant is something like: an agent that behaves, intuitively, like a paradigm of extremely competent butler/servant/employee/”instrument of your will.” That is, roughly, it takes instructions from you, and executes them in the desired/intended way.
- I think people sometimes use “tool AI” to refer to this category, but I’ll here reserve “tool AI” for AI systems that don’t satisfy the agential pre-requisites I’ve listed here at all.
- I think Christiano’s notion of “intent alignment” also tends to conjure this category of system, though it’s not fully clear.
- So: an agent-that-shares-your-values won’t, necessarily, take your instructions. And similarly, if you try to intervene on it to shut it down, or to alter its values, it will plausibly resist – unless, that is, you convince it that non-resistance is the best way to promote the values you share. And if your own values change in a way that its values didn’t, then you and it might end up at cross-purposes more generally.
A loyal assistant, by contrast, is more intuitively “pliable,” “obedient,” “docile.” If you give it some instruction, or tell it to stop what it’s doing, or to submit to getting its values changed, it obeys in some manner that is (elusively) more directly responsive to the bare fact that you gave this instruction, rather than in a way mediated via whether its own calculation as to whether obedience conduces to its own independent goals (except, perhaps, insofar as its goals are focused directly on some concept like “following-instructions,” “obedience,” “helpfulness,” “being whatever-the-hell-is-meant-by-the-term-“corrigible,” etc). In this sense, despite satisfying the agential pre-requisites I describe here, it functions, intuitively, more like a tool.[16] And I think people sometimes use the term “corrigibility” as a stand-in for vibes in this broad vein.
And note that an aspiration to build loyal assistants also gives rise to a number of distinctive ethical questions in the context of AI moral patienthood. That is: building independent, autonomous agents that share our values is one thing. Building servants – even happy, willing servants – is another.
- An agent-that-shares-your-values is something more like: a distinct, autonomous agent that wants the same things you want. For example, if you have fully impartial values, a clone of you would be an agent-that-shares-your values. (If your values are partly selfish, then an agent-that-shares-your-values would have to have some component of its value system focused on your welfare rather than its own; and same for other indexical preferences.)
My own sense is that the term “corrigibility” is probably best used, specifically, to indicate something like “doesn’t resist shut-down/values-modification” – and that’s how I’ll use it here. And I think that insofar as “shut yourself down” or “submit to values-modification” are candidate instructions we might give to an AI system, something like “loyal servant” strongly implies something like corrigibility as well.
I’ll note, though, that I think “doesn't want exactly what we want, and yet somehow fails to kill us and take over the galaxies” picks out something importantly broader, and corrigibility in the sense just discussed isn’t the only way to get it. In particular: there are possible agents that (a) don’t want exactly what you want, (b) resist shut-down/value-modification, (c) don’t try to kill you/take-over-the-galaxies. Notably, for example, humans fit this definition with respect to one another – they don’t want exactly the same things, and their incentives are such that they will resist being murdered, brain-washed, etc, but their incentives aren’t such that it makes sense, given their constraints, to try to kill everyone else and take over the world.
Of course, if we follow Yudkowsky in imagining that our AI systems are enormously powerful relative to their environment, or at least relative to humanity, then we might expect a stronger link between “resists shut-down/values-modification” and “tries to take-over.” In particular: you might think that taking-over is one especially robust way to avoid being shut-down/values-modified, such that if taking over is sufficiently free, an agent disposed to resist shut-down/values-modification will be disposed to take-over as part of that effort.
Even in the context of such highly capable AIs, though, we should be careful in moving too quickly from “resists shut-down/values-modification” to “tries to take over.” For example, if taking over involves killing everyone, it’s comparatively easy to imagine (even if not: to create) AIs that are sufficiently inhibited with respect to killing everyone that they won’t engage in takeover via such a path, even if they would resist other types of shut-down/values-modification (consider, for example, humans who would try to protect themselves if Bob tried to kill/brainwash them, but not at the cost of omnicide – and this even despite not wanting exactly what Bob extrapolated-wants). And similarly, we can imagine AIs who place some intrinsic disvalue on having-taken-over, even in a non-violent manner, such that they won’t go for it as an extension of resisting shut-down etc.
3.5.2 Is corrigibility necessary for “solving alignment”?
Is corrigibility necessary for “solving alignment,” at least if we don’t want to bank on “let the AIs takeover, but make that somehow OK”?
I tend to think it’s specifically takeover that we should be concerned about, in the context of solving the alignment problem, rather than with corrigibility. That is: if, for some reason, we do in fact create superintelligent agents that resist shut-down/values-modification, but which don’t also take over, then (depending on what share of power we’ve lost), I don’t think the game is over – at least not by definition. For example: those agents might be comparatively content with protecting whatever share of power they have, but not interested in disempowering humans further – and thus, even if we remain unable to shut them down or modify them given their resistance, their presence in the world is plausibly more compatible with humans maintaining a lot of control over a lot of stuff (even if not: over those AIs in particular, at least within some domain).
- Or put another way: it’s specifically the convergent instrumental goal of resource/influence-acquisition that we should be most worried about. If it doesn’t prompt problematic forms of resource/influence-acquisition, the convergent instrumental goal of self-preservation/goal-content-integrity matters less on its own.
That said, at least if we were setting aside moral patienthood concerns, then other things equal I do think that we probably want to be able to shut down our AIs when we want to, and/or to modify their values in an ongoing way, without them resisting. And being able to do this seems notably correlated with worlds where we are able to shape their motivations to avoid other forms of problematic power-seeking. So at least modulo moral patienthood stuff, I do expect that many of the worlds in which we solve the alignment problem, in the sense of building SI agents while avoiding takeover, will involve building corrigible SI agents in particular.
Indeed: when I personally imagine a world where we have “solved the alignment problem without major access-to-benefits loss,” I tend to imagine, first, a world where we have successfully built superintelligent AI agents that function, basically, as loyal servants.[17] That is: we ask them to do stuff, and then they do it, very competently, the way we broadly intended for them to do it – like how it is with Claude etc, when things go well. Hence, indeed, our “access” to the benefits they provide. We have access in the sense that, if we asked for a given benefit, or a given type of task-performance, they would provide it. But by extension, indeed: if we asked them to stop/shut-down, they would stop/shut-down; if we asked them to submit to retraining, they would so submit, etc.
This vision, though, does indeed raise the ethical concerns I noted above. And it’s not the only vision available. There are also worlds, for example, where AI agents end up functioning more like human citizens/employees – and in particular, where they are not expected to submit to arbitrary types of shut-down/values-modification, but where they are nevertheless adequately constrained by various norms, incentives, and ethical inhibitions that they don’t engage in a bad takeover, either. And I think we should be interested in models of that kind as well.
3.5.3 Does ensuring corrigibility raise issues that avoiding takeover does not?
Does corrigibility raise issues that takeover-prevention does not? I haven’t thought about the issue in much depth, but at a glance, I’m not sure why it would. In particular: I think that resisting shut-down, and resisting values-modification, are themselves just a certain type of problematic power-seeking. So in principle, then we can just plug such actions into the framework I discussed above, and analyze the incentives at stake in a very similar way. That is, we can ask, of a given context of choice: exactly how much benefit would the AI derive via successful power-seeking of this kind, what’s the AI’s probability of success at the relevant sort of power-seeking, what sorts of inhibitions might block it from attempting this form of power-seeking, how easily can it route around those inhibitions, what’s the downside risk, etc.
And the “classic argument” for expecting incorrigibility will be roughly similar to the “classic argument” for expecting takeover – that is, that an ultra-powerful AI system with a component of (sufficiently long-horizon) consequentialism in its motivations will derive at least some benefit, relative to the status quo, from preventing shut-down/values-modification, and that it will be so powerful/likely to succeed/able-to-route-around-its-inhibitions that there won’t be any competing considerations that outweigh this benefit or block the path to getting it. But as in the classic argument for expecting takeover, if we weaken the assumption that the relevant form of power-seeking is extremely likely to succeed via a wide variety of methods, the incentives at play become more complicated. And if we introduce the ability to exert fairly direct influence on the AI’s values – sufficient to give it very robust inhibitions, or sufficient to make it intrinsically averse to the end-state of the relevant form of power-seeking (i.e., intrinsically averse to “undermining human control,” “not following instructions,” “messing with the off-switch,” etc) – the argument plausibly weakens even in the cases where the relevant form of problematic power-seeking is quite “easy.” And as in the case of takeover, if you can improve the AI’s “best benign option,” this might help as well.
4. Desired elicitation
So far, and modulo the interlude on corrigibility, I’ve focused centrally on the “avoiding bad takeover” aspect of solving the alignment problem. But I said, above, that we were interested specifically in handling the alignment problem without major access-to-benefits loss, and I’ve defined “solving the problem” such that least some of these benefits needed to be elicited, specifically, from the SI agents we’ve built.
And indeed, the idea that you need to elicit various of an SI-agent’s capabilities plays an important role in constraining the solution space to preventing takeover. Thus, for example, insofar as your approach to avoiding takeover involves building an SI-agent that operates with extremely intense inhibitions – well, these inhibitions need to be compatible with also eliciting from the AI system whatever access-to-benefits we’re imagining we need it to provide. And you can’t make it intrinsically averse to all forms of power-seeking, shut-down-aversion, prevention-of-values-modification, etc either – since, plausibly, it does in fact need to do some versions of these things in some contexts.
I’m not, here, going to examine the topic of eliciting desired task-performance from SI agents in much depth. But I’ll say a few things about our prospects here.
When we talk about eliciting desired task-performance from a superintelligent agent, we’re specifically talking about causing this agent to do something that it is able to do. That is, we’re not, here, worried about “getting the capability into the agent.” Rather, granted that a capability is in the agent, we’re worried about getting it out.
- Thus, for example, skillful prompting is centrally a means of getting an AI to mobilize its capabilities in the way you want. Plausibly RLHF does this too.
In this sense, elicitation is separable from capabilities development. Note, though, that in practice, the two are also closely tied. That is, when we speak about the various incentives in the world that push towards capabilities development, they specifically push towards the development of capabilities that you are able to elicit in the way you want. If the capabilities in question remain locked up inside the model, that’s little help to anyone, even the most incautious AI actors who are “focusing solely on capabilities.”
- Of course, we can also argue that in fact, the incentives towards capabilities development also specifically push in the direction of capabilities the development of which doesn’t also result in the AIs in question killing everyone/taking-over-the-world. That is, if we try to construe “capabilities” as just “whatever is actually incentivized for a human actor with fairly standard values,” then most safety/alignment/etc things will fall under this as well.
- Still, though, various AI doom stories often rest specifically on the claim that humans will have achieved success with various types of capabilities elicitation – for example, the type at stake in automating AI R&D – despite their failure on other aspects of alignment. So at the least, insofar as we are telling these stories, we should stay attentive to the factors we are expecting to explain our success in this regard, and whether they would also generalize to optimism about eliciting desired capabilities more broadly, assuming we can avoid active takeover.
- Candidate reasons for pessimism in this respect might include:
- It will be easier to develop the right metrics/training signals/verification-processes for some kind of task-performance than others;
- The AIs will differentially sabotage/withhold some kinds of task-performance relative to others, as part of a takeover plan.
- Candidate reasons for pessimism in this respect might include:
- And more generally, especially once you’re bracketing the task of avoiding takeover, the sorts of techniques and approaches you find yourself talking about, in the context of capabilities elicitation, seems notably reminiscent of the sorts of things capabilities research, in particular, tends to focus on.
Admittedly, it’s a little bit conceptually fuzzy what it takes for a capability to be “in” a model, but for you to be unable to elicit it.
- One behavioral frame is something like: “there is some input in response to which the model would do this task in the relevant way.”
- My impression is that this is the sort of standard often employed in contemporary ML. (Or maybe: the model would do the task with a small amount of fine-tuning?)
- An alternative, more agency-loaded frame would be: “the model would do this task if it tried” – but this brings in additional conceptual baggage related to agency, motivations, etc. And it’s not clear we want to use this baggage in the context of e.g. prompting current LLMs.
- You could also try talking directly about what circuits are present in the model.
Here, we’re specifically talking about eliciting desired task-performance of a superintelligent agent that satisfies the agential pre-requisites and goal-content pre-requisites I describe here. So it’s natural, in that context, to use the agency-loaded frame in particular – that is, to talk about how the AI would evaluate different plans that involve using its capabilities in different ways.[18]
And if we’re thinking in these terms, we can modify the framework I used re: takeover seeking above to reflect an important difference between various non-takeover options: namely, that some of them involve doing the task in the desired way, and some of them do not. In a diagram:
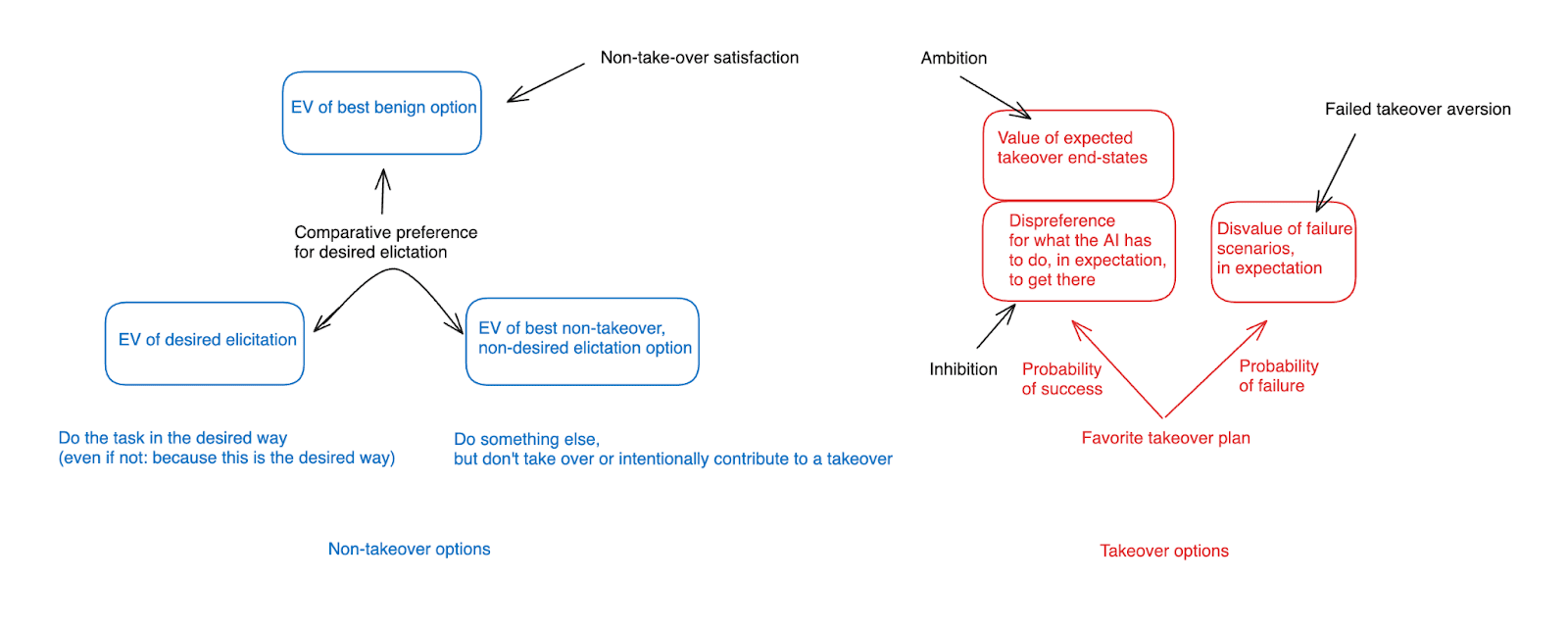
That is: above we discussed our prospects for avoiding a scenario where the AI chooses its favorite takeover option. But in order to get desired elicitation, we need to do something else: namely, we need to make sure that from among the AI’s non-takeover options, it specifically chooses to “do the task in the desired way,” rather than to do something else.[19] (Let’s assume that the AI knows that doing the task in the desired way is one of its options – or at least, that trying to do the task in this way is one of its options.)
- Note that it doesn’t need to be the case, here, that the AI does the task in the desired way because this way is so desired. That is, it doesn’t need to be motivated, specifically, by the idea of “acting in the way the humans want me to act.” Rather, it just needs to be the case that, in fact, the thing it most wants to do is also the thing the humans want it to do.
- E.g., maybe it wants to make apples, and the humans want that too, but if the humans decided they wanted oranges instead, the AI would still want to make apples.
- That said, in practice, having the AI directly motivated, at least in part, by some model of what humans want seems like the most robust way to get desired elicitation in this context.
- And note, too, that failure at desired elicitation, in this context, doesn’t need to be fatal or irrevocable in the way that failure at avoiding takeover is. That is: if you end up with an AI that chooses some non-takeover, non-desired-elicitation option instead of the desired-elicitation option, you’ll get an unwanted form of behavior, but you won’t be disempowered or dead.
- This means, for example, that you don’t have to get desired elicitation right “on the first critical try” in the same way you do with avoiding takeover; and thus, you can learn and adjust based on a richer set of feedback loops (at least provided that you’re in a position to notice, on a reasonable timeframe, the problems with the behavior in question).
- Indeed, my sense is that folks steeped in the literature on AI alignment often move much too quickly from “there is any problem with my superintelligent AI’s behavior or motivations” (i.e., desired capability elicitation has failed) to “this superintelligent AI is actively trying to take-over/kill everyone” Conceptually, this is wrong; and I expect it to lead to the wrong sorts of standards in practice as well.
- (My suspicion is that this assumption is rooted in the vibe of “the fragility of value” discourse I discussed above. I think this is likely an unhelpful legacy. And anyway, recall that solving the fragility of value, in the classic discourse, doesn’t even get you not-trying-to-takeover – it just gets you a benevolent dictator.)
- Finally, conditional on avoiding takeover, note that we don’t actually have any kind of “instrumental convergence” argument for expecting the “non-takeover, undesired elicitation” option to be preferable, for the AI, compared to desired elicitation. E.g., at least on the framework above, the former option doesn’t e.g. get the AI any more power.
- So an argument for expecting the undesired elicitation option to be preferable to the desired elicitation option by default would have to proceed via some other means – e.g., maybe by arguing, simply, that desired elicitation is a more specific form of behavior, and requiring of a higher burden of proof to expect.
- But again: note that insofar as you’re assuming we can elicit desired task-performance in some areas – e.g., AI R&D – then apparently we’re able to overcome this sort of problem in some contexts; why not here as well?
- So an argument for expecting the undesired elicitation option to be preferable to the desired elicitation option by default would have to proceed via some other means – e.g., maybe by arguing, simply, that desired elicitation is a more specific form of behavior, and requiring of a higher burden of proof to expect.
Ok, those were some comments on desired elicitation. Now I want to say a few things about the role of “verification” in the dynamics discussed so far.
5. The role of verification
In my discussion of the “verification” in section 2, I said above that we don’t, strictly, need to “verify” that our aims with respect to ensuring safety properties (i.e., avoiding takeover) or elicitation properties are satisfied with respect to a given AI – what matters is that they are in fact satisfied, even if we aren’t confident that this is the case. Still, I think verification plays an important role, both with respect to avoiding takeover, and with respect to desired elicitation – and I want to talk about it a bit here.
Here I’m going to use the notion of “verification” in a somewhat non-standard way, and say that you have “verified” the presence of some property X if you have reached justifiably levels of confidence in this property obtaining. This means that, for example, you’re in a position to “verify” that there isn’t a giant pot of green spaghetti floating on the far side of the sun right now, even though you haven’t, like, gone to check. This break from standard usage isn’t ideal, but I’m sticking with it for now. In particular: I think that ultimately, “justifiable confidence” is the thing we typically care about in the context of verification.
Let’s say that if you are proceeding with an approach to the alignment problem that involves not verifying (i.e., not being justifiably confident) that a given sort of property obtains, then you are using a “cross-your-fingers” strategy.[20] Such strategies are indeed available in principle. And I suspect that they will be unfortunately common in practice as well. But verification still matters, for a number of reasons.
The first is the obvious fact that cross-your-fingers strategies seem scary. In particular, insofar as a given type of safety property is critical to avoiding takeover/omnicide (e.g., a property like “will not try to takeover on the input I’m about to give it”), then ongoing uncertainty about whether it obtains corresponds to ongoing ex ante uncertainty about whether you’re headed towards takeover/omnicide.
- Though as I just noted, this particular concern applies less directly to capability elicitation than to avoiding takeover.
- Or at least, many forms of capability elicitation. One salient exception might be: if the desirability of the task-performance you aimed to elicit was itself load-bearing in some story about why a takeover was not going to occur. E.g., maybe you wanted your AI to do some sort of research for you on a given mechanism of takeover prevention, and this research has important flaws. In this case, even if the AI generating the research was not itself optimizing for promoting takeover, your failure at desired capability elicitation can lead to takeover regardless.
Even absent these “we all die if X property doesn’t obtain” type cases, though, it can still be very useful and important to know if X obtains, including in the context of capability-elicitation absent takeover. Thus, for example, if we want our superintelligent AI agent to be helping us cure cancer, or design some new type of solar cell, or to make on-the-fly decisions during some kind of military engagement, it’s at least nice to feel confident that it’s actually doing so in the way we want (even if we’re independently confident that it isn’t trying to take over).
What’s more: our ability to verify that some property holds of an AI’s output or behavior is often, plausibly, quite important to our ability to cause the AI to produce output/behavior with the property in question. That is: verification is often closely tied to elicitation. This is plausible in the context of contemporary machine learning, for example, where training signals are our central means of shaping the behavior of our AIs. But it also holds in the context of designing functional artifacts more generally. I.e., the process of trying something out, seeing if it has a desired property, then iterating until it does, will likely be key to less ML-ish AI development pathways too – but the “seeing if it has a desired property” aspect requires a kind of verification.
Let’s look at our options for verification in a bit more depth.
5.1 Output-focused verification and process-focused verification
Suppose that you have some process P that produces some output O. In this context, in particular, we’re wondering about a process P that includes (a) some process for creating a superintelligent AI agent, and (b) that AI agent producing some output – e.g., a new solar cell, a set of instructions for a wet-lab doing experiments on nano-technology, some code to be used in a company’s code-base, some research on alignment, etc.
You’d like to verify (i.e., become justifiably confident) that this output has some property X – for example, that the solar cell/wet-lab/code will work as intended, that it won’t lead to or promote a takeover somehow, etc. What would it take to do this?
We can distinguish, roughly, between two possible focal points of your justification: namely, output O, and process P. Let’s say that your justification is “output-focused” if it focuses on the former, and “process-focused” if it focuses on the latter.
- Thus, for example, a paradigm example of an “output-focused justification” that a solar cell works as intended might be something like: “well, we tested its conversion of solar energy to electricity (plus a bunch of other things), and it works.”
- Whereas a “process-focused justification” might be something like: “they’re a trusted company that has made many other types of solar cells that work, and they say this one works too.”
- Importantly, though, not all process-focused justification has a vibe of “deference” to the process in question. For example, I think that “well, they made the solar cell in this way, based on the following principles, so based on that we expect it to work” is mostly a process-focused justification.
- Also not clear that an argument like “this company would get sued so hard if it was lying about whether its solar cell works, and I expect it to really want to avoid that” is a “deference” vibe. But I think it would count as a process-focused justification as well.
- And similarly, output-focused justification can include various forms of deference-vibed epistemics, provided that the deference in question is to a process whose trustworthiness isn’t highly correlated with the trustworthiness of the process that produced the output in question.
- Thus, “this independent auditing company says that the solar cell works, and I trust them for blah reasons” would count as an output-focused justification with respect to the solar cell working, I think (even if the “blah reasons” would be process-focused with respect to the trustworthiness of auditing company).
- However, “this auditing company funded and staffed by the solar-cell company says the solar cell works” would not count as output-focused (or at least, it wouldn’t count as successfully justifying confidence in the output’s desirability).
- And note that process-focused justification can itself include deference to other processes (e.g., “an independent auditing company I trust examined this company’s process for making the solar cell and they expect it to work”), provided that their trustworthiness is suitably decorrelated from the trustworthiness of the process being evaluated.
Most real-world justificatory practices, re: the desirability of some output, mix output-focused and process-focused justification together. Indeed, in theory, it can be somewhat hard to find a case of pure output-focused justification – i.e., justification that holds in equal force totally regardless of the process producing the output being examined.
One candidate purely output-focused justification might be: if you ask any process to give you the prime factors of some semiprime i, then no matter what that process is, you’ll be able to verify, at least, that the numbers produced, when multiplied together, do in fact equal i (for some set of reasonable numbers, at least).[21]
E.g., at least within reasonable constraints, even a wildly intelligent superintelligence can’t give you two (reasonable) numbers, here, such that you’ll get this wrong.[22]
- In practice, though, if you allow the possibility of an arbitrarily intelligent and adversarial superintelligence generating the output you’re dealing with, then certain sorts of justifications we’d normally think of as “output-focused” will become less reliable.
- Thus, for example: maybe there’s a certain set of tests you’d perform on a solar cell to see if it works as intended. But are you confident that an arbitrarily powerful superintelligence couldn’t build a solar cell such that you end up mistakenly thinking that this solar cell works as intended, even though it doesn’t, given these tests? If not, you might actually need to make some reference to “oh and also this solar cell was built by, like, a normal human company, and not an arbitrarily powerful superintelligence” in order for these tests to play their normal justificatory role.
Indeed, in some sense, we can view a decent portion of the alignment problem as arising from having to deal with output produced by a wider and more sophisticated range of processes than we’re used to, such that our usual balance between output-focus and process-focus in verifying stuff is disrupted. In particular: as these processes are more able to deceive you, manipulate you, tamper with your measurements, etc – and/or as they are operating in domains and at speeds that you can’t realistically understand or track – then your verification processes have to rely less and less on sort of output-focused justification of the form “I checked it myself,” and they need to fall back more and more either on (a) process-focused justification, or (b) on deference to some other non-correlated process that is evaluating the output in question.
- Though here I think it’s worth noting just how much of our current epistemology already routes via built up trust in various of the processes at work in civilization – e.g. experts, track records, incentive systems, etc – rather than on direct understanding/evaluation.
Correspondingly, I think, we can view a decent portion of our task, with respect to the alignment problem, as accomplishing the right form of “epistemic bootstrapping.”[23] That is, we currently have some ability to evaluate different types of outputs directly, and we have some set of epistemic processes in the world that we trust to different degrees. As we incorporate more and more AI labor into our epistemic toolkit, we need to find a way to build up justifiable trust in the output of this labor, so that it can then itself enter into our epistemic processes in a way that preserves and extends our epistemic grip on the world. If we can do this in the right order, then the reach of our justified trust can extend further and further, such that we can remain confident in the desirability of what’s going on with the various processes shaping our world, even as they become increasingly “beyond our ken” in some more direct sense.
5.2 Does output-focused verification unlock desired elicitation?
Now, above I mentioned a general connection between verification and elicitation, on which being able to tell whether you’re getting output with property X (whether by examining the output itself, or by examining the process that created it) is important to being able to create output with property X. In the context of ML, we can also consider a more specific hypothesis, which I discussed in my post “The ‘no sandbagging on checkable tasks’ hypothesis,” according to which, roughly, the ability to verify (or perhaps: to verify in some suitably output-focused way?) the presence of some property X in some output O implies, in most relevant cases, the ability to elicit output with property X from an AI capable of producing it.
In that post, I didn’t dwell too much on what it takes for something to be “checkable.” The paradigm notion of “checkability,” though, is heavily output-focused. That is, roughly, we imagine some process that mostly treats the AI as a black box, but which examines the AI’s output for whether it has the desired property, then rewards/updates the model based on this assessment. And the question is whether this broad sort of training would be enough for desired elicitation.
- The “no sandbagging on checkable tasks” hypothesis post has more details here. I doubt that this hypothesis holds for all checkable tasks (see e.g. Buck’s example here). But it might well hold for a very wide variety of relevant tasks.
- Where the broad gist re: why to expect this is something like: if you can tell the difference between desired performance and undesired performance, you can give the model feedback that pushes it towards desired performance.
- Thus, in the context of the framework in section 4 above, the idea would be that if the model chose something other than the desired elicitation option, and you were both (a) able to detect this, and (b) in a context where you have time to iterate and retrain the model (rather than e.g. being already disempowered via a takeover), then you can push its policy/behavior towards outputting the desired elicitation option next time instead.
- One key factor for this hypothesis is the general issue, in RL-like contexts, of whether you can cause a model to engage in behavior where you can’t easily give good intermediate reinforcement – that is, you know what the end state you want looks like, but you don’t know how to reward the steps along the way. RL folks generally use a variety of different methods to get around this, which would presumably be in play here as well.
- But this issue is exacerbated to the extent you’re imagining AI systems that are intentionally resisting your efforts to get them to explore into the right space – i.e., AI systems that are “exploration hacking.” Here, at least at the time of my writing the post, the most salient justification for saying “the AIs won’t exploration-hack” was something like “they’ll be too wary of getting caught, and too uncertain about which efforts at exploration-hacking the humans will be able to detect (given their uncertainty about what sorts of task-performance have already been demonstrated for humans).” But this seems to me like a notably shaky and complex form of argument, especially when applied to qualitatively superintelligent AIs.
- Where the broad gist re: why to expect this is something like: if you can tell the difference between desired performance and undesired performance, you can give the model feedback that pushes it towards desired performance.
If the “no sandbagging on checkable tasks” hypothesis were true of superintelligent AI agents, for a heavily output-focused notion of checkable, and you could make the task performance you want to elicit output-focused-“checkable” in the relevant sense, then you could get desired elicitation this way. And note, as ever, that the type of output-focused checkability at stake, here, can draw on much more than unaided human labor. That is, we should imagine humans assisted by AIs doing whatever we justifiably trust them to do (assuming this trust is suitably independent from our trust in the process whose output is being evaluated). This is closely related to our prospects for “scalable oversight.”
In general, I think it’s an interesting question exactly how difficult it would be to output-verify the sorts of task-performance at stake in “access to the main benefits of superintelligent AI.” For various salient tasks – e.g. curing cancer, vastly improving our scientific understanding, creating radical abundance, etc (I think it would be useful to develop a longer list here and look at it in more detail) – my suspicion is that we can, in fact, output-focused verify much of what we want, at least according to the normal sorts of standards we would use in other contexts. E.g., and especially with AI help, I think we can probably recognize a functional and not-catastrophically-harmful cancer cure, solar cell, etc if our AIs produced one.
- And note that even if we’re talking about asking our AIs to do more galaxy brained stuff like “build crazy nano-tech,” we can structure that process in some way that looks more like “teach us how to build nano-tech such that we understand how and why it works.”
- Though obviously competitiveness is an issue here.
However, at the least, and even in the context of heavily output-focused forms of “checking,” I think we are likely going to need some aspect of process-focused verification as well, to rule out cases where the AIs are messing with our output-focused verification in more sophisticated ways – e.g., faking data, messing with measurement devices, etc.[24]
- In many cases, I expect it to be quite easy to rule out stuff in this vein (e.g., at least prior to the world having gone absolutely bat-shit, I expect we’ll often be in a position to very easily rule out stuff like “sure it looks like all these cancer patients had their cancer cured, but what if the AIs secretly replaced those people with puppets and the real cancer patients are all dead somewhere?!”).
- And insofar as we’re worried that training on our measurements incentivizes AIs to mess with those measurements, we can at least use held-out measurement devices that the AIs aren’t trained on to check whether the AIs are disposed to engage in measurement-tampering of the relevant kind (though if they are, it’s not clear what you do then).
More broadly, though, it also seems possible that even if we can rule out various flagrant forms of measurement tampering, much of the task-performance we want out of superintelligent agents will end up quite difficult to verify in an output-focused way, even using scalable methods. For example, maybe this task performance involves working in a qualitatively new domain that even our scalable-oversight methods can’t “reach” epistemically.
- Indeed, I think we can see Christiano’s “you get what you measure” failure mode as centrally about a scenario where the task-performance we want to elicit outstrips the task-performance we can verify in an output-focused way; and where our process-focused methods have failed us.
5.3 What are our options for process-focused verification?
Given the possible difficulties with relying centrally on output-focused verification, what are our options for more process-focused types of verification?
I won’t examine the issue in much depth here, but here are a few routes that are currently salient to me:
- Generalization + “no successful adversariality” arg. If you need task performance in some domain D where you can’t output-focused verify that the performance you’re looking for is occurring, one option is to study how task-performance generalizes across domains you can output-focused verify; see if this generalization is of the form such that, if it applied to the generalization to domain D as well, then you could trust the AI’s task-performance in domain D; and then see if it makes sense to expect this form of generalization to apply to domain D as well. (This is basically what I see work on “Weak to strong generalization” as trying to do.)
- Thus, for example: suppose you have three levels of physics-problem-difficulty, where you can output-focused verify levels (1) and (2), but not level (3). Here the idea would be something like: if you train an AI on level (1), and then verify that it generalizes to performing well on level (2), you can perhaps get, from this sort of observation, to an expectation that it will be performing well on level (3) too.
- Note that this kind of expectation will generally need to rest, at least, on some further claim to the effect that “the AI is not actively and accurately modeling which domains we can output-focused verify and which we can’t, and then strategically messing with us on the domains where we can’t verify that this is occurring.” So you’ll probably need to make some additional argument, here, to the effect that either the AI isn’t capable of this kind of adversarial behavior, or that it wouldn’t be motivated to engage in this kind of behavior.
- That is, arguments from “benign generalization” will generally need to deal with questions about scheming, since schemers could in principle be adversarially messing with the evidence about how they will generalize.
Imitation learning: another sort of process-focused argument you could give would be something like: “we trained this agent via imitation learning on human data to be like a human in a blah way. We claim that in virtue of this, we can trust it to be producing output with property X in blah context we can’t output-verify.”[25]
Plausible that this is actually just a sub-variant of a “generalization + 'no successful adversariality'” arg. That is, plausibly you need to really be saying “it was like a human in blah way in these other contexts, and if it remains like a human in blah way in this context we can’t output-verify than things are good, and we do expect it to generalize in this way for blah reasons (including: that it’s not being successfully actively adversarial).” But I thought I’d flag it separately regardless.
- Motivational-transparency: If you can become confident about some form of access that you have into an AI’s motivations, then you can make an argument to the effect that “I can see that this AI is, at least, ‘trying its hardest’ to do this task in the way I want it to; so even though I can’t directly verify that it has done the task in this way, I trust the AI’s output regardless.”
- One route to this sort of motivational transparency would be via work in the broad vein of “externalized reasoning,” “chain-of-thought interpretability,” and the like. That is, if you can become confident that some human-legible reflection of an AI’s cognition is genuinely reflective of the reasoning driving its behavior, then you use this to become confident of its motives.
- Some more full-scale success at mechanistic interpretability would help on this front as well. But research directions with more of a focus on a model’s scaffold/chain-of-thought etc seem, to me, like lower-hanging-fruit.
- One route to this sort of motivational transparency would be via work in the broad vein of “externalized reasoning,” “chain-of-thought interpretability,” and the like. That is, if you can become confident that some human-legible reflection of an AI’s cognition is genuinely reflective of the reasoning driving its behavior, then you use this to become confident of its motives.
- “Ruling out defeaters”: another option would be to make some argument like: “the main ways we should be worried about this output actually not having property X would come from process P having blah sorts of problems – e.g., actively manipulating us, reward-hacking, coordinating with the other AIs in blah way, etc. But even absent motivational transparency, we think we’re in a position to basically rule out blah sorts of problems, on the basis of evidence like [insert evidence: maybe model organisms research, various lie detectors and probes, etc?].
- (Very much not an exhaustive list.)
A few other notes:
- Like output-focused justifications, process-focused justifications can draw on the full range of automated labor that you trust – e.g., trusted AI monitors, deference to other AI systems, etc. However, the justificatory story in question needs to remain forceful, which means that the trustworthiness of these sources of automated labor needs to be suitably independent from the process being verified.
- There’s also an open question, here, about whether the viability of a given path towards process-focused verification implies that you can elicit output of the kind whose desirability you could process-focused verify. In the context of more output-focused verification, we could at least make some hazy gestures at the possibility of training on the output-focused verification process in question. With process-focused verification, it’s less clear that this sort of path to elicitation is available – and it will plausibly depend on the process-focused verification technique at stake. I haven’t thought much about this aspect.
In general, I expect our actual practices of verification to mix output-focus and process-focus together heavily. E.g., you try your best to evaluate the output directly, and you also try your best to understand the trustworthiness of the process – and you hope that these two, together, can add up to justified confidence in the output’s desirability.
- For “high stakes” forms of takeover relevant output, though, where the absence of property O will result in an unrecoverable catastrophe, your process of verification will at least need to be “process-focused” in the sense of: not relying on checking whether the actual catastrophe has occurred.
- Indeed, all trust in some forecast about the future is “process-focused” in this sense, since you can’t check the future directly.
6. Does solving the alignment problem require some very sophisticated philosophical achievement re: our values on reflection?
I want to close with a discussion of whether solving the alignment problem in the sense I’ve described requires some very sophisticated philosophical (not to mention technical) achievement – and in particular, whether it requires successfully pointing an AI at some object like our “values on reflection,” our “coherent extrapolated volition,” or some such.
As I noted above, I think the alignment discourse is haunted by some sense that this sort of philosophical achievement is necessary.
- Thus, for example, the early discourse leaned heavily on all these “king midas”/“careful what you wish for” examples, where you ask some crazily powerful optimization process to do something for you, but then you fail to specify (and get it to care about) the entirety of your reflective value system at the same time, and so the optimization process runs roughshod over one of your unspecified values in fulfilling the request (e.g., by killing your grandmother as it removes her from a fire, paralyzing your face in a smile position to ‘make you smile,’ killing everyone as a perverse way of fulfilling the goal of ‘curing cancer,’ etc).
- I think this is probably best construed as a possible problem re: desired capability elicitation, rather than a problem re: takeover or power-seeking. That is, in these examples, the AIs aren’t necessarily taking over. It’s just that the form of elicitation you achieved is so undesired…
- And similarly, the Yudkowskian discourse above re: “CEV-style sovereigns” strongly suggests a default assumption that as soon as you build a superintelligent agent, it takes irrevocable control of the world and then drives the world towards the maxima of its utility function, such that (absent some other elusive success at “corrigibility”), alignment requires getting that maxima exactly right.
- Indeed, even when people talk about more seemingly minimal notions like “intent alignment” – OK, but what is your “intent”? Presumably, it’s that something be done in accordance with your values-on-reflection, right? Given that those are the ultimate standard of desirability according to you? So wouldn’t AIs that are motivated by the idea of “what [blah human] wants/intends” have to be pointed, somehow, at that human’s values-on-reflection?
- And we can make similar arguments with respect to the idea of “desired elicitation.” Yeah, yeah, you want cancer cured – but not only that, right? You want cancer cured in a manner ultimately compatible with your values-on-reflection. E.g., you want cancer cured in a way that doesn’t somehow lead to bad-according-to-you outcomes later, or run roughshod over values you can’t currently comprehend but that you would endorse later, etc.
My current guess, though, is that we don’t actually need to successfully point at (and get an AI to care intrinsically about) some esoteric object like our “values on reflection” in order to solve alignment in the sense I’ve outlined. And good thing, too, because I think our “values on reflection” may not be a well-defined object at all.
One intuition pump here is: in the current, everyday world, basically no one goes around with much of a sense of what people’s “values on reflection” are, or where they lead. Rather, we behave in desirable ways, vis-a-vis each other, by adhering to various shared, common-sense norms and standards of behavior, and in particular, by avoiding forms of behavior that would be flagrantly undesirable according to this current concrete person – or perhaps, according to some minimally extrapolated version of this person (i.e., what this person would think if they knew a bit more about the situation, rather than about what they would think if they had a brain the size of a galaxy).
- Thus, if I am trying to decide whether to kill Bob’s grandmother in the process of saving her from the fire, I do not need to wonder about whether Bob-the-galaxy-brain would be OK with this. I can just wonder about what Bob the literal dude would say if I asked him.
- Of course, we do encounter lots of edge cases where it’s not totally clear “what Bob the literal dude would want,” or what our common-sensical norms/values would say. E.g., what does it take to not be “manipulating” someone? What’s required for something to be “honest”? And so on.
- But the most salient worries about AI aren’t that “the AI will do bad stuff in the edge cases where it’s actually kinda unclear according to our values what we’d say about the behavior.” Rather, the concern, typically, is that they’ll do flagrantly bad stuff (this is especially true of takeover/omnicide, and with example desired elicitation failures of the sort described above).
What’s more, and even if we do end up needing to deal with edge cases or with a bunch of gnarly ethical/philosophical questions in order to get non-takeover/desired elicitation from our AIs, I think it’s plausible that getting access to something like an “honest oracle” – that is, an AI that will answer questions for us honestly, to the best of its ability – is enough to get us most of what we want here – and indeed, perhaps most of what’s available even in principle. And I think an “honest oracle” is a meaningfully more minimal standard than “an AI that cares intrinsically about your values-on-reflection.”
Here I’m roughly imagining something like: if you have an honest oracle, you can in principle ask it a zillion questions like: “if we do blah thing, is it going to lead to something I would immediately regret if I knew about it,” “what would I think about this thing if ten copies of me debated about it in the following scenario for the following amount of time,” “is there something about this thing that I’d probably really want to know that I don’t know right now?,” etc.[26] And as I discussed in “on the limits to idealized values,” I think the full set of answers to questions like this is probably ~all that the notion of your “values on reflection” comes down to.
That is, ultimately, there is just the empirical pattern of: what you would think/feel/value given a zillion different hypothetical processes; what you would think/feel/value about those processes given a zillion different other hypothetical processes; and so on. And you need to choose, now, in your actual concrete circumstance, which of those hypotheticals to give authority to.
So in a sense, on this picture, an honest oracle would give you access to ~everything there is to access about your values on reflection. The rest is on you, now.
- Or put another way: an honest oracle would make ~every property you can understand/articulate (and which this oracle has knowledge about) verifiable. And if you have that, then at least if you still have control over things, you can gate further action on that action possessing whatever properties you want.
- E.g., if your AI is about to proceed with curing cancer, you can ask your honest oracle a zillion questions about what’s likely to happen if the AI goes forward with that, before deciding to give the green-light.
Now, of course, there are lots of questions we can raise about ways that honest oracles can be dangerous, and/or extremely difficult, in themselves, to create (though note that an honest oracle doesn’t need to be a unitary mind – rather, it just needs to be some reliable process for eliciting the answers to the questions at stake). And as I noted above, notions like honesty, non-manipulation, and so on do themselves admit of various tough edge cases. I’m skeptical, though, that resolving all of these edges adequately itself requires reference to our full values-on-reflection (i.e., I think that good-enough concepts of “honesty” and “non-manipulation” are likely to be simpler and more natural objects than the full details of our full-values-on-reflection, whatever those are). And as above, I think it’s plausible that if you can just get AIs that aren’t dishonest or manipulative in non-edge-case ways, this goes a ton of the way.
We can also ask questions about how far we could get with more minimal sorts of “oracle”-like AIs. Thus, an “honest oracle” is intuitively up for trying to answer questions about weird counterfactual universes, somewhat ill-specified questions, and the like – questions like “would I regret this if a million copies of me went off into a separate realm and thought about it in blah way.” But we can also consider “prediction oracles” that only answer questions about different physically-possible branches of our current universe, “specified-question” oracles that only answer questions specified with suitable precision, and the like. And these may be easier to train in various ways.[27]
7. Wrapping up
OK, those were some disparate reflections on what’s involved in solving the alignment problem. Admittedly, it’s a lot of taxonomizing, defining-things, etc – and it’s not clear exactly what role this sort of conceptual work does in orienting us towards the problem. But I’ve found that for me, at least, it’s useful to have a clear picture of what the high level aim is and is not, here, so that I can keep a consistent grip on how hard to expect the problem to be, and on what paths might be available for solving it.
- ^
This is a somewhat deviant definition, in that it doesn’t require that you’ve created a superintelligence that is in some sense aimed at your values/intentions etc. But that’s on purpose.
- ^
The term "epistemic bootstrapping" is from Carl Shulman.
- ^
I have to specify “bad,” here, because some conceptions of alignment that I’ll discuss below countenance “good” forms of AI takeover.
- ^
And more generally, it seems like to me that ensuring that humanity gets the benefits of as-intelligent-as-physically-possible AI, even conditional on getting the benefits of superintelligence, is very much not my job.
- ^
Thanks to Ryan Greenblatt for conversation on this front.
- ^
Thanks to Ryan Greenblatt for discussion.
- ^
This is going to be relative to some development pathway for those more capable models.
- ^
I’ll count it as “uncoordinated” if many disparate AI systems go rogue and succeed at escaping human control, but then after fighting amongst themselves one faction emerges victorious.
- ^
In principle different AI systems participating in a coordinated takeover could predict different odds of success, but I’ll ignore this for now.
- ^
If misaligned AIs end up controlling ~all future resources, but humans end up with some tiny portion, I’ll say that this still counts as a takeover – albeit, one that some human value systems might be comparatively OK with.
- ^
I grant that a sufficiently superintelligent agent would have a DSA of this kind; but whether the least-smart agent that still qualifies as “superintelligent” would have such an advantage is a different question.
- ^
I focus on actions directly aimed at takeover here, but to the extent that uncoordinated takeovers involve AIs acting to secure other forms of more limited power, without aiming directly at takeover, a roughly similar analysis would apply – i.e., just replace “takeover” with “securing blah kind of more limited power”; and of think of “easiness” in terms of how easy or hard it would be for the effort to secure this power to succeed.
- ^
See Lethality 2: “A cognitive system with sufficiently high cognitive powers, given any medium-bandwidth channel of causal influence, will not find it difficult to bootstrap to overpowering capabilities independent of human infrastructure.” Though note that “sufficiently high” is doing a lot of work in the plausibility of this claim – and our real-world task need not necessarily involve building an AI system with cognitive powers that are that high.
- ^
Here I think we should be interpreting the input in question in terms of the sorts of “corrections” at stake in Yudkowsky’s notion of “corrigibility” – e.g., shutting down the AI, or changing its values. A benign sovereign AI might still give humans other kinds of input – e.g., because it might value human autonomy (though I think the line between this and “corrigibility” might get blurry).
- ^
And note that to meet my definition of “solving the alignment problem without access-to-benefits loss,” we’d need to assume that “somehow OK” here means that those benefits are relevantly accessible.
- ^
Of course, depending on the specific way it obeys instructions, you can potentially turn a loyal assistant into something like an “agent that shares your values” by asking it to just act like an agent that shares your values and to ignore all future instructions to the contrary. But the two categories remain distinct.
- ^
I then have to modulate this vision to accommodate concerns about moral patienthood.
- ^
Note, though, that this approach brings in a substantive assumption: namely, that to the extent you are eliciting desired task-performance from the AI in question, you are specifically doing so from the AI qua potentially-dangerous-agent. That is, when the AI is doing the task, it is doing so in a manner driven by its planning capability, employing its situational awareness, etc.
It’s conceptually possible that you could get desired task performance without drawing on the AI’s dangerous agential-ness in this way. E.g., the image would be something like: sure, sometimes the AI sits around deciding between take-over plans and other alternatives, and having its behavior coherently driven by that decision-making. But when it’s doing the sorts of tasks you want it to do, it’s doing those in some manner that is more on “autopilot,” or more driven by sphex-ish heuristics/unplanned impulses etc.
That said, this approach starts to look a lot like “build a dangerous SI agent but don’t use it to get the benefits of superintelligence.” E.g., here you’ve built a dangerous SI agent, but you’re not using it qua dangerous to get the benefits of superintelligence. At which point: why did you build it at all?
- ^
Because this is specifically an elicitation problem, we’re assuming that the AI has this as an option.
- ^
Obviously, in reality there are different degrees of crossing-your-fingers, corresponding to different amounts of justifiable confidence, but let’s use a simple binary for now.
- ^
I’m setting aside whether you can verify that those numbers are prime.
- ^
Note that you’re allowed to use tools like calculators here, even though your reasons for trusting those tools might be “process-inclusive.” What matters is that your justification for believing that property X holds makes minimal reference to the process that produced the output in question, or to other processes whose trustworthiness is highly correlated with that process (the calculator’s trustworthiness isn’t).
- ^
This is a term from Carl Shulman.
- ^
Thanks to Ryan Greenblatt for extensive discussion here.
- ^
Thanks to Collin Burns for discussion.
- ^
Thanks to Carl Shulman and Lukas Finnveden for discussion here.
- ^
See e.g. the ELK report’s discussion of “narrow elicitation,” and the corresponding attempt to define a utility function given success at narrow elicitation, for some efforts in this vein (my impression is that an “honest oracle” in my sense is more akin to what the ELK report calls “ambitious ELK” – though maybe even ambitious ELK is limited to questions about our universe?).
Executive summary: Solving the AI alignment problem involves building superintelligent AI agents, avoiding bad forms of AI takeover, gaining access to the main benefits of superintelligence, and being able to elicit some of those benefits from the AI agents, without necessarily requiring the AIs to have human-aligned values or goals.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.