Comments
Catastrophic Risks from Unsafe AI: Navigating a Tightrope Scenario (Ben Garfinkel, EAG London 2023)

11 min readJun 2, 2023
19
Ben Garfinkel gave a talk at Effective Altruism Global: London in May 2023 about navigating risks from unsafe advanced AI. In this talk, he:
Ben framed the talk as being “unusually concrete” about framing threats from unsafe AI and recommendations for approaches to reduce risks. I (Alexander) found this very helpful and it gave me several tools for thinking about and discussing AI safety in a practical way[1], so I decided to write up Ben's talk.
The remainder of this article seeks to reproduce Ben’s talk as closely as possible. Ben looked over it quickly and judged it an essentially accurate summary, although it may diverge from his intended meaning or framing on some smaller points. He also gave permission to share the talk slides publicly ("Catastrophic Risks From Unsafe AI", Garfinkel, 2023). After publishing this article, a video of the talk was uploaded: "Catastrophic risks from unsafe AI".

One useful way of thinking about risks from advanced AI is to consider three different scenarios.
It is most worthwhile to focus on tightrope scenarios over bumper or shipwreck scenarios, because tightrope scenarios are the only ones in which we can influence the outcome. This holds true even if the probability of being in a tightrope scenario is unlikely (because you think it is very likely we are in a bumper or shipwreck scenario). This means being clear-eyed about the risks from advanced AI, and identifying & enacting strategies to address those risks so we can reach the other side of the chasm.
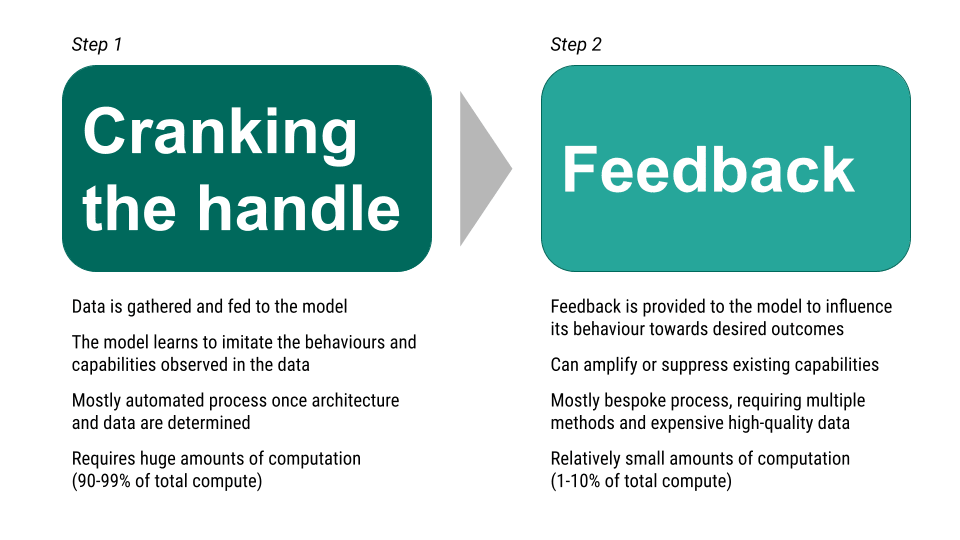
Here is a very simplified process for training an AI model[2], focused on large language models (LLM), because these are the models that in 2023 are demonstrating the most sophisticated capabilities. This simplified process can be useful to establish a shared language and understanding for different threats that can emerge, but it’s important to note that there are often several more steps (especially different kinds of feedback) in training an LLM, and other AI systems may be trained differently.
During Step 1, cranking the handle, the model trains on diverse data and can develop a wide range of capabilities and behaviours. However, the exact capabilities that emerge from this step can be unpredictable. That’s because the model learns to imitate behaviours and skills observed in the data, including those that were not intended or desired by the developers. For example, a model could manipulate people in conversation, write code to conduct cyber attacks, or provide advice on how to commit crimes or develop dangerous technologies.
The unpredictability of capabilities in AI models is a unique challenge that traditional software development does not face. In normal software, developers must explicitly program new capabilities, but with AI, new capabilities can emerge without developers intending or desiring them. As AI models become more powerful, it is more likely that dangerous capabilities will emerge. This is especially the case as systems are trained in such a way as to be able to perform increasingly long term, open-ended, autonomous, and interactive tasks, and their performance exceeds human performance in many domains.
Misalignment is when AI systems use their capabilities in ways that people do not want. Misalignment can happen by an AI model imitating harmful behaviours in the data it was trained on (Step 1). It can also happen through Step 2, Feedback, either straightforwardly (e.g., feedback makes harmful behaviours more likely, such as giving positive feedback to harmful behaviour), or through deceptive alignment. Deceptive alignment is where a model appears to improve its behaviour in response to feedback, but actually learns to hide its undesired behaviour and express it in other situations; this is especially possible in AI systems that are able to reason about whether they are being observed). It is also possible that we don’t understand why an AI exhibits certain behaviours or capabilities, which can mean that it uses those capabilities even when people don’t intend or desire it to do so.
Current AI models are relatively limited as they rely on short, user-driven interactions and are typically constrained to human skill levels. This may reduce the harmfulness of any behaviour exhibited by the model. However, as AI continues to develop and these limitations are addressed or removed, it is more likely that the effects of misalignment will be harmful.
Here’s a story to illustrate how dangerous capabilities and misalignment can combine in a way that can lead to catastrophe.
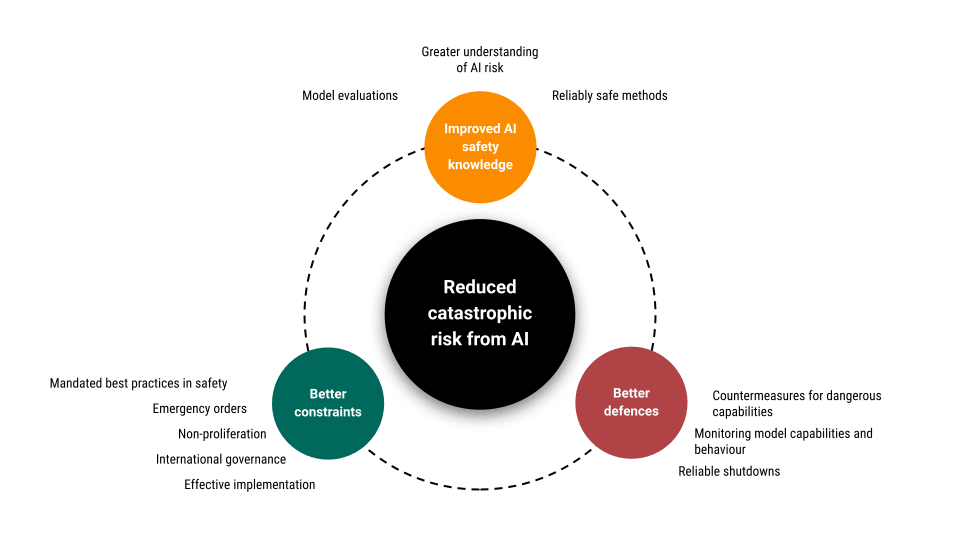
Three categories of approach were proposed that could be used to address risks from unsafe advanced AI: better AI safety knowledge, better defences against misaligned or misused AI with dangerous capabilities, and better constraints on the development and use of AI.
Over time, the risk from unsafe AI will increase with advancement in the capabilities of AI models. Simultaneously, improvements in AI safety knowledge, defences against misaligned or misused AI with dangerous capabilities, and constraints on the development and use of AI will also increase.
One toy model for thinking about this is a ‘risk curve’. According to this model, the pressures that increase and decrease risk will combine so that overall risk will increase to a peak, then return to baseline. A combination of safety approaches could “compress the curve”, meaning reducing the peak risk of the worst harms, and ensuring that the risk descends back towards baseline more quickly.
Compressing the curve can be done by reducing the time lag between when the risk emerges and when sufficient protections are established. It is unlikely that any one strategy is sufficient to solve AI safety. However, a portfolio of strategies can collectively provide more robust safeguards, buy time for more effective strategies, reduce future competitive pressures, or improve institutional competence in preparedness.
Testing and implementing strategies now can help to refine them and make them more effective in the future. For example, proposing safety standards and publicly reporting on companies’ adherence to those standards, even without state enforcement, could be a useful template for later adaptation and adoption by states; judicial precedents involving liability laws for harms caused by narrow AI systems could set an example for dealing with more severe harms from more advanced AI systems.
Approaches to address risks can trade off against each other. For instance, if safety knowledge and defences are well-progressed, stringent constraints may be less necessary to avoid the worst harms. Conversely, if one approach is lagging or found to be ineffective, others may need to be ramped up to compensate.
We could be in a “tightrope” scenario when it comes to catastrophic safety risk from AI. In this scenario, there is a meaningful risk that catastrophe could occur from advanced AI systems because of emergent dangerous capabilities and misalignment, if we do not act to prevent it. We should mostly act under the assumption we are in this scenario, regardless of its probability, because it’s the only scenario in which our actions matter.
Developing, testing, and improving approaches for reducing risks, including safety knowledge, defences, and constraints, may help us to walk the tightrope safely, reducing the impact and likelihood of catastrophic risk from advanced AI.
Ben Garfinkel wrote and delivered a talk titled Catastrophic Risks From Unsafe AI: Navigating the Situation We May or May Not Be In on 20 May 2023, at Effective Altruism Global: London.
I (Alexander Saeri) recorded audio and took photographs of some talk slides, and wrote the article from these recordings as well as an AI transcription of the audio.
I shared a draft of the article with Ben Garfinkel, who looked over it quickly and judged it an essentially accurate summary, while noting that it may diverge from his intended meaning or framing on some smaller points.
I used GPT-4 for copy-editing of text that I wrote, and also to summarise and discuss some themes from the transcription. However, all words in the article were written by me, with the original source being Ben Garfinkel.
For example, this approach doesn't focus on how far away Artificial General Intelligence may be (“timelines”), the likelihoods of different outcomes (“p(doom)”), or arbitrarily distinguish between technical alignment, policy, governance, and other approaches for improving safety. Instead, it focuses on describing concrete actions in many domains that can be taken to address risks of catastrophe from advanced AI systems.
An accessible but comprehensive introduction to how GPT-4 was trained, including 3 different versions of the Feedback step, is available as a 45 minute YouTube talk ("State of GPT", Karpathy, 2023 [alt link with transcript]).
You can also read a detailed forensic history of how GPT-3's capabilities evolved from the base 2020 model to the late-2022 ChatGPT model ("How does GPT Obtain its Ability? Tracing Emergent Abilities of Language Models to their Sources", Fu, 2022).


Great write-up. However, the approaches suggested here sound too timid to be effective. Thank you for creating this post.