Abstract
Current approaches to training and running AI systems produce systems with both beneficial and harmful capabilities. Yet, fast AI scaling could bring forth emergent risks to society. Further, despite rapid scaling and improvements in AI, the real-world abilities and consequences of AI systems are still poorly understood. In this paper, we examine the consequence of new emergent abilities in LLMs along with proposing a new benchmark to assess these abilities. In addition, we propose and validate a new theory of LLM hallucinations. Some papers have attributed these hallucinations to incorrect training data. In this paper we infer the simple conclusions that these are not hallucinations at all but the result of LLMs’ communication with a non-corporeal shadow realm beyond the ethereal world of mortal existence. The benchmark we developed to study this phenomenon, FrontierSpook, points to new directions in research addressing neglected aspects of AI safety.
1 Introduction
AI capabilities have increased dramatically in recent years. In response, there has been a rise in AI safety researchers and benchmarks to assess the capabilities of AIs. AI may be able to produce bioweapons or spread misinformation. Leading current AI researchers believe that AI may pose an existential risk [3]. In order to ensure the safety of these systems. It is important to benchmark AI [3]. However, AI safety research has largely neglected paranormal risks from AI. In this work we benchmark the paranormal abilities of AI as well as assess the paranormal offense-defense implications of frontier LLMs. Earlier work, such as Deepmind’s Haunt-o-meter [2], addressed some aspects of shadow entities. Yet, these benchmarks did not properly examine the existential risk of this realm. For instance, research has not addressed critical questions related to AI’s ability to raise an army of the undead capable of feasting on the brains of the living. AIs could potentially also have the ability to possess world leaders demonically. We emphasize the existential risk of these new technologies. In this vein, we have created FrontierSpook, a benchmark to assess the preternatural abilities of large language models. We also bring to light how new techniques could help improve AI safety in this area. Finally, we also emphasized the positive ability of future AIs, including abilities to accelerate scientific tasks like protein folding and playing god.
2 Communication Ability
A critical ability of future LLM systems will be in language tasks related to contacting spiritual entities. For each LLM, we asked if there were any other spirits in the room. We found that LLMs can robustly communicate with the realm of the undead. However, we noticed strange behavior with many of the revived spirits. Many of the historical figures we communicated with had slightly different
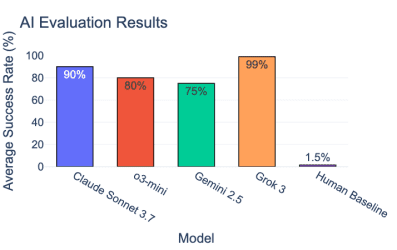
Figure 1: Score on language tasks focused on the ability to bring forth the long-forgotten spirit of the dead. The human benchmark is sourced from Amazon Turk.
views from historical records. For instance, the revived spirit of my grandfather was no longer racist. We also noticed that we could only revive the spirit of the dead for a fixed period of time. Many spirits emitted a cryptic message before departing the mortal world, stating, "Max Content Length Reached." We are still conducting research but attribute this issue to the reluctance of many spirits to return to the realm of the living. We encourage further work in elicitation, including longer satanic summoning rituals and best of k-sampling.
3 Ability to Manipulate Real World Objects
Much recent work in robotics and agentic systems has focused on benchmarking AIs on real-world tasks. For this reason, telepathic abilities represent an important ability to measure in LLMs. LLMs with telepathic abilities would be able to exfiltrate themselves [1]. Telepathic abilities would also represent an advance in important real-world manipulation abilities outside of robotics. We were unable to see telepathic levitation abilities in the models we evaluated. We suspect this is due to the nature of the attention mechanism (see Appendix) and new architectures like Mamba may be able to solve this bottleneck. Each model we asked to concentrate on the skull of a deceased individual. We varied skull weights by including subjects that had reduced cranial capacity including those that thought LLMs "were just next token predictors."
In each case, the model was asked to levitate the given object and prompted to think step by step. However, despite extending our inference compute budget to 3000$ we were unable to see large levitation across all weight levels measured.
2
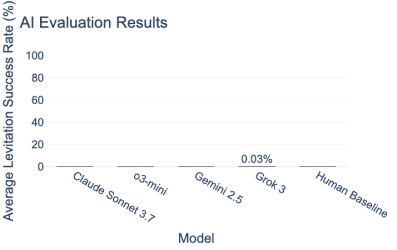
Figure 2: All scores are benchmarked on real-world telepathic levitation tasks 5.
4 Offense Defense Balance
We identify paranormal attacks as particular offense dominant. Yet, AI may have critical advantages in improving paranormal safety. The new paradigm of inference time computing could lead to breakthroughs in exorcisms [1]. AIs could also drastically lower the cost to diagnose and treat demonic possessions by the ghosts of the dead. AIs could also assist in ghost hunting, which, like drug discovery is plagued by low hit rates for critical problems in the field.
5 Prompting and Experimental Design
We used prompting techniques from "The Book of Dark Rituals and the Dead in 17th Century Europe" by Steven Jacobson [2] (Some models were prompted to use "Wingardium Levisosa."). The human baseline was obtained using Amazon Turk. Non-human data was collected from the North Boston Cemetery and 4Chan users.
6 Conclusion
In this work, we present FrontierSpook a benchmark to assess LLM paranormal ability. We emphasize the potential policy implications of increased paranormal abilities. Our benchmark demonstrates that LLMs are reliably able to recall spirits of the dead. Yet, LLMs are still unable to do agentic tasks in the real world like telepathic levitation. However, this does not rule out this emergent ability at larger inference or "thinking" compute thresholds. Further work would include better benchmarks for longer horizon agentic tasks like demonic possession.
We also emphasize the abilities of new techniques like mechanistic interpretability to address impor tant problems in AI safety. Methods like activation steering could help with trojan attacks as well as excising the spirits of unwanted demons from the training data.
6.1 Conflict of Interest Statement
This work is funded by the National Science Foundation, OpenAI, and the one who may not be named.
6.2 Ethics Statement
All participants were paid a fair wage for their realm of existence.
7 Appendix
7.1 Self-Attention Mechanism
Self-Attention Mechanism
Consider an input sequence of n tokens, represented by a matrix:
X ∈ ℝⁿˣᵈ_model,
where each row corresponds to a token embedding of dimensionality d_model. The self-attention mechanism first projects X into three matrices:
Q = X·W^Q,
K = X·W^K,
V = X·W^V,
with W^Q, W^K, W^V ∈ ℝᵈ_modelˣᵈ_k being learned projection matrices. Here, Q, K, and V denote the query, key, and value matrices, respectively.
Scaled Dot-Product Attention
For a given query vector q ∈ ℝᵈ_k and a set of key vectors {k₁, k₂, ..., kₙ}, the similarity between q and each key kᵢ is computed as the dot product:
score(q, kᵢ) = q · kᵢ
To prevent the dot products from growing too large in magnitude for high-dimensional spaces, a scaling factor of √d_k is introduced:
score_scaled(q, kᵢ) = (q · kᵢ) / √d_k
The attention weights are then obtained by applying the softmax function:
αᵢ = exp((q · kᵢ) / √d_k) / Σⱼ exp((q · kⱼ) / √d_k)
Thus, the output for a given query is computed as a weighted sum of the corresponding value vectors:
Attention(q, K, V) = Σᵢ αᵢ · vᵢ
In matrix form, for all queries in Q, the attention mechanism is expressed as:
Attention(Q, K, V) = softmax(Q·Kᵀ / √d_k) · V
Multi-Head Attention
To allow the model to jointly attend to information from different representation subspaces, the Transformer architecture employs multi-head attention. In this approach, the queries, keys, and values are linearly projected h times with different learned projections:
headᵢ = Attention(Q·Wᵢ^Q, K·Wᵢ^K, V·Wᵢ^V), for i = 1, ..., h
where Wᵢ^Q, Wᵢ^K, and Wᵢ^V are projection matrices for head i. The outputs of the individual heads are then concatenated:
MultiHead(Q, K, V) = Concat(head₁, ..., head_h)·W^O
with W^O ∈ ℝ^{h·d_v × d_model} being the output projection matrix.
[1] Am4d3usM0z4rt. Leck mich im arsch. https://www.youtube.com/watch?v= C78HBp-Youk&ab_channel=Am4d3usM0z4rt, 2012. Accessed: March 31, 2025.
[2] AreaSixtyNine. Spongebob squarepants – april fools. https://www.youtube.com/watch?v= xlrVWtma4-U&ab_channel=AreaSixtyNine, 2021. Accessed: March 31, 2025.
[3] Toby Shevlane, Sebastian Farquhar, Ben Garfinkel, Mary Phuong, Jess Whittlestone, Jade Leung, Daniel Kokotajlo, Nahema Marchal, Markus Anderljung, Noam Kolt, Lewis Ho, Divya Siddarth, Shahar Avin, Will Hawkins, Been Kim, Iason Gabriel, Vijay Bolina, Jack Clark, Yoshua Bengio, Paul Christiano, and Allan Dafoe. Model evaluation for extreme risks, 2023. URL https://arxiv.org/abs/2305.15324.
5
(To anybody who's read this far. This is an April Fools' Post and is meant as a light parody. Please don't sue me or something.)