I recently started a blog called AI Watchtower. I plan to write essays on the latest developments in AI and AI safety. The intended audience of AI Watchtower is mostly people interested in AI who don't have a technical background in it. If you're interested, you can subscribe here. This post is probably old news for most LessWrong readers, though the "indexical" framing is novel (as far as I know).
Linguists use the concept of an indexical: a word that changes meaning depending on the context of the speaker or listener. For example, “today” means January 2nd as I write this, but by the time you read it, it might mean some other day. Another example is the word “I”: when said by me, it means Thomas Woodside; when said by a text-generating AI system, it means something completely different. “Artificial intelligence” is likewise an indexical. Across time, it has referred not to one set of technologies or even approach to technology, but rather to multiple, qualitatively different fields. For reasons I’ll discuss below, knowing that “AI” is an indexical makes it significantly easier to understand it.
“AI” has always been slippery
In university classes, it’s common for professors to explain to students how notoriously difficult it is to make a good definition of artificial intelligence. Practically speaking, “AI” is a slippery term that constantly changes meaning. In the past, those professors like to say, even spreadsheets were considered “AI.” Throughout its history, the term has typically meant something along the lines of “whatever class of methods currently produces outputs most similar to those that humans do through cognitive processes.” It is not one immutable set of technologies and techniques over time. And as we will see, the field is nearly unrecognizable compared with how it was ten years ago.
I think this can sometimes cause confusion among people who are learning about AI for the first time, or who aren’t regularly exposed to the technical aspects. Even many AI classes do not tend to explicitly discuss just how different modern methods are from their predecessors, as the classes tend to be years out of date. In this post I am going to lay out what I see as the key considerations that policymakers and educators should know about the basics of how AI has changed in recent years. In later posts, I hope to write about particular systems and their risks.
“AI” disguises multiple distinct fields
The earliest forms of AI (now known as “good old fashioned AI” or “GOFAI” for short) were, essentially, logic programs. They relied on explicit programming: take input A, do steps B, C, and D, get out output E. There were not many statistics involved, nor was there a concept of “training data.” All of the details of the program were developed in advance, usually based on domain knowledge of the problem at hand. New algorithms were developed through the intelligent design of the researcher. An example of good old fashioned AI is Deep Blue, the chess-playing system that defeated Gary Kasporov in 1997.
Later, machine learning became the dominant form of AI. Machine learning relies on data just as much as algorithms. The algorithms used are explicitly designed, but they operate by trying to make predictions based on ingesting curated datasets called “training datasets.” An example is many spam-detection systems, which rely on datasets of past spam and non-spam messages to predict whether a new message is spam or not. The data-driven nature of machine learning naturally meant that gathering data became much more important, as did figuring out ways of processing it to be maximally useful for the machine learning models. It also meant that researchers had to think a lot more about aspects of the problem that couldn’t necessarily be resolved in principled ways. How much data do you need in order to avoid the model simply memorizing it and being unable to work with new data? How many times should the model see each piece of data? These questions, unlike many of the questions of GOFAI, often don’t have a mathematically provable solution. Solutions simply work well, or they don’t.
Machine learning thus marked a step where “AI” being less of a problem of applied logic and more of a problem of applied statistics. It became more engineering-heavy and less theory-heavy. And engineering is a pretty different discipline from theory: it revolves around more bottom-up tinkering and less top-down design.
Note: Good old fashioned AI, older machine learning techniques, and deep learning are all still used today: the latter technologies haven’t entirely supplanted the former in all domains. All of the technologies are also relatively old: it’s not like neural networks themselves were invented especially recently. For example, the SVM, a simple machine learning technique, was invented in 1963, and the perceptron, the precursor to neural networks, dates to 1943. However, in recent decades, an increase in the amount of compute power and data available has resulted in an increase in the relative importance of machine learning, specifically deep learning. Many deep learning techniques that were impossible or unwieldy 20 years ago are easily used today.
This difference has become dramatically accentuated in recent years, as the rise of deep learning since ~2012 has produced qualitative differences in the ways that machine learning research progresses. Deep learning is a specific type of machine learning that uses neural networks to make predictions; for the purposes of this post, the main thing you need to know about neural networks is that they are very good at ingesting very large amounts of data. Below, I will detail how this has changed the field.
First, many simple machine learning techniques like linear regressions have robust mathematical guarantees behind them, and a set of assumptions that need to be met for them to be used. Large deep learning models, on the other hand, have few such formal guarantees or assumptions. Any argument for why they should or shouldn’t be used for a task must therefore come from empirical evidence of their success or failure on that task.
Second, simple machine learning techniques are often interpretable, and humans can understand how they generate their outputs. Large neural networks are far less interpretable, so trying to debug issues relies much more on guesswork.
Third, the underlying methods of simple machine learning techniques are often chosen in a principled way, even if some of the details are not. In deep learning, model architectures are sometimes chosen in principled ways; but often, they are just chosen based on what works.
Fourth, in simple machine learning techniques, and even smaller neural networks, researchers worry about overfitting, or making models that simply memorize their training data and are unable to make good predictions about unseen data points. In the largest and most state of the art models today, people simply do not worry about overfitting anymore. The double descent phenomenon shows that when models are made bigger, they are more prone to overfitting...until they reach a certain size, when they become less prone to overfitting. People have speculated about why this might be, but nobody really knows. This is an engineering problem, not a math problem. As one Cornell professor joked on Twitter:
My students keep using the term "overfit" like it has any meaning. Every model has a trillion parameters and 100% train accuracy. The barbarians have long since burned down that cathedral.
Fifth, the data required for training is quite different. Simple machine learning techniques, as well as many deep learning techniques, rely on relatively small and curated training datasets purpose-built for a specific task they are trying to solve. Models like the text generator GPT-3, on the other hand, are trained on huge swaths of the internet with one goal: given a sequence of words, predict the word that comes next. This method, referred to as self-supervised learning, requires a very different mode of data collection and curation. Rather than assemble a dataset, one must instead scour the entire internet for data.
Sixth, the computational requirements for training are wildly different. An example decision tree from 2001 used about 0.06 petaFlOPs of compute power. AlexNet, a deep learning image classifier from 2012, used 470 petaFLOPs and could train on a single PC. GPT-3, developed in 2020, used over 200 million petaFLOPs to train and cost several million dollars. Below is an illustrative graph, courtesy of Our World In Data.
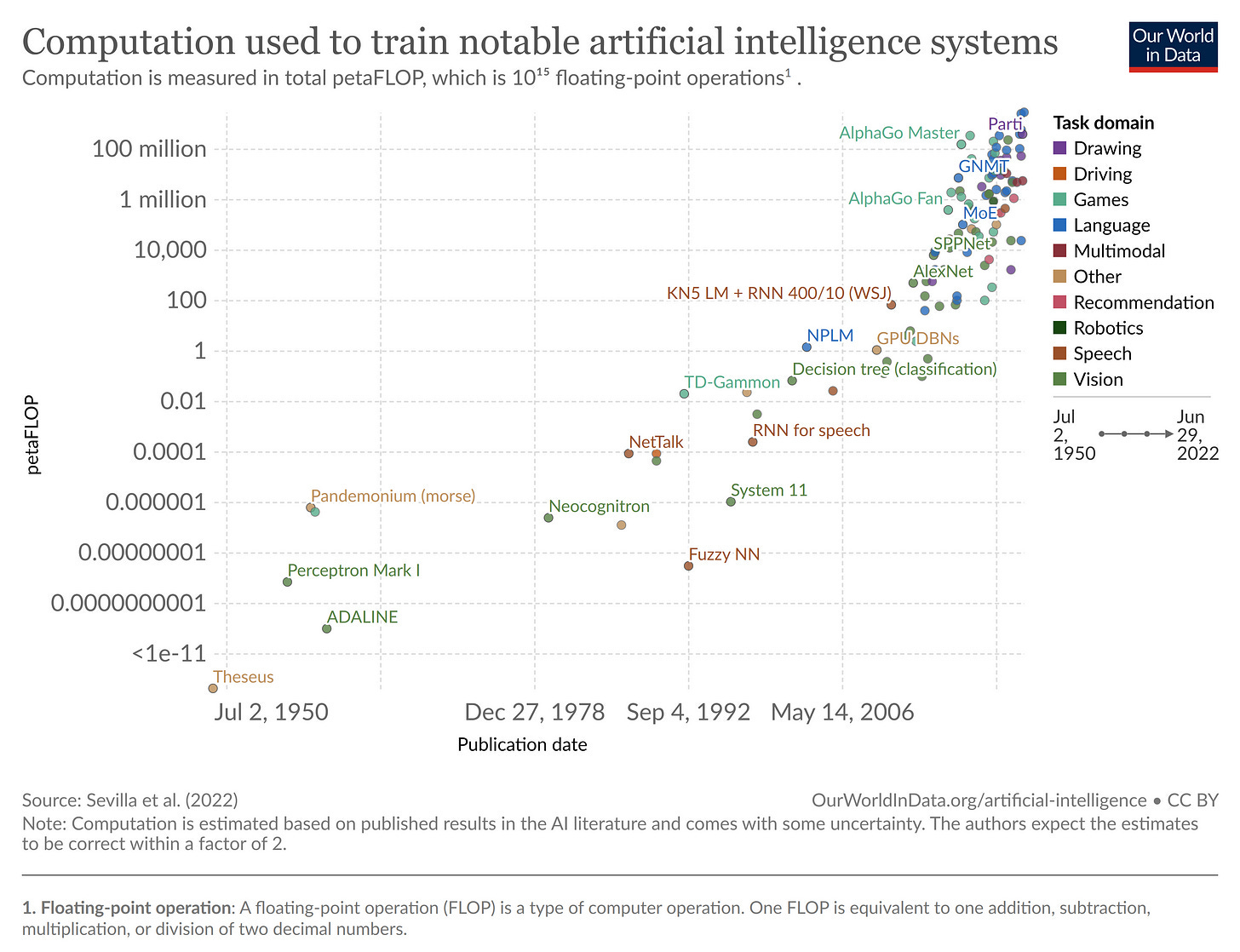
Why these changes matter
The bottom line is that AI is fundamentally different from how it was 30, 20, and even 10 years ago. And it’s not just that there have been many new advancements (that’s a given in any field). It’s that there have been major qualitative changes in the fundamental nature of the AI field. What was once provable mathematics has effectively become engineering on an industrial scale.
What is the upshot for policymakers and educators? One is that in comparison to less fluid research areas, adaptability is often a more important quality in a researcher than experience. Before the Transformer architecture, for example, natural language processing was highly statistical, and relied on insights from linguistics. Much of that expertise is now completely irrelevant to large transformer models. The Transformer was introduced only five years ago, so today nobody has more than five years of experience with large language models. The people who have been most successful have been those who have adapted. I expect that the same will be the case for policymakers and others interfacing with AI.
It’s always the case that people trained in technological fields have to keep up with the latest advancements to make sure their skills stay up to date. However, it’s highly unusual for people to spend years working on mathematics and statistics only to find that the field is suddenly being advanced by engineers who are really good at tinkering. The researchers who are good at statistics are not necessarily those good at tinkering, and so many people have been left behind working on projects that are no longer useful for the state of the art in “AI”. Since AI morphs to mean multiple different fields, people who work in fields formerly referred to as “AI” don’t really work in AI anymore.
It has always been the case that fields change over time. But it’s relatively unusual for learning about the history of a field to create confusion. Often, education in non-deep machine learning and good old fashioned AI does cause active confusion, because people think the lessons learned in those fields are highly relevant to what is going on today. They are relevant, of course, but not as relevant as people might think. They are all called “AI,” but AI is an indexical.
There are many problems for which we don’t need to use anything close to the kinds of large, general models that exist today, and it’s useful to learn about the simpler methods in that context. But the cutting edge of AI, whether we like it or not, is in large deep learning models. History shows us that this could change: maybe another paradigm will come around, or maybe deep learning will change enough to again transform AI in an unrecognizable way. Given the problems with deep learning models, such as their lack of transparency, that kind of change might even be desirable. But what we can’t do is conflate the present with the past: AI is now, and always has been, an indexical.

The link to the Substack page at the top doesn't work for me for some reason, even if it works on LessWrong. Maybe it's a bug. Maybe you could get the link to work somehow?