If we can find a way to connect other AI systems to brain organoids via brain-computer interfaces, then advances in other types of AI will also accelerate Biological AI
I always think about the "Dr. Octopus" problem. In Spider-Man 2, the AI that Doc Ock uses to control his mechanical "octopus" arms takes control of him and turns him evil.
I think the general consensus, which I share, is that neither mind uploading nor good BCI to allow brain extensions are likely to happen before AGI. I wish I had citations ready to hand.
I haven't heard as much discussion of the biological superbrains approach. I think it's probably feasible to increase intelligence through genetic engineering, but that's probably also too long to help with alignment before AGI happens, if you took the route of altering embryos. Altering adults would be tougher and more limited. And it would hit the same legal problems.
I think that neuromorphic AGI is a possibility, which is why some of my alignment work addresses it. I think the best and most prominent work on that topic is Steve Byrnes' Intro to Brain-Like-AGI Safety.
I personally think LLMs will plateau around human level, but that they will be made agentic and self-teaching, and therefore and self-aware (in sum, "sapient") and truly dangerous by scaffolding them into language model agents or language model cognitive architectures. See Capabilities and alignment of LLM cognitive for my logic in expecting that.
That would be a good outcome. We'd have agents with their own goals, capable enough to do useful and dangerous things, but probably not quite capable enough to self-exfiltrate, and probably initially under the control of relatively sane people. That would scare the pants off of the world, and we'd see some real efforts to align the things. Which is uniquely do-able, since they'd take top-level goals in natural language, and be readily interpretable by default (with real concerns still there aplenty, including waluigi effects and their utterances not reliably reflecting their real underlying cognition).
I think the scaling hypothesis is false, and we'll get to AGI quite soon anyway, by other routes. The better scaling works, the faster we'll get there, but that's gravy. We have all of the components of a human-like mind today, putting them together is one route to AGI.
Biological superintelligence: a solution to AI safety
I use the term “biological superintelligence” to refer to superhuman intelligences that have a functional architecture that closely resembles that of the natural human brain. A biological superintelligence does not necessarily have an organic substrate.
Biological superintelligence includes:
Brain emulations/mind uploads: Also called “digital people” by Holden Karnofsky. Fine-grained software copies of natural human brains. Could be digitally enhanced (e.g. by increasing the number of neurons) to attain higher intelligence.
Brain implants/brain-computer interfaces: Devices under development by companies such as Neuralink, Kernel, Openwater, and Meta’s Reality Labs. Could hypothetically enhance human intelligence.
Brain simulations/neuromorphic AI: Coarse-grained software simulacra of natural human brains that capture enough of the brain’s functional architecture to produce intelligent behaviour. Could be digitally enhanced to exceed limitations of the natural human brain.
Bioengineered superbrains: Organic human brains enhanced with biotech, such as genetic engineering, to achieve a higher level of intelligence. Larger brains (and skulls) could be engineered, for example.
Biological superintelligence is a solution to AI safety because it solves the alignment problem and the control problem by avoiding them entirely. Provided, of course, biological superintelligence is created before AGI.
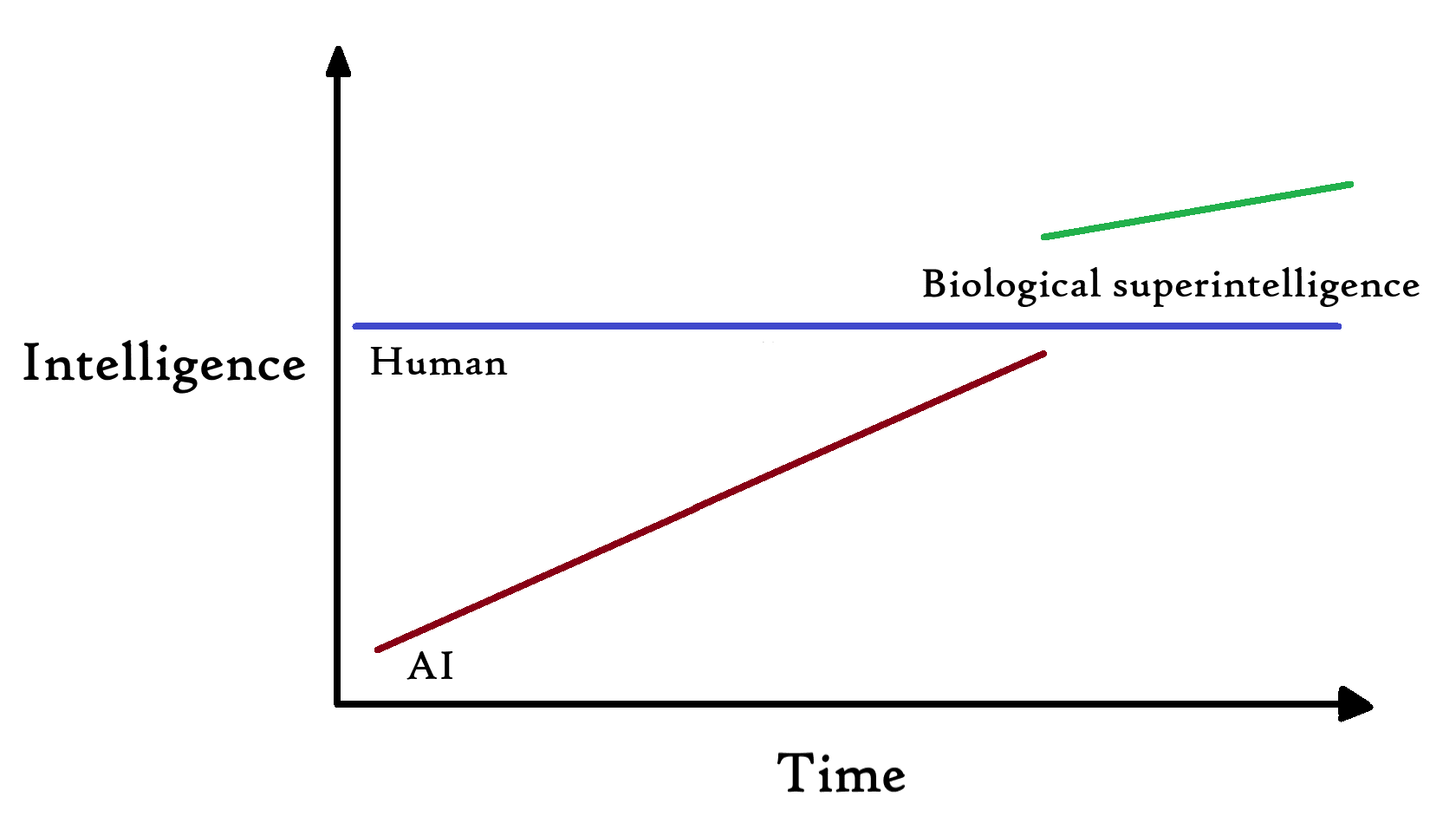
How can we ensure biological superintelligence is created before AGI? Could subhuman AI assist in this goal? Probably, but how much? It partly depends on how slow and smooth the takeoff to AGI is. If AI smarter than AlphaFold 2 and GPT-4 but dumber than AGI can accelerate science and engineering, that boon could be directed toward creating biological superintelligence. In the ideal case, the situation would look something like this:
Biological superintelligence is an alternative approach to AI safety to the more standard approach of AI alignment research. I believe it is an underrated and relatively neglected approach, in spite of its promise.
This post presents the executive summary from Giving What We Can’s impact evaluation for 2025. At the end of this post we share links to more information, including the full report and...
I used AI to fix transcription errors, rerrarange the ideas, and suggest tweaks to the title and some sentences.
Three of the most exciting projects to come out of EA in recent years are, in a vague sense, CEA spinouts:
* Kairos is directly a spinout of CEA and now handles most support for university AI safety groups. Basically everyone I've found who knows them is really excited about what they do
* NEST is an opinionated ideas-fi...



If we can find a way to connect other AI systems to brain organoids via brain-computer interfaces, then advances in other types of AI will also accelerate Biological AI
I always think about the "Dr. Octopus" problem. In Spider-Man 2, the AI that Doc Ock uses to control his mechanical "octopus" arms takes control of him and turns him evil.