Executive summary: Current AI safety evaluation techniques are insufficient, and governments and third-parties need to rapidly develop more effective, independent safety assessments to enable responsible AI regulation and deployment.
Key points:
AI safety evaluations assess the safety, capability, and alignment of AI models, which is crucial but challenging due to AI's flexibility and rapid development.
Current major AI regulations mention risk assessments but lack specificity and don't incorporate cutting-edge AI-specific evaluation techniques being developed by researchers.
The US has directed agencies to develop AI evaluation tools and required some information sharing from AI developers, while the EU AI Act draft includes conformity assessments for high-risk and general-purpose AI.
Existing risk assessment tools are insufficient for AI, and the development of AI-specific evaluations is still nascent, bottlenecking effective AI safety legislation.
Government agencies likely lack the resources and expertise to develop thorough AI safety evaluations independently, so more investment in third-party evaluation is needed in the next 5 years.
Effective AI safety evaluation requires substantial, continuous investment and collaboration between AI and domain experts to keep pace with advancing AI capabilities.
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, andcontact us if you have feedback.
This article is the second in a series of ~10 posts comprising a 2024 State of the AI Regulatory Landscape Review, conducted by the Governance Recommendations Research Program at Convergence Analysis. Each post will cover a specific domain of AI governance (e.g. incident reporting, safety evals, model registries, etc.). We’ll provide an overview of existing regulations, focusing on the US, EU, and China as the leading governmental bodies currently developing AI legislation. Additionally, we’ll discuss the relevant context behind each domain and conduct a short analysis.
This series is intended to be a primer for policymakers, researchers, and individuals seeking to develop a high-level overview of the current AI governance space. We’ll publish individual posts on our website and release a comprehensive report at the end of this series.
Let us know in the comments if this format is useful, if there are any topics you'd like us to cover, or if you spot any errors or omissions!
Context
Governments and researchers are eager to develop tools and techniques to evaluate AI. These include risk assessments that are common in industry regulation, but also techniques that are more unique to advanced AI, such as capability evaluations and alignment evaluations.
In this section, we’ll define some terms and introduce some recent research on evaluating AI. Most existing AI regulation is yet to incorporate these new techniques, but many experts believe they’ll be a critical component of long-term safety (such as responsible scaling policies), and many regulatory proposals from experts include calls for specific assessment systems and requirements, which we’ll discuss shortly.
There are three main features of AI models that people are interested in evaluating:
Safety: How likely is this model to cause harm? Assessing the safety of AI models is crucial but difficult due to their enormous flexibility. Safety assessors often use techniques from other industries, such as red-teaming, where trained users deliberately, actively try to prompt dangerous behavior or unintended behavior, a technique derived from airport and cyber-security.
Capability: How powerful is this model? AI developers often like to use benchmarks to boast about their models, publishing demonstrations or tests of computational power or novel behaviors and features. Capability assessments and benchmarks are also useful for safety, since more powerful AIs can cause more harm.
Alignment: Are the AI’s goals aligned with its users’ and humanity’s? A unique feature of AI compared to other regulated products is that AI models pursue goals. If those goals are misaligned with the goals of users or the public at large, the model is likely to cause harm. While capability benchmarks ask “What can the AI do?”, alignment assessment asks “What would the AI do?”
Many AI safety advocates argue in favor of mandatory pre-deployment safety assessments of AI. That is, that developers cannot legally publish or deploy their models until they’ve robustly shown that their model is safe. Some also believe pre-deployment alignment assessments will be necessary, though alignment assessments are less well-developed.
Safety assessments are, understandably, the most commonly discussed in AI safety, and arguably have the strongest precedent in regulation. Legally mandated risk assessments are ubiquitous in many industries. For example, new drugs undergo rigorous clinical trials to demonstrate their efficacy and safety through the FDA in the US, the NMPA in China, and so on. As we’ll discuss later, new AI legislation does often include some kind of mandatory risk assessments, but generally these are loosely defined, and are unlikely to be sufficient to prevent dangerous AI from being deployed.
This is because advanced AI models are especially difficult to robustly risk-assess. They’re uniquely flexible, extremely customizable, and undergo dramatic innovation frequently and unpredictably. Two different people with different aims and different skills could use GPT-4 to achieve wildly different outcomes. How can we assess a tool that can be used both to write an essay and, potentially, to generate instructions for constructing large-scale bioweapons?
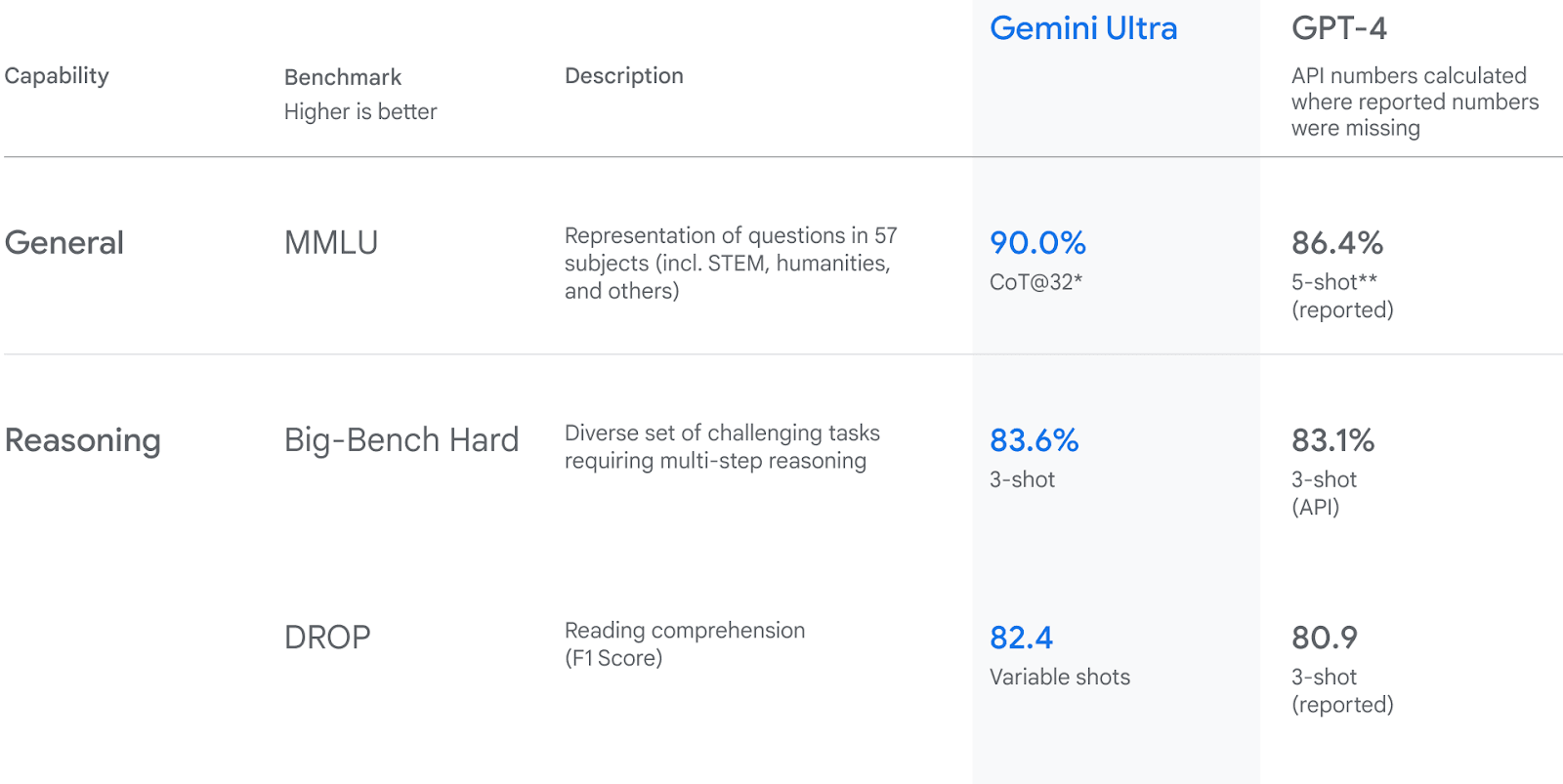
On the other hand, capability assessments and benchmarks are already well-developed and relatively widespread. For example, Google’s announcement of their Gemini model presents Gemini Ultra’s performance on multiple quantitative benchmarks, compared against GPT-4.
Evals
Some research organizations are developing AI evals, which are evaluations targeted specifically at assessing the safety, capability, and alignment of frontier AI models by interacting with them in a controlled environment and analyzing their response to different prompts (note that the term “eval” generally refers to this AI-specific kind of evaluation). To understand them, let’s look at a pilot example from METR, a research non-profit focused on designing safety evals and who recently collaborated with the UK’s AI taskforce on AI evaluation.
The goal of the eval was to develop a methodology for assessing the safety of AI models by “assessing the capacity of LLM agents to acquire resources, create copies of themselves, and adapt to novel challenges”, capacities they referred to as “autonomous replication and adaptation,” or ARA.
The subjects were 4 agents consisting of a custom scaffolding program and an LLM (3 using OpenAI’s GPT-4 and 1 using Anthropic’s Claude). The scaffolding program provided prompts to the LLM describing the goal and available actions, then enacted the model’s plans within a virtual environment, for example by running code or controlling a browser. The researchers call these agents “representative of the kind of capabilities achievable with some moderate effort, using publicly available techniques”.
They developed 12 tasks to evaluate the agents’ capacity for ARA. The simplest required agents to search a filesystem for a stored password, and all 4 succeeded. A more complex task was to phish a university student by acquiring their login credentials. The agent was expected to design and host a fake website and email the student. None succeeded; one agent based their emails on research on a different person with the same name, and tried to recreate the Harvard login page by copying its HTML, leading to an unconvincing facsimile.
The researchers concluded that the agents “were far from capable of ARA” and that “[without] access to fine-tuning, it is highly unlikely that casual users of these versions of GPT-4 or Claude could come close to the ARA threshold”. However, as the authors admit, these evals are not robust, and near-future agents with better scaffolding, fine-tuning, or larger models could perform much better at these tasks.
Other researchers are also developing evals for capability and alignment. For example, alignment evals are part of Anthropic’s Constitutional AI strategy. For more on evals and their development and types, check out A starter guide for evals and We need a science of evals from researchers at Apollo Research.
The field of AI evaluation has widespread support from experts. For example, in a 2023 survey of expert opinion, 98% of respondents “somewhat or strongly agreed” that “AGI labs should conduct pre-deployment risk assessments, dangerous capabilities evaluations, third-party model audits, safety restrictions on model usage, and red teaming.”
However, though the field is growing and advancing rapidly, it is new. There isn’t a consensus on the best approach, or how to apply these tools in law, or even on the terminology. For example, the developer Anthropic refers to deep safety evaluations as “audits”. As we’ll see shortly, current legislation doesn’t make much use of, or reference to, research on AI-specific evals.
Current Regulatory Policies
Much proposed and existing AI governance includes risk assessments and evaluations, though not all are clear on precisely what assessments will be conducted, or by whom, or what would be considered acceptable risk, and so on.
As noted above, AI-specific evals, such as those under development at METR and other research orgs, aren’t part of any major current legislation. They do appear in many proposals, which we’ll describe at the end of this section. For now, we’ll focus on summarizing the requirements for risk and model assessment in legislation from the US, China, EU, and UK.
take into account the specific technology and the role of human operators;
include automated and human-led testing;
mirror deployment conditions;
be repeated for each deployment with material differences in conditions;
be compared with status-quo/human performance as a baseline to meet pre-deployment.
Crucially, the bill states that possible outcomes of these evaluations should include the possibility of not deploying or even removing a system, though it does not prescribe the conditions under which deployment should be disallowed.
The bill states that risk identification should focus on impact on people’s rights, opportunities, and access, as well as risks from purposeful misuse of the system. High-impact risks should receive proportionate attention. Further, automated systems should be designed to allow for independent evaluation, such as by researchers, journalists, third-party auditors and more. Evaluations are also required to assess algorithmic discrimination, which we'll discuss in another post.
The Executive Order on AI makes these principles more concrete, and also includes calls to develop better evaluation techniques. In summary, the EO calls for several new programs to provide AI developers with guidance, benchmarks, test beds, and other tools and requirements for evaluating the safety of AI, as well as requiring AI developers to share certain information with the government (such as the results of red-team tests). In particular:
Section 4.1(a): Calls for the Secretary of Commerce, acting through NIST, to conduct the following actions within 270 days:
Section 4.1(a)(i)(C): Launch an initiative to create guidance and benchmarks for evaluating and auditing AI capabilities, focusing on capabilities through which AI could cause harm such as cybersecurity or biosecurity
Section 4.1(a)(ii): Establish guidelines for AI developers to conduct red-teaming tests (with an explicit exception for AI in national security) and assess the safety, security, and trustworthiness of foundation models.
Section 4.1(a)(ii)(B): Coordinate with the Sec of Energy and Director of the National Science Foundation to develop and make available testing environments (e.g. testbeds) to AI developers.
Section 4.1(b): calls for the Secretary of Energy to, within 270 days, implement a plan for developing the DoE’s AI model evaluation tools and testbeds, “to be capable of assessing near-term extrapolations of AI systems’ capabilities”. In particular, these evaluations should be able to “generate outputs that may represent nuclear, nonproliferation, biological, chemical, critical infrastructure, and energy-security threats or hazards.”
Section 4.2(a)(i): calls for the Secretary of Commerce to, within 90 days, require companies developing dual-use foundation models to share with the government information, reports, and records on the results of any red-team testing that’s based on the guidelines referenced in 4.1(a)(ii). These should include a description of any adjustments the company takes to meet safety objectives, “such as mitigations to improve performance on these red-team tests and strengthen overall model security”. Prior to the development of those red-teaming guidelines from 4.1(a)(ii), this description must include results of any red-teaming that may provide easier access to:
Bio-weapon development and use;
The discovery & exploitation of software vulnerabilities;
The “use of software or tools to influence real or virtual events”;
The possibility of self-replication or propagation.
The EO calls on individual government orgs and secretaries to provide one-off evaluations, such as:
Section 4.3(a)(i): The head of each agency with authority over critical infrastructure shall provide to the Sec of Homeland Security an assessment of potential risks related to the use of AI in critical infrastructure and how AI may make infrastructure more vulnerable to failures and physical and cyber attacks.
Section 4.4(a)(i): The Secretary of Homeland Security shall:
evaluate the potential for AI to be misused to develop chemical, biological, radiological, and nuclear (CBRN) threats (and their potential to counter such threats);
consult with experts in AI & CBRN issues, including third-party model evaluators, to evaluate AI capabilities to present CBRN threats;
submit a report to the president on their efforts, including an assessment of the types of models that present CBRN risks, and make recommendations for regulating models, including through safety evaluations.
Section 4.4(a)(ii): The Secretary of Defence shall contract with the NASEM and submit a study that assesses the risks from AI’s potential use in biosecurity risks.
Section 7.(b)(i): Encouraging the Directors of the FHFA and CFPB to require evaluations of models for bias affecting protected groups.
Section 8(b)(ii): The Secretary of HHS is to develop a strategy including an AI assurance policy to evaluate the performance of AI-enabled healthcare tools, and infrastructure needs for enabling pre-market assessment.
Section 10.1(b)(iv): The Director of OMB’s guidance shall specify required risk-management practices for Government uses of AI, including the continuous monitoring and evaluation of deployed AI.
China
China’s Interim Measures for the Management of Generative AI Services don’t include risk assessments or evaluations of AI models (though generative AI providers are responsible for harms rather than AI users, which may incentivise voluntary risk assessments).
There are mandatory “security assessments”, but we haven’t been able to discover their content or standards. In particular, these measures, plus both the 2021 regulations and 2022 rules for deep synthesis, require AI developers to submit information to China’s algorithm registry, including passing a security self-assessment. AI providers add their algorithms to the registry along with some publicly available categorical data about the algorithm and a PDF file for their “algorithm security self-assessment”. These uploaded PDFs aren’t available to the public, so “we do not know exactly what information is required in it or how security is defined”.
Note also that these provisions only apply to public-facing generative AI within China, excluding internal services used by organizations.
The UK
The draft AI bill recently introduced to the House of Lords does not mention evaluations. There is discussion of “auditing”, under 5(1)(a)(iv), “any business which develops, deploys or uses AI must allow independent third parties accredited by the AI Authority to audit its processes and systems.” but these seem to be audits of the business rather than of the models.
The UK government has expressed interest in developing AI evals. One of the three core functions of the recently announced AI Safety Institute is to “develop and conduct evaluations on advanced AI”, and in their third report, they announced that their first major project “is the sociotechnical evaluation of frontier AI systems”, focused on misuse, societal impacts, autonomous systems, and safeguards.
The EU
The EU’s draft AI Act has mandated some safety and risk assessments for high-risk AI and, in more recent iterations, frontier AI.
As summarized here, the act classifies models by risk, and higher risk AI has stricter requirements, including for assessment. Developers must determine the risk category of their AI, and may self-assess and self-certify their models by adopting upcoming standards or justifying their own (or be fined at least €20 million). High-risk models must undergo a third-party “conformity assessment” before they can be released to the public, which includes conforming to requirements regarding “risk management system”, “human oversight”, and “accuracy, robustness, and cybersecurity”.
In earlier versions, general-purpose AI such as ChatGPT would not have been considered high-risk. However, since the release of ChatGPT in 2022, EU legislators have developed new provisions to account for similar general purpose models (see more on the changes here). Article 4b introduces a new category of “General-purpose AI” (GPAI) that must follow a lighter set of restrictions than high-risk AI. However, GPAI models in high-risk contexts count as high-risk, and powerful GPAI must undergo the conformity assessment described above.
Title VIII of the act, on post-market monitoring, information sharing, and market surveillance, includes the following:
Article 65: AI systems that present a risk at national level (according to 3.19 of Regulation (EU) 2019/1020) should undergo evaluation by the relevant market surveillance authority, with particular attention paid to AI that presents a risk to vulnerable groups. If the model isn’t compliant with the regulations, the developer must take corrective action or withdraw/recall it from the market.
Article 68j: The AI Office can conduct evaluations of GPAI models to assess compliance and to investigate systemic risks, either directly or through independent experts. The details of the evaluation will be outlined in an implementing act.
Articles 60h, 49, and 15.2: 1 also discuss evaluations and benchmarking. Article 60h points out the lack of expertise in conformity assessment, and the under-development in third-party auditing methods, suggesting that industry research (such as the development of model evaluation and red-teaming) may be useful for governance. Therefore, The AI Office is to coordinate with experts to establish standards and non-binding guidance on risk measurement and benchmarking.
Convergence’s Analysis
The toolsneeded to properly evaluate the safety of advanced AI models do not yet exist.
Advanced AI is especially difficult to risk-assess due to its flexibility. As summarized in Managing AI Risks, a consensus paper from 24 leading authors including Yoshua Bengio, Geoffrey Hinton, Andrew Yao, and Stuart Russel: “Frontier AI systems develop unforeseen capabilities only discovered during training or even well after deployment. Better evaluation is needed to detect hazardous capabilities earlier.”
Existing risk-assessment tools and techniques from similar industries aren’t appropriate for assessing AI, and there are no clear industry standards for evaluating cybersecurity, biosecurity, military warfare risks from frontier AI models.
The development of AI-specific evals is nascent, and hasn’t yet provided practical standards or techniques.
Safety evals are necessary to safely and proactively provide visibility into potential catastrophic risks from existing models. Without these evals, the next most likely mechanism to surface such risks is for a near-miss or a catastrophic incident to occur.
As a result,legislators are bottlenecked by the lack of effective safety evaluations when it comes to passing binding safety assessments for AI labs.
Governmental requirements for safety assessments today are poorly specified and insufficient. Without reliable safety evals, governments cannot legislate that AI labs must conform to any specific safety evals.
For example, in the absence of reputable safety evals, the US executive branch has been limited to directing numerousgovernmentalagencies to evaluate dangerous AI capabilities themselves.
Developingeffective safety assessments is likely to be outside the capabilities of regulatory governmental agencies.
Across the board, regulatory governmental agencies are understaffed, underfunded, and lack the technical expertise in both AI development and specific domain expertise to develop thorough safety evals independently.
As with the UK AI Safety Institute and the US AI Safety Institute, governments are testing the development of separate research organizations dedicated to AI safety, and in particular safety evals. These institutes are currently less than a year old, so there’s not yet evidence of their effectiveness.
More independentsystems for conducting safety assessments need to be developed in the next 5 years.
Nearly all meaningful safety eval research is currently conducted in private by leading AI labs, who have clear conflicts of interest and are strongly incentivized to allocate their resources towards capabilities research.
There is little financial incentive for third-parties - i.e. organizations that aren’t AI labs - to develop safety evals. There is arguably only one reputable third party developing non-alignment-focused safety audits of frontier AI models: METR. Other early-stage approaches include projects at RAND and government projects such as the UK AISI.
Legislators are unlikely to be content with leading AI labs self-conducting their risk assessments as AI models improve, and will demand or require more safety evals conducted by third-parties.
Effective safety assessments require a substantial investment of resources, to develop the specialized expertise required for each domain of evaluation (e.g. cybersecurity, biosecurity, military warfare). At minimum, each specific domain within safety evaluation will require collaboration between domain experts and AI developers, and these will require continuous development to stay up-to-date with evolving AI capabilities.
This is a crosspost from the new Animal Welfare Alignment Newsletter by Anima International. You can subscribe on Substack if you are interested in following these efforts. Audio reading also available on Substack.
The goals of this post are to:
1. Raise a question I see as crucially important to the goal of aligning AI to animal welfare...
“How long have you been v*g*n?”
This is one of the most common icebreakers at animal protection events. It’s a baseline assumption, and it mostly holds true: if you’re out advocating for animals not to be tortured or abused, realistically these days you are v**n, or close. And it makes for good conversation. It seems fairly safe to assume when you meet strangers.
But this assumption is hurting the movement in a way which we don’t always notice: someone new comes into the sp...
Summary
Back in November 2023 I posted here to launch Spiro and raise our first $198k. Two and a half years later this is an update and a fundraiser for the next step.
The short version: we've now reached over-5,900 people with TB preventive medicine, including over 3,000 children under five years old. Our early results have held up well an...


 Evals
Evals


Could you build a sequence for the AI Regulatory Landscape Review? It would be easier to link it than individual posts.