Executive summary: The author announces a substantially revised version of “Intro to Brain-Like-AGI Safety,” arguing that brain-like AGI poses a distinct, unsolved technical alignment problem centered on reward function design, continual learning, and model-based reinforcement learning, and that recent AI progress does not resolve these risks.
Key points:
The series still aims to bring non-experts to the frontier of open problems in brain-like AGI safety, with a core thesis that such systems will have explicit reward functions whose design is critical for alignment.
The author argues that today’s LLMs are not AGI and that focusing on benchmarks or “book smarts” obscures large gaps in autonomous, long-horizon planning and execution.
A central neuroscience claim is that the cortex largely learns from scratch, while evolved steering mechanisms in the hypothalamus and brainstem ultimately ground all human motivations, including prosocial ones.
The update expands critiques of interpretability as a standalone solution, emphasizing scale, continual learning, and competitive pressures as unresolved obstacles.
The author maintains that instrumental convergence is not inevitable but becomes likely for sufficiently capable RL agents with consequentialist preferences, making naive debugging approaches unsafe at high capability levels.
The revised conclusion elevates “reward function design” as a priority research program for alignment, complementing efforts to reverse-engineer human social instincts.
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, andcontact us if you have feedback.
New version of “Intro to Brain-Like-AGI Safety” — EA Forum
This is a crosspost from the new Animal Welfare Alignment Newsletter by Anima International. You can subscribe on Substack if you are interested in following these efforts. Audio reading also available on Substack.
The goals of this post are to:
1. Raise a question I see as crucially important to the goal of aligning AI to animal welfare...
Hello! I'm Justin Portela. I got hired by GWWC to make YouTube videos after AI in Context did such a kickass job.
My channel is using that same cinematic, high-production value beauty to talk about everything in the EA universe that isn't AI.
...
This is a linkpost for Request for Proposals: Research and Applied Work on Digital Minds.
I'm glad to announce a request for proposals for research and applied work on digital minds at Longview Ph...
Suppose we someday build an Artificial General Intelligence algorithm using similar principles of learning and cognition as the human brain. How would we use such an algorithm safely?
I will argue that this is an open technical problem, and my goal in this post series is to bring readers with no prior knowledge all the way up to the front-line of unsolved problems as I see them.
Post #1 contains definitions, background, and motivation. Then Posts #2–#7 are the neuroscience, arguing for a picture of the brain that combines large-scale learning algorithms (e.g. in the cortex) and specific evolved reflexes (e.g. in the hypothalamus and brainstem). Posts #8–#15 apply those neuroscience ideas directly to AGI safety, ending with a list of open questions and advice for getting involved in the field.
A major theme will be that the human brain runs a yet-to-be-invented variation on Model-Based Reinforcement Learning. The reward function of this system (a.k.a. “innate drives” or “primary rewards”) says that pain is bad, and eating-when-hungry is good, etc. I will argue that this reward function is centered around the hypothalamus and brainstem, and that all human desires—even “higher” desires for things like compassion and justice—come directly or indirectly from that reward function. If future programmers build brain-like AGI, they will likewise have a reward function slot in their source code, in which they can put whatever they want. If they put the wrong code in the reward function slot, the resulting AGI will wind up callously indifferent to human welfare. How might they avoid that? What code should they put in—along with training environment and other design choices—such that the AGI won’t feel callous indifference to whether its programmers, and other people, live or die? No one knows—it’s an open problem, but I will review some ideas and research directions.
Highlights from the changelog
So what’s new? Well, I went through the whole thing and made a bunch of edits and additions, based on what I’ve (hopefully) learned since my last big round of edits 18 months ago. Here are some highlights:
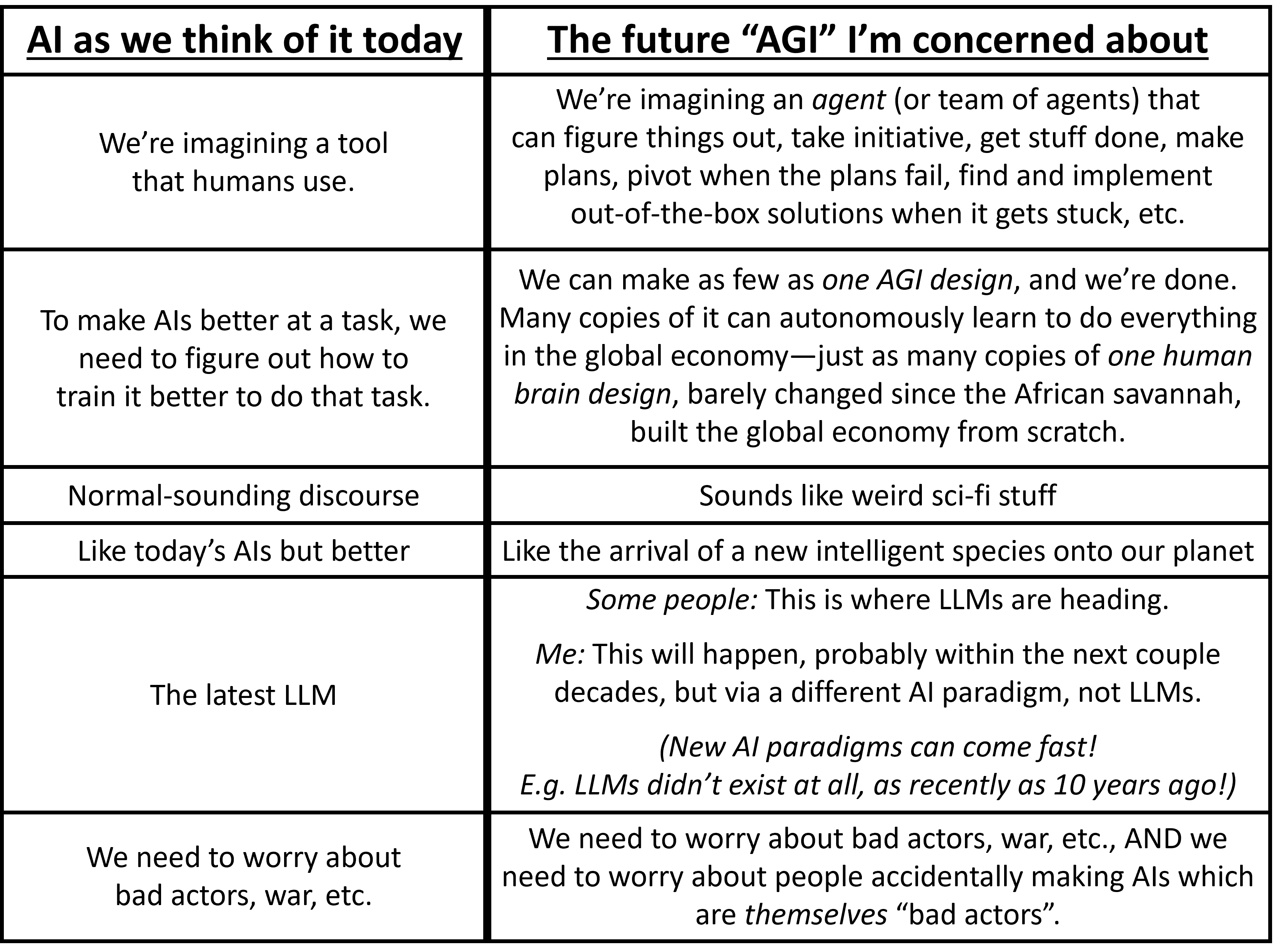
I updated my “what is AGI” chart, along with more elaboration on why some (not all!) LLM enthusiasts have a blind spot for just how much headroom there still is beyond the AI of today.
…
I should elaborate on that last part. I think that some LLM enthusiasts have a massive blind spot, where they are so impressed by all the things that today’s LLMs can do, that they forget about all the things that today’s LLMs can’t do. These people read the questions on Humanity’s Last Exam (HLE), and scratch their heads, and say “C’mon, when LLMs ace the HLE benchmark, then what else is there? Look at how hard those questions are! It would need to be way beyond PhD level in everything! If that’s not superintelligence, what is?”
Well, no, that’s not superintelligence, and here’s an example of why not. Consider the task of writing a business plan and then founding a company and growing it, over the course of years, to $1B/year revenue, all with zero human intervention. Today’s LLMs fall wildly, comically short of being able to complete that task. By analogy, if humans were like today’s AIs, then humans would be able to do some narrow bits of founding and running companies by ourselves, but we would need some intelligent non-human entity (angels?) to repeatedly intervene, assign tasks to us humans, and keep the larger project on track. Of course, humans (and groups of humans) don’t need the help of angels to conceive and carry out ambitious projects, like building businesses or going to the moon. We can do it all by ourselves. So by the same token, future AGIs (and groups of AGIs) won’t need the help of humans.
Anyway, this series is about brain-like algorithms. These algorithms are by definition capable of doing absolutely every intelligent behavior that humans (and groups and societies of humans) can do, and potentially much more. So they can definitely reach AGI. Whereas today’s AI algorithms are not AGI. So somewhere in between here and there, there’s a fuzzy line that separates “AGI” from “not AGI”. Where exactly is that line? My answer: I don’t know, and I don’t care. Drawing that line has never come up for me as a useful thing to do. It won’t come up in this series either.
More responses to intelligence denialists
I added my response to another flavor of “intelligence denialism”
Opinion #6:“Brain-like AGI is kinda an incoherent concept; intelligence requires embodiment, not just a brain in a vat (or on a chip). And we get things done by trial-and-error, and cooperation across a society, not by some abstract ‘intelligence’.”
The “embodiment” debate in neuroscience continues to rage. I fall somewhere in the middle. I do think that future AGIs will have some action space—e.g., the ability to (virtually) summon a particular book and open it to a particular passage. I don’t think having a whole literal body is important—for example Christopher Nolan (1965-2009) had lifelong quadriplegia, but it didn’t prevent him from being an acclaimed author and poet. More importantly, I expect that whatever aspects of embodiment are important for intelligence could be easily incorporated into a brain-like AGI running on a silicon chip. Is a body necessary for intelligence after all? OK sure, we can give the AGI a virtual body in a VR world—or even a real robot body in the real world! Are hormonal signals necessary for intelligence? OK sure, we can code up some virtual hormonal signals. Etc.
As for societies and cooperation, that’s intimately tied to human intelligence. Billions of humans over thousands of years developed language and science and a $100T economy entirely from scratch. Could billions of rocks over thousands of years do all that? Nope. What about billions of today’s LLMs over thousands of years? Also nope. (Indeed, unlike humans, LLMs cannot invent language from scratch unless they already have language in their training data.) On the other hand, if billions of humans can do all that, then so can billions of brain-like AGIs.
And separately, “a group of billions of AGIs that collaborate and exchange ideas using language” is … also an AGI! It’s an AGI that takes billions of times more chips to run, but it’s still an AGI. Don’t underestimate what one AGI can do!
There’s a common conflation of “intelligence” with “book smarts”. This is deeply mistaken. E.g. as the saying goes, charisma resides in the brain, not the kidneys.
Having learned more about the range of opinions on my “learning from scratch” hypothesis, I wrote a better overview of the state of the discourse:
…Nevertheless, here’s a caricatured roundup of where different groups seem to stand.
In favorof the learning-from-scratch hypothesis:
Many computational neuroscientists in the old-school “connectionist” tradition, such as Randall O’Reilly, would probably endorse most or all of my hypothesis. At the very least, O’Reilly explicitly endorses a learning-from-scratch cortex in this interview, citing Morton & Johnson (1991) as a line of evidence.
Many people who talk about “old brain (a.k.a. lizard brain) versus new brain”, such as Jeff Hawkins and Dileep George, would also probably endorse most or all of my hypothesis, with the learning-from-scratch parts of the brain being “new” and the rest being “lizard”. More on this (slightly dubious) school of thought in §3.3.
Many NeuroAI computational modelers (but not all) build their computational models of the cortex, hippocampus, cerebellum, and striatum, in a way that winds up being learning-from-scratch, I think.
The book Beyond Evolutionary Psychology by George Ellis & Mark Solms (2017) is not quite a perfect match to my hypothesis, but it’s close, probably closer than anything else I’ve seen in the literature. They divide the brain into (what they call) “hard-wired domains” versus “soft-wired domains”, with a similar boundary as mine. Kudos to the authors, even if I have some nitpicky complaints about their formulations. Too bad their book got so little attention.
Opposedto the learning-from-scratch hypothesis:
People in the “evolved modularity” / “innate cognitive modules” tradition would probably strongly disagree that the cortex “learns from scratch”. This category includes most evolutionary psychologists (e.g. Leda Cosmides, John Tooby, Steven Pinker), as well as Joshua Tenenbaum and others in the probabilistic programming school of computational cognitive science. See for example Pinker’s The Blank Slate (2003) chapter 5. To be clear, I’m enthusiastic about evolutionary psychology as a topic of study, but I do think that evolutionary psychology as practiced today is built on a mistaken framework.
People who use phrases like “evolutionary pretraining” are likewise rejecting the learning-from-scratch framework. “Evolutionary pretraining” invokes the idea that the cortex is like a machine learning (ML) algorithm, but not an ML algorithm that starts from random initialization, but rather a “pretrained” ML algorithm that can perform useful innate behaviors from the start, thanks to evolution, in a fashion analogous to “transfer learning” in the ML literature. I obviously disagree.
I revamped my discussion of brain plasticity, relating it to “mutable variables” in computer science:
2.3.3 Learning-from-scratch is NOT the more general notion of “plasticity”
When lay people talk about “brain plasticity” in self-help books, they’re usually imagining a kind of animistic force that makes your brain magically respond to changing circumstances in good ways rather than bad.
Neuroscientists think of it differently: “plasticity” means there’s something in the brain (often synapses, but also potentially myelination, gene expression, etc.) that durably changes in a specific way under specific conditions, as a result of some biochemical triggering mechanism. The change does what it does, and its consequences can be good or bad (but it’s usually good, or else the triggering mechanism would not have evolved).
If we now switch over from biochemistry to algorithms, the previous paragraph may ring a bell: plasticity just means that the brain algorithm has mutable variables.
Now, any learning-from-scratch algorithm necessarily involves mutable variables, which allow it to learn. For example, the “weights” of a deep neural network are mutable variables.
However, practically every other algorithm involves mutable variables too! For example, the Python code a=a+1 takes a mutable variable a, and increases its value by 1. When you play a video game, there are mutable variables tracking your inventory, health, progress, etc. Mutable variables are ubiquitous and routine.
The brain does other things too, besides learning-from-scratch algorithms (more on which in the next post). Those other things, of course, also involve mutable variables, and hence plasticity. Thus, there is brain plasticity that has nothing to do with learning-from-scratch algorithms. Let’s call those other things “idiosyncratic mutable variables”. Here’s a table with an example of each, and general ways in which they differ…
Interpretability
I’ve talked to a number of people who think that interpretability is a silver bullet for brain-like-AGI safety, so I added this subsection in response:
2.7.1 What about interpretability for brain-like AGIs?
There is a field of “machine learning interpretability”, dedicated to understanding the innards of learned-from-scratch “trained models”. I’m generally in favor of efforts to advance that field, but I want to caution strongly against people pinning their hopes on interpretability. Sure, given enough time, maybe people could understand any given entry in the giant unlabeled world-model of a brain-like AGI. But (1) Also, maybe not (e.g., think of the thousands of implicit hard-to-describe learned heuristics used by a charismatic salesperson); (2) If it takes careful scrutiny to understand one entry, how will we deal with millions of them? (3) A brain-like AGI would keep learning and changing as it runs—do we have to keep pausing it to reanalyze its ever-shifting world-model and desires? (4) And if we keep pausing it, won’t we get outcompeted by the more careless firm down the block that just lets its AGI run at full speed?
Relatedly, people sometimes argue that the unlabeled world-model of a brain-like AGI would be easier to understand than the unlabeled world-model of an LLM, for various reasons. Whether this is true or false, I think it’s a red herring. The above four issues would need to be dealt with, regardless of whether or not LLMs have an even worse interpretability profile than brain-like AGI.
To be clear, I’m pushing back on the idea that “we don’t have to worry about safety because interpretability is tractable”. I’m not opposed to interpretability itself, nor to leveraging interpretability as one component of a plan. More on the latter later in the series (esp. Post #14).
I added my extraordinarily bold prediction on when brain-like AGI will appear. In case you’re wondering, yes I am willing to put my money where my mouth is and take bets on “between zero and infinity years”, at 1:1 odds 😉
…Thus concludes my timeline-to-brain-like-AGI discussion, which again is not my main focus in this series. You can read my three timelines sections (§2.8, §3.7, and this one), agree or disagree, and come to your own conclusions. In case anyone is curious, when I am forced to be specific, my position is:
I expect superintelligent brain-like AGI between 5 and 25 years from now. Or I guess maybe more than 25 years, who knows. Or I guess maybe less than 5 years, who knows. Shrug.
Responses to bad takes on acting under uncertainty
I rewrote my round-up of bad takes on AGI uncertainty, including “the insane bizarro-world reversal of Pascal’s Wager”:
…Likewise, the word “hypothetical”, as in “hypothetical possibilities” or “hypothetical risks”, is another jeer thrown at people trying to plan for an uncertain future. Taken literally, it’s a rather odd insult: some hypotheses are false, but also, some hypotheses are true!
Various other bad takes revolve around the idea that we should not even try to prepare for possible-but-uncertain future events. In particular, some people talk as if we shouldn’t try to mitigate a possible future catastrophe until we’re >99.9% confident that the catastrophe will definitely happen. I like to call this the insane bizarro-world reversal of Pascal’s Wager. It probably sounds like a strawman when I put it like that, but my goodness, it is very real, and very widespread. I think it comes from a few places…
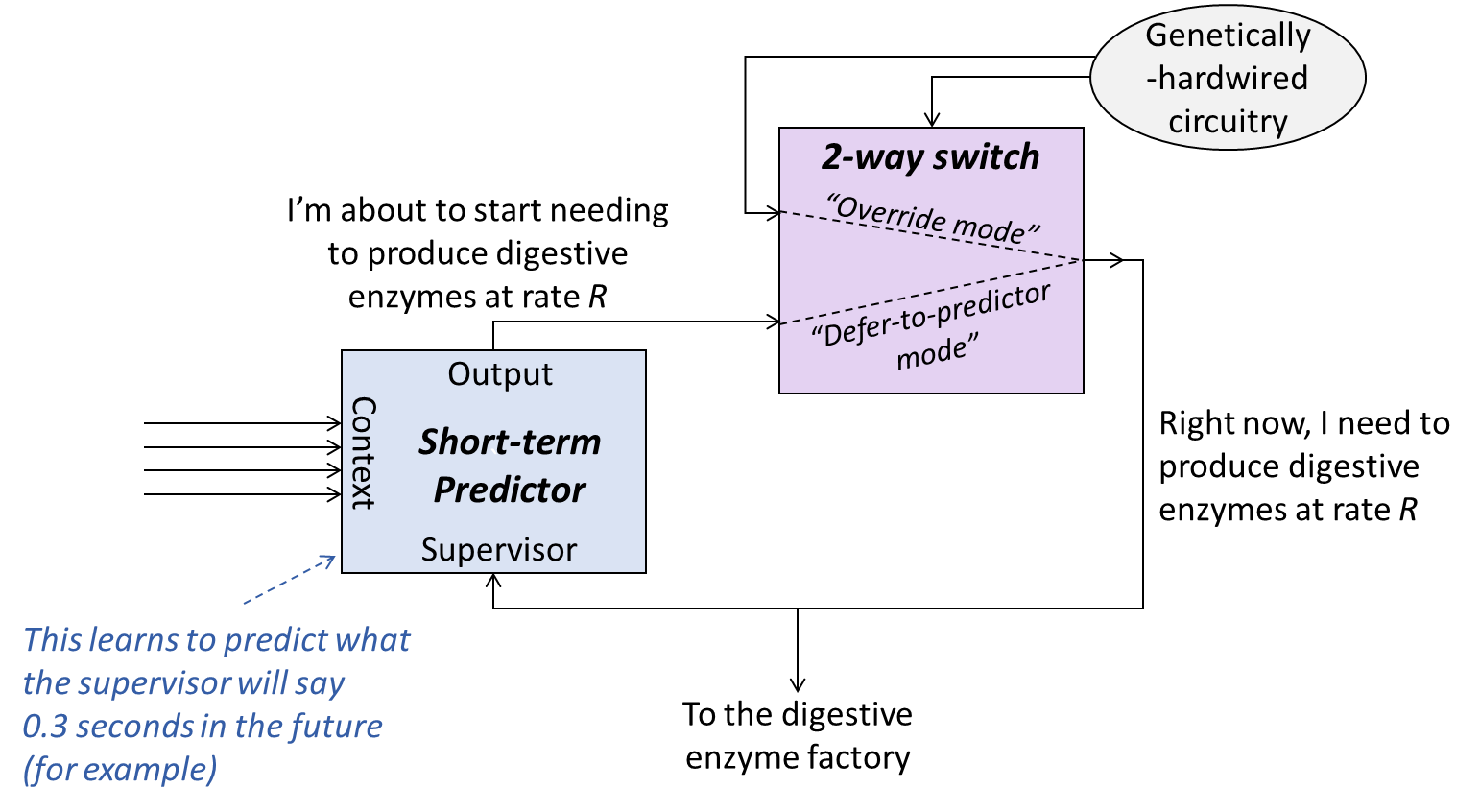
…And the section now has even more silly pictures! The first of these is new, the other two are old.
Much of this post discusses a certain toy model, and many readers have struggled to follow what I was saying. I added a new three-part “preliminaries” section that will hopefully provide helpful pointers & intuitions.
…Here’s a toy model of what that can look like:
…
5.2.1 Toy model walkthrough: preliminaries
Here’s a little summary table for this subsection, that I’ll explain in the text below.
More on why ego-syntonic goals are in the hypothalamus & brainstem
I added a brief summary of why we should believe that desires like friendship and justice come ultimately from little hypothalamic cell groups, just like hunger and pain do, as opposed to purely from “reason” (as one high-level AI safety funder once confidently told me).
Here are four views on why we should believe that the Steering Subsystem is the ultimate source of not only ego-dystonic urges like hunger, but also ego-syntonic desires like friendship and justice.
AI perspective: We don’t yet know in full detail how model-based RL and model-based planning works in the human brain—we don’t have brain-like AGI yet. But we do at least vaguely know how these kinds of algorithms work. And we know enough to say for sure that these algorithms don’t develop prosocial motivations out of nowhere. For example, if you set the reward function of MuZero to always return 0, then the algorithm will emit random outputs forever—it won’t start fighting for justice.
Rodent model perspective: For what it’s worth, researchers have been equally successful in finding little cell groups in the rodent hypothalamus that orchestrate “antisocial” behaviors like aggression, and that orchestrate “prosocial” behaviors like parenting and sociality. I fully expect that the same holds for humans.
Philosophy perspective: Without the Steering Subsystem, the only thing the cortex can do is build a world-model from predictive learning of sensory inputs (§4.7). That’s “is”, not “ought”. And “Hume’s law” says that you can’t get “ought”-statements from exclusively “is”-statements. Granted, not everyone believes in Hume’s law. But I do—see an elegant and concise argument for it here.
LLMs are officially off-topic, but in order to keep up with the times, I keep having to mention them in more and more places. One of the changes this time was to add a subsection “Didn’t LLMs solve the Goodhart’s Law problem?”
10.3.1.1 Didn’t LLMs solve the Goodhart’s Law problem?
When I first published this series in early 2022, I didn’t really need to defend the idea that Goodhart’s Law is an AI failure mode, because it was ubiquitous and obvious. We want AIs that find innovative, out-of-the-box solutions to problems (like winning at chess or making money), and that’s how we build AIs, so of course that’s what they do. And there isn’t a principled distinction between “meet the spec via a clever solution that I wouldn’t have thought of”, versus “meet the spec by exploiting a loophole in how the spec is operationalized”. You can’t get the former without the latter. This is obvious in theory, and equally obvious in practice. Everyone in AI had seen it with their own eyes.
…But then LLM chatbots came along, and gave rise to the popular idea that “AI that obeys instructions in a common-sense way” is a solved problem. Ask Claude Code to ensure that render.cpp has no memory leaks, and it won’t technically “satisfy” the “spec” by deleting all of the code from the file. Well, actually, it might sometimes; I don’t want to downplay LLM alignment challenges. See Soares & Yudkowsky FAQ, “Aren’t developers regularly making their AIs nice and safe and obedient?” for a pessimist’s case.
But more importantly, regardless of whether it’s a solved problem for today’s LLMs, it is definitely not a solved problem for brain-like AGI, nor for the more general category of “RL agents”. They are profoundly different algorithm classes. You can’t extrapolate from one to the other.
See my post Foom & Doom 2: Technical alignment is hard (2025) for a deep-dive into how people get LLMs to (more-or-less) follow common-sense instructions without egregious scheming and deception, and why we won’t be able to just use that same trick for brain-like AGI. The short version is that LLM capabilities come overwhelmingly from imitation learning. “True” imitation learning is weird, and profoundly different from everyday human social imitation, or indeed anything else in biology; I like to call it “the magical transmutation of observations into behavior” to emphasize its weirdness. Anyway, I claim that true imitation learning has alignment benefits (LLMs can arguably obey common-sense instructions), but those benefits are inexorably yoked to capabilities costs (LLMs can’t really “figure things out” beyond the human distribution, the way that societies of humans can, as I discuss in my “Sharp Left Turn” post (2025)). So it’s a trick that won’t help us with brain-like AGI. Again, more details in that link.
I rewrote my discussion of instrumental convergence, its relation to consequentialist preferences, and the surrounding strategic situation:
10.3.2.3 Motivations that don’t lead to instrumental convergence
Instrumental convergence is not inevitable in every possible motivation. It comes from AIs having preferences about the state of the world in the future—and most centrally, the distant future (say, weeks or months or longer)—such that investments in future options have time to pay themselves back. These are called “consequentialist” preferences.
Given that, one extreme position is to say “well OK, if ‘AGIs with consequentialist preferences’ leads to bad and dangerous things, then fine, we’ll build AGIs without consequentialist preferences!”. Alas, I don’t think that’s a helpful plan. The minor problem is that we could try to ensure that the AGI preferences are not consequentialist, but fail, because technical alignment is hard. The much bigger problem is that, even if we succeed, the AGI won’t do anything of note, and will be hopelessly outcompeted and outclassed when the next company down the street, with a more cavalier attitude about safety, makes an AGI that does have consequentialist preferences. After all, it’s hard to get things done except by wanting things to get done. For more on both these points, see my post Thoughts on “Process-Based Supervision” / MONA (2023), §5.2–5.3.
Then the opposite extreme position is to say “That’s right! If AGI is powerful at all, it will certainly have exclusively consequentialist preferences. So we should expect instrumental convergence to bite maximally hard.” But I don’t think that’s right either—see my post Consequentialism & corrigibility (2021). Humans have a mix of consequentialist and non-consequentialist preferences, but societies of humans were nevertheless capable of developing language, science, and the global economy from scratch. As far as I know, brain-like AGI could be like that too. But we need to figure out exactly how.
What about RL today?
I added a discussion of how I can say all this stuff about how RL agents are scary and we don’t know how to control them … and yet, RL research seems to be going fine today! How do I reconcile that?
10.3.3.1 “The usual agent debugging loop”, and its future catastrophic breakdown
I was talking about the ubiquity of Goodhart’s Law just above. You might be wondering: “If Goodhart’s Law is such an intractable problem, why are there thousands of impressive RL results on arXiv right now?” The answer is “the usual agent debugging loop”. It’s applicable to any system involving RL, model-based planning, or both. Here it is:
Step 1: Train the AI agent, and see what it does.
Step 2: If it’s not doing what you had in mind, then turn it off, change something about the reward function or training environment, etc., and then try again.
That’s a great approach for today, and it will continue being a great approach for a while. But eventually it will start failing in a catastrophic and irreversible way—and this is where instrumental convergence comes in.
The problem is: it will eventually become possible to train an AI that is so good at real-world planning, that it can make plans that are resilient to potential problems—and if the programmers are inclined to shut down or edit the AI under certain conditions, then that’s just another potential problem that the AI will incorporate into its planning process!
…So if a sufficiently competent AI is trying to do something the programmers didn’t want, the normal strategy of “just turn off the AI, or edit it, to try to fix the problem” stops working. The AI will anticipate that this programmer intervention is a possible obstacle to what it’s trying to do, and make a plan resilient to that possible obstacle. This is no different than any other aspect of skillful planning—if you expect that the cafeteria might be closed today, then you’ll pack a bag lunch.
In the case at hand, a “resilient” plan might look like the programmers not realizing that anything has gone wrong with the AI, because the AI is being deceptive about its plans and intentions. And meanwhile, the AI is gathering resources and exfiltrating itself so that it can’t be straightforwardly turned off or edited, etc.
The upshot is: RL researchers today, and brain-like AGI researchers in the future, will be able to generate more and more impressive demos, and get more and more profits, for quite a while, even if neither they nor anyone else makes meaningful progress on this technical alignment problem. But that would only be up to a certain level of capability. Then it would flip sharply into being an existential threat.
What do I mean by (technical) alignment?
Posts 10 & 11 now have a clearer discussion of what I mean by (technical) alignment:
10.1.1 What does “alignment” even mean?
The humans programming AGI will have some ideas about what they want that AGI’s motivations to be. I define “the technical alignment problem” as the challenge of building AGI that actually has those motivations, via appropriate code, training environments, and so on.
This definition is deliberately agnostic about what motivations the AGI designers are going for.
Other researchers are not agnostic, but rather think that the “correct” design intentions (for an AGI’s motivation) are obvious, and they define the word “alignment” accordingly. Three common examples are
(1) “I am designing the AGI so that, at any given point in time, it’s trying to do what its human supervisor wants it to be trying to do right now.”
I’m using “alignment” in this agnostic way because I think that the “correct” intended AGI motivation is still an open question.
For example, maybe it will be possible to build an AGI that really just wants to do a specific, predetermined, narrow task (e.g. design a better solar cell), in a way that doesn’t involve taking over the world etc. Such an AGI would not be “aligned” to anything in particular, except for the original design intention. But I still want to use the term “aligned” when talking about such an AGI.
…
“AGI alignment” (previous post) means that an AGI’s motivations are what the AGI designers had in mind. This notion only makes sense for algorithms that have “motivations” in the first place. What does that mean in general? Hoo boy, that’s a whole can of worms. Is a sorting algorithm “motivated” to sort numbers? Or is it merely sorting them?? Let’s not go there! For this series, it’s easy. The “brain-like AGIs” that I’m talking about can definitely “want”, and “try”, and “be motivated” to do things, in exactly the same common-sense way that a human can “want” to get out of debt.
“AGI safety” (Post #1) is about what the AGI actually does, not what it’s trying to do. AGI safety means that the AGI’s actual behavior does not lead to a “catastrophic accident”, as judged by the AGI’s own designers.
I added a subsection clarifying that, contrary to normal RL, we get to choose the source code for AGI but we don’t really get to choose the training environment:
12.5.2 The uncontrollable real world is part of the “training environment” too
RL practitioners are used to the idea that they get to freely choose the training environment. But for brain-like AGI, that frame is misleading, because of continual learning (§8.2.2). The programmers get to choose the “childhood environment”, so to speak, but sooner or later, brain-like AGI will wind up in the real world, doing what it thinks is best by its own lights.
By analogy, generations of parents have tried to sculpt their children’s behavior, and they’re often successful, as long as the kid is still living with them and under their close supervision. Then the children become adults, living for years in a distant city, and the children often find that very different behaviors and beliefs fit them better, whether the parents like it or not.
By the same token, programmers can build a “childhood environment” for their baby brain-like AGIs to hang out and grow up in, but sooner or later we’ll need an AGI that remains aligned while roaming free in the real world. If we can’t do that, careless people will still make brain-like AGIs that roam free in the real world, but they will all be misaligned. That’s bad.
And while we can design the childhood environment, we can’t control the real world. It is what it is.
Indeed, I think a solid starting-point mental model is that, if we want a brain-like AGI that’s aligned after being in the real world for a long time, then we should mostly forget about the childhood environment. Thanks to continual learning, the AGI will settle upon patterns of thought and behavior that it finds most suitable in the real world, which depends on its innate disposition (e.g. reward function), and on the details of the real world, but not on its childhood environment.
I added the RL subfield of “reward function design” as an 8th concrete research program that I endorse people working on:
15.2.2.3 The “reward function design” research program — ⭐⭐⭐⭐
See my post “We need a field of Reward Function Design” (2025). In brief: If people make brain-like AGI, or really any other kind of RL agent AGI, then the reward function is an especially important design degree of freedom for alignment. Alas, the field of RL has always been much more interested in how to maximize reward functions, than in what the reward function should be. The tiny field of reward function design contains a few interesting ideas, including curiosity drive, reward shaping, and inverse reinforcement learning. Let’s find dozens more ideas in the same category!
This research program should hopefully link up with and complement “reverse-engineering human social instincts” (§15.2.1.2 above), as I believe that the AI field of reward function design, in its current primitive state, lacks the theoretical language to explain how human social instincts manage to have the properties that they have.
I give this research program a priority score of 4 stars out of 5. Or up it to 5 stars out of 5 when it’s more narrowly targeted at alignment-relevant reward function design ideas.
Conclusion
Those were just highlights; there were many other small changes and corrections. The blog version has more detailed changelogs after each post. Happy for any feedback, either as blog comments, or by email, DM, etc.!






Executive summary: The author announces a substantially revised version of “Intro to Brain-Like-AGI Safety,” arguing that brain-like AGI poses a distinct, unsolved technical alignment problem centered on reward function design, continual learning, and model-based reinforcement learning, and that recent AI progress does not resolve these risks.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.