Comments
This is the fourth post in a sequence of posts giving an overview of catastrophic AI risks.
4 Organizational Risks
In January 1986, tens of millions of people tuned in to watch the launch of the Challenger Space Shuttle. Approximately 73 seconds after liftoff, the shuttle exploded, resulting in the deaths of everyone on board. Though tragic enough on its own, one of its crew members was a school teacher named Sharon Christa McAuliffe. McAuliffe was selected from over 10,000 applicants for the NASA Teacher in Space Project and was scheduled to become the first teacher to fly in space. As a result, millions of those watching were schoolchildren. NASA had the best scientists and engineers in the world, and if there was ever a mission NASA didn't want to go wrong, it was this one [70].
The Challenger disaster, alongside other catastrophes, serves as a chilling reminder that even with the best expertise and intentions, accidents can still occur. As we progress in developing advanced AI systems, it is crucial to remember that these systems are not immune to catastrophic accidents. An essential factor in preventing accidents and maintaining low levels of risk lies in the organizations responsible for these technologies. In this section, we discuss how organizational safety plays a critical role in the safety of AI systems. First, we discuss how even without competitive pressures or malicious actors, accidents can happen—in fact, they are inevitable. We then discuss how improving organizational factors can reduce the likelihood of AI catastrophes.
Catastrophes occur even when competitive pressures are low. Even in the absence of competitive pressures or malicious actors, factors like human error or unforeseen circumstances can still bring about catastrophe. The Challenger disaster illustrates that organizational negligence can lead to loss of life, even when there is no urgent need to compete or outperform rivals. By January 1986, the space race between the US and USSR had largely diminished, yet the tragic event still happened due to errors in judgment and insufficient safety precautions. Similarly, the Chernobyl nuclear disaster in April 1986 highlights how catastrophic accidents can occur in the absence of external pressures. As a state-run project without the pressures of international competition, the disaster happened when a safety test involving the reactor's cooling system was mishandled by an inadequately prepared night shift crew. This led to an unstable reactor core, causing explosions and the release of radioactive particles that contaminated large swathes of Europe [71]. Seven years earlier, America came close to experiencing its own Chernobyl when, in March 1979, a partial meltdown occurred at the Three Mile Island nuclear power plant. Though less catastrophic than Chernobyl, both events highlight how even with extensive safety measures in place and few outside influences, catastrophic accidents can still occur. Another example of a costly lesson on organizational safety came just one month after the accident at Three Mile Island. In April 1979, spores of Bacillus anthracis—or simply "anthrax," as it is commonly known—were accidentally released from a Soviet military research facility in the city of Sverdlovsk. This led to an outbreak of anthrax that resulted in at least 66 confirmed deaths [72]. Investigations into the incident revealed that the cause of the release was a procedural failure and poor maintenance of the facility's biosecurity systems, despite being operated by the state and not subjected to significant competitive pressures.
The unsettling reality is that AI is far less understood and AI industry standards are far less stringent than nuclear technology and rocketry. Nuclear reactors are based on solid, well-established and well-understood theoretical principles. The engineering behind them is informed by that theory, and components are stress-tested to the extreme. Nonetheless, nuclear accidents still happen. In contrast, AI lacks a comprehensive theoretical understanding, and its inner workings remain a mystery even to those who create it. This presents an added challenge of controlling and ensuring the safety of a technology that we do not yet fully comprehend.
AI accidents could be catastrophic. Accidents in AI development could have devastating consequences. For example, imagine an organization unintentionally introduces a critical bug in an AI system designed to accomplish a specific task, such as helping a company improve its services. This bug could drastically alter the AI's behavior, leading to unintended and harmful outcomes. One historical example of such a case occurred when researchers at OpenAI were attempting to train an AI system to generate helpful, uplifting responses. During a code cleanup, the researchers mistakenly flipped the sign of the reward used to train the AI [73]. As a result, instead of generating helpful content, the AI began producing hate-filled and sexually explicit text overnight without being halted. Accidents could also involve the unintentional release of a dangerous, weaponized, or lethal AI sytem. Since AIs can be easily duplicated with a simple copy-paste, a leak or hack could quickly spread the AI system beyond the original developers' control. Once the AI system becomes publicly available, it would be nearly impossible to put the genie back in the bottle.
Gain-of-function research could potentially lead to accidents by pushing the boundaries of an AI system's destructive capabilities. In these situations, researchers might intentionally train an AI system to be harmful or dangerous in order to understand its limitations and assess possible risks. While this can lead to useful insights into the risks posed by a given AI system, future gain-of-function research on advanced AIs might uncover capabilities significantly worse than anticipated, creating a serious threat that is challenging to mitigate or control. As with viral gain-of-function research, pursuing AI gain-of-function research may only be prudent when conducted with strict safety procedures, oversight, and a commitment to responsible information sharing. These examples illustrate how AI accidents could be catastrophic and emphasize the crucial role that organizations developing these systems play in preventing such accidents.
4.1 Accidents Are Hard to Avoid
When dealing with complex systems, the focus needs to be placed on ensuring accidents don't cascade into catastrophes. In his book "Normal Accidents: Living with High-Risk Technologies," sociologist Charles Perrow argues that accidents are inevitable and even "normal" in complex systems, as they are not merely caused by human errors but also by the complexity of the systems themselves [74]. In particular, such accidents are likely to occur when the intricate interactions between components cannot be completely planned or foreseen. For example, in the Three Mile Island accident, a contributing factor to the lack of situational awareness by the reactor's operators was the presence of a yellow maintenance tag, which covered valve position lights in the emergency feedwater lines [75]. This prevented operators from noticing that a critical valve was closed, demonstrating the unintended consequences that can arise from seemingly minor interactions within complex systems. Unlike nuclear reactors, which are relatively well-understood despite their complexity, complete technical knowledge of most complex systems is often nonexistent. This is especially true of deep learning systems, for which the inner workings are exceedingly difficult to understand, and where the reason why certain design choices work can be hard to understand even in hindsight. Furthermore, unlike components in other industries, such as gas tanks, which are highly reliable, deep learning systems are neither perfectly accurate nor highly reliable. Thus, the focus for organizations dealing with complex systems, especially deep learning systems, should not be solely on eliminating accidents, but rather on ensuring that accidents do not cascade into catastrophes.
Accidents are hard to avoid because of sudden, unpredictable developments. Scientists, inventors, and experts often significantly underestimate the time it takes for a groundbreaking technological advancement to become a reality. The Wright brothers famously claimed that powered flight was fifty years away, just two years before they achieved it. Lord Rutherford, a prominent physicist and the father of nuclear physics, dismissed the idea of extracting energy from atoms as "moonshine," only for Leo Szilard to invent the nuclear chain reaction less than 24 hours later. Similarly, Enrico Fermi expressed 90 percent confidence in 1939 that it was impossible to use uranium to sustain a fission chain reaction—yet, just four years later he was personally overseeing the first reactor [76].

AI development could catch us off guard too. In fact, it often does. The defeat of Lee Sedol by AlphaGo in 2016 came as a surprise to many experts, as it was widely believed that achieving such a feat would still require many more years of development. More recently, large language models such as GPT-4 have demonstrated spontaneously emergent capabilities [77]. On existing tasks, their performance is hard to predict in advance, often jumping up without warning as more resources are dedicated to training them. Furthermore, they often exhibit astonishing new abilities that no one had previously anticipated, such as the capacity for multi-step reasoning and learning on-the-fly, even though they were not deliberately taught these skills. This rapid and unpredictable evolution of AI capabilities presents a significant challenge for preventing accidents. After all, it is difficult to control something if we don't even know what it can do or how far it may exceed our expectations.
It often takes years to discover severe flaws or risks. History is replete with examples of substances or technologies initially thought safe, only for their unintended flaws or risks to be discovered years, if not decades, later. For example, lead was widely used in products like paint and gasoline until its neurotoxic effects came to light [78]. Asbestos, once hailed for its heat resistance and strength, was later linked to serious health issues, such as lung cancer and mesothelioma [79]. The "Radium Girls" suffered grave health consequences from radium exposure, a material they were told was safe to put in their mouths [80]. Tobacco, initially marketed as a harmless pastime, was found to be a primary cause of lung cancer and other health problems [81]. CFCs, once considered harmless and used to manufacture aerosol sprays and refrigerants, were found to deplete the ozone layer [82]. Thalidomide, a drug intended to alleviate morning sickness in pregnant women, led to severe birth defects [83]. And more recently, the proliferation of social media has been linked to an increase in depression and anxiety, especially among young people [84].
This emphasizes the importance of not only conducting expert testing but also implementing slow rollouts of technologies, allowing the test of time to reveal and address potential flaws before they impact a larger population. Even in technologies adhering to rigorous safety and security standards, undiscovered vulnerabilities may persist, as demonstrated by the Heartbleed bug—a serious vulnerability in the popular OpenSSL cryptographic software library that remained undetected for years before its eventual discovery [85]. Furthermore, even state-of-the-art AI systems, which appear to have solved problems comprehensively, may harbor unexpected failure modes that can take years to uncover. For instance, while AlphaGo's groundbreaking success led many to believe that AIs had conquered the game of Go, a subsequent adversarial attack on another highly advanced Go-playing AI, KataGo, exposed a previously unknown flaw [86]. This vulnerability enabled human amateur players to consistently defeat the AI, despite its significant advantage over human competitors who are unaware of the flaw. More broadly, this example highlights that we must remain vigilant when dealing with AI systems, as seemingly airtight solutions may still contain undiscovered issues. In conclusion, accidents are unpredictable and hard to avoid, and understanding and managing potential risks requires a combination of proactive measures, slow technology rollouts, and the invaluable wisdom gained through steady time-testing.
4.2 Organizational Factors can Reduce the Chances of Catastrophe
Some organizations successfully avoid catastrophes while operating complex and hazardous systems such as nuclear reactors, aircraft carriers, and air traffic control systems [87, 88]. These organizations recognize that focusing solely on the hazards of the technology involved is insufficient; consideration must also be given to organizational factors that can contribute to accidents, including human factors, organizational procedures, and structure. These are especially important in the case of AI, where the underlying technology is not highly reliable and remains poorly understood.
Human factors such as safety culture are critical for avoiding AI catastrophes. One of the most important human factors for preventing catastrophes is safety culture [89, 90]. Developing a strong safety culture involves not only rules and procedures, but also the internalization of these practices by all members of an organization. A strong safety culture means that members of an organization view safety as a key objective rather than a constraint on their work. Organizations with strong safety cultures often exhibit traits such as leadership commitment to safety, heightened accountability where all individuals take personal responsibility for safety, and a culture of open communication in which potential risks and issues can be freely discussed without fear of retribution [91]. Organizations must also take measures to avoid alarm fatigue, whereby individuals become desensitized to safety concerns because of the frequency of potential failures. The Challenger Space Shuttle disaster demonstrated the dire consequences of ignoring these factors when a launch culture characterized by maintaining the pace of launches overtook safety considerations. Despite the absence of competitive pressure, the mission proceeded despite evidence of potentially fatal flaws, ultimately leading to the tragic accident [92].
Even in the most safety-critical contexts, in reality safety culture is often not ideal. Take for example, Bruce Blair, a former nuclear launch officer and senior fellow at the Brookings Institution. He once disclosed that before 1977, the US Air Force had astonishingly set the codes used to unlock intercontinental ballistic missiles to “00000000” [93]. Here, safety mechanisms such as locks can be rendered virtually useless by human factors.
A more dramatic example illustrates how researchers sometimes accept a non-negligible chance of causing extinction. Prior to the first nuclear weapon test, an eminent Manhattan Project scientist calculated the bomb could cause an existential catastrophe: the explosion might ignite the atmosphere and cover the Earth in flames. Although Oppenheimer believed the calculations were probably incorrect, remained deeply concerned, and the team continued to scrutinize and debate the calculations right until the day of the detonation [94]. Such instances underscore the need for a robust safety culture.
A questioning attitude can help uncover potential flaws. Unexpected system behavior can create opportunities for accidents or exploitation. To counter this, organizations can foster a questioning attitude, where individuals continuously challenge current conditions and activities to identify discrepancies that might lead to errors or inappropriate actions [95]. This approach helps to encourage diversity of thought and intellectual curiosity, thus preventing potential pitfalls that arise from uniformity of thought and assumptions. The Chernobyl nuclear disaster illustrates the importance of a questioning attitude, as the safety measures in place failed to address the reactor design flaws and ill-prepared operating procedures. A questioning attitude of the safety of the reactor during a test operation might have prevented the explosion that resulted in deaths and illnesses of countless people.
A security mindset is crucial for avoiding worst-case scenarios. A security mindset, widely recognized among computer security professionals, is also applicable to organizations developing AIs. It goes beyond a questioning attitude by adopting the perspective of an attacker and by considering worst-case, not just average-case, scenarios. This mindset requires vigilance in identifying vulnerabilities that may otherwise go unnoticed and involves considering how systems might be deliberately made to fail, rather than only focusing on making them work. It reminds us not to assume a system is safe simply because no potential hazards come to mind after a brief brainstorming session. Cultivating and applying a security mindset demands time and serious effort, as failure modes can often be surprising and unintuitive. Furthermore, the security mindset emphasizes the importance of being attentive to seemingly benign issues or "harmless errors," which can lead to catastrophic outcomes either due to clever adversaries or correlated failures [96]. This awareness of potential threats aligns with Murphy's law—"Anything that can go wrong will go wrong"—recognizing that this can be a reality due to adversaries and unforeseen events.
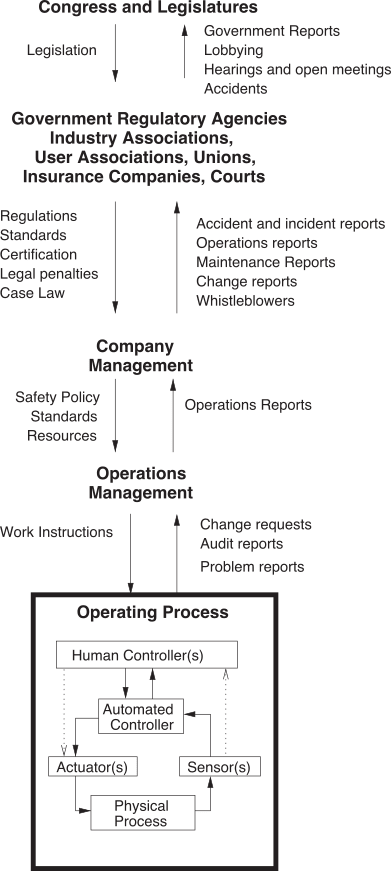
Organizations with a strong safety culture can successfully avoid catastrophes. High Reliability Organizations (HROs) are organizations that consistently maintain a heightened level of safety and reliability in complex, high-risk environments [87]. A key characteristic of HROs is their preoccupation with failure, which requires considering worst-case scenarios and potential risks, even if they seem unlikely. These organizations are acutely aware that new, previously unobserved failure modes may exist, and they diligently study all known failures, anomalies, and near misses to learn from them. HROs encourage reporting all mistakes and anomalies to maintain vigilance in uncovering problems. They engage in regular horizon scanning to identify potential risk scenarios and assess their likelihood before they occur. By practicing surprise management, HROs develop the skills needed to respond quickly and effectively when unexpected situations arise, further enhancing an organization's ability to prevent catastrophes. This combination of critical thinking, preparedness planning, and continuous learning could help organizations to be better equipped to address potential AI catastrophes. However, the practices of HROs are not a panacea. It is crucial for organizations to evolve their safety practices to effectively address the novel risks posed by AI accidents above and beyond HRO best practices.
Most AI researchers do not understand how to reduce overall risk from AIs. In most organizations building cutting-edge AI systems, there is often a limited understanding of what constitutes technical safety research. This is understandable because an AI's safety and intelligence are intertwined, and intelligence can help or harm safety. More intelligent AI systems could be more reliable and avoid failures, but they could also pose heightened risks of malicious use and loss of control. General capabilities improvements can improve aspects of safety, and it can hasten the onset of existential risks. Intelligence is a double-edged sword [97].
Interventions specifically designed to improve safety may also accidentally increase overall risks. For example, a common practice in organizations building advanced AIs is to fine-tune them to satisfy user preferences. This makes the AIs less prone to generating toxic language, which is a common safety metric. However, users also tend to prefer smarter assistants, so this process also improves the general capabilities of AIs, such as their ability to classify, estimate, reason, plan, write code, and so on. These more powerful AIs are indeed more helpful to users, but also far more dangerous. Thus, it is not enough to perform AI research that helps improve a safety metric or achieve a specific safety goal—AI safety research needs to improve safety relative to general capabilities.
Empirical measurement of both safety and capabilities is needed to establish that a safety intervention reduces overall AI risk. Improving a facet of an AI's safety often does not reduce overall risk, as general capabilities advances can often improve specific safety metrics. To reduce overall risk, a safety metric needs to be improved relative to general capabilities. Both of these quantities need to be empirically measured and contrasted. Currently, most organizations proceed by gut feeling, appeals to authority, and intuition to determine whether a safety intervention would reduce overall risk. By objectively evaluating the effects of interventions on safety metrics and capabilities metrics together, organizations can better understand whether they are making progress on safety relative to general capabilities.
Fortunately, safety and general capabilities are not identical. More intelligent AIs may be more knowledgeable, clever, rigorous, and fast, but this does not necessarily make them more just, power-averse, or honest—an intelligent AI is not necessarily a beneficial AI. Several research areas mentioned throughout this document improve safety relative to general capabilities. For example, improving methods to detect dangerous or undesirable behavior hidden inside AI systems do not improve their general capabilities, such the ability to code, but they can greatly improve safety. Research that empirically demonstrates an improvement of safety relative to capabilities can reduce overall risk and help avoid inadvertently accelerating AI development, fueling competitive pressures, or hastening the onset of existential risks.
Safetywashing can undermine genuine efforts to improve AI safety. Organizations should be wary of "safetywashing"—the act of overstating or misrepresenting one's commitment to safety by exaggerating the effectiveness of "safety" procedures, technical methods, evaluations, and so forth. This phenomenon takes on various forms and can contribute to a lack of meaningful progress in safety research. For example, an organization may publicize their dedication to safety while having a minimal number of researchers working on projects that truly improve safety.
Misrepresenting capabilities developments as safety improvements is another way in which safetywashing can manifest. For example, methods that improve the reasoning capabilities of AI systems could be advertised as improving their adherence to human values—since humans might prefer the reasoning to be correct—but would mainly serve to enhance general capabilities. By framing these advancements as safety-oriented, organizations may mislead others into believing they are making substantial progress in reducing AI risks when in reality, they are not. It is crucial for organizations to accurately represent their research to promote genuine safety and avoid exacerbating risks through safetywashing practices.
In addition to human factors, safe design principles can greatly affect organizational safety. One example of a safe design principle in organizational safety is the Swiss cheese model (as shown in Figure 14), which is applicable in various domains, including AI. The Swiss cheese model employs a multilayered approach to enhance the overall safety of AI systems. This "defense in depth" strategy involves layering diverse safety measures with different strengths and weaknesses to create a robust safety system. Some of the layers that can be integrated into this model include safety culture, red teaming, anomaly detection, information security, and transparency. For example, red teaming assesses system vulnerabilities and failure modes, while anomaly detection works to identify unexpected or unusual system behavior and usage patterns. Transparency ensures that the inner workings of AI systems are understandable and accessible, fostering trust and enabling more effective oversight. By leveraging these and other safety measures, the Swiss cheese model aims to create a comprehensive safety system where the strengths of one layer compensate for the weaknesses of another. With this model, safety is not achieved with a monolithic airtight solution, but rather with a variety of safety measures.
In summary, weak organizational safety creates many sources of risk. For AI developers with weak organizational safety, safety is merely a matter of box-ticking. They do not develop a good understanding of risks from AI and may safetywash unrelated research. Their norms might be inherited from academia (“publish or perish”) or startups (“move fast and break things”), and their hires often do not care about safety. These norms are hard to change once they have inertia, and need to be addressed with proactive interventions.
Story: Weak Safety Culture
An AI company is considering whether to train a new model. The company's Chief Risk Officer (CRO), hired only to comply with regulation, points out that the previous AI system developed by the company demonstrates some concerning capabilities for hacking. The CRO says that while the company's approach to preventing misuse is promising, it isn't robust enough to be used for much more capable AIs. The CRO warns that based on limited evaluation, the next AI system could make it much easier for malicious actors to hack into critical systems. None of the other company executives are concerned, and say the company's procedures to prevent malicious use work well enough. One mentions that their competitors have done much less, so whatever effort they do on this front is already going above and beyond. Another points out that research on these safeguards is ongoing and will be improved by the time the model is released. Outnumbered, the CRO is persuaded to reluctantly sign off on the plan.
A few months after the company releases the model, news breaks that a hacker has been arrested for using the AI system to try to breach the network of a large bank. The hack was unsuccessful, but the hacker had gotten further than any other hacker had before, despite being relatively inexperienced. The company quickly updates the model to avoid providing the particular kind of assistance that the hacker used, but makes no fundamental improvements.
Several months later, the company is deciding whether to train an even larger system. The CRO says that the company's procedures have clearly been insufficient to prevent malicious actors from eliciting dangerous capabilities from its models, and the company needs more than a band-aid solution. The other executives say that to the contrary, the hacker was unsuccessful and the problem was fixed soon afterwards. One says that some problems just can't be foreseen with enough detail to fix prior to deployment. The CRO agrees, but says that ongoing research would enable more improvements if the next model could only be delayed. The CEO retorts, "That's what you said the last time, and it turned out to be fine. I'm sure it will work out, just like last time."
After the meeting, the CRO decides to resign, but doesn't speak out against the company, as all employees have had to sign a non-disparagement agreement. The public has no idea that concerns have been raised about the company's choices, and the CRO is replaced with a new, more agreeable CRO who quickly signs off on the company's plans.
The company goes through with training, testing, and deploying its most capable model ever, using its existing procedures to prevent malicious use. A month later, revelations emerge that terrorists have managed to use the system to break into government systems and steal nuclear and biological secrets, despite the safeguards the company put in place. The breach is detected, but by then it is too late: the dangerous information has already proliferated.
4.3 Suggestions
We have discussed how accidents are inevitable in complex systems, how they could propagate through those systems and result in disaster, and how organizational factors can go a long way toward reducing the risk of catastrophic accidents. We will now look at some practical steps that organizations can take to improve their overall safety.
Red teaming. Red teaming is a term used across industries to refer to the process of assessing the security, resilience, and effectiveness of systems by soliciting an adversarial "red" team to identify problems [98]. AI labs should commission external red teams to identify hazards in their AI systems to inform deployment decisions. Red teams could demonstrate dangerous behaviors or vulnerabilities in monitoring systems intended to prevent disallowed use. Red teams can also provide indirect evidence that an AI system might be unsafe; for example, demonstrations that smaller AIs are behaving deceptively might indicate that larger AIs are also deceptive but better at evading detection.
Affirmative demonstration of safety. Companies should have to provide affirmative evidence for the safety of their development and deployment plans before they can proceed. Although external red teaming might be useful, it cannot uncover all of the problems that companies themselves might be able to, and is thus inadequate [99]. Since hazards may arise from system training, companies should have to provide a positive argument for the safety of their training and deployment plans before training can begin. This would include grounded predictions regarding the capabilities the new system would be likely to have, plans for how monitoring, deployment, and information security will be handled, and demonstrations that the procedures used to make future company decisions are sound.
Deployment procedures. AI labs should acquire information about the safety of AI systems before making them available for broader use. One way to do this is to commission red teams to find hazards before AI systems are promoted to production. AI labs can execute a “staged release”: gradually expanding access to the AI system so that safety failures are fixed before they produce widespread negative consequences [100]. Finally, AI labs can avoid deploying or training more powerful AI systems until currently deployed AI systems have proven to be safe over time.
Publication reviews. AI labs have access to potentially dangerous or dual-use information such as model weights and research intellectual property (IP) that would be dangerous if proliferated. An internal review board could assess research for dual-use applications to determine whether it should be published. To mitigate malicious and irresponsible use, AI developers should avoid open-sourcing the most powerful systems and instead implement structured access, as described in the previous section.
Response plans. AI labs should have plans for how they respond to security incidents (e.g. cyberattacks) and safety incidents (e.g. AIs behaving in an unintended and destructive manner). Response plans are common practice for high reliability organizations (HROs). Response plans often include identifying potential risks, detailing steps to manage incidents, assigning roles and responsibilities, and outlining communication strategies [101].
Internal auditing and risk management. Adapting from common practice in other high-risk industries such as the financial and medical industries, AI labs should employ a chief risk officer (CRO), namely a senior executive who is responsible for risk management. This practice is commonplace in finance and medicine and can help to reduce risk [102]. The chief risk officer would be responsible for assessing and mitigating risks associated with powerful AI systems. Another established practice in other industries is having an internal audit team that assesses the effectiveness of the lab's risk management practices [103]. The team should report directly to the board of directors.
Processes for important decisions. Decisions to train or expand deployment of AIs should not be left to the whims of a company's CEO, and should be carefully reviewed by the company's CRO. At the same time, it should be clear where the ultimate responsibility lies for all decisions to ensure that executives and other decision-makers can be held accountable.
Safe design principles. AI labs should adopt safe design principles to reduce the risk of catastrophic accidents. By embedding these principles in their approach to safety, AI labs can enhance the overall security and resilience of their AI systems [89, 104]. Some of these principles include:
- Defense in depth: layering multiple safety measures on top of each other.
- Redundancy: eliminate single points of failure within a system to ensure that even if one safety component fails, catastrophe can be averted.
- Loose coupling: decentralize system components so that a malfunction in one part is less likely to provoke cascading failures throughout the rest of the system.
- Separation of duties: distribute control among different agents, preventing any single individual from wielding undue influence over the entire system.
- Fail-safe design: design systems so when failures do occur, they transpire in the least harmful manner possible.
State-of-the-art information security. State, industry, and criminal actors are motivated to steal model weights and research IP. To keep this information secure, AI labs should take measures in proportion to the value and risk level of their IP. Eventually, this may require matching or exceeding the information security of our best agencies, since attackers may include nation-states. Information security measures include commissioning external security audits, hiring top security professionals, and carefully screening potential employees. Companies should coordinate with government agencies like the Cybersecurity & Infrastructure Protection Agency to ensure their information security practices are adequate to the threats.
A large fraction of research should be safety research. Currently, for every one AI safety research paper, there are fifty AI general capabilities papers [105]. AI labs should ensure that a substantial portion of their employees and budgets go into research that minimizes potential safety risks: say, at least 30 percent of research scientists. This number may need to increase as AIs grow more powerful and risky over time.
Positive Vision
In an ideal scenario, all AI labs would be staffed and led by cautious researchers and executives with a security mindset. Organizations would have a strong safety culture, and structured, accountable, transparent deliberation would be required to make safety-critical decisions. Researchers would aim to make contributions that improve safety relative to general capabilities, rather than contributions that they can simply label as "safety." Executives would not be optimistic by nature and would avoid wishful thinking with respect to safety. Researchers would clearly and publicly communicate their understanding of the most significant risks posed by the development of AIs and their efforts to mitigate those risks. There would be minimal notable small-scale failures, indicating a safety culture strong enough to prevent them. Finally, AI developers would not dismiss sub-catastrophic failures or societal harms from their technology as unimportant or a necessary cost of business, and would instead actively seek to mitigate the underlying problems.
References
[70] John Uri. 35 Years Ago: Remembering Challenger and Her Crew. und. Text. Jan. 2021.
[71] International Atomic Energy Agency. The Chernobyl Accident: Updating of INSAG-1. Technical Report INSAG-7. Vienna, Austria: International Atomic Energy Agency, 1992.
[72] Matthew Meselson et al. “The Sverdlovsk anthrax outbreak of 1979.” In: Science 266 5188 (1994), pp. 1202–8.
[73] Daniel M Ziegler et al. “Fine-tuning language models from human preferences”. In: arXiv preprint arXiv:1909.08593 (2019).
[74] Charles Perrow. Normal Accidents: Living with High-Risk Technologies. Princeton, NJ: Princeton University Press, 1984.
[75] Mitchell Rogovin and George T. Frampton Jr. Three Mile Island: a report to the commissioners and to the public. Volume I. English. Tech. rep. NUREG/CR-1250(Vol.1). Nuclear Regulatory Commission, Washington, DC (United States). Three Mile Island Special Inquiry Group, Jan. 1979.
[76] Richard Rhodes. The Making of the Atomic Bomb. New York: Simon & Schuster, 1986.
[77] Sébastien Bubeck et al. “Sparks of Artificial General Intelligence: Early experiments with GPT-4”. In: ArXiv abs/2303.12712 (2023).
[78] Theodore I. Lidsky and Jay S. Schneider. “Lead neurotoxicity in children: basic mechanisms and clinical correlates.” In: Brain : a journal of neurology 126 Pt 1 (2003), pp. 5–19.
[79] Brooke T. Mossman et al. “Asbestos: scientific developments and implications for public policy.” In: Science 247 4940 (1990), pp. 294–301.
[80] Kate Moore. The Radium Girls: The Dark Story of America’s Shining Women. Naperville, IL: Sourcebooks, 2017.
[81] Stephen S. Hecht. “Tobacco smoke carcinogens and lung cancer.” In: Journal of the National Cancer Institute 91 14 (1999), pp. 1194–210.
[82] Mario J. Molina and F. Sherwood Rowland. “Stratospheric sink for chlorofluoromethanes: chlorine atomc-atalysed destruction of ozone”. In: Nature 249 (1974), pp. 810–812.
[83] James H. Kim and Anthony R. Scialli. “Thalidomide: the tragedy of birth defects and the effective treatment of disease.” In: Toxicological sciences : an official journal of the Society of Toxicology 122 1 (2011), pp. 1–6.
[84] Betul Keles, Niall McCrae, and Annmarie Grealish. “A systematic review: the influence of social media on depression, anxiety and psychological distress in adolescents”. In: International Journal of Adolescence and Youth 25 (2019), pp. 79–93.
[85] Zakir Durumeric et al. “The Matter of Heartbleed”. In: Proceedings of the 2014 Conference on Internet Measurement Conference (2014).
[86] Tony Tong Wang et al. “Adversarial Policies Beat Professional-Level Go AIs”. In: ArXiv abs/2211.00241 (2022).
[87] T. R. Laporte and Paula M. Consolini. “Working in Practice But Not in Theory: Theoretical Challenges of “High-Reliability Organizations””. In: Journal of Public Administration Research and Theory 1 (1991), pp. 19–48.
[88] Thomas G. Dietterich. “Robust artificial intelligence and robust human organizations”. In: Frontiers of Computer Science 13 (2018), pp. 1–3.
[89] Nancy G Leveson. Engineering a safer world: Systems thinking applied to safety. The MIT Press, 2016.
[90] David Manheim. Building a Culture of Safety for AI: Perspectives and Challenges. 2023.
[91] National Research Council et al. Lessons Learned from the Fukushima Nuclear Accident for Improving Safety of U.S. Nuclear Plants. Washington, D.C.: National Academies Press, Oct. 2014.
[92] Diane Vaughan. The Challenger Launch Decision: Risky Technology, Culture, and Deviance at NASA. Chicago, IL: University of Chicago Press, 1996.
[93] Dan Lamothe. Air Force Swears: Our Nuke Launch Code Was Never ’00000000’. Jan. 2014.
[94] Toby Ord. The precipice: Existential risk and the future of humanity. Hachette Books, 2020.
[95] U.S. Nuclear Regulatory Commission. Final Safety Culture Policy Statement. Federal Register. 2011.
[96] Bruce Schneier. “Inside the Twisted Mind of the Security Professional”. In: Wired (Mar. 2008).
[97] Dan Hendrycks and Mantas Mazeika. “X-Risk Analysis for AI Research”. In: ArXiv abs/2206.05862 (2022).
[98] CSRC Content Editor. Red Team - Glossary. EN-US.
[99] Amba Kak and Sarah West. Confronting Tech Power. 2023.
[100] Irene Solaiman et al. “Release strategies and the social impacts of language models”. In: arXiv preprint arXiv:1908.09203 (2019).
[101] Neal Woollen. Incident Response (Why Planning is Important).
[102] Huashan Li et al. “The impact of chief risk officer appointments on firm risk and operational efficiency”. In: Journal of Operations Management (2022).
[103] Role of Internal Audit. URL: https://www.marquette.edu/riskunit/internalaudit/role.shtml.
[104] Heather Adkins et al. Building Secure and Reliable Systems: Best Practices for Designing, Implementing, and Maintaining Systems. O’Reilly Media, 2020.
[105] Center for Security and Emerging Technology. AI Safety – Emerging Technology Observatory Research Almanac. 2023

