DLT is an urn-based method where treatment assignment is determined by a simulated urn. By removing balls when the treatment fails and by adding balls uniformly so that no type runs out, we can balance the trial allocation in a sensible way.
The actual algorithm, for a two treatment study:
Consider an urn containing three types of balls. Balls of types 1 and 2 represent treatments. Balls of type 0 are termed immigration balls. When a subject arrives, one ball is drawn at random. If a treatment ball of type k (1 or 2) is selected, the k-th treatment is given to the subject and the response is observed. If it is a failure, the ball is not replaced. If the treatment is a success, the ball is replaced and consequently, the urn composition remains unchanged. If an immigration ball (type 0) is selected, no subject is treated, and the ball is returned to the urn together with two additional treatment balls, one of each treatment type. This procedure is repeated until a treatment ball is drawn and the subject treated accordingly. The function of the immigration ball is to avoid the extinction of a type of treatment ball.
Extending DLT to multi-treatment settings is as simple as adding additional ball types.
Simulation studies show that DTL performs very well as a way to maximise statistical power. I've read that this is because it (1) approaches the correct ratio asymptotically and (2) has lower variance than other proposed methods, although I don't have an intuitive understanding of why this is.
I've had a look around and this paper has a nice summary of the method (and proposes how it should handle delayed responses).
I think you're missing other features of study design. Notably: feasibility, timeliness, and robustness. Adaptive designs generally require knowledge of outcomes to inform randomisation of future enrolees. But this is often not known, especially if the time until the outcome you're measuring is a long time.
EDIT: the paper also points out various other practical issues with adaptive designs in section 3. These include making it harder to do valid statistical inference on your results (statistical inference is essentially assessing your uncertainty, such as through constructing confidence intervals or calculating p-values) and bias arising if treatment effects change over time (e.g.: if what standard care entails changes due to changing guidelines, or if there's interactions with other changes in the environment).
In short, clinical study design is hard and "unless practical reasons have ruled out all strategies which dominate them" is in fact a massive caveat.
In all the discussion of the explore-exploit trade-off, I've never heard anyone describe it as a frontier that you can be on or off. The explore-exploit frontier is hopefully a useful framework to add to this dialogue.
The literature on clinical trial design is imo full of great ideas never tried. This is partly due to actual difficulties and partly due to a general lack of awareness about the benefits they offer. I think we need good writing for a generalist audience on this topic and this my attempt.
You're definitely right that the caveat is a large one. Adaptive designs are not appropriate everywhere, which is why this post raises points for discussion and doesn't provide a fixed prescription.
To respond to your specific points.
the paper also points out various other practical issues with adaptive designs in section 3
Section three discusses whether adaptive designs lead to
a substantial chance of allocating more patients to an inferior treatment
reducing statistical power
making statistical inference more challenging
making robust inference difficult if there is potential for time trends
making the trial more challenging to implement in practice.
My understanding of the authors' position is that it depends on the trial design. Drop-the-Loser, for example, would perform very well on issues 1 through 4. Other methods, less so. I only omit 5 as CRO are currently ill-equipped to run these studies - there's no fundamental reason for this and if demand increased, this obstacle would reduce. In the mean time, this unfortunately does raise the burden on the investigating team.
if what standard care entails changes due to changing guidelines
This is not an objection I've heard before. I presume the effect of this would be equivalent to the presence of a time trend. Hence some designs would perform well (DTL, DBCD, etc) and others wouldn't (TS, FLGI, etc).
Adaptive designs generally require knowledge of outcomes to inform randomisation of future enrolees.
This is often true, although generalised methods built to address this can be found. See here for example.
In summary: While I think that these difficulties can often be overcome, they should not be ignored. Teams should go in eyes open, aware that they may have to do more themselves than typical. Read, discuss, make a plan, implement it. Know each option's drawbacks. Also know their advantages.
Hope that makes sense.
The Relative Ethicalness of Clinical Trial Designs
Clinical trials feature the 'explore-exploit' trade-off.
Clinical trial designs exist on a possibility frontier.
If you are going to pick a trial design that isn't on the frontier of power and patient benefit, make sure you have a good reason.
This has controversial implications because the standard RCT design - "we should randomise half the patients to one treatment, half to the other and then take stock of the results" - is not on that frontier.
EA funders and researchers should make an effort to consider research methods that, for any given statistical power, maximise the number of treatment successes.
This post is aimed at EAs who use RCTs and EAs who fund projects that use RCTs.
Thanks to Nathan Young and my dad for reviewing early versions of this post.
Introduction
Medical research trials balance several aims. They should
be very likely to find the right answer
give as many people as possible the best treatment, and
be cheap.
These aims are in tension. If we gave every patient the treatment we think is best, we'd learn nothing about the relative safety and efficacy of the treatments. If we give half the patients one treatment and the other half the other, we'd learn a reasonable amount but in doing so we'd give half patients a treatment that might - fairly quickly - seem obviously bad.
This is known as the explore vs exploit trade-off.[1]
Some trial designs achieve one aim at the expense of another. Some trial designs achieve none.
It is the job of the team designing the trial to choose a trial design that balances this trade-off. They should ensure that the design they use is on the efficient frontier.
Trial Designs
In clinical trials, there are lots of ways to decide who gets which treatment.
One popular method is Equal Randomisation (ER): randomly assign half the patients one treatment, and the other half the other, in a 1:1 allocation ratio. This method is reasonably powerful and it is relatively simple to implement. ER does not - despite a widespread misconception to the contrary - maximise statistical power in general. As we will see shortly, other methods often achieve higher power.
Another method is Thompson Sampling (TS): the probability a patient gets assigned a treatment should match the probability that that treatment is best. Since this probability depends on the interim results of the trial, it is an example of an adaptive design. TS is less statistically powerful than ER but outperforms in terms of patient benefit - it quickly figures out which treatment is best and, as it grows in certainty, gives more and more patients that treatment.
In fact, there are many many trial designs. Some maximise statistical power; some patient benefit. Others some mixture of the two. For a recent review of trial designs see Robertson et al (2023).
The Patient-Benefit-Power Frontier
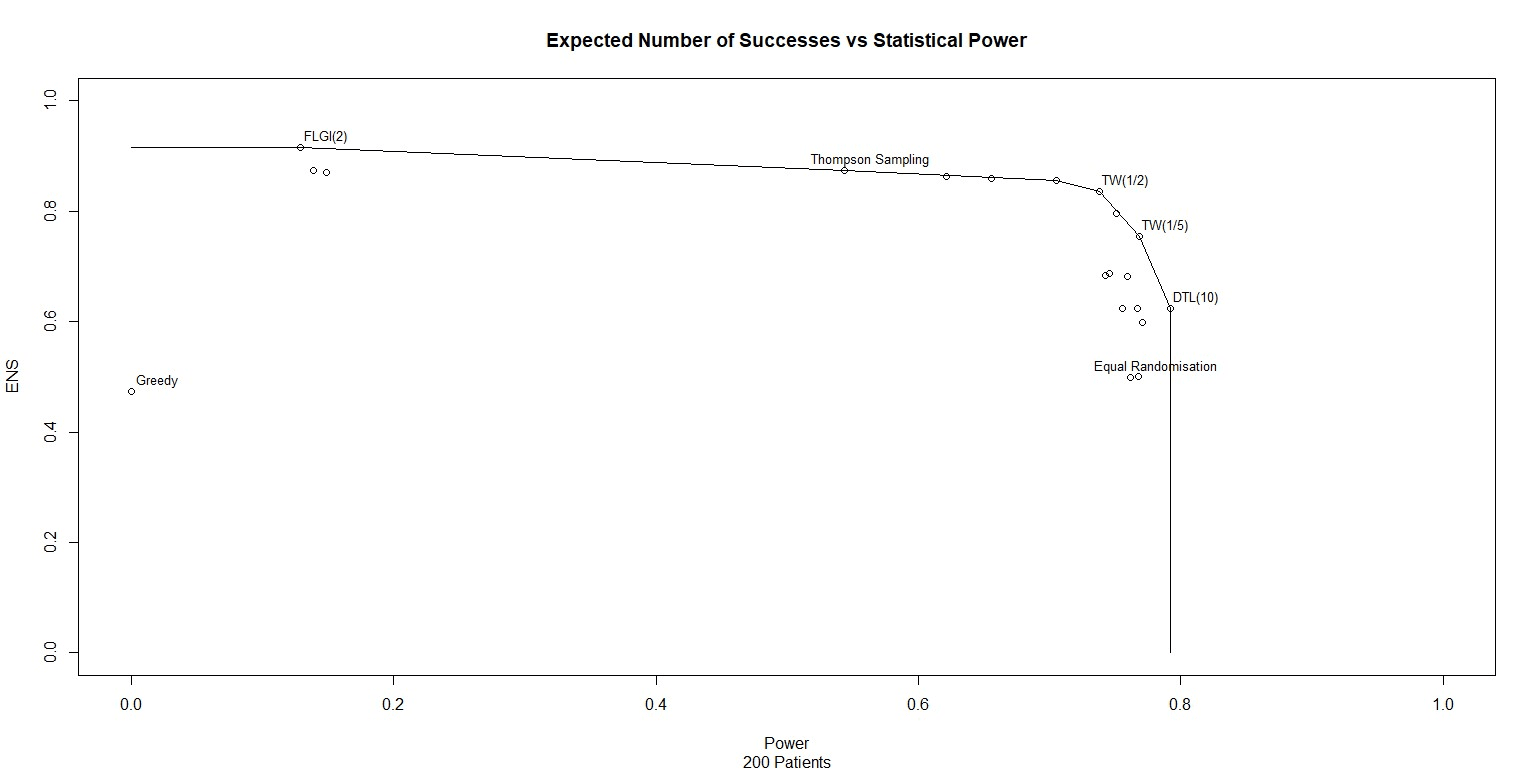
We can take these designs, simulate them and observe the effective power and expected patient benefit. I have done this for 20 different trial designs and plotted the results in Figure 1. Note that I have also drawn a line through the points on the patient-benefit-power frontier, points where no other trial design outperforms on both power and patient benefit.
Figure 1: A scatter plot showing the results of a simulation study with binary endpoints, uniform priors and trials of 200 patients. Shown is the expected power and expected number of successes for 20 various trial designs. Also plotted is a line through the points on the efficient frontier.
Inspecting Figure 1 confirms several things.
Some trial designs are not on the efficient frontier.
One the efficient frontier, there is a trade-off between power and patient benefit.
The common research method of allocating half the patients to one treatment and half the patients to the other is labelled "Equal Randomisation" on the plot. We can see that Equal Randomisation is not on the frontier either. If you want to maximise statistical power, allocate patients using Drop The Loser (DTL) or some similar method. These alternatives, as well as being more powerful, are also more likely to give patients the best treatment.
Conclusions
Human capital related constraints aside, there are few reasons to use an allocation strategy that isn't on the efficient frontier.
Because choosing a strategy that isn't on the efficient frontier involves reducing the safety/efficacy of the treatments for no corresponding gain of statistical power, unless practical reasons have ruled out all strategies which dominate them, it is plainly unethical to use allocation strategies that aren't on the efficient frontier.[2]
Figure 1 shows that, under the assumed priors, Equal Randomisation is not on the patient-benefit-power frontier. As stated in Robertson et al (2023), in general "ER does not maximize the power for a given n when responses are binary. The notion that ER maximises power in general is an established belief that appears in many papers but it only holds in specific settings (e.g. if comparing means of two normally-distributed outcomes with a common variance)." So unless very specific statistical conditions are met, or unless all the trial designs which dominate it have been ruled out for practical reasons, it is unethical for clinical trials to use Equal Randomisation.
With the priors and sample size used in Figure 1, we can see that using Equal Randomisation adds no additional power over TW(1/5) and yet results in 25% fewer treatment successes!
Implications for EA
I don't want to overstate my case; adaptive trials can have downsides. They are, for example, operationally harder to run, they can be harder to explain and regulatory bodies will be less familiar with them relative to more standard study designs.
The main message I want EAs to take away is this: If you are going to pick a trial design that isn't on the frontier of power and patient benefit, make sure you have a good reason.
If you know someone running an RCT, ask them if other trial designs, holding sample size and statistical power constant, would have higher expected patient benefit. If they're not using those designs or if they've not considered the question, ask them why not. (Reasonable answers very much do exist.)
If you are designing an RCT, consider adaptive designs in addition to the standard ones. Use simulation studies to estimate the pros and cons of the different trial designs in terms of power and patient benefit. Consider whether you and your team can implement them. And make the normal considerations too. Whether you go for adaptive designs or not, I'd encourage you to strongly consider it.
For further reading, I highly recommend Robertson et al (2023).
References
Lattimore, T. and Szepesvári, C. (2020) Bandit Algorithms. 1st edn. Cambridge University Press. Available at: https://doi.org/10.1017/9781108571401.
Christian, B. and Griffiths, T. (2017) Algorithms to Live By. Paperback. William Collins.
Robertson, D.S. et al. (2023) ‘Response-adaptive randomization in clinical trials: from myths to practical considerations’, Statistical science : a review journal of the Institute of Mathematical Statistics, 38(2), pp. 185–208. Available at: https://doi.org/10.1214/22-STS865.
For a technical survey of the relevant Mathematics, see Lattimore and Szepesvári (2020). For a general discussion of this research and its applications, see Christian and Griffiths (2017).
This fairly straightforward observation has a counterintuitive and controversial implication: It is therefore unethical for doctors to just give whatever treatment seems best. The Greedy allocation strategy is not on the efficient frontier.
This is a crosspost from the new Animal Welfare Alignment Newsletter by Anima International. You can subscribe on Substack if you are interested in following these efforts. Audio reading also available on Substack.
The goals of this post are to:
1. Raise a question I see as crucially important to the goal of aligning AI to animal welfare...
“How long have you been v*g*n?”
This is one of the most common icebreakers at animal protection events. It’s a baseline assumption, and it mostly holds true: if you’re out advocating for animals not to be tortured or abused, realistically these days you are v**n, or close. And it makes for good conversation. It seems fairly safe to assume when you meet strangers.
But this assumption is hurting the movement in a way which we don’t always notice: someone new comes into the sp...
AI Use Note: Main body text entirely human written. Claude (Opus 4.8) helped develop models of animal life histories in the appendix.
Cross-posted from Good Structures.
Executive Summary
* Animal advocates sometimes make claims like “there are X of this animal...

Can you briefly explain how DTL works?
DLT is an urn-based method where treatment assignment is determined by a simulated urn. By removing balls when the treatment fails and by adding balls uniformly so that no type runs out, we can balance the trial allocation in a sensible way.
The actual algorithm, for a two treatment study:
(Source)
Extending DLT to multi-treatment settings is as simple as adding additional ball types.
Simulation studies show that DTL performs very well as a way to maximise statistical power. I've read that this is because it (1) approaches the correct ratio asymptotically and (2) has lower variance than other proposed methods, although I don't have an intuitive understanding of why this is.
I've had a look around and this paper has a nice summary of the method (and proposes how it should handle delayed responses).