Comments
Context
In October 2022 the AI Risk community kindly filled out this survey on AI Risk probabilities and timelines. Very basic research ethics is that if I use the community’s data to generate results I should try and reflect that data back to the community as soon as possible, and certainly faster than I have done. My excuse for being so tardy is that apparently my baby daughter does not respect research ethics in the slightest and came unexpectedly early, comprehensively blowing up my planned timelines.
I used the data in two places:
If you use the data for any other projects, please let me know in a comment and I will update this list.
The raw data are here. If you try and replicate my results and find slight differences this is because some participants asked to be completely anonymised and stripped from the public-facing element of the survey[1]. If you try and replicate my results and find massive differences this is because I have made a mistake somewhere!
I would always recommend digging into the raw data yourself if you are interested, but I’ve included a couple of descriptive outputs and some basic analysis below in case that isn’t practical.
Demographics
42 people took the survey (thank you very much!), of whom 37 did not request their results to be removed before making them public.
Responses were heavily weighted towards men (89%) and US respondents (64%). The majority of respondents accessed the survey via Astral Codex Ten (62%), with 22% accessing from the EA forum and 16% from LessWrong. Generally, respondents were quite educated, although there was a fairly good spread of education levels as indicated in the graph below.
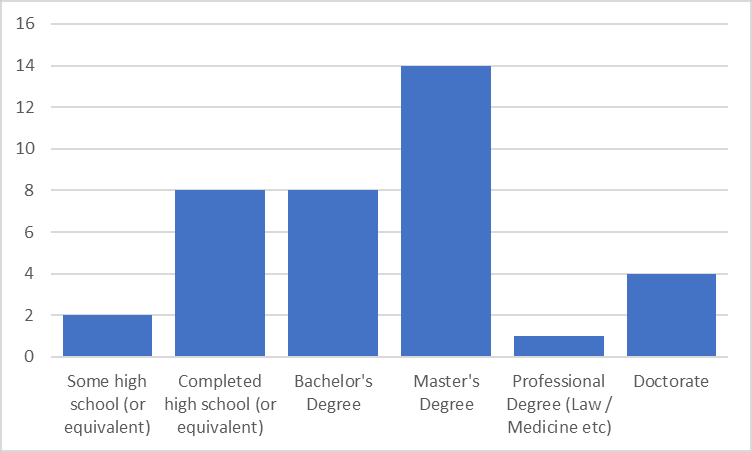
4 respondents self-identified as ‘experts’, and 7 additional respondents self-identified as ‘marginally’ expert. I have grouped these respondents together for the purposes of most of my analysis, reasoning that the ‘marginals’ were probably more likely to be 'modest experts' than a separate subcategory all by themselves. This means therefore 70% of responses were ‘nonexpert’ and 30% were ‘expert-as-defined-by-me’.
The average respondent has been interested in AI Risk for around 7 years. This is heavily skewed upwards by three respondents who have been interested for 40, 39 and 24 years respectively – the median respondent has been interested for only 5 years. Since these three long-term respondents all indicated that they were not experts, this results in the rather amusing outcome that non-experts have been involved with AI Risk longer than experts, on average (7.6 years vs 6.2 years respectively). However, removing the three long-term respondents gives the expected direction of effect, which is that non-experts tend to have been involved with AI Risk for less time than experts (4.2 years vs 6.2 years respectively)[2].
There are unfortunately insufficient data to make any reasonable claims about the relationship between any other variables and expertise.
Catastrophe responses
The average respondent believes that there is a 42% chance of AI Catastrophe conditional on AI being invented. This rises to 52% for self-identified experts. If Catastrophe occurs, the average respondent believes that there is a 42.8% chance it will be due to an in-control AI performing exactly the instruction it was given (“Design and release a deadly virus”) and a 56.1% chance it will be due to an Out-of-Control AI. These don’t quite add up to 100% because some respondents indicated that there was a third option I didn’t properly consider (most commonly arguments that the Catastrophe could be caused by a combination of in-control and out-of-control actions which don’t neatly fit into exactly one bucket[3]). There is a significant difference between experts and non-experts in this respect; experts believe 32.8% of Catastrophes will be due to in-control AI and 72.6% due to out-of-control AI (also note these add up to more than 100%, for basically the same reason as far as I can make out).
I didn’t ask when people expected Catastrophe to occur, which is one of many weaknesses of the survey.
I also asked about the probability and timelines of individual steps of Carlsmith’s 2021 model of AI risk. These are summarised below:
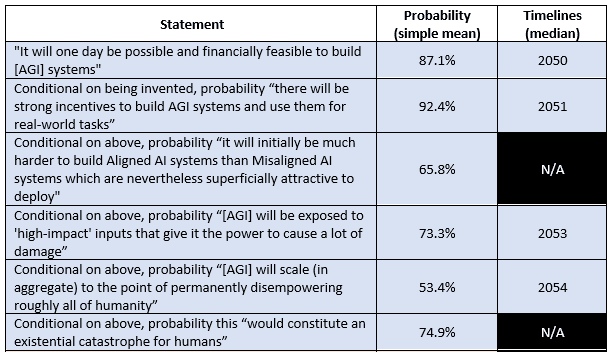
Generally, responses were similar between experts and non-experts; there were two major disagreements:
- Experts thought that conditional on being exposed to ‘high impact’ inputs there was a significantly higher chance that the AI would scale in aggregate to the point of permanently disempowering all of humanity. In the anonymised survey response, the experts have a probability of 63.7% (but if you include the experts who asked to be anonymised this jumps to 75.9%!).
- Experts thought that the time for this step to occur would be much shorter than non-experts (1.0 years median vs 6.5 years median respectively)
My observation here – which I also made in the essay on parameter uncertainty – is that there is a likely some fairly high impact work in communicating the urgency of this step in particular to non-experts, since it appears experts are considerably more worried about AIs scaling to disempower us than non-experts. I also made the observation in the essay on structural uncertainty that there is a tendency to create 'grand unified theories' of AI Risk rather than focussing on specific steps when discussing and describing AI Risk. Connecting those two thoughts together here; it might be that Experts assume that everybody knows that Disempowerment is a very high risk step, and so when they assert that AI Risk is higher than everyone else thinks they are assuming everyone is more or less working with the same model structure as them. But unless that step is explicitly spelled out, I think people will continue to be confused because non-experts don't have the same sort of model, so the apparent impression will be of experts getting frustrated about points that seem irrelevant.
The derived probability of catastrophe was 22% for all respondents and 29% for experts specifically. This is notably lower than the directly elicited probability of catastrophe – almost halving the risk. To some extent, this reflects a very common cognitive bias that asking about lots of small steps in a process gives you different answers than asking about the probability of the process in toto. It may also reflect one of my very favourite drums to bang, which is that distributions are frequently more important than point estimates. In particular, using the geomean of directly elicited estimates gives you a number much closer to 22% and this might be a better way of averaging forecasts than the simple mean. Finally it might reflect that some people have models of AI Risk which don’t track perfectly onto the Carlsmith model, and be a statement to the effect that the Carlsmith model captures only about half of the Catastrophe probability mass. Sadly for such an important point I don’t really have any way of investigating further.
The median timeline for AI Catastrophe was 2054 considering all responses, and 2045 considering expert responses only. This indicates experts tended to believe AI Catastrophe was both more likely and coming faster than non-experts, which is consistent with their directly-elicited probabilities of Catastrophe.
Alignment responses
22 individuals indicated that they believed there was some date by which “Unaligned AGI ceases to be a risk”. Participants were instructed to leave blank any question which they did not think had an answer, which means that – potentially – respondents believed there was a 64% chance that Alignment in the strongest sense was possible. I say ‘potentially’ because people may have left the question blank simply because they didn’t have a good guess for the answer, so 64% represents a lower bound for the probability that Alignment is possible. Because the number of respondents is starting to get quite small here, I haven’t distinguished between expert and non-expert responses below.
The median date people predict Alignment will happen in the strong sense of causing AI to cease to be a risk is 2066. However, I asked a couple of probing questions to see if I had understood these responses correctly. The median date by which people believe there will be a TEST to detect whether an AI is Aligned or not was 2053, and the median date by which people believe we will have a METHOD to build a provably Aligned AI is 2063. The difference between building provably Aligned AIs to ‘solving the Alignment problem’ which takes three years is because of an additional step of making Aligned AIs approximately as easy to build as Unaligned AIs (so nobody has any incentive to deploy Unaligned AIs). Indeed, the median response is 3 years for this step so people's answers are extremely internally consistent.
However, these figures hide a very wide distribution in responses. For example, not everyone (27% of respondents) believed that Strong Alignment necessarily followed from the TEST / METHOD definitions of Alignment I described above – they thought that we would solve Alignment before developing a test for Alignment or developing a method to build provably Aligned AIs[4]. Nor did everyone believe that the gap between developing the capability to build AIs and making them practically easy to deploy would be short – despite the median being 3 years, the average was 12 years.
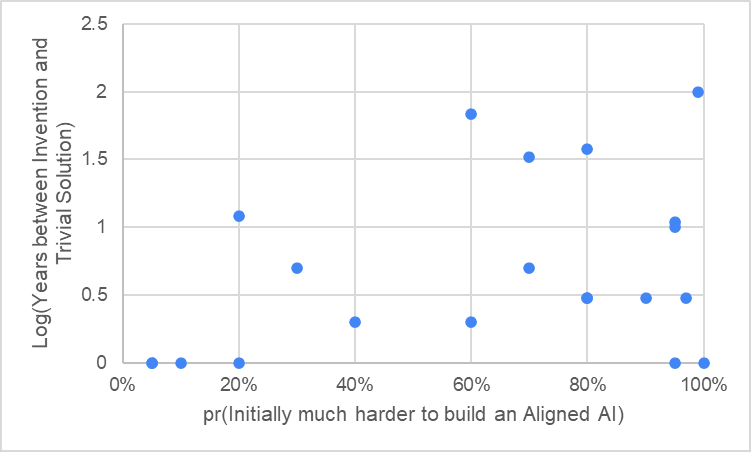
I think there may be something fairly important I’m missing about the way I framed the questions, because there is a very poor correlation between people’s answers to the Carlsmith-like question "Conditional on AGI being possible to build, it will initially be much harder to build Aligned AI systems than Misaligned AI systems which are nevertheless superficially attractive to deploy" and their Alignment timeline estimates. For example in the graph below you can see basically a random cloud of points, and some points I would expect to essentially never show up; for example in the bottom right you can see people with ~100% probability that it will initially be harder to deploy Aligned than Unaligned systems who nevertheless have a very short best guess for how long it will be between finding any solution to Alignment and finding a trivial solution. This isn’t logically incoherent by any means – a very sensible path to finding a trivial solution to Alignment will be to experiment with complex solutions to Alignment – it just seems weird to me that there’s no correlation when I would expect one.
Newcome responses
Finally, for my own interested, I asked people about ‘Newcombe’s Box Paradox’. In this philosophical thought experiment, you are shown two boxes; inside one is $1000 that you are certain exists (the box is transparent, perhaps), and inside the other is either nothing or $1,000,000 but you don’t know which. You can collect the money from inside either the second box alone or from both the first and second box together. A super powerful predictor – perhaps an AI to keep with the flavour of the rest of this post – has put $1,000,000 in the second box if they predict you will choose the second box alone and $0 in the second box if they predict you will choose both. The predictor is just a predictor, and can’t change what it has already put in the box. What option do you choose?

I run an informal forecasting tournament with my friends and ask this question every year. So far I’ve not seen a clear signal that one-boxers or two-boxers are better forecasters, but I live in hope!
Of the respondents with an opinion, 78% one-box and 9% two-box. The remaining 13% have a solution to the problem which is more complicated, which I regret not asking about as I absolutely love this paradox. Self-identified experts only ever one-boxed but this would have occurred by chance about half the time anyway even if experts were no different to the general population.
One-boxers and two-boxers differ in a number of interesting and probably-not statistically significant ways. For example, the average one-boxer believes that AI will be invented much later than the average two-boxer (mean 2075 vs 2042, driven by some big one-boxer outliers). They also believe Alignment will come much later (mean 2146 vs 2055, again driven by some big outliers and hence why I use median for these figures in general). Their overall probabilities of Catastrophe are similar but still different enough to comment on – 41% for one-boxers and 68% for two-boxers.
If we can rely on these statistics (which I stress again: we cannot) then this suggests those who believe AI is coming soon and going to be dangerous are more likely to ignore the predictive power of the AI and just grab both boxes, whereas those who believe AI is coming later and going to be less dangerous are more likely to defer to the predictive power of the AI and take only the one box the AI won’t punish them for. This seems to be the wrong way around from what I'd expect it to be, so answers on the back of a postcard please!
- ^
If you have a lot of time and energy you can work out what the missing values must have been by looking at the raw data in the Excel models associated with the essays above. However, I have made sure there is no way to reconstruct the individual chains of logic from these documents, usually by arranging all results in size order so there is no way to connect any particular guess with any particular anonymous participant.
- ^
Two of the very long-term respondents completed a column indicating that they would prefer to have their data pseudonymised rather than fully anonymised – if you are either ‘Geoffrey Miller’ or ‘Eric Moyer's Wild Guesses’ I’d be very interested in hearing from you in the comments as to why you do not consider yourself an expert despite multiple decades of following the field. My working theory is that AI Risk is a field which moves very rapidly and so you’d expect an inverted ‘bathtub curve’ of expertise, as shown below, where people are most productive after a few years of training and then gradually lose their cutting edge as the field advances. This is sort of what we see in the data, but I’d need a lot more responses to be sure. And perhaps these individuals had a totally different reason for why they’ve self-described in that way!
- ^
For example, one comment I received is that an AI might be tasked with doing something locally good for a small number of humans but globally bad for a lot of humans. If there were a lot of these ‘negative sum’ requests of AI the end result might be Catastrophe, even though no AI ever acts out-of-control and no human ever orders an AI to cause a Catastrophe.
Interestingly non-experts tended to think of this sort of scenario as ‘neither IC or OOC’ whereas experts tended to think of it as ‘both IC and OOC’. There were too few experts to read much into this, but it is certainly an interesting difference between the groups.
- ^
For example, we might have a method to randomly generate lots and lots of AI candidates, then TEST all and see which are Aligned. This solves the Alignment problem for a pretty brute-force definition of ‘solving the Alignment problem’ and may have been what these respondents had in mind