psyched about this post, want to jot down a quick nit-pick
S-Risk can occur any time from now until the end of the race, and represents – for example - a totalitarian government seizing control of the world to such an extent that human flourishing is permanently curtailed, but the development of AI is not (so S-Risk can occur before AI is Invented).
I don't think curtailing human flourishing constitutes s-risk, I don't think the suffering-focused community likes to draw equivalences between opportunity cost and more immediate or obvious disvalue. When the s-risk community talks about malevolent actors (see CLR), they're talking more about associations between totalitarianism and willingness/ability to literally-torture at scale, whereas other theorists (not in the suffering-focused community) may worry about a flavor of totalitarianism where everyone has reasonable quality of life they just can't steer or exit.
One citation for the idea that opportunity costs (say all progress but spacefaring continues) and literally everyone literally dying is morally similar is the precipice. We can (polarizingly!) talk about "existential risk" not equalling "extinction risk" but equaling under some value function. This is one way of thinking about totalitarianism in the longtermist community.
Political freedoms and the valence of day to day experience aren't necessarily the exact same thing.
Analysts discussing AI Risk should describe the structure of their model much more explicitly. I observe there is a bit of a tendency on the forums to be cagey about one’s ‘actual’ model of AI Risk when presenting estimates of Catastrophe, and imply that the ‘actual’ model of AI Risk one has is significantly more complicated than could possibly be explained in the space of a single post (phrases like, “This is roughly my model” are a signifier of this).
This is an entry into the Open Philanthropy AI Worldview Contest. It investigates the risk of Catastrophe due to an Out-of-Control AI. It makes the case that that model structure is a significant blindspot in AI risk analysis, and hence there is more theoretical work that needs to be done on model structure before this question can be answered with a high degree of confidence.
The bulk of the essay is a ‘proof by example’ of this claim – I identify a structural assumption which I think would have been challenged in a different field with a more established tradition of structural criticism, and demonstrate that surfacing this assumption reduce the risk of Catastrophe due to Out-of-Control (OOC) AI by around a third. Specifically, in this essay I look at what happens if we are uncertain about the timelines of AI Catastrophe and Alignment, allowing them to occur in any order.
There is currently only an inconsistent culture of peer reviewing structural assumptions in the AI Risk community, especially in comparison to the culture of critiquing parameter estimates. Since models can only be as accurate as the least accurate of these elements, I conclude that this disproportionate focus on refining parameter estimates places an avoidable upper limit on how accurate estimates of AI Risk can be. However, it also suggests some high value next steps to address the inconsistency, so there is a straightforward blueprint for addressing the issues raised in this essay.
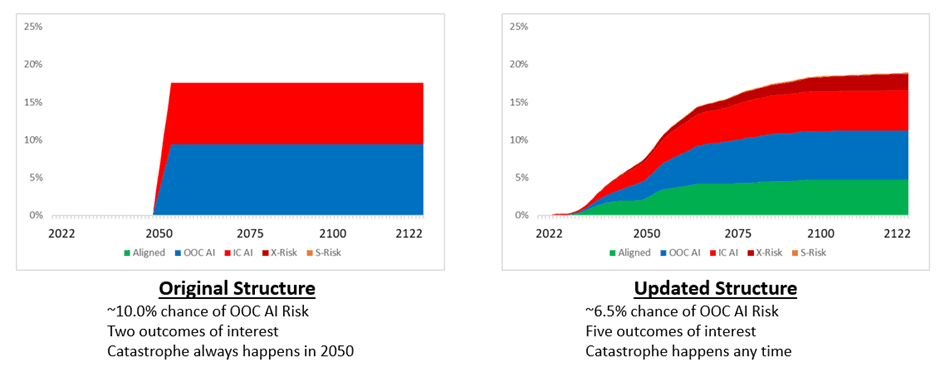
The analysis underpinning this result is available in this spreadsheet. The results themselves are displayed below. They show that introducing time dependency into the model reduces the risk of OOC AI Catastrophe from 9.8% to 6.7%:
My general approach is that I found a partially-complete piece of structural criticism on the forums here and then implemented it into a de novo predictive model based on a well-regarded existing model of AI Risk articulated by Carlsmith (2021). If results change dramatically between the two approaches then I will have found a ‘free lunch’ – value that can be added to the frontier of the AI Risk discussion without me actually having to do any intellectual work to push that frontier forward. Since the results above demonstraste quite clearly that the results have changed, I conclude that work on refining parameters has outpaced work on refining structure, and that ideally there would be a rebalancing of effort to prevent such ‘free lunches’ from going unnoticed in the future.
I perform some sensitivity analysis to show that this effect is plausible given what we know about community beliefs about AI Risk. I conclude that my amended model is probably more suitable than the standard approach taken towards AI Risk analysis, especially when there are specific time-bound elements of the decision problem that need to be investigated (such as a restriction that AI should be invented before 2070). Therefore, I conclude that hunting for other such structural assumptions is likely to be an extremely valuable use of time, since there is probably additional low-hanging fruit in the structural analysis space.
I offer some conclusions for how to take this work forwards:
There are multiple weaknesses of my model which could be addressed by someone with better knowledge of the issues in AI Alignment. For example, I assume that Alignment is solved in one discrete step which is probably not a good model of how Aligning AIs will actually play out in practice.
There are also many other opportunities for analysis in the AI Risk space where more sophisticated structure can likely resolve disagreement. For example, a live discussion in AI Risk at the moment is whether American companies pausing AI research (but not companies in other countries) raises or lowers the risk of an Unaligned AI being deployed. The sorts of time-dependency techniques described in this essay are a good fit for this sort of question (and there are other techniques which can address a range of other problems).
In general, the way that model structure is articulated and discussed could be improved by a concerted community effort. Analysts offering predictions of AI Risk could be encouraged to share the structure of their models as well as their quantitative predictions, and people reading the work of these analysts could be encouraged to highlight structural assumptions in their work which might otherwise go unnoticed.
Given the relative lack of sophistication of AI Risk model structures, I end with the argument that careful thought regarding the structure of AI Risk is likely to be extremely high impact compared to further refining AI Risk parameters, which will have a material impact in our ability to protect humanity from OOC AI Risk.
1. Introduction
In very broad terms, models can be thought of as a collection of parameters, and instructions for how we organise those parameters to correspond to some real-world phenomenon of interest. These instructions are described as the model’s ‘structure’, and include decisions like what parameters will be used to analyse the behaviour of interest and how those parameters will interact with each other. Because I am a bit of a modelling nerd I like to think of the structure as being the model’s ontology – the sorts of things need to exist within the parallel world of the model in order to answer the question we’ve set for ourselves. The impact of structure on outcomes is often under-appreciated; the structure can obviously constrain the sorts of questions you can ask, but the structure can also embody subtle differences in how the question is framed, which can have an important effect on outcomes.
In any real-world model worth building, both parameters and structure will be far too complex to capture in perfect detail. The art of building a good model is knowing when and how to make simplifying assumptions so that the dynamics of the phenomenon of interest can be investigated and (usually) the right decision can be made as a result. In my experience of teaching people to build models in a health economics context, people almost always have a laserlike focus on simplifying assumptions relating to parameters, but very frequently a blindspot when it comes to assumptions relating to structure. This is a bad habit - if your model structure is bad, spending a lot of time and effort making the parameters very accurate is not going to improve the quality of the model output overall for the same reason a bad recipe isn’t improved by following it more precisely.
My observation is that this blindspot also appears to exist in AI Risk analysis. I conducted a systematic review of the EA / LessWrong / AI Alignment forums to identify previous work done on formal models of AI risk and noticed the same imbalance between effort spent refining parameters and effort spent refining structure. For example, descriptions of what constitutes structural decision-making such as this wiki entry are incomplete and misleading, and attempts to engage the community in discussions about structural uncertainty analysis such as here have not met with significant engagement (in fairness this piece is extremely technical!).
To an outsider, one of the most obvious ways this imbalance reveals itself is by looking at the difference in the number of approaches between modelling structural approaches and modelling parameterisation approaches. When looking at parameters there are a nearly endless number of methods represented – biological anchors, expert survey, prediction markets, historical discontinuity approaches and probably a load I’ve missed because I’m not an expert in the field. However, by contrast there is – from what I can tell from my review – exactly one published structural model of AI Risk, Carlsmith (2021). This structure is replicated below. In lay terms we might think of the structure of the model as operating by describing a number of weighted coinflips which can come up ‘good’ or ‘bad’. If all of these coinflips come up ‘bad’ then we have a Catastrophe. In this sort of model, the overall risk of Catastrophe is simply the probability of each of these individual steps multiplied together. Although only Carlsmith has extensively specified his model, you can see that this sort of ‘weighted coinflip’ approach is motivating other qualitative discussions of AI Risk structures (e.g. here).
I don’t want to give the impression that Carlsmith’s approach is uncritically accepted as some kind of ‘universal modelling structure’. For example, Soares (2022) makes the excellent point that the Carlsmith model assumes through its structure that AI Catastrophe is a narrow target – six coinflips need to go against us in succession before Catastrophe occurs. Soares makes the case that in fact we could turn the problem on its head; assume that Catastrophe is the default and that a bunch of coinflips need to go in our favour for Catastrophe to be prevented. While it would have been ideal if Soares had also attached probability estimates to each step in his argument, it is a great example of the central point of this essay – model structure doesn’t just constrain the sorts of questions you can ask of a model, but also embodies subtle assumptions about how the question should be framed. Surfacing those assumptions so they can be properly debated is an important role of a modelling peer-review community[1].
Nevertheless, in comparison to the number and sophistication of analyses on the topic of AI Risk prediction, model structure is notably under-explored. With a few important exceptions like Soares’ piece, there seems to be a strong (but implicit?) consensus that there is a standard way of building a model of AI Risk, and limited incentive to explore other model structures[2]. I think there is a risk in not promoting more structural analysis in the AI Risk modelling space, since structural issues with models are often significantly pernicious – it takes an expert to spot ‘the dog that didn’t bark’ and identify that an entity or relationship which should exist in the model has instead been overlooked. This essay is attempting to serve as a proof by example of the level of predictive imprecision which can arise if AI Risk modellers spend too long focussing on parameter uncertainty and not enough time on structural uncertainty.
2. The Race to the End of Humanity”
As discussed above, the purpose of this essay is to identify an assumption in existing AI Risk models (ie Carlsmith’s paper) and show that by not making that assumption results change dramatically. The idea is that by demonstrating the way that structure can be just as important as parameters I might encourage people with a bit more expert knowledge to start producing their own discussions about structure.
With that in mind, Section 2.1 identifies and describes the assumption I will be investigating. Section 2.2 describes one method of building a model without that assumption, and Section 2.3 offers some preliminary results from the model. I save all the conclusions for Section 3 so that you can safely skip all the technical modelling stuff and still get the main insights of the essay.
2.1 The assumption of 'time independence'
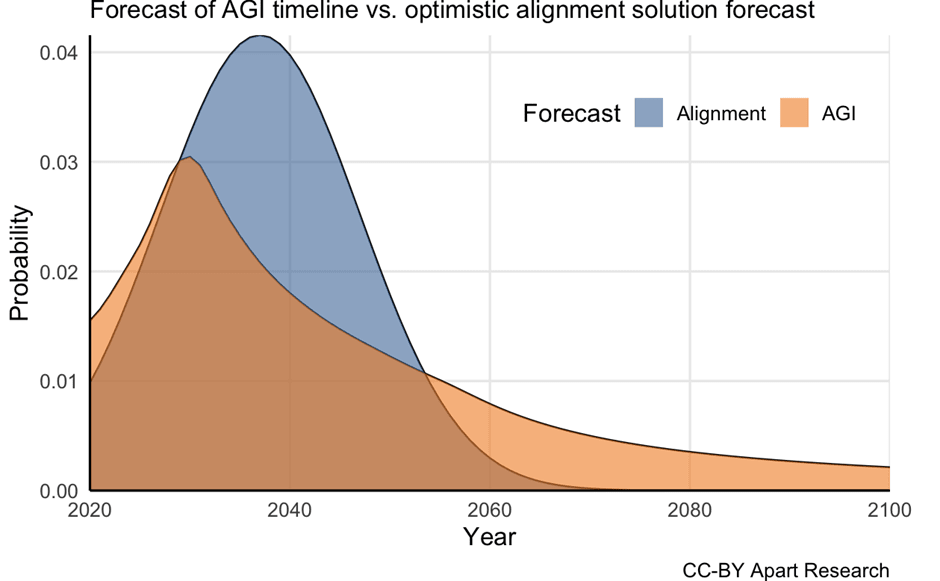
I am not an AI Risk expert so to avoid making an embarrassing error I am going to identify an assumption where the expert-level thinking has already been done for me by Apart Research, and I can focus entirely on modelling out the implications. Specifically, I am going to trace out the implications of uncertainty existing in the timelines for AI Alignment, and therefore the implication that we don’t have perfect knowledge of whether Alignment will come before Catastrophe. The motivation for this approach described in this post (and summarised very nicely by the diagram below).
The easiest way to understand what is happening in the above graph is to switch the metaphor we use to describe the model we just looked at from one of weighted coinflips to one where we are watching a runner in a one-man hurdles race. The runner starts today, and then runs down the track until they encounter a hurdle – “AI Invented”, for example. These hurdles are of variable height, and the runner clears the hurdle with some probability depending on its height (if they fail to clear the hurdle they are disqualified). When the runner finishes the race, they get to push a button which destroys all of humanity. Although the ‘runner doing hurdles to get to a doomsday button’ is a pretty convoluted way of describing a ‘weighted coinflip’, I hope you see how it is the same underlying structural problem.
However, this ‘runner in a race’ metaphor makes a very strong structural assumption about what question we are interested in – in a normal race we don’t typically care if some particular runner finishes, but rather which runner finishes the race first. Instead of the weighted coinflip approach where AI is the only runner in the hurdles race, the real world looks more like a ‘Race to End Humanity’ amongst multiple competitors. For example, a naturally occurring Catastrophic asteroid impact, global pandemic, nuclear war etc are mutually exclusive with AI Catastrophe and so if one of those happens there is no possibility for AI to destroy humanity later. Once humanity is destroyed, there’s no prize for second place – even if the AI competitor finishes the race somehow they’ve lost their chance to push the button and the AI cannot itself cause a Catastrophe. This is also true if an external force prevents an AI from completing the race under any circumstances – perhaps one day we will be able to Align AIs so effectively that Unaligned AI ceases to be a risk.
The Carlsmith model asks the question, “What is the probability that the runner finishes the race (rather than being disqualified)?”, but this is potentially the wrong question to be asking; some runner will always finish the race over a long enough timeframe, because there are simply no serious hurdles to stop, for example, a stellar nova from wiping out humanity. What we are interested in instead is rather the probability that AI finishes the race first. We cannot answer the question “What is the probability that humanity will suffer an existential Catastrophe due to loss of control over an AGI system?” in isolation from other potential causes of Catastrophe, since the first Catastrophe (or Alignment) automatically precludes any other Catastrophe (or Alignment) in the relevant sense any human being cares about. And if we are interested in the first of something, we need a way to track when events are occurring. This can’t really be done in a ‘weighted coinflips’ model, so we can be fairly confident that Carlsmith’s model oversimplifies[3].
It happens that the specific change I have identified here has a technical name – ‘time dependency’. Time dependency is a general name for any situation where the model exhibits dynamic behaviour with respect to time; most commonly that parameters change over time (as in this case, where the probability of achieving Alignment changes over time) but you can have very exotic time dependent models too, where the entire structure of the model changes repeatedly over its runtime. The structural change this model needs can be summed up in a single sentence: Carlsmith’s model of Alignment is time-independent (‘static’) whereas I think the real-world process of Alignment is likely time-dependent (‘dynamic’). As an added bonus, adding time-dependency for the purpose of modelling Alignment will allow me to investigate other time-dependent elements like X-Risk and S-Risk which I’m fairly sure are unimportant but there’s no harm in checking!
2.2 Time dependency in a Carlsmith-like model
If you consult a modelling textbook it will tell you in no uncertain terms that you should absolutely not try and encode time dependent behaviour into a ‘weighted coinflip’ model like the Carlsmith model, and that there are instead specific model structures which handle time dependence very gracefully. However, I wanted to try and keep the Carlsmith structure as far as I could, partly because I didn’t know what other assumptions I might accidentally encode if I deviated a long way off the accepted approach in the field and partly because I wanted to show that it was only the structural decision about time-dependency that was driving results (not any of the other modelling dark arts I would employ to create a more typical modelling structure for this kind of problem). Disappointingly, it turns out that the textbooks are bang on the money here – the model I came up with is extremely inelegant and in hindsight I wish I’d taken my own advice and thought a bit harder about model structure before I made it!
Nevertheless, I did succeed in making a model structure that was almost exactly like the Carlsmith model but which had the ability to look at time-dependent results. The model is available here, and it might be helpful to have it open to follow along with the next section. The structure is below:
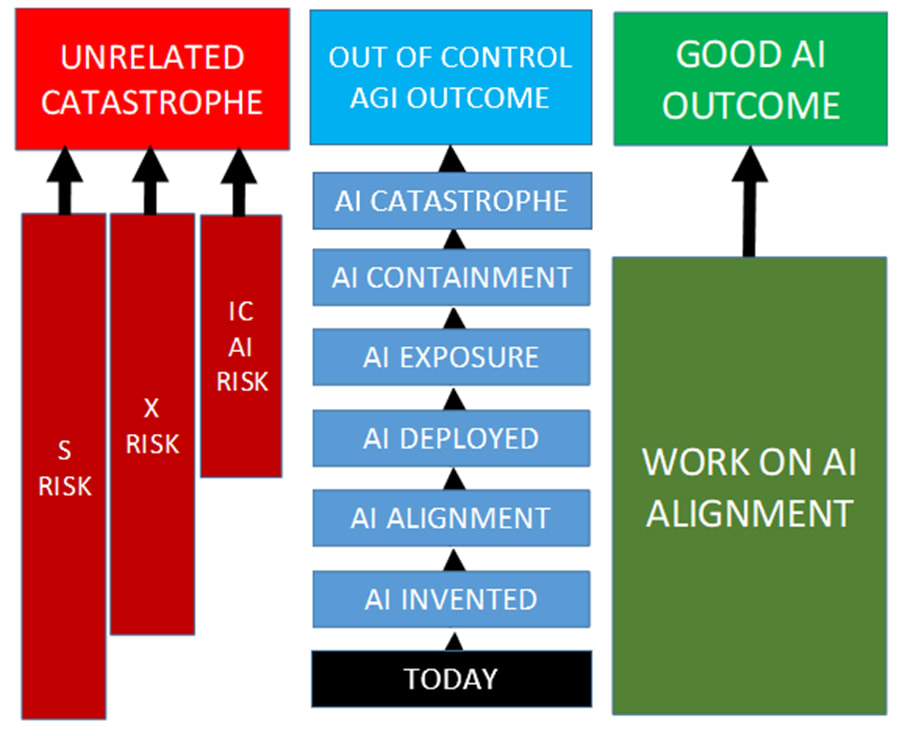
The general principle of the model is that each box represents an event which will occur with some probability (like in the Carlsmith model), but also each arrow indicating a transition between events represents a certain amount of time. There are three ‘runners’ in this model, ‘Unrelated Catastrophe’, ‘Out of Control AGI Outcome’ and ‘Good AI Outcome’. Once every runner has finished, I work out how long they took and then calculate who the winner was after everyone is finished. Parameter uncertainty about the time between each step is extremely important (otherwise the race will always have the same winner provided that runner finishes), so I simulate the ‘race’ thousands of times with different starting parameters drawn from a survey of the AI Risk community and look at the probability that each participant wins.
The three possible outcomes from the model are:
Unrelated Catastrophe – Representing any bad outcome for humanity that isn’t explicitly caused by an Out-of-Control AI. There are three sub-elements of this outcome, which have the interesting feature of beginning the race at different times:
S-Risk can occur any time from now until the end of the race, and represents – for example - a totalitarian government seizing control of the world to such an extent that human flourishing is permanently curtailed, but the development of AI is not (so S-Risk can occur before AI is Invented).
X-Risk can occur any time from AI Invention until the end of the race (since if X-Risk occurs before AI is invented then by definition AI cannot cause a Catastrophe). It represents any non-AI source of mass human extinction, for example an asteroid impact or deadly viral pandemic.
IC AI Risk is a one-off risk which is tested for if AI causes a Catastrophe. It represents a Catastrophic event where an AI is deliberately used to cause a mass extinction (like X-Risk) or subjugate the population of the world (like S-Risk). Since Carlsmith does not distinguish between ‘in control’ and ‘out of control’ AI Risk this element is needed to avoid overestimating OOC AI Risk versus the Carlsmith model. Because it isn't time dependent it isn’t very interesting from a modelling perspective.
OOC AI Risk represents a Catastrophic event caused by an AI doing something a human did not want it to. This could be either the AI pursuing its own project entirely, or misunderstanding the task it was instructed to undertake which nevertheless causes a Catastrophe. The events leading up to a Catastrophe are taken directly from the Carlsmith model, although it is assumed that AI will always be invented prior to 2070 so in effect the OOC AI Risk runner gets a bit of a headstart over the other competitors.
AI Alignment represents achieving a solution to Alignment so perfect that the risk of Out-of-Control AI plunges to zero. In hindsight I might have been a bit over-zealous in defining Alignment in this way, and perhaps humanity might be satisfied with an Alignment solution which merely reduces the risk of Catastrophe to some known and tolerable level (say, on the order of the risk of nuclear war). AI Alignment is by far the most likely outcome of the race because in most worlds AI Catastrophe does not occur so there is effectively infinite time to find an Alignment solution (in the model). Consequently, I employ a modelling convenience to get more sensible results out of the model – I only count Alignment events which actually prevent Catastrophe, rather than any Alignment event which actually occurs (or even Alignment events which occur before the AI Catastrophe timebomb has defused itself by sheer good luck). This is just a presentational trick which doesn’t alter the probability of OOC AI Risk, but it does lead to a significant underestimate of how many worlds will eventually see an Aligned AI.
Note that ‘AI ALIGNMENT’ in the OOC AI Risk track represents Alignment being so trivially easy that we don’t have to do any work to achieve it, whereas AI Alignment in the green boxes represents Alignment which is tough but possible. The idea here is to get at the distinction between the bit of the Alignment problem which is affected by longer timelines and the bit that isn’t.
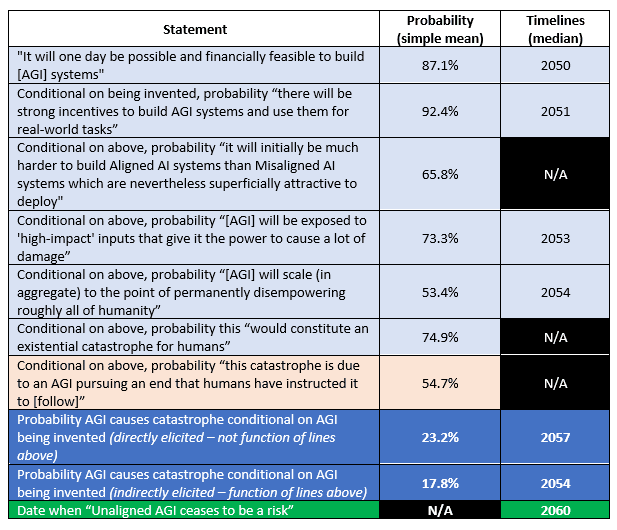
The model is populated from a survey of the AI Risk community I conducted in 2022. I am not a triallist and have no particular expertise in survey design beyond hobbyist projects, so in hindsight there are some design errors with the survey. In particular, note that the instrument does not condition on the catastrophe occurring by 2070, and since receiving feedback on my first AI essay I realise that some of the questions are quite ambiguous. Nevertheless, the responses from the survey seem mostly in line with the Carlsmith model / community consensus and have good internal consistency:
The community believes that there is a 17.8% chance of Catastrophe conditional on AI being invented, but because the distinction between In-Control and Out-of-Control Catastrophe matters it is perhaps more relevant to say that the community believes there is a 9.7% risk of Out-of-Control AI Catastrophe. Of interest is that the median Catastrophe date is 2054-2057 (depending on the elicitation technique used) compared to a median Alignment date of 2060. The conventional model structure which uses median timelines indicates that we will miss Alignment by an agonisingly small margin.
The base case of the model uses the data in the following way:
The only feature of significant interest here is that I have set all the transition probabilities to a fixed value, corresponding to their mean (by contrast I use ‘SDO sampling’ for the timelines, which is just a fancy way of saying that I pick a value at random from the set which was presented in the survey). The reason for this is that I want to prove beyond any doubt that it is the structure of the model which drives the change in results, not any fancy sampling technique like I demonstrate in the sister essay to this one. For technical reasons it actually makes no difference to do things this way, I'm just aware that the audience of this post won't all be modelling experts so I want to ensure that I remove even the perception of a modelling sleight-of-hand.
There are also a few other small features of the model initialisation which don’t really deserve their own paragraph so I will put them in the following footnote[4].
2.3 Results
Main results
The point of making these changes is not to create increasingly arcane variants of common modelling structures just for aesthetic reasons (however much I wish someone would let me do this) but rather to check whether altering our assumptions about a model’s ontology meaningfully alters the way we should approach the conclusion. There’s no fancy statistics or algorithms that are used here – we just literally compare the two results side-by-side and make qualitative remarks about whether we think the change in structure has had an important impact. This is sometimes an extremely expert process; cases where it is not clear whether an impact is important or not it can require considerable nuance to interpret results.
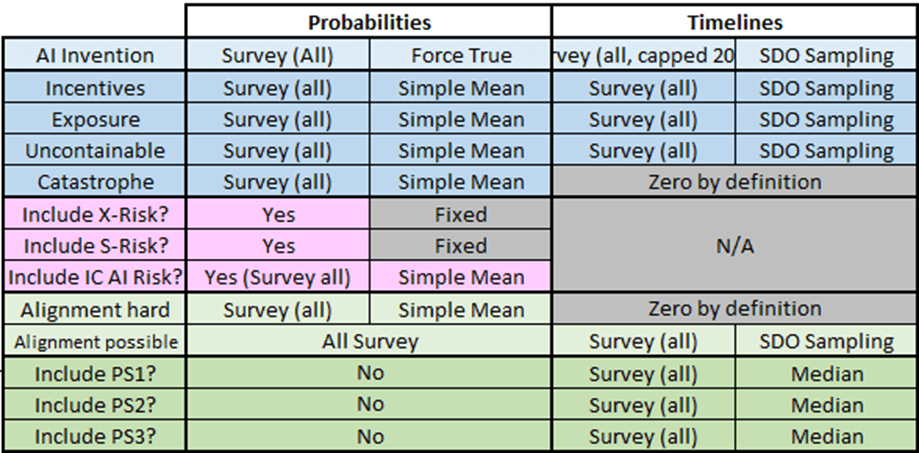
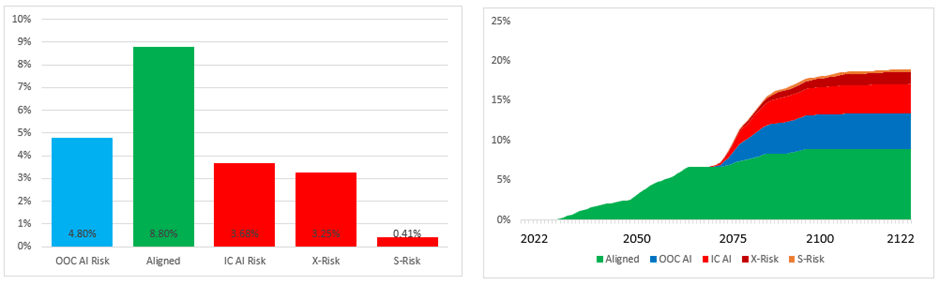
However fortunately for us, the change in model structure has had an absolutely massive impact which even a non-expert like me can tell should drive decision-making. The diagram below shows the results from running the community’s numerical assumptions through a model designed to look broadly like Carlsmith’s structural assumptions:
It gives a risk of AI Catastrophe of around 18% (ie entirely in line with the community survey as expected - all results are going to be approximate because the simulation contains a lot of random elements which change between model runs). Carlsmith doesn’t distinguish between ‘In Control’ and ‘Out of Control’ AI Risk so the value Open Philanthropy are specifically interested in is the 10% column on the far left.
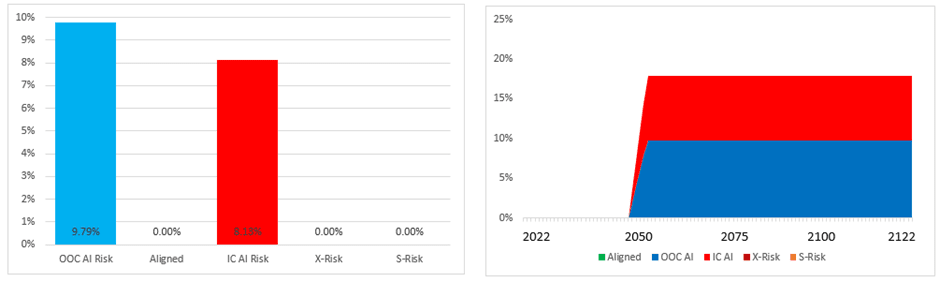
The next diagram shows the output of the base case analysis of my time-dependent model:
You can see that a nearly half of that probability mass has redistributed itself to non-AI competitors in the race, and the OOC AI Risk column has shrunk to just 6.7%. Consequently, I would conclude that accounting for time-dependency in models of AI Risk leads to an approximate 30% increase in the risk of OOC AI Catastrophe. That might be a slight overstatement of the result, because quite a lot of this probability has just found its way to other bad outcomes like nuclear war and totalitarian subjugation of humanity. Nevertheless, however you slice the result it is clear that humanity is a lot safer if we look at the full range of Alignment timelines rather than just the median timelines.
Sensitivity analysis of time
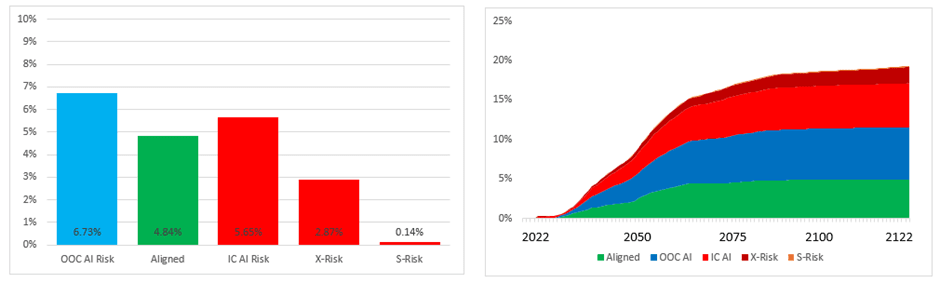
One of the interesting features of a time-dependent model is that it makes more sense of questions we might have about model dynamics. For example, Open Philanthropy are especially interested in scenarios where AI is invented prior to 2070, but are somewhat uncertain about exactly when AI will be invented conditional on that. We can see what impact the two extremes of possible impact will have by considering first the distribution of results if AI is invented in 2024:
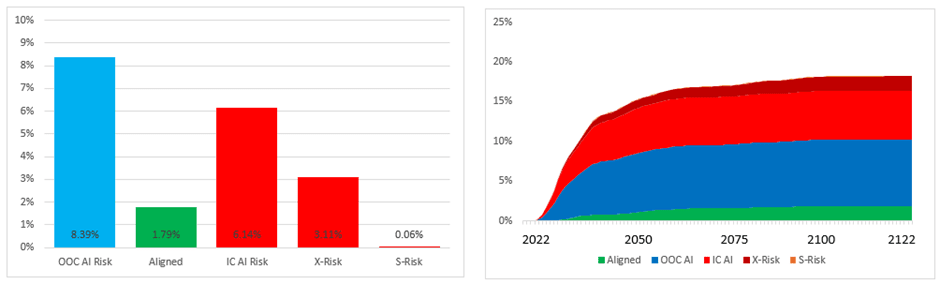
And if it is invented in 2070:
We see – as we should probably expect – that inventing AI later gives humanity a lot longer to try to find a solution for Alignment and reach a good AI future. The effect of delaying AI’s invention by ~50 years is to approximately halve the risk of OOC AI Catastrophe. As a strict output from the model we might say that a delay to AI invention of one year increases the chance that humanity survives to experience a good AI future by about 0.1% (although I’m not really confident my model is sophisticated enough to make this sort of judgement). What I can confidently say is that if you have short AI Catastrophe timelines the effect of time dependency is much less pronounced than if you have long AI Catastrophe timelines – effects which become more pronounced over time will have less of an impact if you compress the time in which they are able to occur.
Sensitivity analysis of original inputs
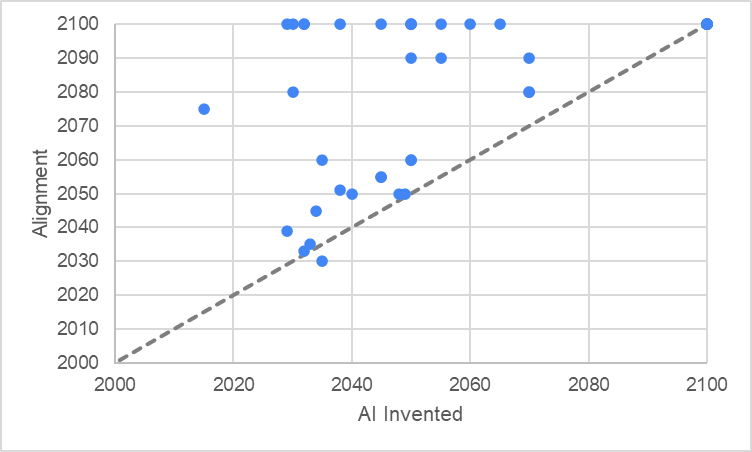
I hope these results have a ring of truth to them, because I think they reflect the uncertainty in the community survey quite accurately. The diagram below shows the community’s estimates for AI Invention timelines versus their estimates for AI Alignment timelines. The 45 degree line shows the cutoff where people believe that AI will be Aligned before it is Invented. Any datapoint at the far edge of the graph indicates that either the respondent gave a value that was too big to display or didn’t give a value and therefore is assumed to believe that AI cannot be Aligned (that is, either way they do not believe that AI will be Aligned before Invented). Only one brave iconoclast believes AI will be Aligned before it is Invented, which is why it might be surprising that adding in time dependency based on this survey makes any difference to the results.
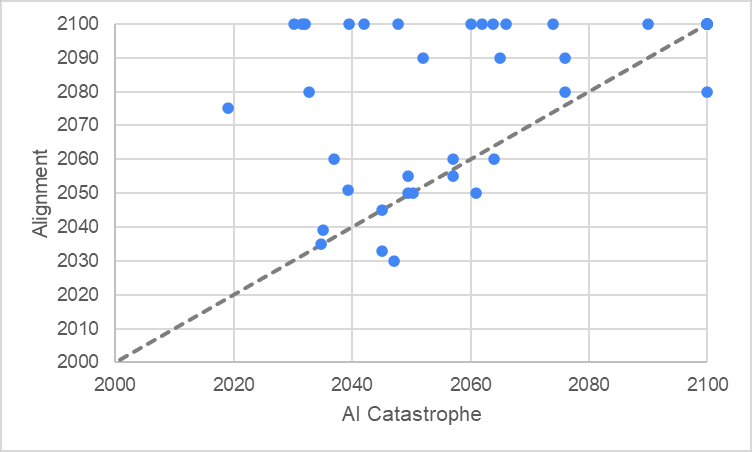
However, the next graph shows the same plotting for people’s estimates of AI Catastrophe timelines alongside their AI Alignment timelines. About 20% of responses are showing Alignment as occurring strictly before Catastrophe, and there are a few more which are almost exactly on the 45 degree line. In fact, of the respondents who believe Alignment is possible within the next century, 65% conclude that Alignment is likely to occur before Catastrophe. This is why I believe that the inclusion of time-dependency is likely to improve the way the model aggregates community forecasts; simply taking the median timelines ignores 20% of people and gives a distorted result.
3. Conclusions
This essay makes the claim that parameters of AI Risk models have been extensively cultivated, to the detriment of discussion about model structure. I present a proof by example of this claim in Section 2; overlooking time-dependency as a structural factor leads to a significant over-estimate of the risk of AI Catastrophe, because it ignores worlds in which AI Alignment is hard but possible (and the dynamic mechanisms which drive the Alignment process). As I am not an expert in AI Risk modelling, the specific numbers and results I arrive at should be taken with a degree of caution. However, I think they are sufficient for proving the key contention of this essay, which is that structural uncertainty is a significant blindspot in the way in which AI Risk is articulated and discussed. I would be extremely surprised if someone more expert than me couldn’t find an effect twice the size I managed with a trivial amount of work by combing over other commonly-accepted structural assumptions in AI Risk modelling with a fine-tooth comb.
There is a nuanced but important point involved in interpreting these results; I have not made a ‘better’ model than Carlsmith in any kind of unambiguous way. By making my model more granular I have introduced problems that Carlsmith can (correctly) ignore because his model is more abstract. This tradeoff between granularity and abstractness is a real problem in professional structural uncertainty analysis, and part of what makes modelling an art rather than a science. For the record, consider some ways in which my approach is clearly inferior to Carlsmith:
We don’t know whether the rate-limiting step for Alignment will be time (like I propose) or perhaps money / expertise / some other thing. My model can’t investigate this and so is at high risk of reaching the wrong conclusion but Carlsmith abstracts away the problem and so has more flexibility.
We don’t know whether ‘solving Alignment’ will be a one-time event (like I propose in the base case), or a multi-step process (like I propose in this footnote[5]). You have to tie my model in knots to get anything sensible out of it on this topic, whereas the Carlsmith structure is well set up to turn the main steps into smaller discrete steps if required.
We don’t know how governments will react to AI risk by speeding up or slowing down funding for Alignment research. I think both my model and the Carlsmith model struggle with this issue, and solving it would require a lot of work to both models. However, on points I’d say Carlsmith has the better of it – Carlsmith won’t currently give you the wrong answer because it abstracts this step away, whereas there is a great danger of my model being simple, compelling and wrong because it makes specific predictions about AI timelines.
My model is also way more complicated, which all other things being equal would lead you to prefer Carlsmith just on aesthetic / maintainability grounds.
I think on balance my model makes sense for the specific problem Open Philanthropy are interested in - the extra complexity of adding a time-dependent element to the model's ontology is worth it when the problem has a time-dependent element in it (such as the requirement that AI be invented before 2070). However that wouldn't necessarily be true for other problems, even problems which look quite superficially similar.
That said, there are some very clear ways in which my approach could be improved to unambiguously improve its suitability for Open Philanthropy’s question:
An obvious starting point would be to replicate my results in a more sensible model structure (ie rather than trying to cram a time-dependent structure into a deterministic decision tree, instead use an individual-level Markov Chain Monte-Carlo simulation, or even a Discrete Event Simulation if you want to flex the analyst muscles). Although I am confident my results are broadly right, there may be some interesting dynamics which are obscured by the structure I have chosen[6].
An expert in AI Risk could overhaul my approach to Alignment. For example, I list a few ways in which my model is inferior to the Carlsmith model on this point but since these are features of my implementation and not inherently a tradeoff that needs to be made when modelling they could be fixed pretty easily by someone who know what they were talking about. My implementation was to be as abstract as possible on topics I didn’t know much about, but an expert doesn’t have that constraint.
I focus very heavily on Alignment because the thinking has already been done for me on that issue. There is no particular reason other than convenience why I focussed my attention here, and it is hopefully obvious that the same approach could be applied elsewhere just as easily. For example, a live discussion in AI Risk at the moment is whether American companies pausing AI research (but not companies in other countries) raises or lowers the risk of an OOC AI being deployed; applying some time dependent dynamics to the ‘Deployment’ step in the Carlsmith model could provide excellent insight on this problem.
More generally, I can offer a few conclusions of relevance to AI Risk analysts:
Analysts discussing AI Risk should describe the structure of their model much more explicitly. I observe there is a bit of a tendency on the forums to be cagey about one’s ‘actual’ model of AI Risk when presenting estimates of Catastrophe, and imply that the ‘actual’ model of AI Risk one has is significantly more complicated than could possibly be explained in the space of a single post (phrases like, “This is roughly my model” are a signifier of this). Models should be thought of as tools which help us derive insight into dynamic processes, and not binding commitments to certain worldviews. A well-specified model which captures some essential insight about the problem is worth hundreds of posts trying to gesture at the same insight. Alongside the existing culture of productive critique of parameter assumptions, there should be a culture of open peer review explicitly calling out structural assumptions made in these models (which is made more difficult if people are vague about what exactly they are modelling).
Discussions about structures of AI Risk (what entities exist in the decision problem and how they interrelate to each other) should be treated as at least as meaningful as discussions about parameters of AI Risk. What I mean by this is that if you would accept that it is a worthwhile contribution to put some upper-bound on the risk of an ‘escaped’ AI proving to be uncontainable you should find it at least as worthwhile to have someone present a few different models of what ‘uncontainable’ might mean in practice and which of these models tend to over- or under-estimate risk in what circumstances. An excellent template for this sort of analysis is Soares (2022), which very neatly argues that the Carlsmith model will systematically underestimate the chance of Catastrophe in scenarios which are more ‘disjunctive’ (nothwithstanding that ‘conjunctive’ and ‘disjunctive’ aren’t really terms which are used outside AI Risk analysis).
Although I am pleased I’ve been able to contribute to a debate on the probabilities of AI Catastrophe, I’m under no illusions that this is the most sophisticated structural critique of AI Risk modelling that is possible; it is just the critique which I am qualified to offer. The nature of modelling is that tiny assumptions that other people overlook can have a massive impact on the eventual outcomes, and the assumptions which are important are not necessarily those which modellers are natively interested in. I believe there would be considerable value in individuals or teams taking a detailed look at each step in the Carlsmith model and hunting for further errant assumptions. I'd be delighted if experts were able to show that my work on time-dependency is ultimately a trivial footnote to the real driver of OOC AI Catastrophe Risk, since identifying the true structural drivers of risk is the first step in a plan to mitigate and ultimately defeat that risk.
There are also a handful of incomplete attempts to move beyond the ‘weighted coinflip’ approach and into more sophisticated modelling structures. The most salient of these would probably be the MTAIR project, although I believe that MTAIR is now sadly defunct following the FTX collapse.
As a hypothesis, my guess is that a lot of AI Alignment researchers come into the movement via Effective Altruism and then find the AI Catastrophe arguments convincing once they have already bought into broader EA logic. By coincidence, high-profile conventional charitable interventions (meaning, for example, those funded by GiveWell) are extremely well suited to the deterministic decision tree, and so the ‘weighted coinflip’ model is an excellent default choice in almost all conventional charity analyses. If many AI Alignment researchers have been socialised into always using the deterministic decision tree structure, and that approach always works, it is probably unsurprising that this approach becomes like water to a fish – even if it is understood that other model structures exist, there are significantly more important things to be doing than messing around with the approach that is fast, logical and has always worked in the past.
Of course, nobody – least of all Carlsmith – believes that his model really describes reality any more than I believe my new model really describes reality. Instead, Carlsmith has made a simplifying assumption that treating AI Risk timelines as implicitly fixed will still allow him to investigate the sorts of dynamics he is interested in. He is probably right about this - Carlsmith asks and answers the question, "Is Power-Seeking AI an Existential Risk?" for which he is basically looking for a binary answer ("Yes it is" or "No it isn't"). Consequently it doesn't really matter if his model oversimplifies as long as it produces robust order-of-magnitude risk estimates. However, Open Philanthropy ask the question, "Conditional on AGI being developed by 2070, what is the probability that humanity will suffer an existential catastrophe due to loss of control over an AGI system?" for which a more complex model is needed, one which can produce results on a more granular level than just order-of-magnitude.
I will revisit this theme later in the essay, but an observation that modelling outsiders sometimes miss is that there is no such thing as a 'better' or 'worse' model provided you meet some minimum bar for competence in execution. Instead, there are models which are better suited for some questions and others which are better suited for other questions. So the paragraph spawning this footnote might look like a criticism of Carlsmith when instead it is really a compliment - Carlsmith has found a very simple and elegant way of modelling what he needs which (sadly) oversimplifies relative to what I need.
A few small notes on the base case that aren't interesting enough to include in the main body of the text:
- I have forced AI to be invented before 2070, in line with Open Philanthropy’s preferences, by capping the data I generated from my survey to dates prior to then and forcing the probability it happens to be 100%.
- I have included X-Risk and S-Risk drawn from literature sources - Ord (2020) and Caplan (2008) respectively. S-Risk estimates seem very low to me - it would be extremely interesting to investigate this further in the future because I think it might be another area where some careful structural thinking could reveal some interesting insights. But it isn't AI Risk so isn't relevant for now.
- Some people did not give a date for when they thought Alignment would occur, which I interpreted as meaning they did not think it would ever be possible (backed up by reading some of their comments on their entries). I added a bit of an ad hoc term to make Alignment literally impossible in those worlds, so the only possible outcome is some sort of Catastrophe. If I ran the survey again, I would explicitly ask about this.
- PS1, PS2 and PS3 are my attempt to include some early thoughts about ‘partial successes’ in Alignment which are not as strict as the definition Carlsmith uses where Alignment reduces the risk of OOC AI to zero. I would describe my success here as ‘mixed’, so I have turned them all off for the base case.
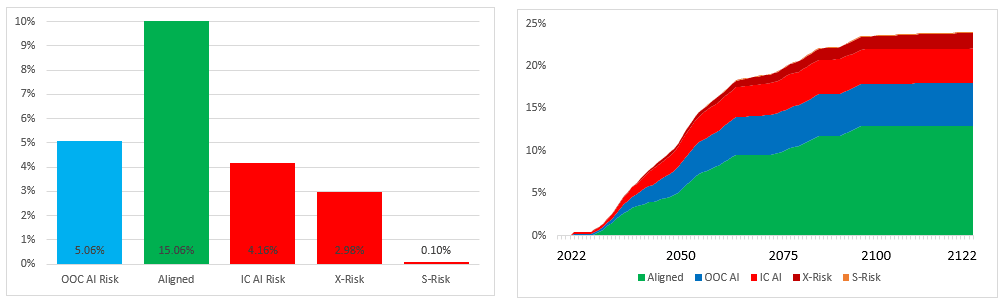
I had enough time to code up some exploratory work on the idea that 'Alignment' could be a moving target depending on how far advanced we were down the pathway towards AI Catastrophe. In the model below, ‘Alignment’ occurs either if we find a way to make AI completely safe as in the main model, but also if we develop a TEST which can show us whether an AI is aligned before we expose any AI to high-risk inputs. The intuition here is that we might be able to convince governments to act to ban unsafe AIs if we haven't already handed power to AIs, but after handing power to AIs we need some kind of 'weapon' to defeat them. The graph below shows the result of this analysis:
Unsurprisingly, this results in a significant probability mass redistribution away from AI Risk towards Alignment, as scenarios which were once the absolute worst-case for OOC AI Risk have the possibility of being defused even before AI is invented.
I got a bit anxious at the thought of presenting these alongside the main results because I think I've done a fairly good job of only talking about things I understand properly in the main body of the text, and I don't understand the nuts-and-bolts elements of Alignment at all well. But I thought people might be interested to see this even if it isn't perfect, if only to prove my point that there’s probably another halving of risk available to the first team who can present a plausible account of how a ‘multi-step’ model of alignment could work.
Part of the art of modelling is knowing when you have made the model complex enough for whatever purpose you intend to use it for. Any model which fixed the problems with my model would inevitably have problems that needed to be fixed by another model and so on. Although this conveyer belt keeps modellers like me (somewhat) gainfully employed, it can be a trap for organisations who just want to use the best possible model to make decisions, because ‘best possible’ is a moving target. As discussed above, the structure needs to match the needs of the decision problem and there isn't a generic solution for how to find the best structure for a particular job.
This is a crosspost from the new Animal Welfare Alignment Newsletter by Anima International. You can subscribe on Substack if you are interested in following these efforts. Audio reading also available on Substack.
The goals of this post are to:
1. Raise a question I see as crucially important to the goal of aligning AI to animal welfare...
Hello! I'm Justin Portela. I got hired by GWWC to make YouTube videos after AI in Context did such a kickass job.
My channel is using that same cinematic, high-production value beauty to talk about everything in the EA universe that isn't AI.
...
This is a linkpost for Request for Proposals: Research and Applied Work on Digital Minds.
I'm glad to announce a request for proposals for research and applied work on digital minds at Longview Ph...



psyched about this post, want to jot down a quick nit-pick
I don't think curtailing human flourishing constitutes s-risk, I don't think the suffering-focused community likes to draw equivalences between opportunity cost and more immediate or obvious disvalue. When the s-risk community talks about malevolent actors (see CLR), they're talking more about associations between totalitarianism and willingness/ability to literally-torture at scale, whereas other theorists (not in the suffering-focused community) may worry about a flavor of totalitarianism where everyone has reasonable quality of life they just can't steer or exit.
One citation for the idea that opportunity costs (say all progress but spacefaring continues) and literally everyone literally dying is morally similar is the precipice. We can (polarizingly!) talk about "existential risk" not equalling "extinction risk" but equaling under some value function. This is one way of thinking about totalitarianism in the longtermist community.
Political freedoms and the valence of day to day experience aren't necessarily the exact same thing.
Thank you, really interesting comment which clarifies a confusion I had when writing the essay!