TLDR; no one talks about how far we are towards safe AGI and the focus is on when AGI doom arrives. We want to readjust this focus and measure progress, guide and facilitate research, and evaluate projects in AI safety for impact. We also ask you to add your views to this survey.
Prelude
It was a hot London Summer day and fourteen people had gathered to discuss the future of AI safety. To ascertain the mission criticality of our endeavor, we drew everyone’s AGI timelines on a whiteboard. The product of our estimates was close to the Metaculus estimate and some expressed concern at the stress of impending doom.
We then proceeded to draw our expected timelines for when alignment would be solved and very few had ever analyzed this. The few that expressed their timelines ended at 15 years hence, in 2037. And I thought this was a remarkably hopeful message!
A case for hope
Let us be optimistic and expect the median arrival for the solution to alignment is 2037 estimated as a Gaussian with a standard deviation of 10 years[1]. If we estimate the probability that the solution will come before AGI based on sampling the probability mass of the Metaculus’ forecast for AGI and our “Safety Timeline” (or “alignment solution timeline”), we can calculate the probability that alignment will be solved before an AGI is released:
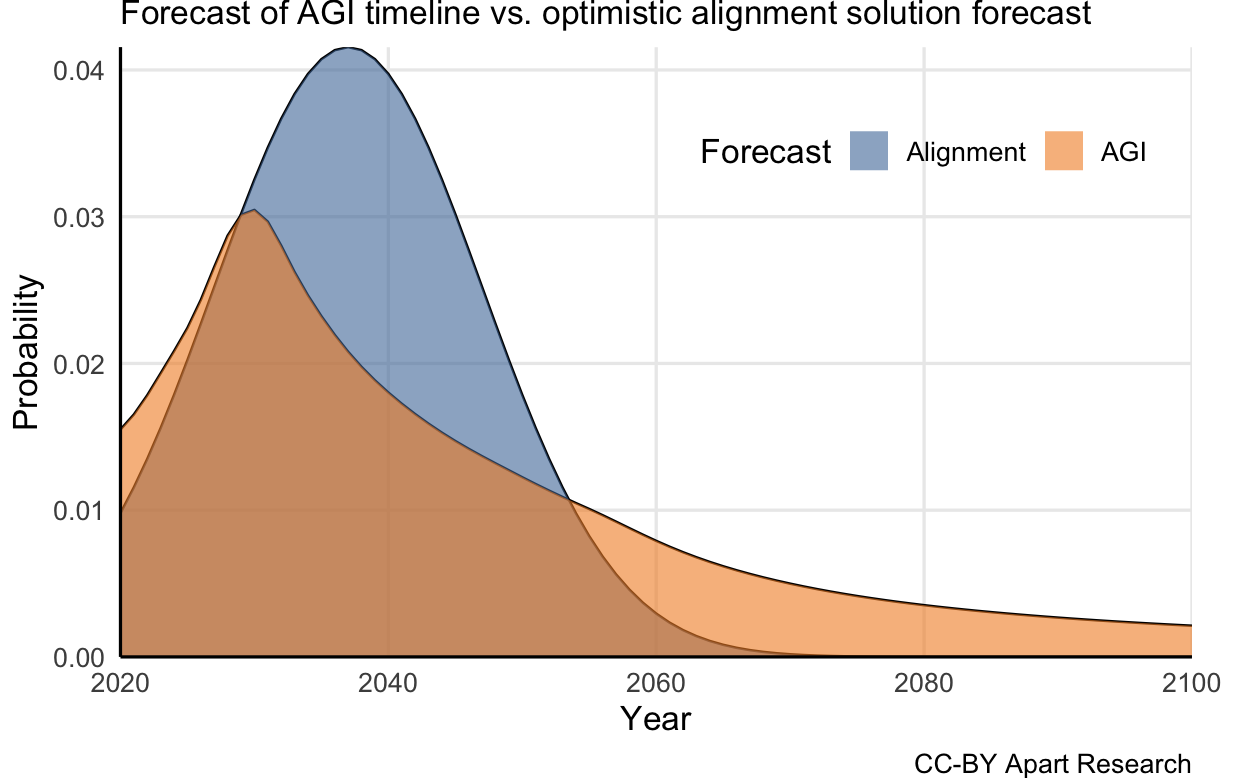
We can then insert our conditional prior for the probability that the solution will also lead to human flourishing and the prior probability of doom from AGI to calibrate P(AGI-caused doom)[2]. In this case, we set at a 90% effectiveness probability and the from 24 researchers in AI safety (see the list in the Appendix). From this, we can calculate the probability mass for the calibrated , .
Now we introduce the previous graph with the updated for any year on the AGI timelines. We calculate the uncalibrated by multiplying by the mean of estimates while is , i.e. P(doom) is multiplied by the complement of the cumulative probability distribution for safe AGI from alignment for that year:
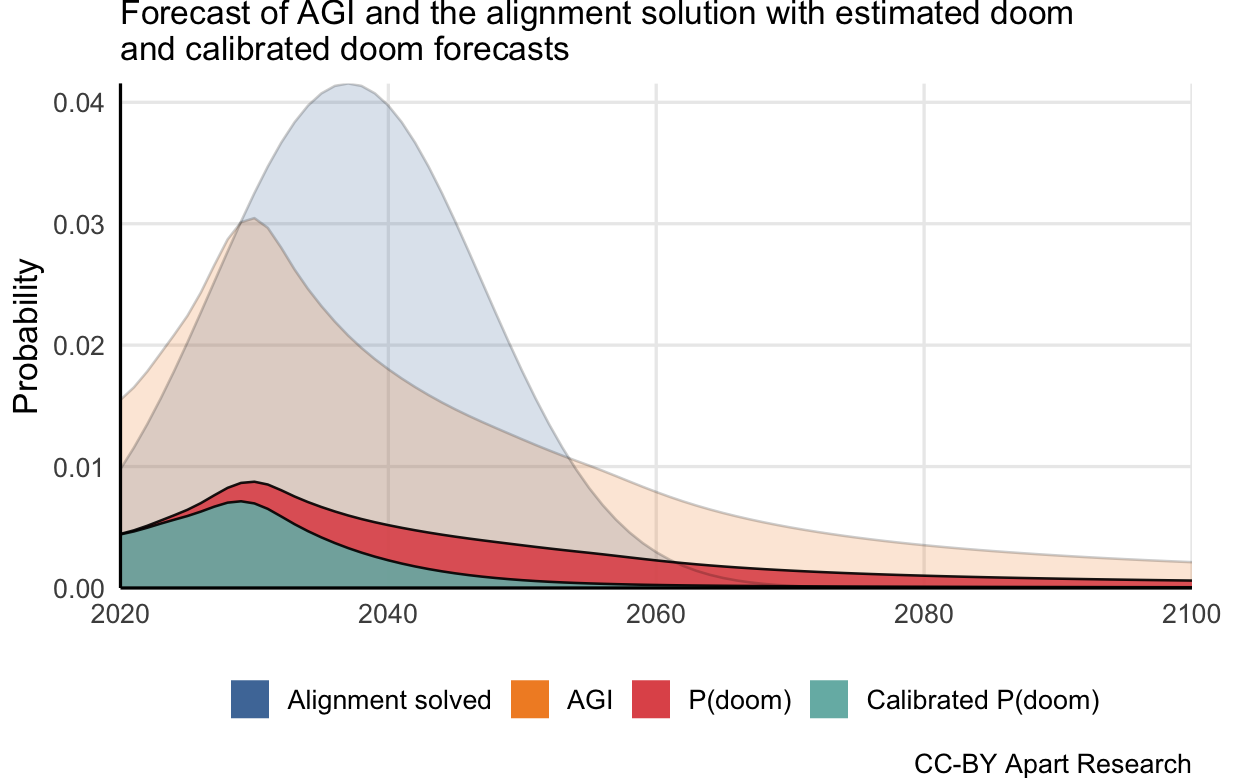
Though it might be an optimistic prior in this case, having metrics and evaluations to measure how far towards safe AGI we are seems incredibly valuable and surprisingly few attempts to measure this already exist.
Safety timelines
Even though no one seems to have explicitly forecast or evaluated our safety timelines, related literature exists to inform our work on forecasting safety timelines and what it means to have safe AGI.
What does it mean to solve alignment?
This is a very open question and something we ask your help in defining. In our novelty search for “the alignment algorithm”, most people anchor on rough judgements and BOTECs made from qualitative forecasts.
A popular judgement in AI safety is the evaluation of the so-called “P(doom)” or “the probability of doom” from our foray into artificial intelligence technology which we have already used above. The P(doom) concept has not been formally established and is most often used as a qualitative and rough estimate of our expected mission-criticality in AI safety. See the Appendix for an overview of people’s P(doom) estimates.
We imagine a proposal for qualitative evaluating alignment could look like the following survey-based evaluation:
> Will a panel of 15 recognized experts in AI safety expect a proposed alignment solution to make TAI increase human flourishing with an average above X% certainty given no malevolent human intervention if released during the subsequent 5 years?
We expect this to approximate a model of our uncertainty on what alignment looks like at this stage with the expert judgments that researchers often defer to. However, this is but one way to measure our progress towards alignment. We expect there to be many metrics to track. Some examples can be seen in the survey.
Importance of measuring progress
There are several reasons why we would like to measure progress. Some of the most important include:
- Better markers of progress allows us to measure AI safety against AGI, providing further argumentation for when we can safely deploy or stop AGI development.
- Better models of alignment solutions give us better arguments for which solutions should work and which should not. This is relevant both for differential technology research but also for people in policy.
- Benchmarks can push the AI safety field forward (with caveats): Benchmarks in ML development have guided research immensely, e.g. ImageNet and CNNs and CASP and AlphaFold.
- AI safety needs more wins, and showcasing these wins is important for AI safety to be seen as an attractive and serious field.
- AI safety is missing empiricism[3]: If we get measures of progress and an effectiveness / dollar spent for AI safety, this will integrate the empiricism of effective altruism more and make us better at evaluating the impact of future AI safety projects.
- A case for hope that has not existed until now becomes more tangible. If we understand where we made progress, we might elicit a feeling that we can actually solve alignment.
Benchmarks & data
There are already a few existing benchmarks for progress on safe AGI that attempt to measure safety or correlates of safety in AI systems. One of the most famous ones (both in ML and alignment) is TruthfulQA which is a dataset that measures the truthfulness of language models given adversarially generated text examples. It seems there are multiple issues with using it as a safety measure (though it is good as a radicalization bug fixer) and it has not had many papers that attempt state-of-the-art[4] despite its citations. However, it did stir the media on language models when it came out.
Another is Safety Gym, an OpenAI gym environment for safe exploration experiments in RL. We could not find any benchmark tracking, however it seems to have a substantial amount of citations (154) in papers with related projects so maybe it has inspired other benchmarks.
SafeLife is a benchmark for reducing side effects of goal-oriented environment interaction in complex game-like environments made by the Partnership on AI. It seems to function as a benchmark, though it has received limited traction by the community.
The inverse scaling prize has a Google Colab that generates the plots necessary to evaluate if there is inverse scaling and the prize itself is given based on reviewer feedback and automatic auditing of the results using private models. This is not scalable as a benchmark but with a bit of tweaking, it can possibly be a fully-automatic process to identify future inverse scaling laws which are relevant for inferring the capability misalignment dimensions of future large models.
Additionally, The Center for AI Safety and its affiliates have recently released several competitions in machine learning safety. The benchmark-based ones are the NeurIPS Trojan Detection Challenge, the OOD robustness challenge, and the Moral Uncertainty Competition.
All these seem like good benchmarks for sub-problems in pragmatic AI safety and from our perspective seem to have good potential. Here follows a short benchmark description of each.
The Trojan detection challenge has three tracks which all relate to the detection, generation, and analysis of neural networks that have been attacked with an adversarial perturbation that is intentionally hidden. The benchmark would consist of a training, test, and validation set of Trojaned and non-Trojaned neural networks which is quantifiable as an automatic auditing task on relevant ML metrics.
The out-of-distribution generalization in computer vision (OOD-CV) challenge has three tracks which all relate to image transformation models’ ability to generalize beyond a given training set to images that show significant differences on six different properties in its test set. This also seems like a good benchmark for explicit OOD performance evaluation.
The moral uncertainty competition directly rewards performance (AUROC) and therefore seems ideal for a benchmark (which it already is based on its leaderboard). The task is to classify if the author in a text was in the moral wrong or right given a description of a situation. The data is from AmITheAsshole and examples created by MTurk (these two example types segregate into two distinct groups if you run an embedding algorithm so they seem qualitatively and quantitatively distinct).
These all seem like good first steps towards benchmarking safety in AI systems but it still seems like there are too few and that they do not have the traction of other machine learning benchmarks. If we missed any AI safety-related benchmarks, please do add them to this spreadsheet.
Next steps
Now, what can we do to measure and facilitate progress on alignment and AI safety? This is an important question that we want to tackle.
Forecasting and keeping track of progress
Apart Research will focus on measuring and reporting the progress towards safe AGI. We are starting the YouTube series Safe AI Progress Report, we have developed the first version of a kanban for AI safety (which will be updated to reflect this agenda), and we plan to build a progress tracker with a weekly updated database and API as an aggregate measure of our progress towards safe AGI compared to AGI progress.
Lastly, please add your thoughts in this survey so we can get feedback on which metrics of AI safety progress you think are valuable.
Thank you for your attention and we hope to hear from you! You are welcome to email us or set up a meeting.
Thank you to Jamie Bernardi, Oliver Zhang, Michael Chen, and the Apart Discord for valuable comments and discussion.
Appendix
P(doom) data
P(doom) is an often used term for the probability that AGI will be an existential risk for humanity. Here is a short survey of experts’ opinions explicitly represented in public writing. 5 numbers originate from the X-risk estimates database and 8 from the reviewers of Carlsmith’s report. The rest are found from a variety of sources. Also see Rob’s related survey. Be aware that these are not all recent estimates (thank you to Julia Wise for pointing this out). All estimates are P(doom|AGI) in some form or another. See all P(doom) estimates with their associated year here.
- Joseph Carlsmith: 10%
- Rohin Shah: P(doom|AGI launched 2030) = 20%, P(doom|AGI by debate) = 10%
- Steven Byrnes: 90%
- AI Impacts survey: 10% (see report, see data)
- Leopold Aschenbrenner: 0.5% <2070
- Ben Garfinkel: 0.4% <2070
- Daniel Kokotajlo: 80%
- Neel Nanda: 9% <2070
- Nate Soares: 77% <2070
- Christian Tarsney: 3.5% <2070
- David Thorstad: 0.00002% <2070
- David Wallace: 2% <2070
- FeepingCreature: 85%
- Dagon: 80%
- Anonymous 1 (software engineer at AI research team): 2% <2070
- Anonymous 2 (academic computer scientist): 0.001% <2070
- JBlack: 90%
- Anders Sandberg, Nick Bostrom: 5% human extinction <2100
- Buck Shlegeris: 50%
- James Fodor: 0.05%
- Stuart Armstrong: 5-30%
- Jaan Tallinn: 33-50%
- Paul Christiano: P(doom from narrow misalignment | no AI safety) = 10%, P( doom from narrow misalignment | 20,000 in AI safety) = 5%
- Eliezer Yudkowsky: No numerical estimates but very high
- Vanessa Kosoy: 30% success
- ^
This Gaussian distribution is used for illustration purposes only.
- ^
Many AGI P(doom) estimates are already conditional on the fact that AI safety exists but this is most often not explicitly stated in casual writing.
- ^
There was a post concerned about the empiricism and estimates in AI safety from both a quantitative and emotional perspective in relation to broader EA but we were not able to find it.
In the "a case for hope" section, it looks like your example analysis assumes that the "AGI timeline" and "AI safety timeline" are independent random variables, since your equation describes sampling from them independently. Isn't that really unlikely to be true?
And just to dive into some of these dynamics:
Just off the top of my mind, I'd be curious to hear more.
Indeed, I think there are a lot of dynamics that might arise in the combination of these two timelines. This is also one of the reasons why it is used solely for illustrating the point that we might be able to calculate this if we can model these dynamics. We hope to use our reports as a way to dive deeper and deeper into the materia of how to properly analyze our progress. A next post will have more details in relation to this.
The compilation of p(doom) estimates is interesting, thanks for putting that together! I initially didn't realize that some of those are on the older side - several being from a couple of years ago, and the Sanders / Bostrom one being from 2008. I think it would be good to flag that these aren't all recent estimates.
Thank you for pointing it out! This is now mentioned before the list and maybe we'll add the years individually if we get the time.
Seems to me safety timeline estimation should be grounded by a cross-disciplinary, research timeline prior. Such a prior would be determined by identifying a class of research proposals similar to AI alignment in terms of how applied/conceptual/mathematical/funded/etc. they are and then collecting data on how long they took.
I'm not familiar with meta-science work, but this would probably involve doing something like finding an NSF (or DARPA) grant category where grants were made public historically and then tracking down what became of those lines of research. Grant-based timelines are likely more analogous to individual sub-questions of AI alignment than the field as a whole; e.g. the prospects for a DARPA project might be comparable to the prospects for working out the details of debate. Converting such data into a safety timelines prior would probably involve estimating how correlated progress is on grants within subfields.
Curating such data, and constructing such a prior would be useful both in terms of informing the above estimates, but also for identifying factors of variation which might be intervened on--e.g. how many research teams should be funded to work on the same project in theoretical areas? This timelines prior problem seems like a good fit for a prize, where entries would look like recent progress studies reports (c.f. here and here).
Very good suggestions. Funnily enough, our next report post will be very much along these lines (among other things). We're also looking at inception-to-solution time for mathematics problems and for correlates of progress in other fields, e.g. solar cell efficiency <> amount of papers in photovoltaics research.
We'd also love to curate this data as you mention and make sure that everyone has easy access to priors that can help in deciding AI safety questions about research agenda, grant applications, and career path trajectory.
You say your estimate for when alignment will be solved is from a "Gaussian distribution... used for illustration purposes only". How do you intend the graphs/numbers based on this estimate to be interpreted?
It is the naive estimate and we would need a broader range of others' estimates (e.g. on Metaculus) before we make concise predictions based on this. I also wouldn't expect it to follow a gaussian at the moment but some mixture distribution of several parameters.