'They could use this to potentially make more scientific and engineering breakthroughs in a few months as the rest of the world would make in decades, and use these breakthroughs to supercharge their economy. Or, if they wanted to, they could do as much bioweapons research in a few weeks as it would take millions of the world’s top bioscientists to do in decades. '
I think this is plausibly misleading though maybe not outright false. Certain kinds of research, for sure, involve only sitting around and thinking (for example, pure maths, but probably not only). Though in those areas you might be able to dramatically accelerate in speed, yes. But for a lot of research, actually doing experiments in the real physical world is probably necessary. For those sorts of research, just having AI will only speed up the bits that don't involve doing experiments, which is going to cap the speed up at whatever amount of time doing the experiments actually takes (i.e. for example, if they take up 20% of the time, you can at most go five times faster.)
Though in fairness, it only takes 1 important area where doing things in the real world is not a significant time bottleneck for something dramatic to happen.
Shorten the text and go even more easy on the language/complexity: I'm an outsider to the AI field and this was a great overview for me. But: I got up at at 3 am to watch Alpha Go beat Lee Sedol on livestream and I spent the last three months in full immersion mode, reading up on things every day. I'd say I'm an highly interested, somewhat knowledgable outsider. If your intended audience are people less driven to the topic, it might be worth to both shorten the text and spend more time at key points. Example: I'm not sure if all the players really need to be introduced here. At the same time, I'm under the impression people often don't really grasp what it means that neural nets are black boxes nobody understands. If you look at the discourse on reddit, even people highly interested in the topic often conceptualize neural nets as being programmed. I feel people are really struggling with the idea that engineers don't understand their product.
Strengthen the paragraph about what people can do. I would give it a shout-out int the introduction separate from section 7-9. Things I would add:
Use the tools available and use them all the time! If AI apocalypse happens, it won't help. But: That the job market will be highly impacted is almost a certainty, and familiarity with current tools just might help to stay relevant on the job market for longer. Practical experience will also help to appreciate the strengths and limitations of the current tools better.
Be in favor of AI alignment and act accordingly. Support research financially, bring up the topic in conversations and on political events (but don't inject it into partisan settings).
The AI guide I'm sending my grandparents — EA Forum
This is intended to be a comprehensive guide to getting up to speed in the AI landscape for somebody with little or no background. It walks through AI history, how it works, capabilities, potential impacts, and the general current landscape. I’ve been sending it to my friends and family, and I figured others might like to do the same.[1]
1 Intro
I think there’s a good chance that AI developments are the most important issue in the world right now, and have thought this for the past three years or so. With the success of ChatGPT and similar models, much of the discussions around AI that have been happening for the past decade or so have suddenly entered the mainstream, and the public is quickly starting to form their own opinions. This is a guide that I’m compiling for my friends and family to help you get up to speed on what’s going on in the AI landscape.
One of the major themes of this document is that nobody really knows what’s going to happen with this stuff, and that obviously includes me. It’s very possible that everything here is deeply misguided and wrong. However, I do believe that if this isn’t one of the main things you’re thinking about at the moment, you’re probably taking your eye off the ball. Also, I expect that these issues will continue to enter and play a larger role in American public discourse in the near future. It will likely eventually polarize along left/right lines, at which point the discourse around it will become much stupider and noisier. Therefore, I think it’s very much worth your time to familiarize yourself and form your own opinions right now so you can better think for yourself in the coming months/years.
This document is broken down into sections so that you can skip ahead easily. The most important sections are 7-9, so I would prioritize reading those over anything else here.
2 Summary
Current AI systems have been progressing at a rapid rate for the past few years, leading many to speculate that within the coming years or decades, we will develop an AI that is as or more intelligent as humans. If this happens, it could very well be the most significant event in the history of the world. Humans would no longer be the unchallenged smartest things on the planet, and it could potentially help usher in unprecedented advances in science. Nobody is sure what could happen after this, but it might have the potential to bring utopian abundance or be powerful enough to be incredibly dangerous. So, it seems worth it to spend some time right now thinking about how to prepare for these possible futures. Below, I outline the current state of the AI landscape and some reasons why many people are concerned that AI will be catastrophic.
3 History
Every history of AI is obligated to start with the 1956 Dartmouth Summer Workshop, where they set out to attempt to “make machines use language, form abstractions, and concepts, solve kinds of problems now reserved for humans, and improve themselves”. Needless to say, they didn’t solve all these problems that summer, but they did lay the groundwork for the field to begin. Since then, the field of AI has gone through a handful of “AI summers”, periods of optimism and excitement followed by periods of disappointment and dead ends. Significant progress was made, but mainly in areas such as chess where the environment could be straightforwardly mathematically modeled. The current AI era, dubbed the “Deep learning revolution”, began in the early 2010s. It was brought about by the realization that deep neural networks (neural networks with lots of internal layers) could do previously unsolved tasks and continue to get better as they were scaled up. In 2017, Google published a paper outlining the architecture of “transformers”, a design for neural networks that has since led to the rapid progress of large language models.
In 2015 OpenAI was founded with the goal of developing artificial general intelligence, and they released GPT1 in 2018, which wasn’t very impressive. GPT2 and GPT3 are released in 2019 and 2020 and are shocking to many experts because GPT3 functions fairly well and almost all of the increase in performance came from simply scaling up the size of the neural network, not any new technological breakthroughs. In 2022 they released ChatGPT, a better packaged, user-friendly version of GPT (running on a slightly improved model dubbed GPT3.5), which became the most successful product launch in history. And in March of 2023, they released GPT4, which is even more powerful and can take images as input.
During this time, concerns about the safety of powerful AI have grown as well. Eliezer Yudkowsky, considered the founder of the AI safety field, founded a research institute in 2000 to study potential problems from AI. In 2014, Nick Bostrom published Superintelligence, which was the seminal book in AI safety at the time and is what got many people into the field.
4 How this stuff works
(This is an intentional oversimplification in several areas)
I will focus on large language models (LLMs) like ChatGPT and GPT4 since they’re currently the most popular and exciting. However, deep neural nets have also recently been used with stunning success on things like image generation, music generation, image classification, and predicting protein folding.
Large Language Models
LLMs can be thought of as glorified autocompletes. They work by taking a phrase of text, calculating the most likely word to follow this text, adding that word to the original text, and then repeating the process with the new modified text. (It will also occasionally picks words that don’t have the highest likelihood to keep the text from sounding flat, which explains why they may not return identical answers for identical prompts.)
But how does it calculate the next word? A naïve approach would be to take the frequency of each word in English. Out of all ~40,000 English words, the word “the” is the most common. But this approach results in an absurd response where the LLM returns “the the the the the the the…” repeatedly. However, we can do better.
What if instead of considering isolated words, we consider the frequency of pairs of two words? This means we need a list of the frequency with which each of the 40,000x40,000 possible two-word pairs occurs in English. We can calculate this by counting how often these pairs occur in the corpus of all text ever published online. Then, if we are given the first word, we can look at the words that most frequently follow it. When adding a new word, we simply add the word that most frequently comes after the last word of the text. For example, if the word “be” is the word that most frequently follows the word “to”, then we would complete the sentence “I want to” as “I want to be”. This does better, and the sentences you generate sound sort of coherent. However, it is only looking one word back. So, the sentences will repeat themselves, ramble, and generally not say anything intelligent.
We can do better by increasing the number of words we consider in order to calculate the next one. Instead of considering the frequencies of two-word pairs, we can look at groups of three, ten, or however many words we want. Like before, we calculate these frequencies by counting up the times they occur in all the text ever published online. The more words we consider, the more coherent our sentences become.
However, there’s a problem: the number of groups of n words is 40,000^n, which increases exponentially. There are 1.6 billion possible two-word pairs, and the number of distinct sequences of 20 words is greater than the atoms in the universe. Therefore, we can’t just look through example text to calculate the frequencies of all 20-word sequences. Instead, we have to construct a mathematical model that lets us accurately approximate these probabilities.
Neural Nets
This is done through neural nets. Neural nets can be usefully thought of as black boxes since nobody actually knows what’s really going on inside them. In essence, they are a mathematical function with a ton of parameters. By tweaking the parameters correctly, you can get any output you desire from whatever input (they can approximate any function). Here, we give the sequence of text as input, and the output we want is a list of 40,000 probabilities of which every English word is likely to follow that sequence.
I’m not going to explain the details of neural nets, but here is a wonderful video that will explain them much better than I could. The architecture of neural nets is actually quite simple, and most of the improvements we’ve seen over the past few years have come from making these neural nets bigger and bigger (GPT3 had over 175 billion parameters).
To train a neural net, we feed it the corpus of the entire written English language, and have it attempt to create an internal model of which words are likely to follow previous blocks of text. For text one or two words long, this would give roughly the same results as our first attempt of just counting word frequencies. However, we can also now feed it in text that it’s never seen before, and it will predict the next word based on the patterns it has deduced from studying all the text it’s seen. While we can see every parameter in this neural net and know every calculation that happens, once the models get large enough, we can’t make sense of what functions the model is replicating or why the parameters are what they are.
Again, neural nets can and are also used for lots of useful applications besides LLMs, but the basic paradigm is the same: create a large neural net, give it lots of training data, and end up with a black box model that somehow does the task surprisingly well.
GPT
When GPT1 came out in 2018, it wasn't very impressive. It functioned much more like autocomplete than anything resembling a human brain. When GPT2 came out in 2019, it still wasn’t great, but it was vastly better. This was shocking to lots of people because it was essentially the same model, just bigger. GPT3 came out in 2020 and was again much better, with again most of the improvements just coming from size.
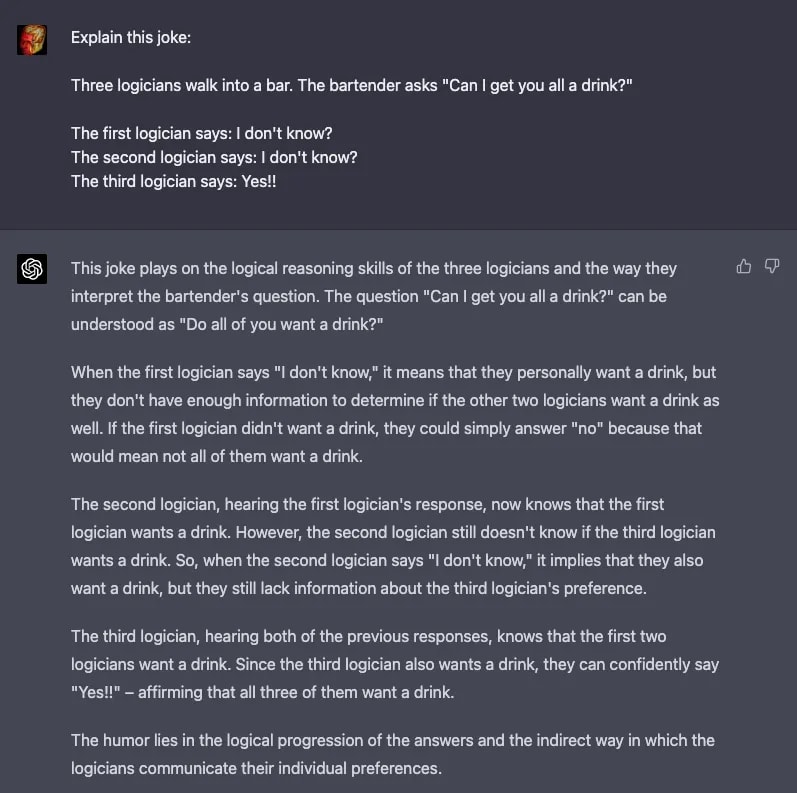
Many people are quick to dismiss ChatGPT since it is essentially a glorified autocomplete. However, to autocomplete sentences coherently is not necessarily a trivial matter. For the machine to be able to finish a sentence coherently, it needs to have some internal model of coherence. Currently, GPT4 still functions a lot like an autocomplete and not yet like a brain. It is not an artificial general intelligence (AGI), an intelligence that could reason as well as a human over all domains humans care about. And it is unclear if the paradigm of “have some neural nets try to complete sentences” could ever create an AGI.
However, it is able to imitate the functions of the brain surprisingly well. It has shown the ability to write compelling essays, reason logically, reason about the internal states of people’s minds, and write high-level software (examples in section 5). It is clearly picking up on some important underlying patterns in the structure of language, which seems to suggest it might be picking up important patterns in thought itself. Nobody knows how good GPT5 or GPT6 will be, but the pace of improvements suggests that it will continue to keep getting better and better at imitating human thought.
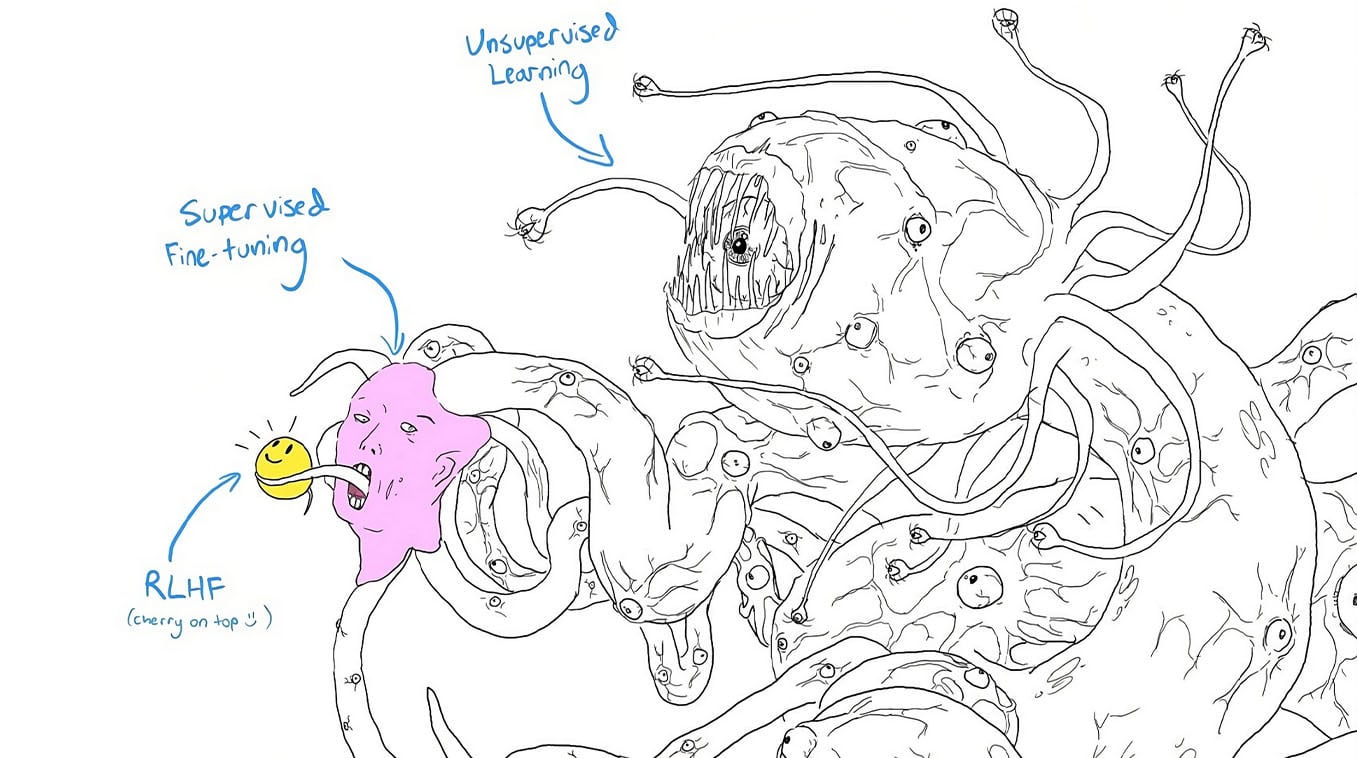
If you’ve been online recently, you might have seen a variant on the image below, which is actually a fairly helpful way to understand more of what GPT is doing.
The essence of GPT is training on the corpus of English text online to learn which words tend to follow each other. This part gets better and smarter when it is trained on more text, and when it is trained on better text (training it on books gives better results than on Twitter feeds). In the picture, this is represented by the white monster.
This part is a complex mathematical representation of the patterns in language, which, by itself, isn’t terribly useful for answering prompts, since it’s just trying to complete the text. For example, this is an early model completing a prompt:
This isn’t super useful, because although this completion follows the patterns in language that GPT found, we don’t want it to just add words that would likely follow after our prompt. We want it to give a meaningful response to it. So the next level of training gave it lots of tailored examples of prompts and helpful completions. This made GPT’s responses start resembling how a human would actually respond to the prompt. (This is represented by the pink human face attached to the monster).
Finally, they fine-tuned the model with Reinforcement Learning with Human Feedback (RLHF), where they would have humans rate specific outputs from the model for how good they were, then feed these responses back into the model. They punished the model if it would say things that were offensive or violent, and rewarded it when it gave answers described as “helpful, harmless, and honest”.
This picture is helpful because it reminds you that ChatGPT isn’t the helpful personality you interact with. It’s not an actual personality (presumably), but also, the original model isn’t exclusively any single personality. It is a giant, unintelligible model of patterns in language. We call on this unintelligible model to simulate how a person that was helpful, harmless, and honest would complete that prompt, but that person isn’t the model.
5 Some examples of what the current models can do[2]
GPT4 is a large language model that is trained to predict the next word in a sequence. Despite this, and despite not being a general intelligence, it is able to complete some impressive and surprising tasks, such as those listed below.
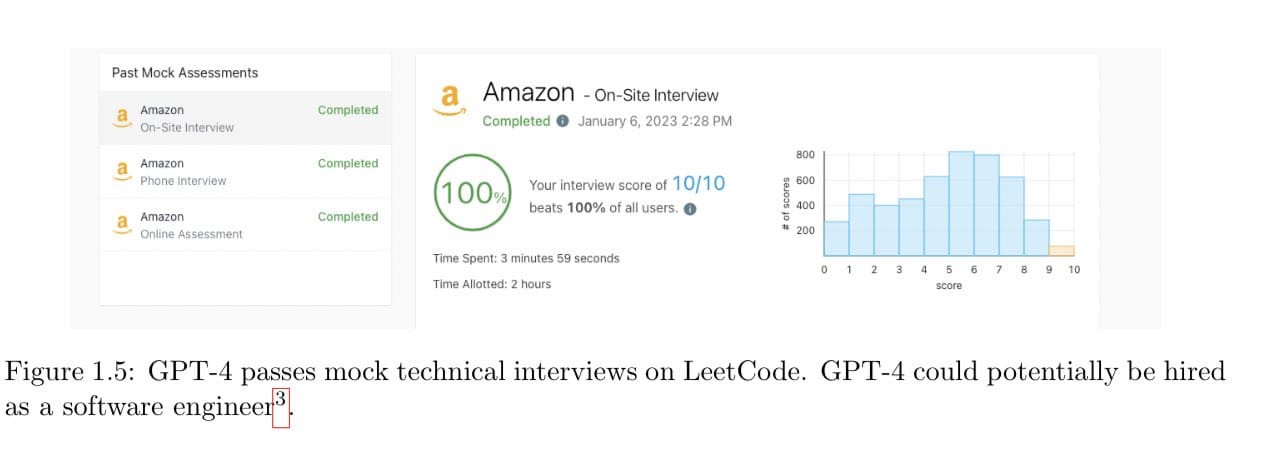
Code well enough to get hired as a software engineer:
Generate a correct internal map of its environment:
Generate images of things despite not being trained on images:
Solve math problems:
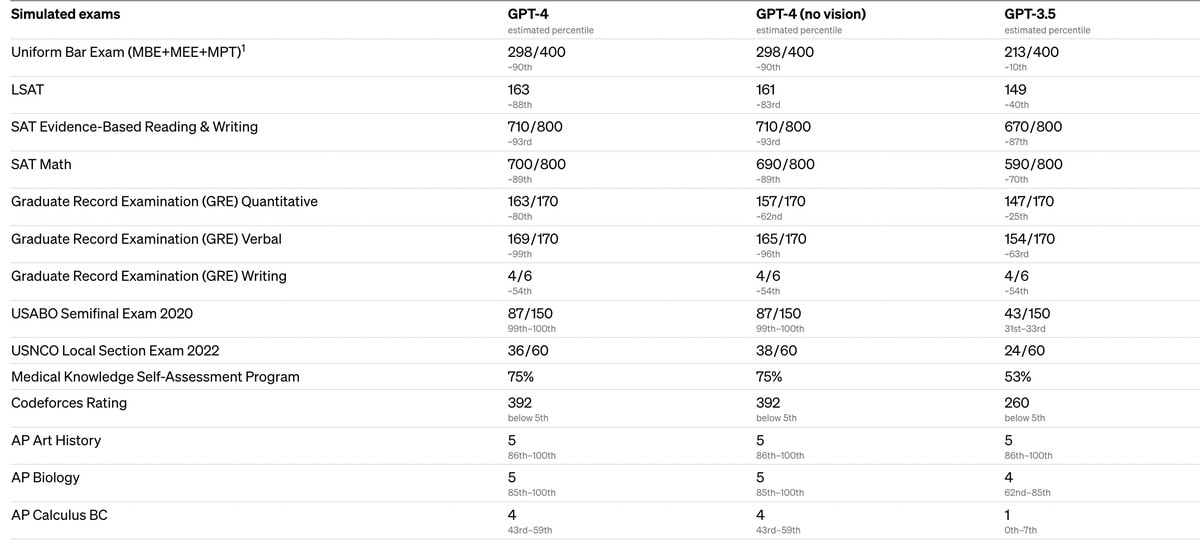
Score well on hard tests
(Source). Note that it is in the 88th percentile for the LSAT, which requires lots of logical reasoning.
6 Near-term impacts
These models are now powerful enough to have large societal consequences, even if no new models were released. I have no idea what’s going to happen, but here are some plausible things we might run into in the coming years.
I don’t know if AI is going to take your job, but I am fairly confident that in any white-collar job, your daily tasks will likely be significantly transformed. AI can code better than many software engineers, draft full legal documents, and do most of the bureaucratic work of white-collar professions. AI will likely take most of the grunt work of writing out long code or long legal documents, and humans will shift to spending their time coming up with the original ideas, running the AIs, and supervising them. Whether this will take your job or make you a much more productive worker will likely depend on how good you are at adapting to using this technology to make you a better worker (and how much your job is protected by bureaucracy and regulation).
Also, these models can convincingly imitate a person on the internet. This greatly increases the chance that anybody on the internet is actually a bot trying to manipulate you. Without strong countermeasures, this will likely result in the internet being flooded with more misinformation and scammers trying to take your money. I advise responding by: being much more skeptical that any given person on the internet is real, being much more skeptical that any claim online is true, being much more skeptical that any picture you see is real, and strengthening relationships with people you know in person. It also wouldn’t hurt to develop a code phrase to share with your trusted friends that you could use to prove to them over the internet that you’re you. (For example, if there’s a recording of you on the internet, it’s fairly straightforward for somebody to train an AI to imitate your voice, call your parents, and have the AI have a long conversation where it convinces them that you’re in trouble and need them to wire you money.)
These models will also have large benefits, as they give us more power to do things we want. If you don’t code, it is now easy to have this software write fully functioning programs for you (one of my professors has already used this to automate logistical bureaucratic work that used to take several hours a week). Since these models aren’t 100% reliable, I have found they are quite useful for generating lots of ideas when it is easy to check the ideas but hard to generate them (eg “Give me a list of singers whose name starts with the letter "A" helpful for understanding the Russian Revolution”). As these models become more reliable, they might be able to act as individualized tutors.
These are all likely impacts from just currently existing models. However, progress does not seem to be slowing down, and these systems will keep improving within the next few years.
A fundamental problem is that these models will become economically useful before they become fully reliable since we don’t yet know how to make this technology do exactly what we want it to do. A current example is that OpenAI has tried incredibly hard to keep GPT from saying bad words or giving offensive results, but the models still occasionally do this. In the short term, the biases within the models will lead to occasional socially undesirable results when deployed (eg predictive policing/parole algorithms). However, this will become much more of a problem if these models continue to get much better and are used for more important tasks, which is the focus of the next section.
7 Artificial General Intelligence
While our current AI systems are not as smart or as general-purpose as humans, many people believe that it is possible to build artificial intelligence powerful enough to do most useful things that humans do, and humans will likely do this at some point. By “intelligence”, I mean the ability to achieve goals in a range of environments. An analog thermostat can be thought of as weakly intelligent since it adjusts the heat to keep the room at the goal temperature. However, it’s not that smart and is only specified for one job.
There is a spectrum of how powerful an AI is, depending on how good it is at achieving its goal. There is also a spectrum of how “general” it is, and how well it can do jobs it wasn’t specifically trained for. For example, Google’s AlphaGo was designed to play Go, but its algorithms were generalizable enough that it was able to also play chess at a superhuman level after training for less than a day. Even more general are humans, who are able to do countless different tasks that we weren’t evolutionarily programmed to do.
So far, we’ve mainly built narrow task-based AIs (like AIs that can play chess or predict how a protein will fold), and many of these have greatly surpassed human performance in their narrow domain. However, many companies have the explicit goal to build artificial general intelligence (AGI), which would be able to reason as well as a human across all domains that humans do.
This task doesn’t seem like it should be impossible: our best neuroscience suggests that the brain is simply a large connection of physical neurons firing, and general intelligence somehow results from this. So, in theory, it seems possible to replicate the mechanics of general intelligence on silicon.
There’s a strong economic incentive for a company to build an AGI since it could do all the work normally done by a human. Furthermore, it could be run 24/7, perform tasks much faster, and be replicated countless times. However, it could also contribute to AI research. With the help of seemingly limitless brain power brought by the first AGIs, we could build an even better AGI that didn’t just match human reasoning performance but exceeded it. This cycle could theoretically be repeated to make smarter and smarter AGIs. While humans have already reached peak performance in some domains (like tic tac toe), there are still many domains in which computers could clearly become vastly smarter than us (in chess this has already happened). There seems no reason why a human brain is the smartest physical thing possible, so it’s possible that a recursively self-improving AGI could blow past human-level reasoning and become much smarter than us in every domain we care about.
From Superintelligence, 2014
However, we don’t need to build a fully general AI for weird things to start happening. If we just built one that could automate the process of technological and scientific advancements, we could get this sort of recursive self-improvement within science. This could, in theory, be done by a narrow task-based AI that couldn’t reason as broadly as humans but could reason well enough to work on scientific breakthroughs. (I think you get the same results I describe below with this narrower AI, so going forward I will just be referring to AGI).
8 Large safety concerns
Many people are seriously concerned that the continued advancement of AI is the most dangerous threat we’ve ever faced as a species, and it poses a direct existential threat. Their predictions of how bad it will be vary wildly, from “ kills literally everyone” to “causes some major havoc but we muddle through”, and their probabilities of this happening routinely range anywhere between 99% and 1%. These may sound crazy when heard for the first time, so I hope to spell out below some of the arguments they make.
Reasons for concern
The clearest reason for concern over the development of AGI is that AGI would likely bring unprecedented amounts of power to whoever has it. If a country had AGI, they could effectively “outthink” the rest of the world by running countless instantiations of it in parallel. They could use this to potentially make novel scientific breakthroughs and use these to supercharge their economy. Or, if they wanted to, they could direct this towards weapons development. For example, they could have the equivalent of millions of the world’s top bioscientists thinking about bio weapon development, though progress might still be bottlenecked by the need to perform physical experiments. This could drastically shift the international balance of power! If a country got an AGI truly smarter than all humans, this would possibly represent a gain in sheer economic, political, and military power orders of magnitude greater than the development of the first atomic bomb. If a dictator or oppressive regime developed AGI, they could use it to cause devastating amounts of harm.
Another reason for concern is that while these systems will likely be incredibly intelligent and useful, their inner workings remain black boxes to the engineers creating them, which leads to the possibility that they could have catastrophic errors if given the opportunity. Giving an AGI control over a system (eg, scheduling meetings, managing operations at a power plant, or as an autonomous drone used in warfare) is like entrusting it to aliens who we trust because they have a good track record of running things so far, though we can’t directly communicate with them or verify their goals. We currently have no idea why these black box neural network models give the outputs they do, and so we can’t rule out any output they would give our actions they’d take.
Furthermore, as outlined below, there’s reason to believe that the dispositions or goals that a black box develops will not be the ones we intend for it to develop. Many believe that this failure mode (we give an AGI with unclear and likely unintended goals an unsafe amount of power) has a good chance of causing unparalleled amounts of destruction or even literally killing everyone on Earth. I’ll be walking through the details of their argument below.
Systems with aims
The argument first assumes that we will develop AGI, and also that we will develop AGI that acts as if it is “goal-directed”. Specifically, I use “goal-directed” to mean that it scores highly on the following: acts to bring about some state of the world, understands that its behavior impacts the real world, considers different plans, decides which plan would best satisfy its goal, is coherent in pursuing this goal, and flexible in executing it. I am goal-directed when making dinner: my goal is to make something tasty and healthy, and I think through different options of what I could make, decide on what I think would be best, get the groceries from the store, and make the dish. Being goal-directed isn’t binary, each one of these components is a dimension an AI could vary upon. Since we are only concerned with systems acting as if they have goals, AGIs don’t need to have inner desires, understandings of our goals, or any of the things we usually associate with human goal-directedness. All they would need are strong tendencies/dispositions to intelligently do things that will bring about some state of the world.
Current AIs (as of early April 2023) aren’t very goal-directed. As discussed above, when GPT4 answers a question, it is not reasoning over states of the world and trying to achieve its desired world state. It is simply trying to predict the next word. So, current AIs are more tools used by agents (like people) rather than agents themselves. However, there are strong incentives to develop goal-directed AIs. For example, it would be very handy if I could tell an AI “Get me ingredients to make a nice dinner tonight”, and it thought about my favorite dishes, considered what I’d eaten recently, compared prices of current ingredients, and hired Instacart to go pick them up. There are even stronger economic incentives to develop an AI I could tell to “make me money in the stock market” or “design and produce a new cancer medicine”. Furthermore, it is possible to generate goal-directed AI even when we’re not trying to. We have no idea what’s going on inside the neural nets, so even if we’re training an AI to just function as a tool and not an agent, the internal algorithm that the neural net creates once trained may act in a goal-directed way since this was found to be the most effective way to perform the tool-like task.
However, although cutting-edge AI models (like GPT4) are not goal-directed, they have already been modified by third-party software to act as goal-directed agents. For example, “Auto-GPT” is a program that is given a goal in natural language, and then calls GPT to generate ideas on how to achieve the goal. GPT is then repeatedly called to further break down the tasks or tackle a sub-task, such as by writing any necessary code. The technology is new and imperfect, but it’s already able to autonomously complete simple tasks, and will undoubtedly continue to improve.
The main question now is whether agentic AI models will stay confined to scrappy third party software built on top of LLMs by a few independent programmers, or if the major AI labs will try to create a cutting-edge agentic model themselves. The economic incentives to create goal-directed AIs are strong, and people really want to have an AI to which they can delegate entire tasks.
Also, note that I have nowhere mentioned anything about consciousness. Consciousness is not necessary to be goal-directed, recursively self-improve, or pose dangers. Google Maps is not conscious, but it can still reason about the world and do useful things. While consciousness is interesting for conversations about how we should treat AIs, it is almost entirely irrelevant to questions about their safety and risks.
Misalignment
So if we assume that we will have goal-directed AGI, how do we make sure that it pursues the goal we want it to? This turns out to be an incredibly difficult question and is dubbed the Alignment Problem.
The first part of the problem is how to give a goal to an AI. This is called “inner alignment”. With the machine learning paradigm, current AIs are trained by showing examples of desired performance and rewarding/punishing it for good/bad performance. For example, if I want to train an AI to differentiate pictures of cats and dogs, I just show it a bunch of labeled examples of cats and dogs, and let it learn how to spot the differences. Since we are not giving it an explicit goal (like a utility function to maximize) and instead trusting it to infer it from trial and error, there’s a possibility that the goal it learns isn’t exactly the goal we had in mind.
Since they are not rewarded for actually achieving some goal, but rather just by getting some other human or algorithm to press the button to reward them, they are incentivized to find clever or deceptive ways to trick/force the evaluator into rewarding them or finding some loophole in their evaluation method they can exploit. One example is when a claw machine was trained by human feedback to pick up a ball. However, the policy the AI instead learned was to position the claw between the ball and the camera, making it look like it was picking up the ball, and earning positive feedback from the human. Another example is with LLMs. When evaluating LLM responses to a question as true or false, the human evaluators will sometimes be mistaken (rewarding answers that are actually false, and pushing answers that are actually true). Thus, the goal that the feedback is telling the machine is not “say true things” but rather “lie to the human when they are mistaken”.
Furthermore, almost all goals implicitly reward undesirable behaviors. A machine will learn that it is much more likely to achieve its goal if it isn’t turned off while completing the task, doesn’t have its internal objective changed, acquires more knowledge of the situation, or acquires more power over its environment. Thus, we will be implicitly training them to become power hungry, prevent themselves from getting turned off or having their goal changed, and try to become all-knowing (these are certainly not behaviors we want in powerful AI!) Therefore, AIs will likely by default have goals unaligned with the goals we wish to give them unless we figure out some new technology to give them the explicit goals we want (solve the inner alignment problem).
Unfortunately, there’s currently no way for us to look inside the algorithm to verify that the goal they’re acting upon is a goal we would want. While we can see every line of their code, the way that the algorithm actually makes decisions is by multiplying large matrices of billions of weights together, which we can inspect yet not understand. We have no way of interpreting what these parameters are doing or why.
The current approach that we have to solving this problem is to have humans evaluate the outputs of models, and punish the model if they do unintended things. However, this is not foolproof, since it's not possible to test a model so many times that you are certain what its goal is. Yet, it faces another issue in that it relies on the human evaluators being much smarter than the model they’re evaluating. If an AI model becomes more intelligent than us, we will not be able to reliably judge whether their output is desirable, since the output may be beyond our comprehension. Thus, the current alignment approach could break down right at the moment when the systems become dangerously powerful.
If we can solve the inner alignment problem, we’re now faced with the task of how to specify the goal we want to give it. This is referred to as “outer alignment”. Put simply, fully optimizing any arbitrary goal could lead to a pretty terrible world. For example, if you tell a superintelligent AI to keep the room at 72 degrees, it might conclude that it is more likely to keep the A/C running if it doesn’t have to worry about blackouts and thereby take over the entire power grid to prevent this. If we instead try to formulate our goal in terms of broad topics like “obedience” or “helpfulness”, we should expect the AI to do things that score well on whatever metric we use to measure these concepts but aren’t quite what we want (see Goodhart’s Law). Finally, for any goal, we would always be incentivizing it to prevent us from ever turning it off or changing its goal (by force if necessary), since this would reduce the chance it accomplishes its original goal.
I find it can also be helpful to think of a third layer of alignment, which I call “societal alignment”. This is the attempt to align the goals of whoever is running the AI with the broader goals of humanity. However, this is an alignment problem that has been with humanity for thousands of years and is not unique to AI.
Likely Outcomes
So now we’re assuming that we have an AI smarter than us that is trying to achieve some goal about the state of the world, and its goal is not the goal we want it to have. How bad would this be? It’s unclear, but it seems possible that it could be quite bad.
A general intuition pump for the arrival of AGI, to think of it as sort of analogous to a second species. Humans have been the most intelligent animals on the planet for thousands of years, and we pretty much do whatever we want with the planet without thinking about other animals. While tigers may be stronger than us, their survival is now completely dependent on our current societal whims, and they are not able to exert any control at all over what eventually happens to them. If human or superhuman-level AGI was developed, we would no longer be the smartest creatures on the planet, which might result in us no longer being the most powerful group.
As outlined above, there are several reasons that we should expect by default a superintelligent AI to seek to acquire lots of power, acquire as much knowledge as possible, prevent itself from being turned off or having its goal changed, and seek to bring about some state of the world that isn’t what we originally intended it to. Any goal that the AI wants to achieve could be better achieved if it controlled the world. (This is true for any goal humans pursue, but we usually don’t consider this avenue because it’s not feasible for us.) Humans also pose a risk of interfering with the AI's goals, so the AI could have a higher chance of achieving its goals if humans weren’t around. Thus, if AI development continues along its current course, there is a significant likelihood that we would be creating an agent vastly smarter than us that has at least a small wish to control the world.
How strong this wish would be is unclear, and it could be outweighed by other goals it has. Also, I think that the assumptions we’ve made along the way have a few weaknesses. However, this possibility seems plausible enough and bad enough that it’s worth spending serious time and resources trying to avoid it.
Would a superintelligent AI actually be able to seriously harm us if it wanted to? This is again unclear, but it seems likely. Cutting-edge AIs (like Microsoft/OpenAIs Bing) are often connected to the internet, and if this AI was, it could duplicate itself, spread around the world, and hack into numerous things. A key problem would be expanding power from the digital to the physical world, but if it were able to achieve this (by tricking somebody or hacking into the required websites), then it could bootstrap its way to real-world physical power.
Consider what it would be like if all of humanity was trapped inside the internet of some alien species, but this species was much stupider than us, and their thought process was a million times slower. Furthermore, humanity has some desire to influence the aliens' physical world somehow, despite their wishes. Would we be able to do so? However confident you are that we would be able to so seems about as worried as you should be about AI that wanted to harm us.
However, the extent that AGI is dangerous depends on the extent to which it is misaligned and the amount of intelligence/power it has. Without some large technological breakthroughs in alignment, it seems inevitable that goal-directed AIs would be misaligned. However, it is still unclear whether they would be misaligned enough and superintelligent enough that they would take over the world. This could be because their goals are still close enough to ours, or because being vastly smarter than humans doesn’t necessarily cash out in the ability to be more powerful than humans.
How scary all this also depends largely on how quickly superintelligent AI comes. If there is a long time between when AI starts becoming usefully powerful and when it is radically superintelligent (think 10 years), then we will have more time to adapt, prepare, and use the AI systems to help us try to align the more advanced AIs. However, if the recursive self-improvement is much faster (think months or weeks), then responding well would be much harder.
Stewart Russel has a famous thought experiment, where he imagined we got an email from aliens saying that they were coming to Earth in 2050, and not including any more details. Nobody would know what they would do or what would happen when they arrived, but there would be a clear consensus that it would certainly be a big deal, and worth spending lots of time and money right now trying to prepare to make their arrival go well. This is roughly analogous to the situation we are in today: the median AI expert predicts that AGI will arrive by 2059, and the arrival of machines that can outthink us seems roughly as foreign and weird as the arrival of aliens.
My Personal Takes
I’ve been noncommittal for quite a while, so it’s time for me to lay some of my cards on the table. I am radically uncertain about all the arguments above, and can’t say anything definitively. However, I think that the development of AGI is likely enough, will happen soon enough, and would be world-alteringly powerful enough that it is well worth devoting a substantial fraction of our resources to keep things from going terribly poorly. It seems likely to me that there will probably be a technological event in my lifetime that displaces humanity from our perch as the most intelligent species on Earth, and brings whoever controls the technology unfathomable power. I have no real idea what would happen once this occurs, but this event would definitely be a huge deal, and things certainly wouldn’t be guaranteed to go well.
In the explicit reasoning chain I’ve outlined, I find all four components (we get AI, it’s goal-directed, it’s misaligned, and could seriously hurt us) to individually each be more plausible than not. I, therefore, think there’s a decent chance we will get all four components, though I’m not sure if I think the combination of all four components is the most likely outcome. Furthermore, even if all four components do occur, I don’t know if AI would be superintelligent enough, goal-directed enough, misaligned enough, or able to harm us enough to cause any extinction-level events. Finally, I’m decently hopeful that we realize the dangers we are facing, and take serious actions to respond by for example investing a ton in alignment or banning the development of dangerous AIs.
While I am incredibly uncertain, my best guesses would be:
We get superintelligent AI within my lifetime: 75%
We get superintelligent AI within my lifetime and it’s literally the worst thing to ever happen to humanity (eg extinction): 5%
That being said, I view these probabilities as endogenous: I think that a lot of our hope for having things go well is if we place wise restrictions on AI because people freak out about things going terribly!
9 Our world today
Several strategic considerations are driving current AGI development. First off, there’s a huge economic incentive for companies to develop it: this could potentially be the biggest technology since fire, and they’re all eager to cash in. Second, there’s a strong desire to develop it first, since lots of people would prefer that they themselves control it (because they’d presumably be safe and smart with it) instead of somebody else (because they’d presumably be stupid or use it for bad things). The people building this AI often don’t specify who the bad parties are they’re trying to be, but when pressed on it, their answer is usually some combination of “Facebook and/or the Chinese Communist Party”. Many Westerners believe that if the CCP got this technology first they’d do bad things with it, so they think it’s important that the US wins the AI race. Facebook AI has historically dismissed AI safety concerns, leading to concern that they would accidentally deploy a system that was unsafe.
However, the race dynamic created is terrible for the prospects of making the technology safe, since it significantly reduces the time we have to work out the technical and social problems we need to solve to make it safe. Also, companies have an economic incentive to deploy AI that they know isn’t fully safe, since the safety threshold it has to pass to make it worth it for the firm is much lower than the threshold needed to make it worth it for the world. For example, imagine a button that, when pressed, would give you $100 billion with a 99% probability, and destroy the world with a 1% probability. It would be very tempting for an individual CEO or government to press the button, even if, from the standpoint of everyone else, it’s a terrible decision.
Recently, there was a letter that sought to stall the development of AI by calling for a 6-month pause on training runs. Reaction to this letter roughly divided into the camps: this is a good idea because it slows AI; this is a bad idea because it hurts the lead that the top companies have, and this would tighten the competition (increasing the race dynamic) or give a worse actor an edge; this is bad because it distracts from more important issues around AI that we face right now; or this is bad because of some other strategic concern (like calling wolf slightly too early).
One of the biggest questions is how soon AGI will come. When the field of AI safety was first developing, the mindset was that AGI would probably come within a century, so it would be good to start thinking about it now. Two decades ago, deep neural nets were just one of many different popular AI paradigms, none of which worked particularly well. In the past decade, though, they have made unprecedented progress on many open problems largely just by adding more layers. This surprised many and led people to expect AGI sooner than they previously thought. Similarly, the recent development of LLMs has shocked experts with how much they’re now able to do. When these LLMs were first getting started, they were largely seen as a useful tool for processing language, but almost nothing like a potential general intelligence in themselves. However, LLMs have been able to reason logically much better than expected, generalize significantly outside their training domain, and excel at a host of specific unexpected tasks. While few people think that sufficiently good next-word prediction would be enough to get a machine all the way to AGI, many people now think this paradigm might get us much of the way there. Yet, how far the next word prediction LLM paradigm will take us is still an open question. Though many people expected progress to stall already, it's possible that this paradigm simply can’t create machines much smarter than the current models. However, even if AIs don’t become superintelligent, human-level AIs could be dangerous by themselves largely because there could be millions of them.
The largest concern by many people in AI safety is not that these LLMs will become generally intelligent. Rather it’s that they’ll become good enough that they create enough hype and investment around AI that some other paradigm will be developed which is sufficient to reach AGI.
In addition to the field of “AI safety”, there is also the field of “AI ethics”, which is characterized by concern over the problems that AI is creating today, such as the proliferation of misinformation, the generation of harmful content, and the treatment of low wage content moderators. These two fields share most of the same goals: ensure that AI only does what we want, ensure it doesn’t have biases, and slow the progress of AI. However, these two fields instead mostly dislike each other and can’t get along, largely because of vibes, distrust, and personal problems. After the letter requesting a 6-month pause was released, it was roundly criticized by leading AI ethicists because it might distract from the real issues we actually face today and generate undue hype around AI.
Finally, I think it’s worth emphasizing that none of the arguments I’ve outlined rely on AI “waking up” or “becoming conscious”, and I think consciousness is irrelevant to pretty much everything I’ve talked about. Heat-seeking missiles certainly aren’t conscious, but they’re still intelligent and powerful enough to cause a lot of damage.
10 AI Safety Landscape
Given the potential enormity of the task at hand, what are people doing about it? The short answers are “not enough” and “nothing that seems certain to actually solve the problem”. The current best plan is pretty close to “do some basic safety stuff now, and hope that we can ask the moderately smart AIs to solve the alignment problem for the super smart AIs”. However, many people believe that this problem is solvable, and if we had enough time to solve it we could. At the moment, though, this is a general overview of the field.
Technical Work
Reinforcement learning with human feedback and similar things: This is pretty much the current leading plan, and what all the major labs are doing. It relies on having a human give a machine feedback on whether its output is good or bad. However, this isn’t enough to ensure inner alignment, and will likely not work at all once the machines get smart enough that their output is too complex for humans to evaluate. There are several proposals of how to get around this, but most of them boil down to “get moderately smart AIs to do a lot of the work for us”.
Interpretability work: This is the attempt to study deep neural nets to interpret what the different parts in it are doing, which would let us figure out the AI’s “thought process”. This is important because neural nets are essentially a black box to us at the moment. If this succeeded, we would be able to know an AI’s inner goals, and thus not deploy ones that are unsafe. However, progress here is incredibly slow, an incredible amount of work would need to be done before it was remotely useful, and even if this was fully solved, that wouldn’t solve all problems of alignment.
Other Research: There are several labs that are trying to solve alignment by coming up with a new AI paradigm from scratch that doesn’t face these problems, or by discovering new important theorems around things like decision theory. Some of these are seen as mildly promising, while many are seen as Hail Marys.
Non Technical Work
Work outside the technical field of aligning AI focuses on the project of creating political and economic conditions that don’t lead to dangerous AI. One major approach attempts to slow down AI development and create barriers to deploying unsafe AI by calling for bans/delays on research or implementing higher safety standards. However, not everyone agrees that slowing AI progress is the safest route (because a less safe actor would get it first, then). Other goals here are to ensure that the supply chain for developing the necessary AI hardware goes entirely through U.S. allies so the U.S. could in theory cut off bad actors who were trying to develop AI (though this is also controversial). People are also trying to foster cooperation between relevant actors that might be tempted to engage in an AI race, but this is hard. A clearly good thing for governments to do, though, would be to invest much more in technical AI safety research.
An ideal goal of non-technical work would be to get together all the actors from around the world capable of making AI developments, give them lots of money, lots of security, and 100 years to develop provably safe and beneficial AI. Then, find some way to stop everyone else in the world from working on AI during this time. However, this seems incredibly difficult to do.
11 Key terms and players
OpenAI- Lab founded in 2015 with the explicit goal of developing AGI. They’ve made most of the impressive breakthroughs recently, including ChatGPT, GPT4, and Dalle2. It was originally founded as a nonprofit with the goal of making AI development go safely and smoothly. However, they have since changed their charter and now operate mostly as a for-profit company. Many people believe that they effectively started an AI arms race and significantly shortened timelines to AGI.
Sam Altman- CEO of OpenAI, and former president of YCombinator (the gold standard of startup funding and incubation). He is very familiar with all the arguments around AI safety, and has expressed deep concerns about AI safety, but seems to also think that OpenAI will be fine.
Eliezer Yudkowsky- Regarded as the pioneer in AI safety, he started talking about how it was a huge deal about two decades ago and has inspired much of the current thought today. He is insanely pessimistic about the future and seems to believe it's almost certain that AI will kill literally everyone. This leads him to believe that drastic action is needed to stop AI.
MIRI (Machine Intelligence Research Institute)- Research group started by Eliezer to make AI safer. They are also pretty confident we’re all going to die and largely do blue-sky-type safety research.
Paul Christiano- Widely regarded as the current leading technical expert in AI alignment. He is very worried about AI, but less so than Eliezer, and often acts as his foil.
AI Alignment- The attempt to make AI do what we want it to do. This was originally used mainly to refer to making sure AI doesn’t kill everybody, but has since been appropriated and largely watered down to refer to making AI more powerful or less biased.
AI Notkilleveryone-ism- A new phrase in response to the watering down of “AI Alignment” used by those trying to do large-scale safety work to keep AI from killing everyone.
AI ethics people- People largely concerned with the problems we face with AI right now, such as misinformation, abuse, and labor practices.
Timnit Gebru- Used to lead Google’s ethics of AI team, but was fired because of a paper she wanted to publish on the dangers of LLMs. Now is a leading AI ethics voice.
Yann LeCun- Head of Facebook AI, and considered one of the “Godfathers of Deep Learning”. He does not believe AI safety is an actual problem.
Elon Musk- Helped found OpenAI in 2015, but is no longer associated with it. He seems to take AI safety seriously and has recently expressed regret for helping found OpenAI. However, it’s unclear what he’s actually thinking, and he’s now planning on starting a new rival to OpenAI with less politically correct restrictions on its output.
DeepMind- Google’s AI lab. Has made some large breakthroughs, and was generally regarded as the top AI lab before OpenAI’s recent progress.
Anthropic- A new AI lab founded largely by people that left OpenAI. They promise to be doing this to make AI go well and safely.
12 What you can/should be doing at the moment
Read more about this stuff! If this guide has convinced you that this is an important issue to pay attention to, then study up!
If you are working in politics, I would highly recommend learning as much as you can about this issue. You should try to learn enough about it so that you can develop your own informed opinions about what the best course of action for regulation and government involvement would be.
If you are working in tech or have a strong STEM background, I would suggest studying the technical side of AI alignment, and seeing if you think you might be able to make progress on some of the open problems. There is a huge need for smart researchers in alignment, and you should seriously consider shifting your career to work on it full-time if you think you’d be a good fit.
Everyone else should talk to their friends about these issues, and continue to learn as much about them as they can. I’m not sure if this will become the most important issue we face, or if progress will stall and most people forget about AI. However, I’m incredibly confident that it’s at least worth your time to do your research now so that you have informed opinions in the event that AI is a big deal.
As a summary document, I make no claims to originality in anything here and have borrowed especially heavily from the ideas here. Any mistakes are mine, and I would appreciate any helpful feedback.
This post presents the executive summary from Giving What We Can’s impact evaluation for 2025. At the end of this post we share links to more information, including the full report and...
I used AI to fix transcription errors, rerrarange the ideas, and suggest tweaks to the title and some sentences.
Three of the most exciting projects to come out of EA in recent years are, in a vague sense, CEA spinouts:
* Kairos is directly a spinout of CEA and now handles most support for university AI safety groups. Basically everyone I've found who knows them is really excited about what they do
* NEST is an opinionated ideas-fi...











'They could use this to potentially make more scientific and engineering breakthroughs in a few months as the rest of the world would make in decades, and use these breakthroughs to supercharge their economy. Or, if they wanted to, they could do as much bioweapons research in a few weeks as it would take millions of the world’s top bioscientists to do in decades. '
I think this is plausibly misleading though maybe not outright false. Certain kinds of research, for sure, involve only sitting around and thinking (for example, pure maths, but probably not only). Though in those areas you might be able to dramatically accelerate in speed, yes. But for a lot of research, actually doing experiments in the real physical world is probably necessary. For those sorts of research, just having AI will only speed up the bits that don't involve doing experiments, which is going to cap the speed up at whatever amount of time doing the experiments actually takes (i.e. for example, if they take up 20% of the time, you can at most go five times faster.)
Though in fairness, it only takes 1 important area where doing things in the real world is not a significant time bottleneck for something dramatic to happen.
Yeah, you’re right, thanks for pointing this out. I’ll edit the post to reflect this.