Epistemic status: We think this is a simple and common idea in discussions about AI governance proposals. We don’t expect this to be controversial, but we think it might be useful to put a label on it and think about it explicitly.
Suppose an AGI lab could choose between two safety standards:
- Standard 1: A third-party organization will implement intense auditing procedures every quarter. Training runs above a certain size will not be allowed unless the lab can show strong evidence in favor of safety.
- Standard 2: Labs must have their own internal auditing procedures. There is a fair amount of flexibility in how the auditing should work. If a lab identifies something dangerous (as defined by the lab’s auditing team), they must report it to a third-party organization.
All else equal, people prefer restrictions that are less costly than restrictions that are more costly. Standard 2 is less demanding on labs, but it’s also less helpful in reducing x-risk.
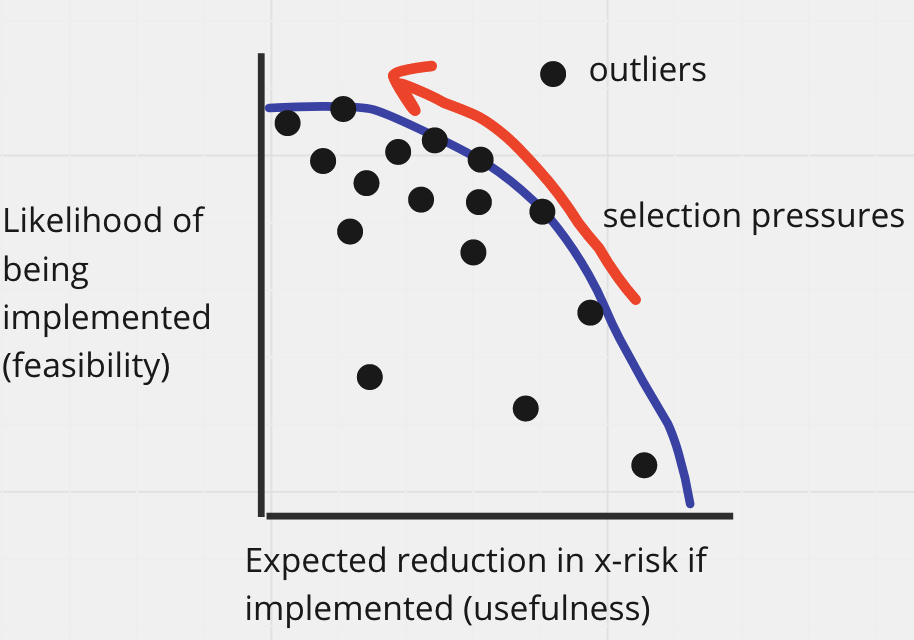
Core point: There is often a tradeoff between the feasibility of a proposal (its likelihood of being implemented) and its usefulness (its expected impact on reducing x-risk, conditional on it being implemented).
We commonly observe this tradeoff in various conversations about AI governance. We don’t think this is a new idea, but sometimes having a term for something helps us track the concept more clearly.
We refer to this as the usefulness-feasibility tradeoff.
Additional points
- Safety-washing. Measures that score highly on feasibility but low on usefulness might be examples of safety-washing. Ideally, we would try to put pressure on labs to raise their willingness to do things that are high on usefulness.
- There are exceptions to the rule. The tradeoff doesn’t always apply, and there are some cases in which a proposal can score highly on both usefulness and feasibility. A potential example would be cybersecurity measures. At first glance, it seems valuable for labs to invest highly in cybersecurity (even if we model them as entirely self-interested) yet also useful for reducing x-risk.
- Legible arguments for usefulness can improve feasibility. Labs are not entirely self-interested. Many lab decision-makers have expressed concerns around catastrophic risks. A proposal can be made more feasible if it is legibly useful for reducing x-risk. However, in cases where lab decision-makers have different threat models than members of the AIS community (e.g., differences in how worried we are about misuse risks relative to accident risks), the usefulness-feasibility tradeoff will still apply.
- Selection pressures may favor less demanding standards (all else equal). If multiple groups (e.g., NIST, Open Philanthropy, the EU, lab governance teams, consulting groups with experience writing safety standards for tech companies) come up with multiple standards, there might be a race to the “least demanding standards.” That is, all else equal, we should expect that labs will prefer standards that minimize the degree to which their actions are restricted. (Of course, if a standard could be argued to be sufficiently useful, this may increase its appeal).
- Less demanding standards could crowd out more demanding standards. For example, if a lab agrees to a set of standards proposed by a consulting group, this might spend political will (and reduce pressure), making it less likely for the lab to adopt another set of safety standards.
- Speculative: On the margin, more people could be thinking about higher usefulness/lower feasibility ideas. In our limited experience, we tend to see most efforts going into standards that are relatively high on feasibility and low on usefulness. Ambitious ideas are often met with, “oh, but labs just won’t agree to that.” On the margin, we’d be excited to see more people thinking about efforts that score high on usefulness, even if they seem to be low on feasibility in the current zeitgeist. (We expect that such proposals will be especially useful if the zeitgeist changes, perhaps as a result of a warning shot, getting closer to AGI, or having more legible arguments for AI risk threat models). Note that we’re pretty uncertain about this bullet point, and it’s possible that we’ve been exposed to an unrepresentative set of AI governance proposals.