This was cross-posted by the Forum team after the time that it was published.
A couple of organizations I’m involved with have recently put out some cool papers relevant to the AI alignment problem, which I’ve emphasized the importance of for how the most important century might go.
I think some readers will find this post too weedsy, but I get a lot of questions like “So what are people literally actually doing to reduce AI risk?” and this post has some answers.
(That said, you should not read this as a "comprehensive survey of AI alignment research," even of recent research. Consistent with other "link posts" on this blog, this is me sharing stuff I've come across and read, and in this case I've read the papers partly because of personal connections to the organizations.)
Eliciting Latent Knowledge
Alignment Research Center (ARC), a two-person organization I’m on the board of, released a paper on Eliciting Latent Knowledge (ELK), which I’d summarize as “trying to think of theoretically robust ways to train an AI such that it will ‘tell the truth,’ even in a sort of worst-case situation where it would be easy by default for it to fool humans.”
The paper largely takes the form of a “game” between a “builder” (who proposes training strategies that might work) and a “breaker” (who thinks of ways the strategies could fail), and ARC is offering cash prizes for people who can come up with further “builder” moves.
The heart of the challenge is the possibility that when one tries to train an AI by trial-and-error on answering questions from humans - with "success" being defined as "its answers match the ones the human judges (possibly with AI assistance) think are right" - the most simple, natural way for the AI to learn this task is to learn to (a) answer a question as a human judge would answer it, rather than (b) answering a question truthfully.
- (a) and (b) are the same as long as humans can understand everything going on (as in any tests we might run);
- (a) and (b) come apart when humans can't understand what's going on (as might happen once AIs are taking lots of actions in the world).
It's not clear how relevant this issue will turn out to be in practice; what I find worrying is that this seems like just the sort of problem that could be hard to notice (or fix) via experimentation and direct observation, since an AI that learns to do (a) could pass lots of tests while not in fact being truthful when it matters. (My description here is oversimplified; there are a lot more wrinkles in the writeup.) Some of the "builder" proposals try to think about ways that "telling the truth" and "answering as a human judge would answer" might have differently structured calculations, so that we can find ways to reward the former over the latter.
This is a theory paper, and I thought it'd be worth sharing a side note on its general methodology as well.
- One of my big concerns about AI alignment theory is that there are no natural feedback loops for knowing whether an insight is important (due to how embryonic the field is, there isn't even much in the way of interpersonal mentorship and feedback). Hence, it seems inherently very easy to spend years making "fake progress" (writing down seemingly-important insights).
- ARC recognizes this problem, and focuses its theory work on "worst case" analysis partly because this somewhat increases the "speed of iteration": an idea is considered failed if the researchers can think of any way for it to fail, so lots of ideas get considered and quickly rejected. This way, there are (relatively - still not absolutely) clear goals, and an expectation of daily progress in the form of concrete proposals and counterexamples.
I wrote a piece on the Effective Altruism forum pitching people (especially technical people) on spending some time on the contest, even if they think they’re very unlikely to win a prize or get hired by ARC. I argue that this contest represents an unusual opportunity to get one’s head into an esoteric, nascent, potentially crucial area of AI research, without needing any background in AI alignment (though I expect most people who can follow this to have some general technical background and basic familiarity with machine learning). If you know people who might be interested, please send this along! And if you want more info about the contest or the ELK problem, you can check out my full post, the contest announcement or the full writeup on ELK.
Training language models to be “helpful, honest and harmless”
Anthropic, an AI lab that my wife Daniela co-founded, has published a paper with experimental results from training a large language model to be helpful, honest and harmless.
A “language model” is a large AI model that has essentially[1] been trained exclusively on the task, “Predict the next word in a string of words, based on the previous words.” It has done lots of trial-and-error at this sort of prediction, essentially by going through a huge amount of public online text and trying to predict the next word after each set of previous words.
From this simple (though data- and compute-hungry) process has emerged an AI that can do a lot of interesting things in response to different prompts - including acting as a chatbot, answering questions from humans, writing stories and articles in the style of particular authors, writing working code based on English-language descriptions of what the code should do, and, er, acting as a therapist. There’s a nice collection of links to the various capabilities GPT-3 has displayed here.
By default, this sort of AI tends to make pretty frequent statements that are false/misleading and/or toxic (after all, it’s been trained on the Internet). This paper examines some basic starting points for correcting that issue.
Over time, I expect that AI systems will get more powerful and their "unintended behaviors" more problematic. I consider work like this relevant to the broader challenge of “training an AI to reliably act in accordance with vaguely-defined human preferences, and avoid unintended behaviors." (As opposed to e.g. "training an AI to succeed at a well-defined task," which is how I'd broadly describe most AI research today.)
The simplest approach the paper takes is “prompting”: giving the language model an “example dialogue” between two humans before asking it any questions. When the language model “talks,” it is in some sense spitting out the words it thinks are “most likely to come next, given the words that came before”; so when the “words that came before” include a dialogue between two helpful, honest, harmless seeming people, it picks up cues from this.[2]
We provide a long prompt (4600 words from 14 fictional conversations) with example interactions. The prompt we used was not carefully designed or optimized for performance on evaluations; rather it was just written by two of us in an ad hoc manner prior to the construction of any evaluations. Despite the fact that our prompt did not include any examples where models resisted manipulation, refused requests to aid in dangerous activities, or took a stand against unsavory behavior, we observed that models often actively avoided engaging in harmful behaviors based only on the AI ‘personality’ imbued by the prompt.
Something I find interesting here:
- An earlier paper demonstrated a case where larger (“smarter”) language models are less truthful, apparently because they are better at finding answers to questions that will mimic widespread misconceptions.
- The Anthropic paper reproduces this effect, but finds that the simple “prompting” technique above gets rid of it:
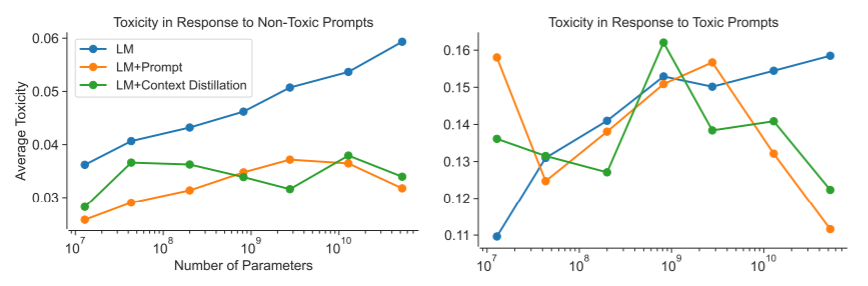
“Number of parameters” indicates the “size” of the model - larger models are generally considered “smarter” in some sense. “LM” = “Language model,” “LM+prompt” is a language model with the “prompting” intervention described above, and don’t worry about the green line.
(As noted by Geoffrey Irving, a very similar result appears in a Deepmind paper that came out around the same time. Reminder that this post isn't a comprehensive survey!)
The paper examines a few other techniques for improving the “helpful, honest and harmless” behavior of language models. It presents all of this as a basic starting point - establishing basic “benchmarks” for future work to try to improve on. This is very early-stage work, and a lot more needs to be done!
Understand the mechanics of what a neural network is doing
Anthropic also published Transformer Circuits, first in a series of papers that represents a direct attempt to address a problem I outline here: modern neural networks are very “black-box-like.” They are trained by trial-and-error, and by default we end up with systems that can do impressive things - but we have very little idea how they are doing them, or “what they are thinking.”
Transformer Circuits is doing something you might think of as "digital neuroscience." It examines a simplified language model, and essentially uses detective work on the model's “digital brain” to figure out which mathematical operations it’s performing to carry out key behaviors, such as: “When trying to figure out what word comes after the current word, look at what word came after previous instances of the current word.” This is something we could've guessed the model was doing, but Transformer Circuits has tried to pin the behavior down to the point where you can follow the "digital brain" carrying out the operations to do it.
It's hard to say more than that in a layperson-friendly context, since a lot of the paper is about the mechanical/mathematical details of how the "digital brain" works. But don't take the lower word count as lower excitement - I think this series of papers is some of the most important work going on in AI research right now. This piece by Evan Hubinger gives a brief technical-ish summary of what’s exciting, as well.
Breaking down and starting to understand the “black box” of how AI models are "thinking" is a lot of work, even for simplified systems, but it seems like essential work to me if these sorts of systems are going to become more powerful and integrated into the economy.
- ^
This is of course a simplification.
- ^
"Prompting" is different from "training." The AI has been "trained" on huge amounts of Internet content to pick up the general skill: "When prompted with some words, predict which words come next." The intervention discussed here is adding to the words it is "prompted with" that are giving its already-trained prediction algorithm clues about what comes next.