Inspired by Aaron Gertler’s notes on hiring a copyeditor for CEA and more recently ERA’s hiring retrospective, I am writing a retrospective on Giving What We Can’s hiring for the Research Communicator role. This is written in my capacity as a Researcher for Giving What We Can. I helped drive the hiring process along with several other team members. The main motivation of the post is to:
- Provide more information for applicants on what the hiring process looked like internally.
- Share our lessons learned so that other organisations can improve their hiring processes by avoiding our mistakes and copying what we think we did well.
Summary
- We received ~145 applications from a diverse pool of candidates, and made one hire.
- We had four stages:
- An initial series of short answer questions — 24/145 moved to the next stage.
- A ~2-hour work test — 5/24 moved to the next stage.
- A work trial (11-hours total) — 2/5 moved to the next stage.
- A final interview and reference checks — we made one offer.
- There are parts of the hiring process that we think went well:
- We had a large and highly diverse pool of candidates.
- We provided at least some feedback for every stage of the application process, giving more detail for later stages.
- We think there were advantages to our heavy reliance on work tests and trials, and the ways we graded them (e.g. anonymously, and by response rather than by candidate).
- There are ways we could have done better:
- Our work trial was overly intense and stressful, and unrepresentative of working at GWWC.
- We could have provided better guidance and/or tools for how long to take on the initial application tasks.
- We could have had better communication at various stages, e.g. on the meaning of some of the scores shared as feedback on that application.
What we did
In this section, I’ll outline the stages of our hiring process and share some reflections specific to each. The next section will provide some more general reflections.
Advertising the role
We made a reasonable effort into ensuring we had as large and diverse a pool of candidates for the role as we could. Some of the things we did include:
- Before the role opened, our Director of Research Sjir Hoeijmakers attended EAGxIndia and EAGxLatAm, in part motivated to meet potential candidates (we thought it was likely we would hire another person to our research team later in the year).
- Once the role opened:
- Many of our team reached out to our own personal networks to advertise the role, especially to those from less represented backgrounds.
- We advertised the role on our newsletter, 80,000 Hours’ job board, and used High Impact Professionals’ directory to reach out to candidates outside our networks.
We think this contributed to a diverse applicant pool, including many candidates with backgrounds, experience, and perspectives that we felt were underrepresented by the existing team:
- The majority of applicants at the work test and work trial stage were women (we mostly graded applicants blindly — more details below).
- When we asked the 145 applications for their country of residence, roughly half were non-English speaking countries, and the majority of those were outside of Europe.
The initial application
We asked applicants to fill in an Airtable form which asked for:
- General information and permissions (e.g., whether they wanted to opt-in to receiving feedback or to us proactively referring them to other related roles in the future).
- Their LinkedIn profile and/or resume.
- Answers to short-answer questions, about:
- Their background with effective altruism or effective giving and interest in the role.
- Specific questions that functioned more as a very quick test (providing an elevator pitch on effective giving, and giving feedback on our recommended charities page).
We then created a spreadsheet view for reviewers to grade individual and anonymised responses to each short-answer question (rather than grading candidates). Roughly, each reviewer graded each response out of seven and this allowed us to aggregate all the reviewers’ scores.

We then used this to give us a short-list of ~40 candidates, for whom we also rated their resumes on a 1-7 scale based on a highly subjective judgement of how much relevant experience we thought the candidate had for the role. Using a weighted average (weighting resumes/background information a bit less) we had an ordered list of the highest scoring candidates. Roughly speaking, we then:
- Decided what thresholds to use to, by default, move the candidate forward (or not).
- We went through a selection of applications more granularly and holistically, to make a decision of whether or not to move the candidate forward to the work test. In some cases this included diversity considerations (providing more weight to candidates with backgrounds, experiences, and perspectives that we felt were underrepresented by our existing team).
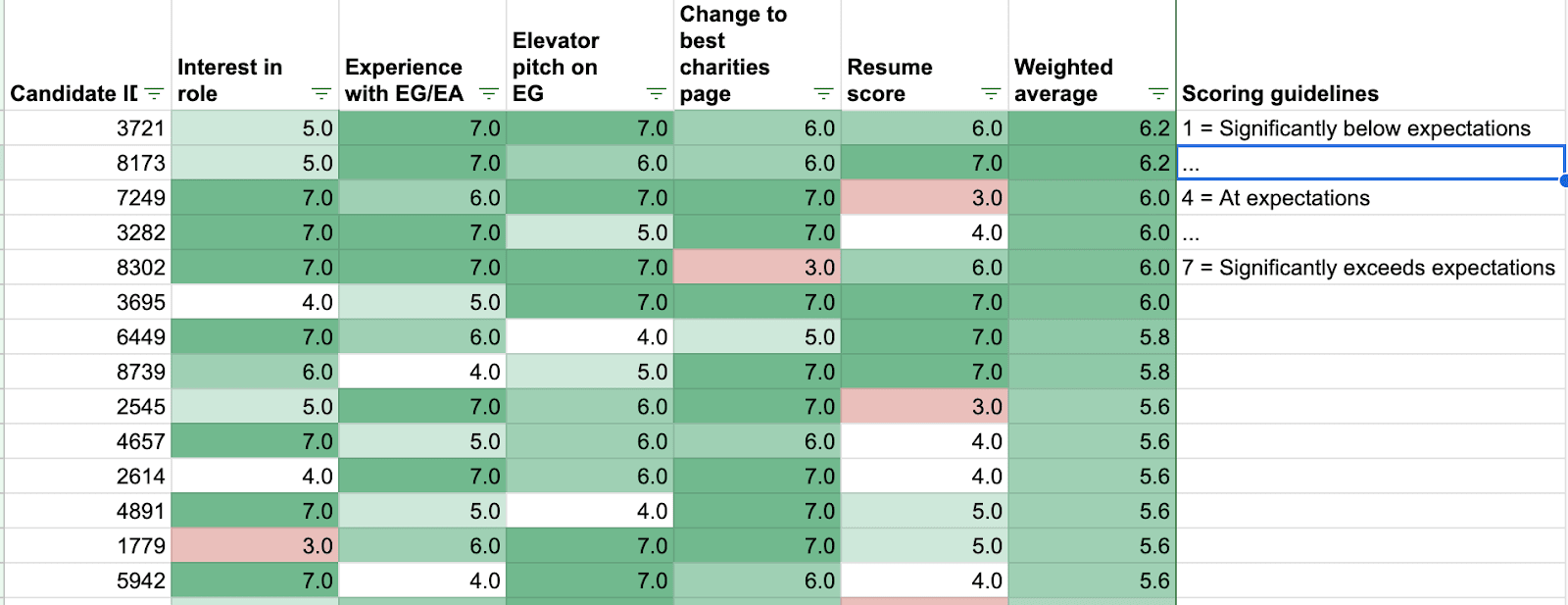
(Note — the figure above is an example using randomly generated numbers and does not reflect actual applicant scores.)
For candidates who (a) we did not move forward; (b) opted into feedback sharing; (c) scored above a certain threshold, we shared a view (like the one above, but with actual scores). This allowed us to provide at least some feedback, but with minimal effort.
Reflections on this stage:
- What went well:
- We liked our grading system overall. Reviewers all agreed that reviewing specific responses to a particular question improved the quality of their grading.
- We liked the balance we struck between preserving anonymity for most of the process, but also including some room for diversity considerations to play a role.
- We think it was the right call to pay less attention to resumes. Though our subjective impression is that they did correlate with work test and trial scores, there were plenty of exceptions where a candidate with a lower scoring resume scored highly on the tests, and vice versa.
- What we could have done better:
- From the feedback form we shared with all candidates, we learned that while feedback was appreciated, it was hard to make sense of what the scores meant and why they were given. We gave further feedback to candidates who asked, and made improvements to the feedback shared at the work test stage:
- We added a more detailed rubric of how we graded responses.
- We provided some exemplar responses, so candidates could see what a high scoring response looked like.
- One regret is that we shared that this stage would take 20–60 minutes, but on reflection, we expect many candidates spent longer (potentially, much longer) on this, and that this time may have in fact improved their application. In retrospect, we could have ensured this was done on a time-limited basis, or provided a more reasonable estimate. Thank you to Amber Dawn’s short-form for pointing this out as a general issue in EA job applications, and drawing our attention to it.
The work test
For the work test, we:
- Created a Google Doc that contained our questions and provided space to answer those questions.
- Created a GuidedTrack survey (using this code) that linked candidates to their specific Google Doc (which was identified via their application ID, to retain anonymity). This allowed us to time the test, as we could see when they started, but also allowed candidates to take the test at a time of their own convenience.
- We graded responses and decided which candidates to move forward using the same process as we did for the initial application.
Reflections on this stage:
- What went well:
- This stage was probably the most successful of all our stages, in part because we found we received substantial information from how candidates performed on the test (arguably, it provided more information than the work-trial!).
- GuidedTrack had several advantages:
- We could time tests (which turned out to be important, as several candidates did in fact go over-time).
- Candidates could take the test at their own convenience.
- Candidates followed instructions as we intended, in part because we erred on over-communicating these instructions (via an instruction document which linked to a short video explainer, our email to applicants, and on the test itself). Usually, at this stage, we would expect some confusion and back-and-forth.
- We were able to give much more detailed feedback for candidates, based on the lessons learned from the previous stage. This included:
- Their raw scores (compared to other candidates) and comments from reviewers.
- Exemplar responses.
- An explanation on how we graded responses in general.
- What could have been improved:
- I don’t think we shared a timeline on when we would get back to candidates with more information, and I think it would have been good to do so.
The work trial
This stage worked very similarly to the work test, except we had two tests:
- One 3-hour test.
- One 8-hour test (including a 1-hour break).
These were written to, as closely as possible, resemble the type of work we imagine the candidate would go on to do, and each included a meeting with a member of our team.
Reflections on this stage:
In retrospect, the 8-hour test being done in a single block of time was a mistake. In addition to scheduling and time-zone issues (I had some of my calls scheduled on weekends, before 7am, and after 11pm) it was overly intense and stressful, and not reflective of what it would be like in the role. While we decided to do this to ensure consistency between candidates, in retrospect, these considerations outweighed the potential advantages of other approaches (like an honest-timed test that could be taken over several days, or possibly weeks).
Another issue was that we provided candidates with very little time (one week) to take the test. While we also shared that such short notice might not be possible, and that requesting an extension would not negatively impact the application, this level of pressure was arguably not reasonable.
Unfortunately, a consequence of our choices here is that one of our five candidates — very understandably — chose not to proceed with their application. We are especially grateful for the feedback they then shared about why they made this decision. One helpful suggestion they offered us was running a Q&A session with each candidate just before the work trial. This could have been an opportunity to more casually meet with them, and discuss any concerns they might have about the work trial.
The interview and reference checks
Our interview stage followed a fairly standard process. We shared with candidates the kinds of questions we would ask, and then they met our Director of Research, Sjir, for the interview (which lasted one hour). We also conducted reference checks at this stage.
We ultimately went into this stage thinking we had two exceptional candidates, and left feeling much the same. Yet, we still think it was an important stage of the process because we could imagine other scenarios in which the interview ended up being decisive. Further, part of the value of the interview is giving candidates an opportunity to meet us and see if we are a good fit for them!
General reflection
We are overall happy with the hiring process, though we think there are several ways we could do better in the future.
Some of our largest actionable take-aways for other organisations conducting hiring rounds are:
- Provide feedback — while it’s not always possible, as a small organisation we were able to find relatively low-cost ways of giving feedback to candidates.
- Solicit feedback — we think that by having a feedback form at the end of our application, we’ve learned a lot on how we could do better in future hiring processes.
- Use GuidedTrack surveys for work tests — we found these really helpful on our end (they were relatively operationally efficient to set up) and yet also allowed candidates to take the tests at their convenience.
- Review individual responses where possible — this is a bit of a niche suggestion, but all reviewers found they were able to give more calibrated scores when they reviewed individual responses to specific questions, rather than reviewing a candidates’ set of responses all at once. We also noticed this in other hiring rounds.
One take-away we’d suggest candidates consider is lowering their bar for communicating with the hiring manager. This is likely to be most relevant for applying to organisations with similar hiring processes to GWWC, but we greatly appreciated when candidates gave us feedback (good and bad). Also, when candidates reached out to us to ask if we could make an alteration to the process so that they could provide a better and higher quality application, we were often able to do this (and even when we couldn’t, there was no harm in having asked). We understand that this can be difficult, given the dynamic, but speaking personally — I expect that when I apply for jobs in future, I’m going to be much more likely to email the hiring manager than I was before!
Thank you to Alana Horowitz Friedman, Sjir Hoeijmakers, Katy Moore and several other reviewers for their thoughtful comments.
This post is part of the September 2023 Career Conversations Week. You can see other Career Conversations Week posts here.



I hadn't seen this until now. I still hope you'll do a follow up on the most recent round, since as I've said (repeatedly) elsewhere, I think you guys are the gold standard in the EA movement about how to do this well :)
One not necessarily very helpful thought:
is a noble goal, but somewhat in tension with this goal:
It's really hard to make a strictly timed test, especially a sub-one-day one unstressful/intense.
This isn't to say you shouldn't do the latter, just to recognise that there's a natural tradeoff between two imperatives here.
Another problem with timing is that you don't get to equalise across all axes, so you can trade one bias for another. For example, you're going to bias towards people who have access to an extra monitor or two at the time of taking the test, whose internet is faster or who are just in a less distracting location.
I don't know that that's really a solvable problem, and if not, the timed test seems probably the least of all evils, but again it seems like a tradeoff worth being aware of.
The dream is maybe some kind of self-contained challenge where you ask them to showcase some relevant way of thinking in a way in time isn't super important, but I can't think of any good version of that.