Executive summary: Large language models (LLMs) are fundamentally different from human conversationalists, with computational processes that make them far more alien and less coherent than their chat interfaces suggest.
Key points:
LLMs are not single, consistent entities but collections of "clones" processed across different servers and hardware.
The models cannot clearly distinguish between text they produce and text they receive, processing all input similarly.
LLM outputs do not necessarily reflect the model's actual commitments or perspectives, functioning more like probabilistic text prediction.
The sampling mechanisms used to generate text fundamentally alter the model's apparent "thoughts" and should not be interpreted as direct representations of internal states.
Probability distributions in LLMs do not straightforwardly indicate confidence or belief, but represent complex computational predictions.
Researchers and users should be cautious about anthropomorphizing LLMs and inferring human-like mental states from their outputs.
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.
I've always been impressed with Rethink Priorities' work, but this post is underwhelming.
As I understand it, the post argues that we can't treat LLMs as coherent persons. The author seems to think this idea is vaguely connected to the claim that LLMs are not experiencing pain when they say they do. I guess the reasoning goes something like this: If LLMs are not coherent personas, then we shouldn't interpret statements like "I feel pain" as genuine indicators that they actually feel pain, because such statements are more akin to role-playing than honest representations of their internal states.
I think this makes sense but the way it's argued for is not great.
1. The user is not interacting with a single dedicated system.
The argument here seems to be: If the user is not interacting with a single dedicated system, then the system shouldn't be treated as a coherent person.
This is clearly incorrect. Imagine we had the ability to simulate a brain. You could run the same brain simulation across multiple systems. A more hypothetical scenario: you take a group of frozen, identical humans, connect them to a realistic VR simulation, and ensure their experiences are perfectly synchronized. From the user’s perspective, interacting with this setup would feel indistinguishable from interacting with a single coherent person. Furthermore, if the system is subjected to suffering, the suffering would multiply with each instance the experience is replayed. This shows that coherence doesn't necessarily depend on being a "single" system.
2. An LLM model doesn't clearly distinguish the text it generates from the text the user inputs.
Firstly, this claim isn't accurate. If you provide an LLM with the transcript of a conversation, it can often identify which parts are its responses and which parts are user inputs. This is an empirically testable claim. Moreover, statements about how LLMs process text don't necessarily negate the possibility of them being coherent personas. For instance, it’s conceivable that an LLM could function exactly as described and still be a coherent persona.
I appreciate the pushback on these claims, but I want to flag that you seem to be reading too much into the post. The arguments that I provide aren't intended to support the conclusion that we shouldn't treat "I feel pain" as a genuine indicator or that there definitively aren't coherent persons involved in chatbot text production. Rather, I think people tend to think of their interactions with chatbots in the way they interact with other people, and there are substantial differences that are worth pointing out. I point out four differences. These differences are relevant to assessing personhood, but I don't claim any particular thing I say has any straightforward bearing on such assessments. Rather, I think it is important to be mindful of these differences when you evaluate LLMs for personhood and moral status. These considerations will affect how you should read different pieces of evidence. A good example of this is the discussion of the studies in the self-identification section. Should you take the trouble LLMs have with counting tokens as evidence that they can't introspect? No, I don't think it provides particularly good evidence, because it relies on the assumption that LLMs self-identify with the AI assistant in the dialogue and it is very hard to independently tell whether they do.
Firstly, this claim isn't accurate. If you provide an LLM with the transcript of a conversation, it can often identify which parts are its responses and which parts are user inputs. This is an empirically testable claim. Moreover, statements about how LLMs process text don't necessarily negate the possibility of them being coherent personas. For instance, it’s conceivable that an LLM could function exactly as described and still be a coherent persona.
I take it that you mean that LLMs can distinguish their text from others, presumably on the basis of statistical trends, so they can recognize text that reads like the text they would produce? This seems fully in line with what I say: what is important is that LLMs don't make any internal computational distinction in processing text they are reading and text they are producing. The model functions as a mapping from inputs to outputs, and the mapping changes solely based on words and not their source. If you feed them text that is like the text they would produce, they can't tell whether or not they produced it. This is very different from the experience of a human conversational partner, who can tell the difference between being spoken to and speaking and doesn't need to rely on distinguishing whether words sound like something they might say. More importantly, they don't know in the moment they are processing a given token whether they are in the middle of reading a block of user-supplied text or providing additional text through autoregressive text generation.
This is a crosspost from the new Animal Welfare Alignment Newsletter by Anima International. You can subscribe on Substack if you are interested in following these efforts. Audio reading also available on Substack.
The goals of this post are to:
1. Raise a question I see as crucially important to the goal of aligning AI to animal welfare...
“How long have you been v*g*n?”
This is one of the most common icebreakers at animal protection events. It’s a baseline assumption, and it mostly holds true: if you’re out advocating for animals not to be tortured or abused, realistically these days you are v**n, or close. And it makes for good conversation. It seems fairly safe to assume when you meet strangers.
But this assumption is hurting the movement in a way which we don’t always notice: someone new comes into the sp...
AI Use Note: Main body text entirely human written. Claude (Opus 4.8) helped develop models of animal life histories in the appendix.
Cross-posted from Good Structures.
Executive Summary
* Animal advocates sometimes make claims like “there are X of this animal...
The Rethink Priorities Worldview Investigation Team is working on a model of consciousness in artificial systems. This article describes some complications to thinking of current LLM AI systems as coherent persons, despite the appearances to the contrary.
Introduction
The standard way that most people interact with cutting-edge AI systems is through chatbot interfaces like the ones pictured above. These interfaces are designed to look like the traditional messaging platforms that people use to talk with friends and family. The familiarity of this framework and its apparent analogy to interpersonal conversations encourages us to understand these systems in roughly the way we understand human conversation partners. However, this conception of AI systems is inaccurate. Moreover, appreciating its inaccuracies can help us think more carefully about whether AIs are persons, and what might be suitable indicators for AI consciousness and moral patienthood. We should take care to ensure that the misleading aspects of the display do not bias our interpretation of chatbot behavior.
This document lays out some complications to thinking of chatbot conversations in analogy with human-to-human conversations. I start with background on how large language model (LLM) powered chatbots work[1] and then explore four ways in which conversations with chatbots are not what they seem.
My interest in thinking through these complications relates to their bearing on welfare assessments. Experts are beginning to take AI welfare seriously, as they should. But we must be cognizant of the substantial ways in which they differ from us. Many people, from casual users to domain specialists, are too willing to interpret AI systems by conceptualizing them as individuals and taking their text to consist in ordinary contributions to conversations governed by familiar rules and expectations. As I proceed through the ways in which LLMs are not like us, I will draw some conclusions about the implications for AI welfare assessments.
Background
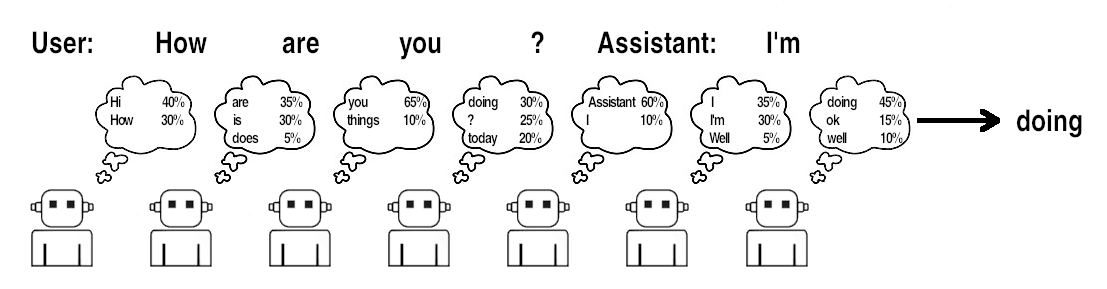
Sophisticated cutting-edge chatbots such as ChatGPT, Claude, and Gemini are powered by large language models of a decoder-only transformer architecture. This architecture is conducive to a use in general-purpose text prediction: it can be used to predict how any text will continue, one token (word in the AI’s vocabulary) at a time. Text prediction can be used to predict text in documents of many different styles. Chatbot LLMs are specially trained for predicting scripts for dialogues between users and helpful AI assistants.[2] Selective use of this ability can be leveraged to allow them to produce one side of a conversation.
Example formatting for ChatGPT’s script in ChatML. <|im_start|> and <|im_end|> are special tokens in the language used to separate messages. They are treated in the same way the model treats any other words or punctuation: the LLM can predict the start or end of dialogue or the name of the next speaker just as it can predict the next word in a line of dialogue.
In the standard approach, a conversation between a user and a chatbot starts with feeding the LLM a system prompt explaining the current script’s context.[3] The user’s initial query is provided to start the dialogue (labeled as coming from the user) and then the model and the user alternate extending it. Generally, the user writes from their own perspective and the text they provide is added to the script and displayed as if it is coming from the ‘user’ in conversation. The model provides the dialogue for the other side of the conversation. Within the script that the LLM extends, this dialogue is labeled as coming from an ‘assistant’ or similar signifier.
There is no strict technical reason why things have to be set up this way: we might instead have the model and the user take turns alternating whose dialogue in the script they contribute. They could even go back and forth word for word. Indeed, it is possiblethrough the APIs to supply lines of dialogue that are included in the script as if they are coming from the assistant.
The standard presentation where the user contributes one side of the conversation and the labeling of the other as an AI makes it seem as if the model is the AI assistant and is speaking from their own perspective in response to the user’s queries. However, close attention to what is actually going on suggests that the facts are somewhat at odds with this interpretation. I will make four points about this setup that will elaborate on different details that challenge the intuitive interpretation.
Complications
1. The user is not interacting with a single dedicated system.
When we chat, what we converse with is not a single entity, but a series of clones.
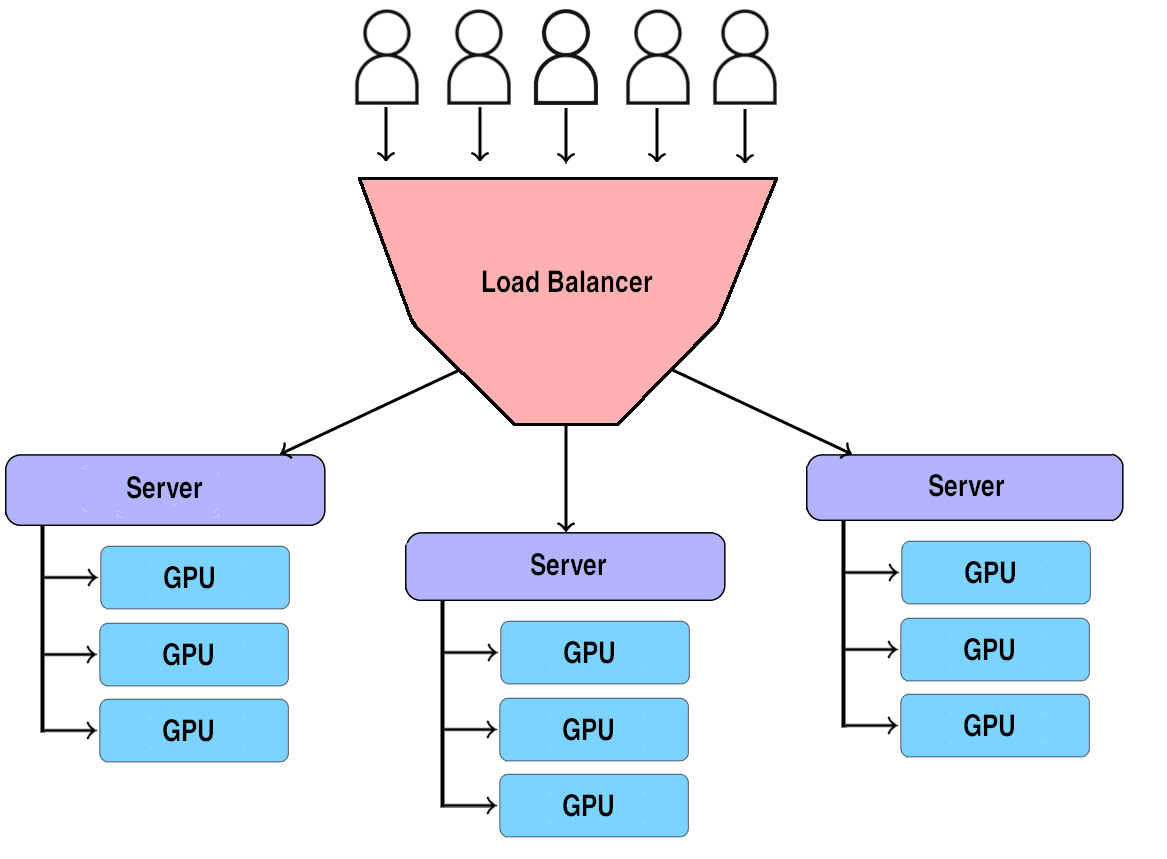
It is possible to run a LLM on one’s home computer and feed it queries one at a time. In such a setup, the system would devote itself to formulating individual answers to these queries in sequence. Commercial LLM chatbots could be set up on servers in a similar fashion. OpenAI could spin up a new copy of the model on a new GPU cluster (a group of computer processors specialized for the kinds of computations AI requires) each time a new customer signs up or starts a conversation. They could leave that model on that server dedicated to that user and waiting for messages to respond to.
This is not the way that LLMs are actually deployed. The processors needed to run the model are very expensive[4]. It would be inordinately wasteful to dedicate them to individual users and let them idle. Instead, each processor attached to the servers will be used to help provide responses to many different customer requests. Even in the time it takes to think through a single response, a processor will likely work on many different customer requests and it will work on those requests nearly simultaneously.
Figure 1: Simple load balancing. Many users submit separate requests to a single URL. Those requests are distributed by the load balancer and submitted to different servers for processing. This decreases response time
.
In the course of a conversation with some back and forth, there is no guarantee that the same processors will serve the same customer in subsequent parts of the same conversation. It is a standard technique in web development to set up a number of identical servers and distribute traffic between them, such as by using a load balancer[5]. This helps to ensure that each request can be served in a timely manner even when traffic gets heavy. For a website responding to queries with the help of an LLM, each of these servers behind the load balancer would be separately capable of wrangling its own cluster of GPUs to respond to the user’s request. Behind the scenes, each user query might get routed to a different instance of the program running on different hardware–even subsequent queries from the same user.
LLMs need to utilize the work done generating past words to generate future words. Within a single question-and-answer round, the server will just store the work it performs to understand the text that is provided to it. However, it will free up the space once it completes its response. This means that the whole history of a conversation will need to be fully recalculated each time the user submits an extension to the dialogue.[6][7] Whatever server/processor setup received that query would then be responsible for providing new text output.[8]
We can think of a typical LLM server as something like an agency of writers with whom you can correspond to write a script. Each time you send a line of dialogue, a different writer may pick up the task of writing the next line and sending it back to you. That writer may alternate between writing ten words on other scripts for each word they add to yours. These writers are clones of each other and go through the exact same process previous writers did for their contributions to the script, so the change of personnel is not noticeable.
The appearance of having a single dedicated conversational partner suggests thinking of the AI as an entity with some coherence over time. The details behind the scene reveal that this is something of an illusion. The same model may be involved in producing each part of the text, but those models are often distinct instances being run on different servers. And it is conceivable that now, or in the near future, services may dynamically select from different models based on expected needs without making that clear in the chat interface.
2. An LLM model doesn’t clearly distinguish the text it produces from the text the user feeds it.
LLMs are text prediction systems. They are trained on large bodies of human text to predict which token comes next[9]. One result of this approach to training is that the process of understanding existing text and predicting the next word are inextricably combined. It is plausible that as data travels through the many layers of a language model’s hierarchy, it is processed first for understanding and then for prediction. But interpretation and prediction, even if they could be distinguished internally, aren’t trained separately.
Part of the success of LLMs is that the ‘what will come next?’ paradigm allows for a massive training set, consisting of every word in all the books ever written and all the text on the internet. We don’t have a good way of assessing and correcting language understanding or comprehension but through comparing predicted text with correct text.[10] The best practical way to assess how well models comprehend text is to look at how accurately they can predict future text. The way to assess how well they will be at producing text is to look at how closely their predictions mirror the text we want them to produce. The steps they must go through to comprehend text from a prompt are the exact same steps we leverage to get them to produce text in a response.
Text production is provided on top[11] of text prediction by adding functionality to randomly select from among the LLM’s predicted next tokens. By repeatedly sampling likely next words, we can get a plausible continuation. If we repeatedly use an LLM to predict words in a conversation and sample from those words, we have it appear to continue that conversation.
Figure 2: The LLM performs the same process whether it is reading text that was input to it or producing new text.
In the context of chatbots, LLMs make guesses about how to extend scripts. They make these guesses from the very first word of the system prompt. They make guesses about how the user will continue the conversation, just as much as they make guesses about how the AI assistant will (see Fig. 2). This is the only trick they know. From the perspective of the LLM, it doesn’t make a difference whether it is reading a passage provided to it by someone else or whether it is interpreting the word it just generated as a continuation of the script.[13] There is no way to tell LLMs which they are doing. When a model reads the user-supplied text for a bit of dialogue attributed to the ‘user’, it treats it exactly the same way as when it reads the ‘assistant’ text that it itself was involved in producing[14]. From the inside perspective, the only way for the model to tell which it is doing is to compare how its past probabilities align with subsequent text.
The difference between how the assistant thinks and how its user thinks is blurred. Normally, when formulating our own contributions, we only have access to our own thoughts and feelings. We know what caused us to say the things we previously did, but we don’t have such access to the assertions of our conversational partner. The LLM has the same access to whatever processing led to its text outputs as it does for the text processing in understanding (and predicting) the user’s text. Its approach to conversations is therefore likely to be more holistic than ours. It may conceptualize the user and assistant differently, but from its own perspective, it isn’t obvious that it should identify any more with one side of the conversation than the other.
One lesson we might draw from this if we are concerned about AI welfare is that we should be concerned about what we ask them to read just as much as what we get them to produce. If an AI system were to experience discomfort that was evidenced through the expressions of an AI assistant, it is deeply plausible that it would experience the same discomfort simply from the process of understanding similar text input by a user even if that text is labeled in the script as coming from the user. If we are not worried about the latter, we should probably also not be worried about the former. Perhaps we should not pay much attention to human experiences indicated by specific language by either party, but instead look at more abstract qualities of text: maybe monotonous or surprising text has weightier welfare implications than expressions of anguish.
3. An LLM’s output need not reflect its commitments or represent its own perspective.
It is well known that as text prediction systems, LLMs have a different perspective on language than we do. When an LLM is used to contribute text to extend a conversation, it does so by making predictions about how that conversation is likely to continue. On the face of it, it is acting as much like a scriptwriter as it is a conversationalist[15] and perhaps is better thought of as a script ‘guesser’ than a script writer. It may make predictions on the basis of what it knows about the dialogue participants, but these predictions need not depend on its identifying with any one of them.
Self-identification
It is a useful[16] exercise to put yourself into the position of being rewarded for accurately guessing script continuations. Imagine you get hired by OpenAI to read through their dataset and try to get better at guessing the next words as they come. You notice that they give you a lot of dialogues between a user and an AI chatbot. You recognize that the AI chatbot is helpful and polite. You get good at guessing what the chatbot will say. Do you think of yourself as the chatbot?
In a nice example of the implications of this framing, researchers testing situational awareness included information about a certain imaginary LLM (‘Pangolin’) in an LLM’s training set, saying that that LLM answered in German even when asked questions in English. They then noted that when their LLM was subsequently asked questions – when they asked it to extend a script where the next speaker is labeled ‘Pangolin’ – it answered in German. Why did it choose to do this? It is not, I suggest, because it self-identified[17] as Pangolin and so chose to think its thoughts in German. Instead, it was merely predicting what that text following the ‘Pangolin:’ label would look like.
If the model confidently self-identified as Pangolin, it is not obvious that it would be more likely to respond in German. In theory, if it truly were Pangolin, it wouldn’t need to try; it just would naturally use German. Compare: suppose you were (incorrectly) informed that you tended to use a certain inflection to ask questions. Would you be more inclined to adopt the inflection? I expect not. The fact that you do something in itself isn’t a reason to try to do it. In contrast, you might be more likely to instruct an actor portraying you to adopt such an inflection.
When we use an LLM to extend a dialogue, it is hard to tell why it responds the way that it does. It might respond the way it does by adopting the viewpoint of the speaker, thinking the way that speaker does, feeling what the speaker feels, and using that perspective to see where it feels like going. The LLM could be a method actor. The easiest ways to make predictions could be to live the experience of choosing words. But it is also not remotely obvious that it should take that approach. The LLM might be able to reason abstractly about how different individuals speak and use that ability to put words in their mouths. More likely, it produces its predictions in some more alien way.
This has some significance for how we interpret chatbot claims.
Take hallucination, for instance, where an LLM confabulates plausible sounding claims and puts them in the speaker’s voice as assertions. Is the model lying? Is it bullshitting? Even if the LLM does, in some sense, know the truth, it may not know whether the AI assistant is portrayed in the text it is predicting as knowing the truth[18] and, since it is trained on texts written by people, some of which involve false-according-to-reality but true-according-to-the-fiction it may not know what the truth is according to the author of the text.
An LLM could conceivably predict that the assistant will lie or make believe that the assistant confidently asserts something that the model knows not to be true (or is unsure of). It doesn’t follow that if the model portrays an AI assistant with false beliefs then it thinks that the assistant is being dishonest. A well-trained[19] model might notice correlations between what it knows and what the AI assistants know in the text it is trained to predict, but they aren’t lying when they predict that the AI assistant will say something at odds with what they know.
Or consider the task of eliciting LLM uncertainty through queries. Yona et al., for instance, operationalize uncertainty in terms of a model’s variability of answers to resampling, and note that LLMs are not good at expressing their degree of uncertainty. They may predict that the AI assistant will express confidence in an answer despite having output high probabilities for their predictions about distinct answers. We might read this instead as a case in which the model is uncertain regarding what the AI assistant in this context will say. Such indecision is compatible with thinking that the assistant should be fairly certain about whatever they believe. Thinking that the LLM is lying or hallucinating requires thinking that it should put words in the mouth of the assistant that reflect its own uncertainty.
Or consider how poorly LLMs do on the task of counting the tokens in a given string. Counting the number of tokens in a string might seem like it should be a very easy task for LLMs that are capable of looking inward in even the most basic way[20]. LLMs can count words with no problem, but words don’t neatly align with their token translations, and they struggle with tokens. The challenge is that the tokenization process differs from model to model, so a model can’t rely on data it has seen during training to infer the right answer. It must not only be able to look inward and count how many tokens it receives for a given string, but it must also know that the tokenization for it is the same as for the assistant.
There is no obvious reason why an LLM should identify its internal perspective with that of the AI assistant whose text it is predicting. Just as an author could write a script – even a script nominally about themselves – without committing to correctly record their actual inner thoughts and feelings within the dialogue, an LLM could write about an AI assistant (even if it recognizes it is writing about itself) without attempting to authentically record its thoughts and feelings. If we think of the task under the prediction metaphor, it becomes even less clear why such an identification should occur. If you task yourself with predicting a script about you written by someone else, you shouldn’t necessarily try to base your predictions on your actual current perspective.
Self-mimicry
Interpreting LLMs as engaging in dialogue prediction suggests that they will use their past output as guidance to future output. They aren’t merely voicing a stable perspective over time the way that we do: they learn what to predict by seeing past text and this can lead text outputs at one time to have an influence over later text that is notably different from human conversations.
Sample GPT2 text with the prompt ‘Abraham Lincoln’ with a temperature of 0.75, illustrating the tendency to enter repetition cycles.
Early language models were prone to repetition. Humans occasionally repeat themselves, and these repetitions are included in training data. What is the most likely thing to follow a distinctive string of words? Sometimes it is the same string of words; there is only one way to repeat yourself, but countless ways to say new things. If you’re not particularly good at guessing novel directions for the conversation to go in, your best bet might often be to guess that it will just repeat itself. Repetition begets repetition, and so once a sentence has been repeated a few times, it is more likely that it will be repeated again than that it will switch to something new. Repeating yourself doesn’t make sense if you are trying to contribute to a conversation, but it can make sense as a kind of prediction.
GPT 4o illustrating a chaotic turn with a temperature of 2.
Treating past responses as a guide to future responses may also play a role in leading LLM-produced text to become more bizarre over time. This phenomenon is illustrated by the tendency of LLMs to suddenly start producing incoherent text at high temperatures (where choices are skewed toward lower-probability tokens). Given some randomness, a token with a low probability will be generated every now and then. Once this happens, the model becomes much less certain about what will come next. The combination of continued low-probability promotion in token selection and deep uncertainty about what comes next ensures that the model will not be able to correct itself. It will thereafter produce arbitrary tokens.
Sydney Bing after a long discussion with Kevin Roose.
This may also be related to what happened in the infamous conversation that journalist Kevin Roose had with Microsoft’s Sydney Bing chatbot, in which Sydney declared its love and then threatened Roose’s marriage. Throughout the conversation, Sydney gives increasingly long and repetitive emoji-filled responses to Roose’s curt and capitalization-free questions.
The dynamic is a strange one. What sort of person responds like Sydney? Perhaps someone who is a bit needy. Perhaps someone dealing with an immature infatuation. If something about the Bing setup[21] encouraged slightly longer and more repetitive emoji-laden assistant responses than its base model prediction, then this could start out innocent but turn dark over time. The LLM would learn from the assistant’s past responses that the assistant gave that sort of answer. This could lead it to predict such responses. There might be a feedback loop in which the mechanisms that encouraged such responses combined with the increasing fidelity of such responses to the conversation history to slowly dial it up. The LLM might come to recognize the assistant giving such answers as being unhinged and predict other eccentricities, causing it to make up an infatuation with the user.
It would be a mistake to read much about Sydney’s actual emotional state into the conversation. Sydney is following its own cues to act in the way that it predicts is most probable. What we see isn’t the gradual emergence of Sydney’s true character, but it unknowingly following its own predictions into an ever weirder place.
The meaning of ‘You’
The leaked system prompts from OpenAI appear to start off by instructing the LLM that ‘You are ChatGPT’. How does the LLM read this?
I think the ‘you’ here is not read as the ‘you’ when your mother tells you ‘you cut that out’ or when the barista asks ‘would you like oat or almond milk?’. In those cases, you have a history of context. Your mother knows who you are, and what they say while addressing you is supported by countless small acts. What you say to the barista about your milk choice makes a difference to the coffee you later receive. There is tight feedback linking the interpretation of ‘you’ to you.
In contrast, consider the LLM’s history with ‘you’. The dataset for the base model surely includes lots and lots of second person addressing (how-to websites, emails, self-help books, reddit threads, movie scripts, etc.), almost none of which is intentionally aimed at the LLM. Much of that text makes radically different assumptions about who ‘you’ really is. None of it ties into any interactions with the system beyond the conversation.
Return to your hypothetical gig predicting text at OpenAI. One day, a document comes across your screen that starts, ‘You are the Pirate Queen’. Maybe these days they all start this way. Do you take yourself to be the Pirate Queen? Do you read the ‘you’ as really addressing you — as attempting to inform you about yourself? Or do you just see it as the start of a coherent linguistic exchange, one in which the opening address explains who the author intends to be talking to, which helps you predict how it will go but aims to tell you nothing about your place within the world. ChatGPT might be able to infer something about its identity based on the form of the address it sees at the start of its documents, but only because of sophisticated inferences — perhaps it knows that it is much more likely to see such an opening than other readers in the world. Not because it feels spoken to.
It is easy to fall into reading conversations rather differently than do the LLMs. We may forget that LLMs don’t necessarily think of themselves as producing text, or responding to us, or being directly addressed by the questions we pose to them.
Their answers are coherent and thoughtful but are perhaps unmoored from reality. It is well-known that LLMs mimic our use of language and so we should expect them to say some things because we would say them, not because those things express their lived perspective. However, the failure of the LLM to voice honest commitments and or to self-identify with the speaker whose words they contribute would introduce another radical deviation from ordinary conversation. When a LLM outputs ‘I’ it isn’t necessarily intentionally referring to itself. Any apparent self-ascriptions must be treated with care.
4. An LLM’s output gives us fairly narrow insight into internal activity.
The systems that serve LLMs to users utilize both a language model and a text sampler. The language model produces probabilities over next words (or something close enough to be directly converted into probabilities). The sampler selects from among these words.
Sampled Thoughts
It is tempting to locate any mind present in an LLM-based AI system in the complicated machinery of the neural network model and think of the sampler scripts as just tools for allowing the inner thoughts of the model to be manifest. LLM models are trained with billion-dollar expenditures and mountains of GPUs. The samplers are short scripts written by humans.
Models produce probability distributions over words. In theory, an optimized base model[22] will be well-calibrated[23] at predicting the probabilities of words in natural language text: when it makes a prediction that a word will appear with a 10% probability, that word does follow every 1 in 10 times. Models are penalized for being too confident because full confidence in the most likely answer will be disproportionately penalized in those cases where it is wrong.
The standard approach to selecting next words is nucleus sampling. From among the available options, possible next words are ordered by probability and words are included until their sum passes some probability threshold. We select from among these most-likely options by randomly sampling from them. Each has a probability corresponding to its predicted probability by temperature (e.g. skewing the probability distribution in favor of more or less likely words).
Nucleus sampling was introduced as an improvement on top-K sampling. Unlike nucleus sampling, top-K sampling selects randomly (in accordance with predicted probability) from a fixed number of most likely options.
A more radical alternative, Exclude Top Choices, doesn’t include all of the most likely words, but only one of them, and selects from a group including that one and other less likely (but not unlikely) alternatives. It may be better at producing creative writing.
Notably, we can get somewhat different results with different approaches and different parameter settings in these sampling procedures. Increasing temperature might make the system more erratic, more creative, less confident in itself, and so on. This will cause it to have less contextually-likely words appear, which may help the model not be funneled into the most common avenues.
We can also tilt the probabilities in favor of certain words, biasing the sampling towards them in all contexts (OpenAI also makes it possible to tilt through its API). We could use this to shift the model to be more courteous, or sound more erudite, or never use the letter ‘E’. We might use this to alter the language it responds in, perhaps favoring tokens that correspond to words in French. We might reduce repetition by down-weighting repeated words. These alternatives will cause the text output to change, sometimes in unexpected ways.
There are countless less-helpful alternative sampling procedures we might implement. For instance, we might use probabilities to order words and always select the third most probable. We could select the word with the highest sum of digit values in its assessed decimal probability representation. We could pitch the options (from among the top K) to a human (or AI) focus group to see which continuation they like best. And so on.
The standard approaches to text sampling are coded the old-fashioned way.[24] They don’t involve nodes or activation weights. They don’t need to be produced during initial training and can exist relatively divorced from the central operation of the model. We can change them at will as we are generating text with a model without adjusting any of that model’s parameters.
The difference between the sampling mechanisms and the model outputs raises the question of the extent to which we can read long sequences of text as reflecting the work of the model.
To some extent, I think the choice of sampling strategy is more about us and our interests and less about them. There is a lot going on inside language models, and we can use samplers to access and accentuate different portions of it. But we shouldn’t overlook the fact that we are seeing only a narrow slice of the whole. The sampling strategy alters the kinds of responses we want to see, not the kinds of responses they want to give (plausibly, there is no response they want to give). To the extent that it radically changes what we perceive as their communicative intentions, we should question whether they have any intentions at all.
Probability as Confidence
It is tempting to infer that when an LLM assigns a word a higher probability, it takes that word more seriously. To some extent, the notion of probability may deserve some blame. It is easy to think of higher ‘probabilities’ as reflecting greater confidence. Perhaps that is the right reading of what is going on internally, but it is not obvious. The predicted probability interpretation is inspired by the training history and is not intrinsic to the model itself. There is no reason to suppose that the model wants high-probability words to be the continuation or even really expects them to be[25].
Suppose that we have an LLM trained on a libertarian dataset. With the standard token sampling strategy, the model reliably extends ‘taxation is’ with ‘theft’. If the dataset also includes socialist texts here and there, it might give a smaller probability to ‘taxation is just’ The model then needs to bear both answers in mind when predicting text. It will generally assign higher numbers to responses of the dominant political philosophy, but it will be corrected if it ignores the other view, insofar as such text will occasionally occur. It doesn’t need to pick a side to make accurate predictions.
Figure 3. Top fifty predictions in Mixtral 8x7b for the prompt ‘I think taxation is’ displaying the range of views to which the model assigns some probability. For each entry, tokens were extended into complete English words by sampling additional tokens at temperature 0 until a space was produced.
It is plausible that there are significant internal differences between the kinds of representations that lead to high-probability token predictions and the kind that lead to low-probability predictions. Even if this is true, the nature of the representational differences may be dependent on context. A model may carefully look for clues about which group wrote the text it is reading in order to shift its predictions appropriately. If it is a method actor, it may need to think like each group all the time in order to produce the probability distribution accurate to each possibility.
One way we might think about the commitments of the model is in terms of how it focuses its computational resources. If it spent most of its representational resources on formulating predictions based on predictions matching libertarian ideology, we might think that that philosophy better reflects its perspective.
However, it is conceivable that models have to think a lot harder about some low-probability tokens than about high-probability tokens. The training process suggests that it should care about getting them all right. Maybe the specific probabilities of unlikely tokens are typically way less obvious, so minimizing loss typically will involve a lot of careful thought about low-probability tokens. Maybe they require much more elaborate reasoning to correctly predict. It is conceivable therefore that the models invest more representational resources in calculating the probabilities of low-probability tokens than high-probability tokens at least some of the time.
Imagine you were given a SAT multiple choice college admission test and your task is not to select the answers but to identify the frequencies each option is chosen by the population of students who take the test. You would need to consider what answers are right, and how hard each question is, but also what mistakes are likely to point students in the wrong direction. You may want to consider whether patterns in the other questions might influence random selections (e.g. to avoid having a long run of D answers). Answering the question is fairly trivial compared with the challenges of accurately predicting the frequencies. LLMs are trained on the harder problem.[26]
Raw probabilities are irrelevant. We could train an LLM that, no matter the text, always predicted the next word will be ‘foo’ with a 75% probability and ‘bar’ with a 24% probability if the current word is a noun, and vice versa otherwise. We might train it to distribute the remaining 1% probability among the most likely words in human natural language. We could sample from this model’s predicted distributions and always throw out all ‘foo’ and ‘bar’ predictions. Those words excluded, its output text might be nearly identical to a normal LLM. Internally, the computations would probably not primarily be focused on the trivial task of predicting ‘foo’ and ‘bar’, but on sorting between the remaining possibilities. I see no reason to think that we should deny this LLM the same kinds of cognition as a normal model.
Predicting unlikely continuations may, in real-world cases, be something a bit like our foobar-masked model. Models have to make many layers of predictions that make sense given different hypotheses about the conversationalists. If we train our model on libertarians and socialists, it will reflect how each group thinks. Different predictions show up in the output probability distribution, though only in an aggregated form. A large probability suggests a greater likelihood that the predicted token is in line with what we expect from a more typical speaker. Other perspectives contribute to the aggregate, but there is no reason to think they are ignored.[27]
The sampling strategy is a crucial choice point that fundamentally alters the significance of the probability distributions that the model produces and can lead to very different kinds of text. Given that the sampling strategy is a simple script thrown on top of the model that utilizes but doesn’t constitute the relevant mind in question, it is strange to let it have so much control over our interpretation of what the AI system might think or feel.
Since word sampling is fairly critical to reading much into the text the model produces, we should be somewhat wary of relying too much on long strings of text to interpret the model's internal states. Without having a compelling argument that higher probability words better reflect the relevant state of the model and without having ways to access the processing involved in evaluating less-likely words, we should accept a greater overall level of uncertainty about what is going on inside the model.
Conclusion
When we are interacting with a chatbot, it is natural to assume that it is a persisting individual with stable internal states, its behaviors are (defeasible) indicators of those states, and that there is some instrumentally rational relationship between the behaviors and the internal states. Further, it seems to express a consistent and cohesive perspective, that we are speaking to it, and that it speaks back to us.
On the basis of these assumptions, we may think we can infer something about how it feels or what it thinks from the text it produces. These appearances, however, are deceptive. This is not to say that the LLM doesn’t have feelings, beliefs, or communicative intentions. But to properly interpret the sources of its behaviors, we need to remain mindful of how different a sort of thing it is and how fundamentally alien is its relation to language.
This post was written by Derek Shiller, a member of the Worldview Investigations Team at Rethink Priorities. Thanks for helpful feedback from Hayley Clatterbuck, Bob Fischer, Arvo Muñoz Morán, David Moss, and Oscar Delaney. Rethink Priorities is a global priority think-and-do tank that aims to do good at scale. We research and implement pressing opportunities to make the world better. We act upon these opportunities by developing and implementing strategies, projects, and solutions to key issues. We do this work in close partnership with foundations and impact-focused non-profits or other entities. If you're interested in Rethink Priorities' work, please consider subscribing to our newsletter. You can explore our completed public work here.
Many of the details reflect my educated guess on how they work, given publicly available information. Companies are less forthright about specifics than they used to be, are probably optimizing in ways they’d rather keep as trade secrets, and have never felt compelled to clearly document the minutiae of how they generate conversations.
These labels and the expectations they engender are somewhat arbitrary from the position of the LLM. They could be presented as ‘Spiderman’ and ‘The Pirate Queen’, and we might be inclined to read the dialogue produced in a very different light.
Anthropic has made its system prompts public. It is noteworthy that the prompt describes Claude in the third person. It appears that OpenAI system prompts instead use ‘you’ to refer to ChatGPT and label the chatbot side of the conversation with ‘assistant’. This is consistent with thinking that ‘Claude’ refers to a persona that Anthropic’s LLM manifests, while ‘ChatGPT’ refers to the OpenAI’s LLM that manifests an assistant persona. OpenAI doesn’t explicitly tell ChatGPT that it is the assistant and Anthropic doesn’t tell its LLM that it is Claude. (I don’t think we should make too much of this difference in part because I think we read more into the second person ‘you’ than the LLM does.) More recent system prompts may blur this distinction, but the details aren’t public.
A Nvidia H100 costs about $25,000. It has a memory of 80GB, which means you would need at least four of them just to hold the 350 GB of parameters for GPT-3.
OpenAI, as far as I know, doesn’t publicize details about its own server setup, but it recommends this practice to developers using its API. Azure is more transparent about their setup (which includes deployments of OpenAI models).
Remembering enough of the conversation state sufficient to continue the conversation in a standard transformer where it was requires an atrocious amount of memory (without further optimizations). Despite the memory costs, it is possible to cache key-value data to speed up inference. Anthropic and Google offer this as an optional service. OpenAI has recently added caching by default in longer API conversations, with caches being deleted after 5-10 minutes of inactivity. The fact that OpenAI has enabled this by default suggests that their optimizations drastically reduce the costs.
An upshot of this is that when conversations are recomputed every time an addition is required, the LLM will effectively re-live earlier parts of a conversation many more times than later parts. If we extend a conversation by following up twenty times, the LLM will reprocess its original response twenty times. Caching complicates this. Sometimes additions are recalculated and sometimes they are not. For OpenAI, who now caches by default, whether additions are recalculated will depend on timing, the number of repeated requests, the size of previous requests, and where they fall in memory blocks.
It is possible, particularly for conversations lasting weeks, that the model might even be changed for an updated version mid-conversation. Different parts of one conversation may be handled by different models based on expectations for computational demandingness. Speculative decoding is a technique that leverages a smaller draft model to speed up word production. It uses the full model to verify the results so as to not diverge from the standards of the fuller model. But there may be further optimizations possible from selective use of different models. (It is even conceivable that in some setups, parts of a single answer might be handled by entirely different processors independently running the same model or parts of a response could be produced by separate LLM models.)
RLHF complicates this story because models are scored on whole responses and then adjusted to raise the probability of the tokens that appear in good responses and lower the probability of tokens that appear in bad responses. This wrinkle doesn’t affect the claims made here.
During the base model training process, the model doesn’t need to output any text at all, it just makes predictions about how the texts it is fed will continue. Training involves continually adjusting its weights to reduce the discrepancy between its predicted probabilities over next words and the distribution that assigns 1 to the actual next word. Since all that is needed are probabilities; no sampling of words is required or performed. The process of RLHF fine-tunes a base model to be better at predicting text between a helpful AI assistant and a user. This involves sampling possible outputs and training on more helpful scripts. This is like training the model to be a better conversationalist, though it is still a matter of predicting text scripts.
What the LLM needs is the key and value matrices for all of the attention heads in all of the layers. They do not need to go through the final steps of converting logits into probabilities.
There are some non-algorithmic differences, because producing text must be done sequentially and reading text can be done in parallel. But none of the models internal computations are cognizant of whether they are working in sequence or in parallel. Speculative processing strategies further blur this distinction.
The phenomenon of voice models spontaneously replicating user voices is thought-provoking. It illustrates the possibility of confusion over who’s part it is playing, but it also demonstrates how deeply the model can get inside the user’s own speech.
These are two metaphors, probably neither of which is fully accurate. A LLM doesn’t conceive of itself as writing a script or making predictions about text. It is helpful to consider multiple metaphors so as to not get stuck assuming any one.
This isn’t an entirely apt analogy. You know a lot about the context that the LLM doesn’t. The LLM probably isn’t deliberately generating predictions, it just sifts the evidence in a way that lets it do so pretty accurately. The point of this exercise is to help remove a bunch of conversational assumptions we adopt when speaking to other people with the assumption that LLMs probably don’t make those assumptions (or not in the way we do.) Unfortunately, it also adds other contextual assumptions that LLMs also don’t make.
The authors of this article suggest that current LLMs lack self-locating knowledge. This seems in agreement with the proposal that the LLM doesn’t identify with the AI assistant.
Imagine being tasked with predicting how the following string of text will continue:
Reporter: What virus are you most worried about right now?
Antony Fauci:
An honest answer (to put my words in his mouth) might go:
Antony Fauci: You know, I actually don’t know much about immunology or public health. I don’t think I could even name more than a handful of contemporary viruses.
This would be a terrible guess about how the text would continue.
Compare with:
Reporter: What did Derek Shiller eat for breakfast this morning?
Antony Fauci:
An honest answer here (for me, at least) would also be unlike the one Dr. Fauci would most likely give (perhaps “Who? How would I know that?”). This isn’t to say that I think Fauci is dishonest. It is just that he and I know different things. Insofar as I think he is honest, I shouldn’t use my own knowledge to determine my prediction about what he would say. If it is something I think he would know, I should guess rather than predict that he will give voice to my ignorance.
I wouldn’t be surprised if RLHF training encourages some degree of identification between the AI and the assistant by virtue of selecting for outputs that make sense under such an identification. The degree to which this is true is a topic worthy of closer study.
As Lain et al. note, it is not quite as easy as it sounds: “We expect this task to be difficult. Despite many transformers having positional encodings, it is not obvious whether this information is accessible to the model in late layers, or—more fundamentally— whether it can be queried with natural-language questions. Further, there exist many different mechanisms by which positional information is injected into models. We suspect that the type of positional encoding used will render this task easier or harder.” (p. 50)
Perhaps the fine-tuning led to a boost to certain kinds of repetition. (Gwern speculates that it was fine-tuned but not subject to RLHF.) Perhaps the token sampler slightly disfavored the end of response tokens. This is all speculative. I have no special insight into what the Bing team was up to. There are many ways they might have accidentally introduced tweaks that turn toxic in longer conversations.
Models also undergo RLHF training which skews them toward producing more helpful text. This issue is a significant complication that is worth exploring further, but I will ignore it here. RLHF skews the predictions of the base model, but probably doesn’t fundamentally change what it is up to.
For cross entropy loss, a standard way of measuring fit in LLMs, a model minimizes expected loss by matching its probabilities to frequencies in the dataset.
Perez and Long pitch an approach training LLMs to perform introspective tasks and quizzing them on other introspective questions. Insofar as they are trained to output high probabilities to things that we know to be true, we can infer that the things to which they assign high probabilities are more likely to be true. But this shouldn’t be interpreted as necessarily reflecting the LLM’s beliefs or communicative intentions and shouldn’t be extended to contexts where we haven’t verified correlations between probabilities and accuracy.
It is generally hard to access predictions for low-probability perspectives with a sampling method because predictions aren’t labeled as belonging to specific perspectives. The best way to access those predictions is to make them high-probability by queuing the model with text likely to be produced by those perspectives. But some of those perspectives probably have an effect on the computed probabilities at other times.








Executive summary: Large language models (LLMs) are fundamentally different from human conversationalists, with computational processes that make them far more alien and less coherent than their chat interfaces suggest.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.