All of Ben_West🔸's Comments + Replies
To decompose your question into several sub-questions:
- Should you defer to price signals for cause prioritization?
- My rough sense is that price signals are about as good as the 80th percentile EA's cause prio, ranked by how much time they've spent thinking about cause prioritization.
- (This is mostly because most EAs do not think about cause prio very much. I think you could outperform by spending ~1 week thinking about it, for example.)
- Should you defer to price signals for choosing between organizations within a given cause?
- This mostly seems decent to me. F

the strength of this tail-wind that has driven much of AI progress since 2020 will halve
I feel confused about this point because I thought the argument you were making implies a non-constant "tailwind." E.g. for the next generation these factors will be 1/2 as important as before, then the one after that 1/4, and so on. Am I wrong?
Interesting ideas! For Guardian Angels, you say "it would probably be at least a major software project" - maybe we are imagining different things, but I feel like I have this already.
e.g. I don't need a "heated-email guard plugin" which catches me in the middle of writing a heated email and redirects me because I don't write my own emails anyway. I would just ask an LLM to write the email and 1) it's unlikely that the LLM would say something heated and 2) for the kinds of mistakes that LLMs might make, it's easy enough to put something in the agents...
The AI Eval Singularity is Near
- AI capabilities seem to be doubling every 4-7 months
- Humanity's ability to measure capabilities is growing much more slowly
- This implies an "eval singularity": a point at which capabilities grow faster than our ability to measure them
- It seems like the singularity is ~here in cybersecurity, CBRN, and AI R&D (supporting quotes below)
- It's possible that this is temporary, but the people involved seem pretty worried
Appendix - quotes on eval saturation
- "For AI R&D capabilities, we found that Claude Opus 4.6 h
Thanks for the article! I think if your definition of "long term" is "10 years," then EAAs actually do often think on this time horizon or longer, but maybe don't do so in the way you think is best. I think approximately all of the conversations about corporate commitments or government policy change that I have been involved in have operated on at least that timeline (sadly, this is how slowly these areas move).
For example, you can see this CEA where @saulius projects out the impacts of broiler campaigns a cool 200 years, and links to estimates from...
I'm excited about this series!
I would be curious what your take is on this blog post from OpenAI, particularly these two graphs:
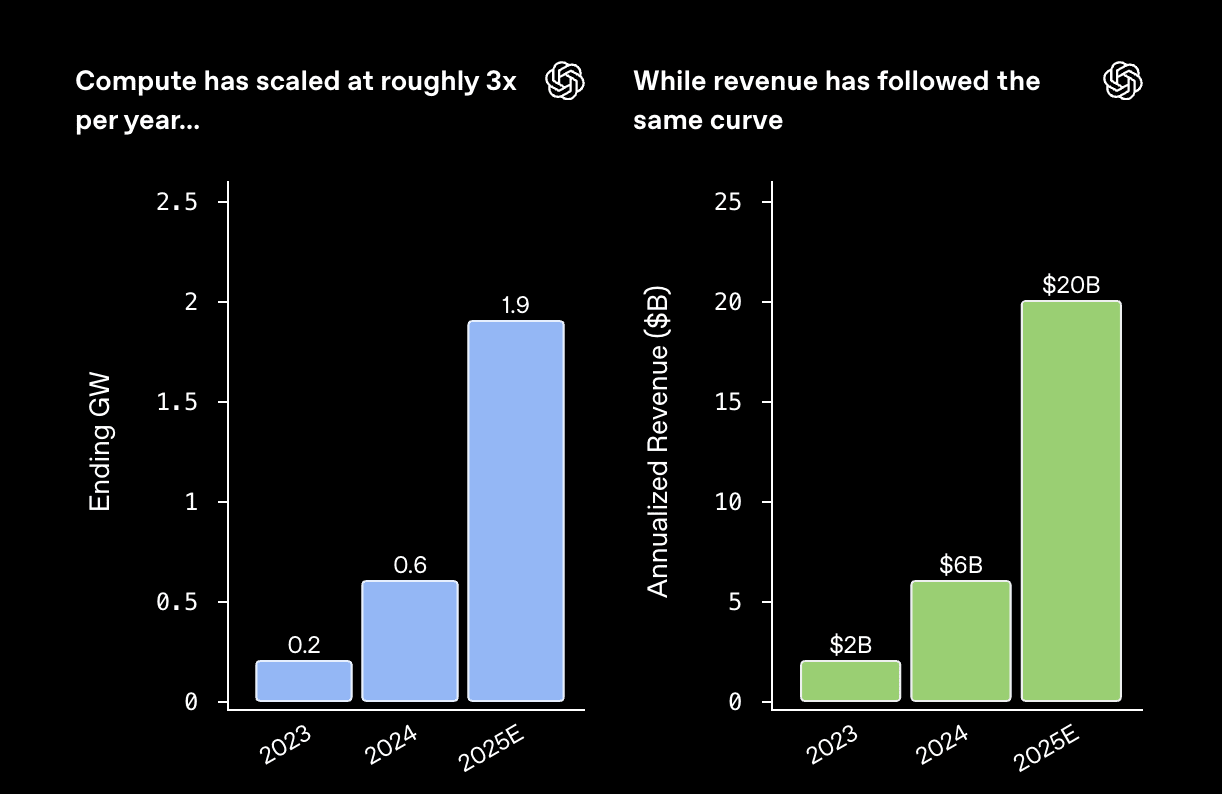
Investment in compute powers leading-edge research and step-change gains in model capability. Stronger models unlock better products and broader adoption of the OpenAI platform. Adoption drives revenue, and revenue funds the next wave of compute and innovation. The cycle compounds.
While their argument is not very precise, I understand them to be saying something like, "Sure, it's true that the costs of both inference and training ...
I think this is a classic potential "correlation" problem. Probably Open AI just cherry picked data which looks good for them. They didn't pick a hypothesis to test, just put 2 graphs next to each other that look the same which is very weak data interpretaiton. Sure both compute and revenue might have increased at 3x a year for 2 years, but that doesn't tell us much. It doesn't mean they have that much to do with each other directly. My guess is that of course there's some relationship between increased compute and revenue, but how much we just don't...
That is quite a surprising graph — the annual tripling and the correlation between the compute and revenue are much more perfect than I think anyone would have expected. Indeed they are so perfect that I'm a bit skeptical of what is going on.
One thing to note is that it isn't clear what the compute graph is of (e.g. is it inference + training compute, but not R&D?). Another thing to note is that it is year-end figures vs year total figures on the right, but given they are exponentials with the same doubling time and different units, that is...
EA Animal Welfare Fund almost as big as Coefficient Giving FAW now?
This job ad says they raised >$10M in 2025 and are targeting $20M in 2026. CG's public Farmed Animal Welfare 2025 grants are ~$35M.
Is this right?
Cool to see the fund grow so much either way.
Agree that it’s really great to see the fund grow so much!
That said, I don’t think it’s right to say it’s almost as large as Coefficient Giving. At least not yet... :)
The 2025 total appears to exclude a number of grants (including one to Rethink Priorities) and only runs through August of that year. By comparison, Coefficient Giving’s farmed animal welfare funding in 2024 was around $70M, based on the figures published on their website.
Is this just a statement that there is more low-hanging fruit in safety research? I.e., you can in some sense learn an equal amount from a two-minute rollout for both capabilities and safety, but capabilities researchers have already learned most of what was possible and safety researchers haven't exhausted everything yet.
Or is this a stronger claim that safety work is inherently a more short-time horizon thing?
This is great.
Thinking through my own area of Data Generation and why I would put it earlier than you, I wonder if there should be an additional factor like "Importance of quantity over quality."
For example, my sense is that having a bunch of mediocre ideas about how to improve pretraining is probably not very useful to capabilities researchers. But having a bunch of trajectories where an attacker inserts a back door is pretty useful to control research, even if these trajectories are all things that would only fool amateurs and not experts. And if y...
Your hypothetical EA sounds kind of like an abolitionist to me :)
The Society formed a ways-and-means committee to deal with the difficulty that more than half of the members, including Troup and Jay, owned slaves (mostly a few domestic servants per household). The committee proposed a plan for gradual emancipation: members would free slaves younger than 28 when they reached the age of 35, slaves between 28 and 38 in seven years' time, and slaves over 45 immediately. This proposal failed however, and the committee was dissolved.
Okay; I guess I was confused by your question because I thought I'd said that in the main doc.
To repeat and with added explanation: Only opinions from before ChatGPT count.
This is because ChatGPT moved the Overton window and changed which sorts of opinions would earn you the horror of contemptuous looks and lowered status, and my negative model of OpenPhil is that they miraculously arrived at a set of opinions which would balance which sort of looks they got from a weighted set of people they cared about. So whatever happened after the ChatGPT ...
Thanks! Perhaps I phrased this poorly; a person being a patient or not isn't the relevant factor, it's whether or not they are licensed. E.g. if you look at the FDA authorization for the first product it says:
The ContaCT mobile application is intended to be used by neurovascular specialists, such as vascular neurologists, neuro-interventional specialists, or users with similar training who have been pre-authorized by their Healthcare Organization or Facility.
I'm actually not sure whether one could generously interpret "similar training" to include e.g. rad...
Thanks for collecting this timeline!
The version of the claim I have heard is not that LW was early to suggest that there might be a pandemic but rather that they were unusually willing to do something about it because they take small-probability high-impact events seriously. Eg. I suspect that you would say that Wei Dai was "late" because their comment came after the nyt article etc, but nonetheless they made 700% betting that covid would be a big deal.
I think it can be hard to remember just how much controversy there was at the time. E.g. you say of...
Your answer is the best that I know of, sadly.
A thing you could consider is that there are a bunch of EAGx's in warm/sunny places (Ho Chi Minh City, Singapore, etc.). These cities maybe don't meet the definition of "hub", but they have enough people for a conference, which possibly will meet your needs.
+1 to maintaining justification standards across cause areas, thanks for writing this post!
Fwiw I feel notably less clueless about WAW than about AI safety, and would have assumed the same is true of most people who work in AI safety, though I admittedly haven't talked to very many of them about this. (And also haven't thought about it that deeply myself.)
LLMs have made no progress on any of these problems
Can we bet on this? I propose: we give a video model of your choice from 2023 and one of my choice from 2025 two prompts (one your choice, one my choice) then ask some neutral panel of judges (I'm happy to just ask random people in a coffee shop) which model produced more realistic videos.
I'm saying that the authors summarized their findings without caveats, and that those caveats would dramatically change how most people interpret the results.
(Note that, despite the "MIT" name being attached, this isn't an academic paper, and doesn't seem to be trying to hold itself to those standards.)
I agree that the authors encourage this misreading of the data by eg saying "95% of organizations are getting zero return" and failing to note the caveats listed in my comment. If you believe that this statement is referencing a different data set than the one I was quoting which doesn't have those caveats, I'd be interested to hear it.
95% of the time, AI fails to generate significant revenue for businesses that adopt it
I think this is a misreading of the study, though the article you link seems to make the same mistake. Here's the relevant graph:
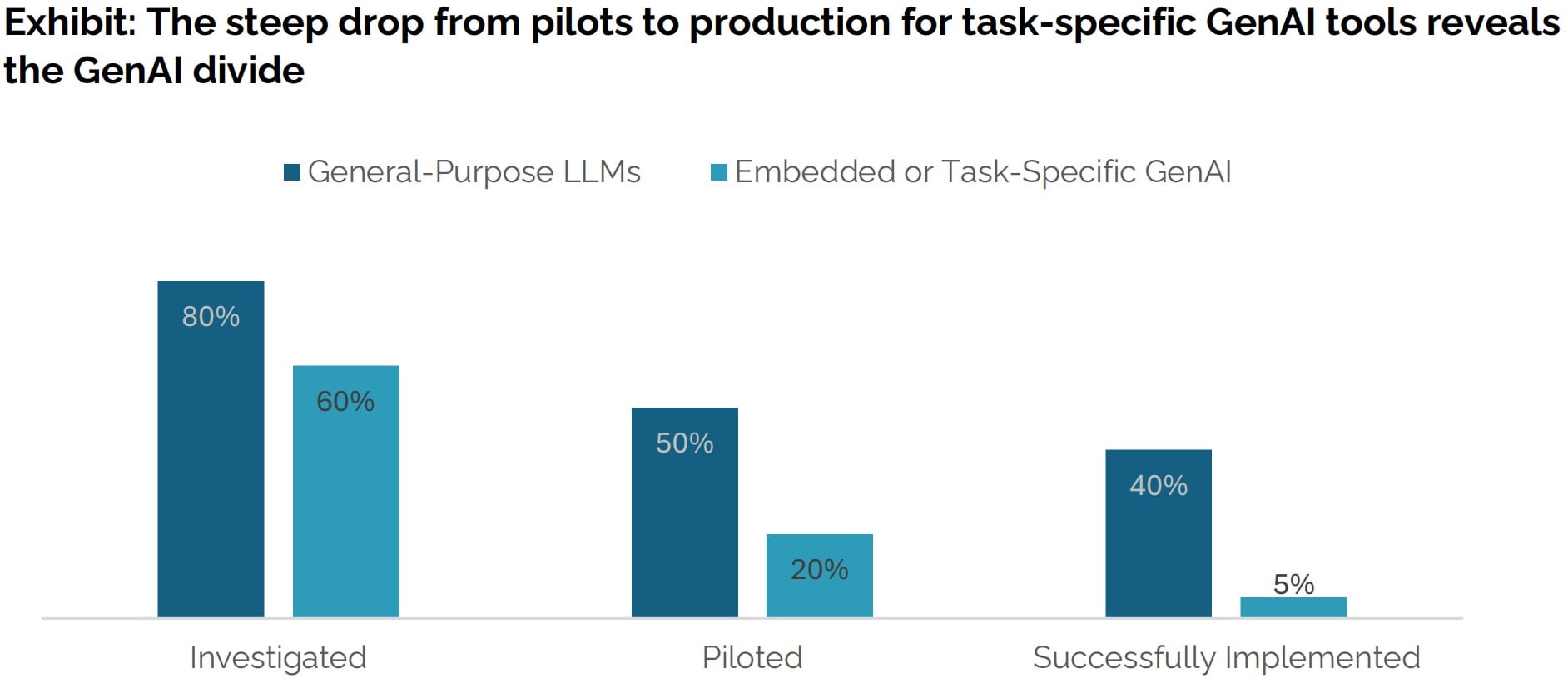
The finding is that 5% of all companies (not just those that have adopted AI) had an executive who reported "a marked and sustained productivity and/or P&L impact" of a task-specific GenAI.
I think a more accurate summary of the paper is something like "80% of LLM pilots are reported as successful by executives."[1]
- ^
Assuming that all successf
+1, this seems more like a Task Y problem.
My impression is that if OP did want to write specialist blogposts etc. they would be able to do that (probably even better placed than a younger person, given their experience). (And conversely, 18 year olds who don't want to do specialist work or get involved in a social scene don't have that many points of attachment.)
Thanks for writing this up - I think "you don't need to worry about reward hacking in powerful AI because solving reward hacking will be necessary for developing powerful AI" is an important topic. (Although your frame is more "we will fail to solve reward hacking and therefore fail to develop powerful AI," IIUC.)
I would find it helpful if you reacted more to the existing literature. E.g. I don't think anyone disagrees with your high-level point that it's hard to accurately supervise models, particularly as they get more capable, but also we have empirical...
Great points both and I agree that the kind of tradeoff/scenario described by @EJT and @bruce in his comment are the strongest/best/most important objections to my view (and the thing most likely to make me change my mind)
Let me just quote Bruce to get the relevant info in one place and so this comment can serve as a dual response/update. I think the fundamentals are pretty similar (between EJT and Bruce's examples) even though the exact wording/implementation is not:
...A) 70 years of non-offsettable suffering, followed by 1 trillion happy huma
In his examples ( and lexically ordered) there is no "most intense suffering which can be outweighed" (or "least intense suffering which can't be outweighed"). E.g. in the hyperreals no matter how small or large .
S* is only a tiny bit worse than S
In his examples, between any S which can't be outweighed and S* which can, there are an uncountably infinite number of additional levels of suffering! So I don't think it's correct to say it's only a tiny bit worse.
Oh yep nice point, though note that - e.g. - there are uncountably many reals between 1,000,000 and 1,000,001 and yet it still seems correct (at least talking loosely) to say that 1,000,001 is only a tiny bit bigger than 1,000,000.
But in any case, we can modify the argument to say that S* feels only a tiny bit worse than S. Or instead we can modify it so that S is degrees celsius of a fire that causes suffering that just about can be outweighed, and S* is degrees celsius of a fire that causes suffering that just about can't be outweighed.
Thanks for writing this Seth! I agree it's possible that we will not see transformative effects from AI for a long time, if ever, and I think it's reasonable for people to make plans which only pay off on the assumption that this is true. More specifically: projects which pay off under an assumption of short timelines often have other downsides, such as being more speculative, which means that the expected value of the long timeline plans can end up being higher even after you discount them for only working on long timelines.[1]
That being said, I think you...
Thanks for doing this. This question is marked as required but I think should either be optional or have a "none" option: