david_reinstein
Bio
Participation2
I'm the Founder and Co-director of The Unjournal; We organize and fund public journal-independent feedback, rating, and evaluation of hosted papers and dynamically-presented research projects. We will focus on work that is highly relevant to global priorities (especially in economics, social science, and impact evaluation). We will encourage better research by making it easier for researchers to get feedback and credible ratings on their work.
Previously I was a Senior Economist at Rethink Priorities, and before that n Economics lecturer/professor for 15 years.
I'm working to impact EA fundraising and marketing; see https://bit.ly/eamtt
And projects bridging EA, academia, and open science.. see bit.ly/eaprojects
My previous and ongoing research focuses on determinants and motivators of charitable giving (propensity, amounts, and 'to which cause?'), and drivers of/barriers to effective giving, as well as the impact of pro-social behavior and social preferences on market contexts.
Podcasts: "Found in the Struce" https://anchor.fm/david-reinstein
and the EA Forum podcast: https://anchor.fm/ea-forum-podcast (co-founder, regular reader)
Twitter: @givingtools
Posts 83
Comments1005
Topic contributions9
I sometimes felt you were implying "no evidence" when I thought something closer to "very weak evidence" would be more appropriate.
Can you provide some specific examples, and I'll reconsider
However, in practice, I would agree the focus should overwhelmingly be on decreasing the uncertainty about the extent to which AI models have welfare, and how to measure it.
I'm not sure if we 'agree' here, or at least that's not the point I was making. I was accepting that AI models (either the information flow itself, or the physical electron flows or something) might indeed "have" or generate consciousness and welfare.
My main doubt was more:
- Suppose this valenced experience and 'welfare' indeed comes about in such a system, which is so very different from human or other biological systems,
- How could we evenr know, even in an expected value directional sense, what things made this welfare higher or lower
- or whether it is even 'net positive' so we want to 'make more of these' or the opposite
- We cannot trust the 'talker' to tell us this and I don't understand what other signals coming out of the AI would be reliable evidence
- This would imply we have 'deep uncertainty' about the impact of our actions on anything welfare-relevant, making our choices morally irrelevant.
So I'm not sure that we have useful ways to decrease the uncertainty about whether th AI models have welfare, and I'm not sure we really have any ways to measure it. But I guess agree we should try to decrease the uncertainty about 'whether we can now or will ever have ways to measure it' (or 'it's valence') ... which is what my post was sort of trying to do.
Perhaps the strongest argument against this would be "what if the model says it is conscious, it is in pain, the data suggests it is not lying and that it is confident in its statement?" I don't find this convincing. ... Even if the talker has no access to the valenced consciousness, it's model may simply lead it to a confident and wrong answer about this.
Did you mean "If" instead of "Even if"?
What I meant was that even if the AI is making a confident statement that it is in pain, and it is not deliberately lying, it doesn't mean that it actually knows the answer to 'is it (or is anything in it's system) in pain'.
So the 'even if' was setting off a contrast between 'not having a access to the answer' and 'making a confident statement'.
Thanks. I've read much of that "bullshit" paper and I think there's some interesting overlap. Some ways I think it relates:
Their "lack of external validation of AI welfare" problem seems at the root of the problem I name that "the signals we get from the AI may not tells us anything directional about the valence of the part of the AI that has consciousness" (if it does). If there is no ground truth (opportunity for 'falsification') here I don't see how we can credibly make that link.
The evidence they cite about the sensitivity of the measures signals of valence to seemingly irrelevant engineering choices reinforces my doubts.
In case helpful, I've been vibe coding a calculator and model og this potential influx here, with input from @MichaelDickens and others
Added and responded to your comments on the page (the hypothesis comments), and then I asked Codex to update to these https://uj-ai-wealth-philanthropy-steelman.netlify.app/ ... I haven't inspected the latest version in detail yet, though.
Some highlights of particular interest to @MichaelDickens , Tobias, and readers/modelers
- More citations, tooltips, direct links, and quoted support for key factual claims, greater reasoning transparency, auditing.
- "Updated the model/text in response to his critiques: especially lockup timing, over-optimistic deployment speed, founder pledge ambiguity, OpenAI Foundation treatment, grantmaker capacity, collapse risk, and the need for distributions rather than just point estimates."
- Clarified "the conversion terms are sequential gates", Made “realization,” “follow-through,” “allocation,” and “deployment by end-2026” more distinct, reduced risk it seems like double-adjusting
- Reframe original 'calculator'
- Added a new tab for correlated uncertainty, added shared latent factors such as liquidity plumbing, donor intent, grantmaking capacity, local optimism, and deployment pressure.
- Clearer planning simulator
- Equations/derivations page
- Automated evidence monitor added
- Added a “Submit your estimate” form.
https://uj-ai-wealth-philanthropy-steelman.netlify.app/
NB it may be getting too complicated to oversee for now, we may want to simplify it
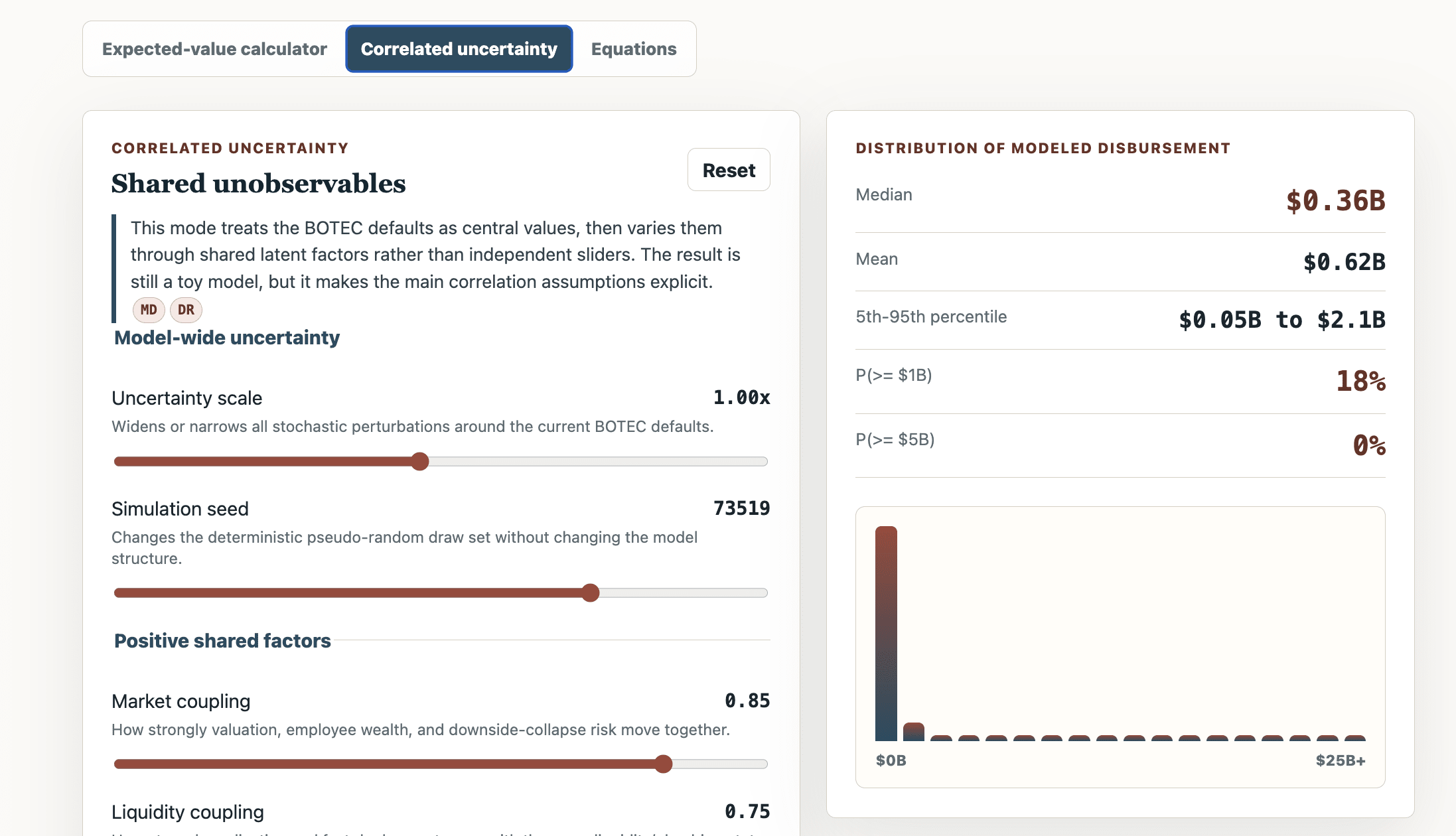
Some updates, mostly automated, based on my inspection and your comments https://uj-ai-wealth-philanthropy-steelman.netlify.app/
I totally agree on using distributions, that's something that can be incorporated in, I've done so in other models/interfaces like here for cultured meat. It's by no means straightforward though; the extent to which the uncertainty is dependent/correlated tends to make a big difference.
I guess I see the deterministic 'model' as more of an interface people could use as a starting point, playing around with each parameter interactively and getting a sense of how these disturbances would affect the aggregate forecast.
This connects to two of our Unjournal Pivotal Questions workstreams. One is on CM cost and viability (related to our post on this here) where we just ran a workshop on cost trajectories (summary here, more reporting to come). The other is on PBA substitution, where the cannibalization question you raise is close to the central one. (Note, we are also planning a workshop for the substitution question: see the resource page here_
On substitution, my main worry is that it's very hard to measure even for products that already exist. From the earlier post, our forest plot of cross-price elasticities is all over the map: credible studies find PBAs to be substitutes for a given meat in some cases and complements in others, with no obvious study-level feature explaining the divergence. Moving outside of PBA/meat, Bray, Sanders and Stamatopoulos (2024) sharpen the concern. In a grocery pricing experiment they find an own-price elasticity around -0.34, versus roughly -2.0 from observational scanner data on comparable stores, and the usual IV and difference-in-differences "fixes" don't close the gap. So I might hold the existing PBA substitution evidence fairly lightly in either direction, which makes me cautious about leaning too hard on it to assess CM.
Going further, see this AI-driven report aiming to synthesize the evidence on 'what can we measure' here.
For cultivated meat itself the evidence is a thin reed at best. You already flag that survey-based WTP is unreliable; I'd push that further. For a product that basically doesn't exist at retail scale (and in a category seemingly rather sensitive to price, brand, framing) and context, I doubt we'll learn much about who actually buys it until it's on shelves and menus. Attitudes can move a lot: in the mid-1990s (from my experience) many/most Americans treated raw fish as absurd and repulsive. Today a large majority have tried sushi, with only about third of Americans never having tried it per one restaurant-chain survey (and about a third having eaten sushi with raw fish in the past year in a 2016 -- paywall linked, I'm relying on chatGPT there).
On cannibalization itself I'm a little less worried than you, mostly because plant-based seems to have a fairly low market-share ceiling so far, so if it gets a decent market share, cannibalization won't matter much.
Fwiw, here's a similarly AI-guided report (with human feedback) on the consumption of plant-based-alternatives. Its market share is still rather low (1-3% at best), but the evidence points it being purchased and consumed mainly by omnivores rather than veg*ns. That makes me a tiny bit more optimistic that if CM is made appealing it will also be consumed by omnivores.
Project Idea: 'Cost to save a life' interactive calculator promotion
What about making and promoting a ‘how much does it cost to save a life’ quiz and calculator.
This could be adjustable/customizable (in my country, around the world, of an infant/child/adult, counting ‘value added life years’ etc.) … and trying to make it go viral (or at least bacterial) as in the ‘how rich am I’ calculator?
The case
While GiveWell has a page with a lot of tech details, but it’s not compelling or interactive in the way I suggest above, and I doubt they market it heavily.
GWWC probably doesn't have the design/engineering time for this (not to mention refining this for accuracy and communication). But if someone else (UX design, research support, IT) could do the legwork I think they might be very happy to host it.
It could also mesh well with academic-linked research so I may have some ‘Meta academic support ads’ funds that could work with this.
Tags/backlinks (~testing out this new feature)
@GiveWell @Giving What We Can
Projects I'd like to see
EA Projects I'd Like to See
Idea: Curated database of quick-win tangible, attributable projects