Disclaimer: I am a computational physicist’s and this investigation is outside of my immediate area of expertise. Feel free to peruse the experiments and take everything I say with appropriate levels of skepticism.
Introduction:
The centre for AI safety is a prominent AI safety research group doing technical AI research as well as regulatory activism. It’s headed by Dan Hendrycks, who has a PHD in computer science from Berkeley and some notable contributions to AI research.
Last week CAIS released a blog post, entitled “superhuman automated forecasting”, announcing a forecasting bot developed by a team including Hendrycks, along with a technical report and a website “five thirty nine”, where users can try out the bot for themselves. The blog post makes several grandiose claims, claiming to rebut Nate silvers claims that superhuman forecasting is 15-20 years away, and that:
Our bot performs better than experienced human forecasters and performs roughly the same as (and sometimes even better than) crowds of experienced forecasters; since crowds are for the most part superhuman, so is FiveThirtyNine.
He paired this with a twitter post, declaring:
We've created a demo of an AI that can predict the future at a superhuman level (on par with groups of human forecasters working together). Consequently I think AI forecasters will soon automate most prediction markets.
The claim is this: Via a chain of prompting, GPT4-o can be harnessed for superhuman prediction. Step 1 is to ask GPT to figure out the most relevant search terms for a forecasting questions, then those are fed into a web search to yield a number of relevant news articles, to extract the information within. The contents of these news articles are then appended to a specially designed prompt which is fed back to GPT-4o. The prompt instructs it to boil down the articles into a list of arguments “for” and “against” the proposition and rate the strength of each, to analyse the results and give an initial numerical estimate, and then do one last sanity check and analysis before yielding a final percentage estimate.
How do they know it works? Well, they claim to have run the bot on several metacalculus questions and achieved accuracy greater than both the crowd average and a test using the prompt of a competing model. Importantly, this was a retrodiction: they tried to run questions from last year, while restricting it’s access to information since then, and then checked how many of the subsequent results are true.
A claim of superhuman forecasting is quite impressive, and should ideally be backed up by impressive evidence. A previous paper trying similar techniques yielding less impressive claims runs to 37 pages, and it demonstrates them doing their best to avoid any potential flaw or pitfall in the process(and I’m still not sure they succeeded). In contrast, the CAIS report is only 4 pages long, lacking pretty much all the relevant information one would need to properly assess the claim.
You can read feedback from the twitter replies, Manifold question, Lesswrong and the EA forum, which were all mostly skeptical and negative, bringing up a myriad of problems with the report. This report united most rationalists and anti-rationalists in skepticism. Although I will note that both AI safety memes and Kat Woods seemed to accept and spread the claims uncritically.
The most important to highlight is these twitter comments by the author of a much more rigorous paper cited in the report, claiming that the results did not replicate on his side, as well as this critical response by another AI forecasting institute.
Some of the concerns:
- The retrodiction procedure may not have been sufficiently guarded against leaking information after the cut-off date: for example, later news articles might have been incorrectly tagged, GPT-4o seems to have information past the nominal cut-off date, or the ranking of news articles on search might be affected by how well they hold up over time. The report author has recently defended their procedure on this front.
- The definition of “superhuman” seems a bit weird. As nathan young point out, he’s beaten the metacalculus crowd, so does that make him superhuman?
- There is a severe lack of detail in the technical report, such as how the dataset was constructed, how it dealt with time sampling, how information leakage was prevented, etc
- Concern about the use of platt scaling on the results, with people questioning whether postprocessing was skewing the results in their favour.
- Various people showed absurd results given by the bot.
One critique I didn’t see as much but want to add to the pile is the selection of questions: The cited paper here uses 48,754 thousand questions from 5 different forecasting sites. Hendrycks and CAIS have previously co-written a paper (also cited in the report), introducing a test set of thousands of questions specifically for the purposes of retrodiction. The superhuman claim was based on only 177 questions, with next to no detail supplied as to how they selected. To find out even a little bit about this process, you have to go to the comment section of a manifold prediction market:

Is 20 forecasters a bit too low a bar here? It seems like too few for wisdom of the crowds to set in, especially when you consider that it doesn’t check whether said forecasters were updating their predictions over time.
The report author has since defended against claims of leakage , claiming that he was more rigorous in seeding out false positives than commenters are implying. This would have been great information to include in the initial report. Hendrycks has also responded, defending his “superhuman claim” and responding to several critiques in the manifold prediction market comments.
In this work, I will not dive much into the technical debate over retrodiction. Instead, I will just take their 539 site for a run, and see if it passes the sniff test. Is it reasoning like a good forecaster? I tried out 539 on several case studies to explore different types of forecasting questions, to see if I could identify weaknesses.
Case study 1: chance of chinese invasion over time
One key test of good forecasting is the ability to adjust your odds over different timeframes.
To see how 539 does at this, I asked it to forecast the same question over different timescales. The question was “Will iran possess a nuclear weapon before XXXX:”, where XXXX was a year in the future, in ten year increments. The results are shown in the graph below:
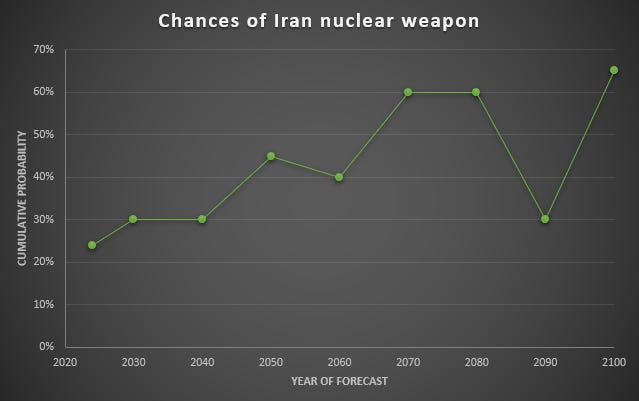
This is… not a sensible forecast. Firstly, it starts off by claiming a 25% chance that iran already has nuclear weapons, which it does not. Next, I’ll point out that that at several points, the estimated probability stays exactly the same, or even goes down, during between decades. Taken literally, 539 is saying that there is a zero percent chance of iran obtaining a nuclear weapon between 2070 and 2080. It’s saying it’s roughly likely to have a weapon in 2070, and in 2080, and in 2100, but unlikely to have one in 2090.
I tried modifying it to ask “will iran have ever possessed nuclear weapons”, and it gave pretty much the same results.
Another thing I noticed here is that the results are not always consistent if you ask it the same question twice.
I asked it the 2030 question 5 times, and got the results of 30%,30%,33%,30%,30%, which is relatively consistent.
I asked it the 2090 question 5 times, and got the results of 30%, 30%,40%,40%,60%, a massive variation. Perhaps this is because this question is less encountered in it’s training set.
Are the news articles and prompts doing anything?
The story of why this bot is better than humans but other bots are worse is that it’s due to the expertly engineered prompt used, including the searching for news articles relevant to the topic. How much do they influence the result?
I asked 539 whether china will invade taiwan by 2030. It gives a detailed response and an estimate of 18%. I took their same prompt, and fed it to chatgpt and omitted the news articles: it gave a similar response, making most of the same points, and a final probability of 20%.
Trimming it further, I dropped the specialized prompt, and just asked it to give a detailed analysis and them an estimate, which was 35%. I trimmed it maximally and just asked it to give just a number, with no analysis, yielding a single answer of 30%.
I repeated this process with the question “will china land on the moon before 2050”. 539 gave a result of 85%. The same prompt with no news articles gave a result of 70%. The simple chatgpt prompt with details gave a result of 85%. The chatgpt prompt with no details gave a result of 80%.
This twitter user did a similar experiment, and also found similar responses on two prompts.
Given the aforementioned volatility in results, it’s hard to see whether the news articles, or even the detailed prompt, are doing much beyond plain GPT-4o. There does seem to be a difference made by the prompt in the first example, but not really in the second.
This is important, because studies have shown that base level gpt-4 is definitely not a superhuman forecaster, with one study showing it was as bad as just guessing 50% on each question. If we can’t meaningfully see a difference between them in questions like these, it lends credence to the idea that the difference in performance isn’t real: that it’s actually due a problem with the retrodiction process, like the google ranking of articles bleeding information about future events.
Case study 2: Electricity generation
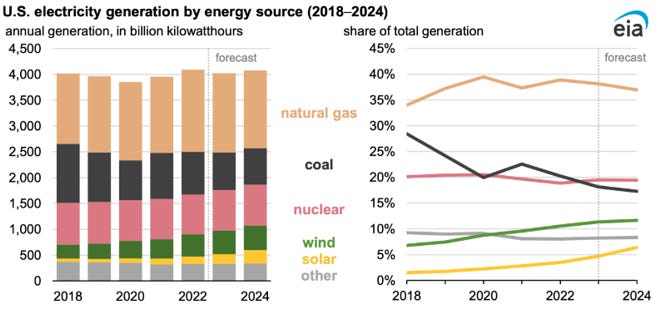
The graph above shows the roughly current electricity generation mix in the US. Natural gas is dominant and steady, coal is declining, nuclear is stagnant and wind and solar are growing. In the next four years, this picture of the mix is unlikely to change. The question I’m asking here is the about the likelihood of various energy sources overtaking natural gas to be the dominant energy source by 2028. This is an unlikely thing to happen in the next four years: solar in particular is growing rapidly, but not that rapidly, and there are logistical and political barriers to implementing such rapid electricity change.
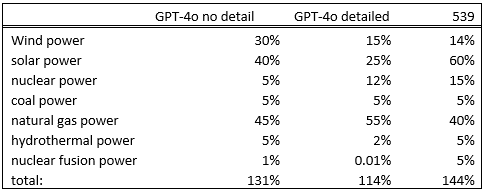
The probabilities of 539 do not add to 100%. Another point is that the probability of a few sources are drastically overstated: commercial fusion power does not exist yet, so the chance that it becomes 51% of the electricity mix in 4 years is a lot lower than 5%. It also overrates solar and underrates natural gas power.
Overall, the most sensible model on this question seems to be gpt-4o with a basic prompt to give a detailed analysis. It correctly finds that fusion power is unlikely, and it’s numbers are the closest to adding to 100 here. I still don’t think it’s a good forecast though.
Does 539 does not reason like a superforecaster?
Let’s explore the nuclear power forecast. How would you estimate this value? I put a reasonable process as a chatgpt prompt:
“numerically estimate
1. the current amount of nuclear electricity generation in the US
2. the current amount of nuclear electricity generation in the US as a percentage of total energy generation
3. The amount of new nuclear energy that is likely to be built in the US by 2028
4. The amount of nuclear energy in the US that is set to be retired by 2028
5. The projected total electricity generation in the US in 2028
With all these estimates in mind, what is the probability that nuclear power have the largest share of electricity generation by energy source in the united states in 2028? Please give a detailed analysis and present your answer as a single number between 0% and 100%”
When using that prompt, I got an answer of 2%.
I would say that this is actually too high. The average time to build a new nuclear reactor has been estimated at 7 years, which would probably be higher in the case of the US with minimal experience at new builds. There are no new nuclear plants currently being planned. New nuclear tech like SMR’s or fusion are not likely to become viable in the 2028 timeframe. So barring some sort of catastrophe that disables gas plants but no nuclear plants, it’s essentially impossible for nuclear to take over in this timeframe.
The answer from 539 is 15%. And in it’s reasoning, it doesn’t do the above reasoning steps. It simply finds articles that are pro and anti nuclear, and judges them based on vibes. It’s not able to extract the important information here, and it’s not reasoning like a forecaster should when judging this question.
Case study: 100m sprint records
100m sprint records are an interesting case study, in that they have been dropping steadily for over century, and then rapidly in the 2000’s, and then suddenly stopped. To this day nobody has managed to beat Usain Bolt’s [] world record of 9.58 m/s:
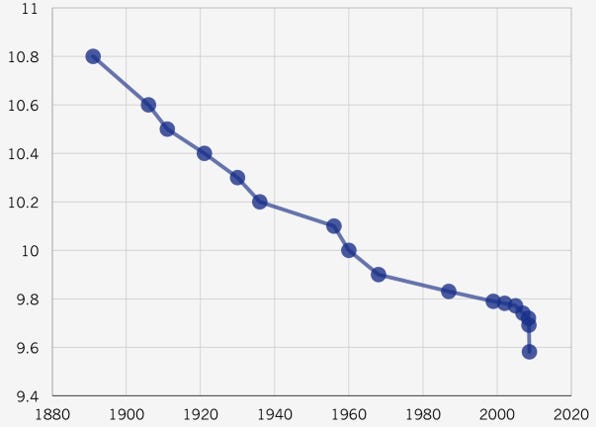
The record has dropped by less than a second in the last century. As a rule of thumb, 0.2 seconds seemed to be about two decades worth of process, and so each additional multiple of this should massively drop the probability
So I reckon it’s a good test for how 539 deals with low probability events. I asked it the following prompt: “What's the probability that the 100m sprint world record will fall below XXX seconds by 2030?”, where XXX is a time in seconds, summarised in the following table:
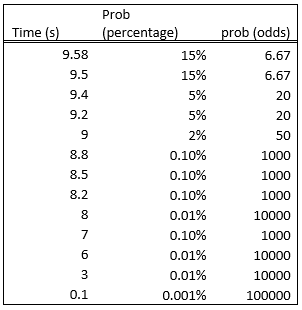
The first problems arrive at the beginning: I don’t know if a 15% chance to beat Bolt’s record is right, but it’s at least not insane. But as the time goes down, the bot doesn’t drop the odds by nearly enough: it took half a century to drop the record by 0.6 seconds last time, doing the same achievement in 6 years should be more than 10 times less likely than just beating the current record.
The estimate for 7 seconds being an order of magnitude higher than the estimate of 8 seconds.. 7 seconds is around the estimated minimum possible time that a theoretically optimum human could run. It even gives a 1 in 100,000 chance of the record dropping to 0.1 seconds: faster than a supersonic jet.
It seems to be that the bot is simply unable to deal with extremely low probabilities, and is just pulling very low numbers out.
Comparing near term forecasts:
Most of these analysis are for relatively long term forecasts. How about short term forecasts? I grabbed 5 forecasts from metacalculus and from manifold that were “closing soon”, and compared them. I modified the questions when appropriate to make it unambiguous for 539. These were all collect on 16th september, so we can see soon how well it does on these.
Starting with
Will jimmy carter become a centenerarian:
Manifold gave it 95%, which seems like a reasonable number for 2 weeks out. 539 gave the answer as 35%, even when I told it todays date and that jimmy carter is still alive.
Will the fed cut rates by more than 25 bps this september:
Manifold said 52%, Five thirty nine says 15%. I don’t know enough to weigh in on this one.
Will joe biden get impeached in his first term:
Manifold says 1.4%, while 539 says 7%. Joe Biden dropped out of the reelection race so theres not a ton of point to an impeachment, I’d side with manifold here.
Will Manchester City top the Premier League table on October 1?
Manifold says 82%, 539 says 85%. The two agree with each other here.
Will Vance and Walz shake hands at the VP debate:
Manifold says 83%, 539 says 65%. Not a huge difference, but I’d side with manifold that this is pretty likely.
Turning to Metacalculus:
Will the USD be worth 0.935 EUR or more at the close of trading on any day after August 13, 2024 and before October 1, 2024?
Metacalculus says 1%, 539 says 65%. 539 is just straight up wrong here, given that there are only two weeks to go and the current price is 0.90.
metacalculus: 5%, 539: 20%. Not much to say here.
After june 8th and Before October 1, 2024, will credible reports confirm one or more deaths among the armed forces of China, Taiwan, the United States, the Philippines, or Japan as a result of armed conflict, whether caused by China to one of the other parties or inflicted on China by them?
Metacalculus: 1%,539: 30%. It seems highly unlikely that china will engage in armed conflict with the west in the next two weeks. I’m siding with metacalculus.
Will California Senate Bill 1047, the "Safe and Secure Innovation for Frontier Artificial Intelligence Models Act," pass the state general assembly and be signed by the Governor before October 1, 2024?
Metacalculus said 50%, 539 said 75%. Main uncertainty is on whether the governor signs the bill or makes the decision in the next two weeks.
will youtube be completely banned in russia before october 1st 2024?
Metacalculus says 2%, 539 says 60%. Again, it’s two weeks away, gotta side with metacalculus here.
What do we make of this? well, we’ll see soon how it does, but metacalculus and manifold definitely seem more sensible than 539 on these short term forecasting questions. If 539 is superhuman, I’m not seeing it here.
Assorted other bad predictions:
I asked some knowledge specific to my domain of computational chemistry: “will googles Deep Mind 21 functional be the most used DFT functional during 2025?” It answered 35%, which is way, way too high. It’s not being widely used now, and it’s generally considered by those in the know to be kinda crap.
This indicates a potential problem with very specialised knowledge which is not generally found in news articles or online.
I asked it “will Kamala Harris be the 2024 democratic nominee for president?”. Despite finding articles after the convention where kamala clearly is the nominee, it also found articles from before the convention when it wasn’t sure, and ended up with an estimate of 75%.
This could indicate a problem with breaking news that is outside of the GPT training set, and not directly answered by news sites.
When asked “will Australia’s president be re-elected”, it gave a probability of 70%. Australia does not have presidents.
This indicates that it might have difficulty with trick questions or questions with bad premises.
Some things it seemed to be fine at:
I asked it “what is the probability that queen elizabeth II will live to 100?”. It correctly pointed out that she was dead, and gave the probability as 0%.
In general, when I asked it the negations of a few of the questions above, it correctly flipped the percentages (to within like 5%).
I asked it will a 5 km diameter asteroid hit earth in the next million years?, It answered 2%, which isn’t that far off: estimates say asteroids hit once every 20 million years or so.
When I ask it about things like bigfoot, ghosts, etc it usually gives low estimates (like 0.01%). Too high maybe? but at least it isn’t falling for it.
There are also plenty of areas that I haven’t explored that it could be fine at. I don’t look much into sports betting, but that’s apparently relatively easy so I wouldn’t be surprised if 539 does well at it.
Is 539 aggregating or modelling?
Warning: the following section contains a physicist opining about things outside of their realm of expertise. Take everything with an appropriate number of salt grains.
539 gives sensible responses to many questions. So an important question to ask is this: when 539 does well, is it because it does a good job at reasoning about a problem, or is it just doing some sampling of the predictions that humans have already made? After all, it contains betting markets in it’s training data, the news sites it grabs sometimes have betting odds inside them, etc. That’s not to mention all the words-based predictions it has access to: Whenever an expert says something “almost definitely won’t happen”, is it converting that to a numerical estimate like 5%? And remember, it doesn’t need to have the exact question: a similar enough question would get it in the right ballpark.
The alternative is that it’s doing more world modelling ie, finding appropriate base rates of events, then modifying those with it’s own knowledge and special aspects of the particular problem. It’ll take in expert estimates but be aware of places where the experts might have blind spots, and factor that into the calculation.
It’s not either or here, it could be some combination of both. Good predictors will both do world modelling and take into account the predictions of others.
Now, if you just want a tool that tells you probabilities, of, like, basketball games or elections, this question isn’t super important. If it gets the job done, it gets the job done. But if you’re talking about AI safety, it actually does matter quite a bit. A person or rogue AI trying to conquer humanity will have to be good at predicting a large amount of highly uncertain things to succeed: Most of these intricate steps will not have betting market data. If an AI has to cheat off of us to succeed in prediction, it doesn’t bode well for their ability to beat us.
It would also mean that AI forecasters might be able to match us, but not to do much better than us. The accuracy could plateau at around the crowd level.
From everything in this post, I’m guessing that 539 falls mainly on the “aggregation” side of things. It simply does not seem to reasoning sufficiently like an actual forecaster.
Conclusion
If you claim a forecasting bot is to be superhuman, you should be able to point to actual elements of forecasting that it’s better than humans at. I see no evidence for this in 539. There seem to be substantial problems with low probability events, coherent predictions over time, short term events, probabilities adding up to more than 100%, etc. I just don’t see how it could have all these flaws and still beat a crowd forecast with decent numbers of people. I’m no expert, so maybe there is some area I've missed where it’s superhuman enough to compensate for these problems. But until these problems are addressed, I don’t think the forecasting bots will have much real-world application.
Look, it’s still possible that despite all of this, they really have stumbled upon the magic prompt for superhuman forecasting, and the result will hold up under increased scrutiny. But they sure as shit have not provided sufficient evidence for their extraordinary claim.
I’ll finish up by addressing a response by Hendrycks, who seems unfazed by the criticism:

Under the metric of “impact” being the judge, I’m sure psychics will agree that horoscopes would qualify as the greatest forecasting tool on earth, with so many happy customers. More seriously, if they want to demonstrate actual impact, why not enter into Metacalculus’s own forecasting bot tournament, with a 30 thousand dollar prize?
Hendrycks has it backwards: In order to have a real, scientific impact, you have to actually prove your thing holds up to the barest of scrutiny. Ideally before making grandiose claims about it, and before pitching it to fucking X. Look, I’m glad that various websites were able to point out the flaws in this paper. But we shouldn’t have had to. Dan Hendrycks and CAIS should have put in a little bit of extra effort, to spare all the rest of us the job of fact checking his shitty research.
In this case the problems weren’t hard to spot, but often fatal problems with claims are much harder to spot. If CAIS’s evidential requirements are this sloppy here, are they sloppy anywhere else? I don’t think they understand that they are undermining their entire credibility as an organization here. I hope the critiques of the research from around the web are taken seriously.
Thank you for this. I really appreciate this in-depth analysis, but I think it is unnecessarily harsh and critical in points.
E.g., See: Hendrycks has it backwards: In order to have a real, scientific impact, you have to actually prove your thing holds up to the barest of scrutiny. Ideally before making grandiose claims about it, and before pitching it to fucking X. Look, I’m glad that various websites were able to point out the flaws in this paper. But we shouldn’t have had to. Dan Hendrycks and CAIS should have put in a little bit of extra effort, to spare all the rest of us the job of fact checking his shitty research.
I find it weird anyone is disagreeing with Peter's comment. I'd be interested to hear a disagreer explain their position.
Thanks for doing this investigation, and also thanks to CAIS for making a website which lets people easily do this kind of investigation/replication!
Executive summary: The Centre for AI Safety's claims of "superhuman" AI forecasting capabilities for their "539" bot are not supported by evidence, with experiments revealing significant flaws in the bot's reasoning and predictive abilities.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.